Regresión con variable categórica de pertenencia a grupo:
El índice de grupo es un factor con \(J\) niveles, correspondientes a \(J\) predictores (o \(2J\) si se incluyen interacciones con un predictor \(x\), \(3J\) si hay interacciones con dos predictores \(X_{(1)}, X_{(2)}\), etc.).
Se añaden \(J-1\) predictores lineales (equivalente a reemplazar la constante por \(J\) interceptos).
Paso clave en el modelado multinivel
Los \(J\) coeficientes no se estiman de manera independiente, sino que se modelan mediante una distribución de nivel superior, por ejemplo:
Si existe un único predictor de nivel grupal, se denota \(u\).
2.3 Pooling parcial sin predictores
En esta sección se presentan los conceptos de pooling completo, no pooling y pooling parcial en el contexto del modelado multinivel. Se ilustra con el ejemplo de los niveles de radón en viviendas de los 85 condados de Minnesota. El objetivo es comprender cómo el modelado multinivel actúa como un compromiso entre ignorar la variación entre grupos y sobreajustar modelos independientes por grupo.
2.3.1 Estimaciones con pooling completo y sin pooling
Ejemplo: estimar la distribución de niveles de radón en casas de 85 condados en Minnesota.
Pooling completo: se usa un único promedio para todas las casas en los 85 condados; ignora la variación real entre condados.
No pooling: se estima el promedio del log del radón para cada condado; sobreajusta los datos cuando hay pocas observaciones por condado (estimaciones muy variables). Un condado con solo dos mediciones puede aparecer como extremo sin suficiente evidencia.
Conclusión: el no pooling exagera la variación entre condados, mientras que el pooling completo la ignora.
Objetivo del bloque de código: Cargar y depurar los datos de radón, crear variables de trabajo y codificar el identificador de condado.
# Carga y preparación de datos de radón (Minnesota)radon <-read_delim("../ARM_Data/radon/srrs2.dat", trim_ws =TRUE)
Rows: 12777 Columns: 25
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (11): state, state2, zip, basement, rep, wave, starttm, stoptm, startdt,...
dbl (13): idnum, stfips, region, typebldg, floor, room, stratum, activity, p...
lgl (1): windoor
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
radon_data <- radon %>%filter(state =="MN") %>%# mantener observaciones de Minnesotamutate(radon = activity, # nivel de radón (escala original)log_radon =log(if_else(activity ==0, 0.1, activity)), # escala log (evitar log(0))floor = floor, # 0 = sótano, 1 = primer piso (según datos)county_name =as.vector(county) # nombre de condado ) %>%group_by(county_name) %>%mutate(county =cur_group_id()) %>%# id numérico de condadoungroup()
Objetivo del bloque de código: Visualizar la distribución de log_radon por condado y marcar la media global (pooling completo).
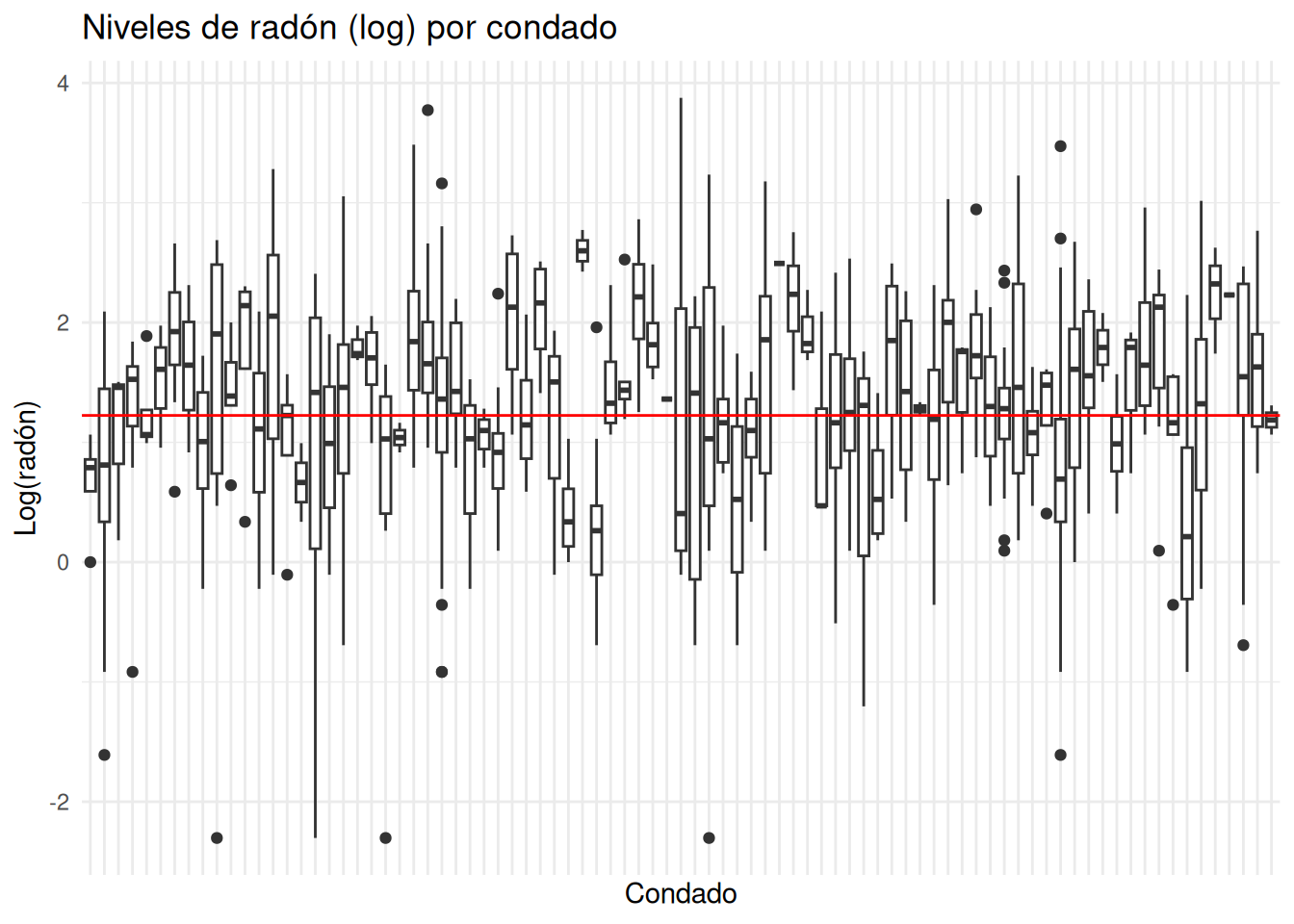
# Media global (pooling completo) en escala logmean_radon <-mean(radon_data$log_radon, na.rm =TRUE)# Boxplot por condado con línea horizontal en la media globalggplot(radon_data, aes(x = county_name, y = log_radon)) +geom_boxplot() +geom_abline(intercept = mean_radon, slope =0, color ="red") +labs(title ="Niveles de radón (log) por condado",x ="Condado",y ="Log(radón)") +theme_minimal() +theme(axis.text.x =element_blank()) # ocultar etiquetas para legibilidad
Objetivo del bloque de código: Ordenar condados por tamaño muestral y repetir la visualización para enfatizar la inestabilidad con muestras pequeñas (no pooling).
# Tamaño muestral por condadotabla_ns <- radon_data %>%count(county_name, name ="n")# Ordenar factor por tamaño de muestraradon_data <- radon_data %>%left_join(tabla_ns, by ="county_name") %>%mutate(county_name =factor(county_name, levels = tabla_ns$county_name[order(tabla_ns$n)]))# Boxplot ordenado por nggplot(radon_data, aes(x = county_name, y = log_radon)) +geom_boxplot() +geom_abline(intercept = mean_radon, slope =0, color ="red") +labs(title ="Niveles de radón (log) por condado (ordenado por tamaño muestral)",x ="Condado (ordenado por n)",y ="Log(radón)") +theme_minimal() +theme(axis.text.x =element_blank())
2.3.2 Estimaciones con pooling parcial (modelo multinivel)
El modelo multinivel genera estimaciones intermedias. El objetivo es estimar el promedio de radón en logaritmos \(\alpha_j\) para el condado \(j\), a partir de una muestra de tamaño \(n_j\).
El estimador multinivel es un promedio ponderado entre el promedio del condado (\(\bar{y}_j\)) y el promedio general del estado (\(\bar{y}_{\text{all}}\)):
donde \(n_j\) es el número de casas medidas en el condado \(j\), \(\sigma_y^2\) la varianza dentro de los condados y \(\sigma_\alpha^2\) la varianza entre los promedios de los condados.
Interpretación de los pesos
Muestras pequeñas (\(n_j\) pequeño): la estimación se acerca a \(\bar{y}_{\text{all}}\) (si \(n_j=0\), coincide).
Muestras grandes (\(n_j \to \infty\)): la estimación coincide con \(\bar{y}_j\).
Casos intermedios: la estimación se sitúa entre ambos extremos.
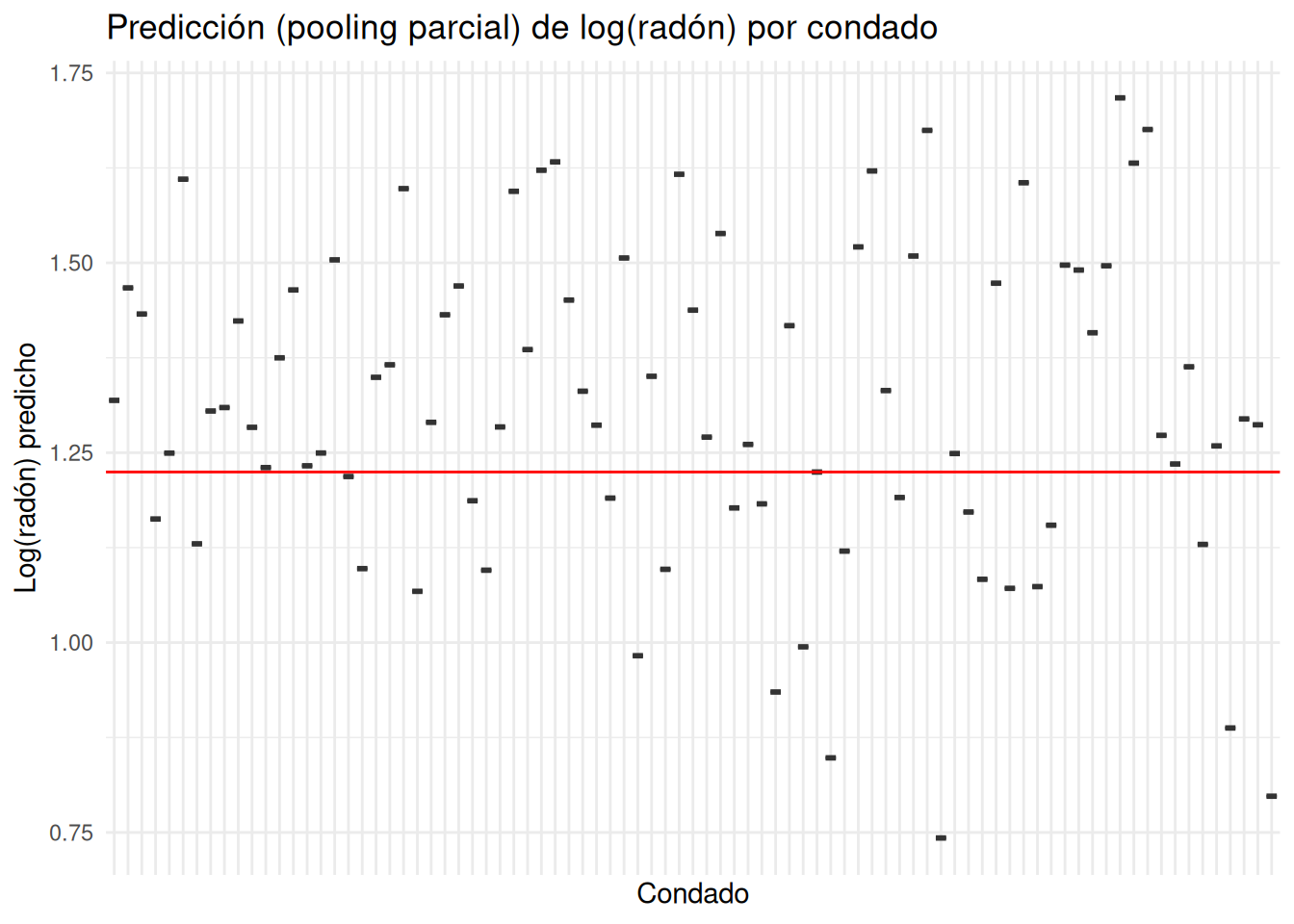
Objetivo del bloque de código: Ajustar un modelo multinivel de interceptos aleatorios por condado y producir valores predichos (pooling parcial).
# Modelo multinivel (intercepto aleatorio por condado)lmer_radon <-lmer(log_radon ~1+ (1| county_name), data = radon_data)# Predicción del nivel de radón (log) con pooling parcialradon_data <- radon_data %>%mutate(log_radon_pred =predict(lmer_radon))# Visualización de las predicciones por condadoggplot(radon_data, aes(x = county_name, y = log_radon_pred)) +geom_boxplot() +geom_abline(intercept = mean_radon, slope =0, color ="red") +labs(title ="Predicción (pooling parcial) de log(radón) por condado",x ="Condado",y ="Log(radón) predicho") +theme_minimal() +theme(axis.text.x =element_blank())
2.4 Pooling parcial con predictores
En esta sección se estudia el pooling parcial con predictores en modelos multinivel. El principio es el mismo que en los casos sin predictores: encontrar un compromiso entre pooling completo y no pooling. El ejemplo de aplicación corresponde a las mediciones de radón en viviendas de 85 condados de Minnesota, incluyendo como predictor el piso de medición (sótano o primer piso).
2.4.1 Pooling completo y no pooling con predictores
Pooling completo: una sola regresión para todos los condados:
\[
y_i = \alpha + \beta x_i + \epsilon_i
\]
No pooling: regresiones con interceptos específicos por condado pero pendiente común:
donde \(j[i]\) indica el condado de la vivienda \(i\). El pooling completo ignora la variación entre condados; el no pooling tiende a producir estimaciones más extremas en condados con pocas observaciones.
Ejemplo en R del pooling completo:
# Ajuste con pooling completo: mismo intercepto y pendientemodelo_pooling <-lm(log_radon ~ floor, data = radon_data)summary(modelo_pooling)
Call:
lm(formula = log_radon ~ floor, data = radon_data)
Residuals:
Min 1Q Median 3Q Max
-3.6293 -0.5383 0.0342 0.5603 2.5486
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.32674 0.02972 44.640 <2e-16 ***
floor -0.61339 0.07284 -8.421 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8226 on 917 degrees of freedom
Multiple R-squared: 0.07178, Adjusted R-squared: 0.07077
F-statistic: 70.91 on 1 and 917 DF, p-value: < 2.2e-16
Ejemplo en R del no pooling:
# Ajuste sin pooling: interceptos específicos por condadomodelo_no_pooling <-lm(log_radon ~ floor +factor(county_name) -1, data = radon_data)summary(modelo_no_pooling)
2.4.1.1 Problemas con pooling completo y no pooling
Pooling completo: elimina la variación real entre condados, ocultando el objetivo de identificar condados con niveles altos de radón.
No pooling: sobreajusta los datos. Condados con pocas observaciones presentan estimaciones poco confiables, como en el caso de Lac Qui Parle, que aparece con el mayor nivel de radón a pesar de tener solo dos mediciones.
2.4.2 Análisis multinivel
El modelo multinivel combina ambos enfoques, introduciendo un “suavizamiento” de los interceptos:
Este planteamiento establece una restricción suave: los interceptos se acercan a \(\mu_\alpha\), pero sin forzarlos a ser idénticos.
Cuando \(\sigma_\alpha \to \infty\), no hay pooling.
Cuando \(\sigma_\alpha \to 0\), se obtiene pooling completo.
2.4.3 Pooling parcial (shrinkage) de los coeficientes \(\alpha_j\)
La estimación multinivel de \(\alpha_j\) puede expresarse como un promedio ponderado entre la estimación sin pooling para su condado y la media general \(\mu_\alpha\):
En la práctica, este cálculo se implementa automáticamente con funciones como lmer() o mediante métodos bayesianos.
# Ejemplo de ajuste multinivel en R con lme4modelo_multinivel <-lmer(log_radon ~ floor + (1| county_name), data = radon_data)summary(modelo_multinivel)
Linear mixed model fit by REML ['lmerMod']
Formula: log_radon ~ floor + (1 | county_name)
Data: radon_data
REML criterion at convergence: 2171.3
Scaled residuals:
Min 1Q Median 3Q Max
-4.3989 -0.6155 0.0029 0.6405 3.4281
Random effects:
Groups Name Variance Std.Dev.
county_name (Intercept) 0.1077 0.3282
Residual 0.5709 0.7556
Number of obs: 919, groups: county_name, 85
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.46160 0.05158 28.339
floor -0.69299 0.07043 -9.839
Correlation of Fixed Effects:
(Intr)
floor -0.288
2.4.3.1 Línea de regresión promedio y varianzas
Los hiperparámetros estimados en el modelo de radón son:
\(\hat{\mu}_\alpha = 1.46\)
\(\hat{\beta} = -0.69\)
\(\hat{\sigma}_y = 0.76\)
\(\hat{\sigma}_\alpha = 0.33\)
La línea de regresión promedio es:
\[
y = 1.46 - 0.69x
\]
La relación entre varianzas puede expresarse como:
Cociente de varianzas: \(\sigma_\alpha^2 / \sigma_y^2 = 0.19\approx 1/5\). El cual se puede interpretar como que la variabilidad entre condados es aproximadamente una quinta parte de la variabilidad dentro de los condados. Además se puede interpretar a que la desviación estándar entre condados equivale a la desviación estándar del promedio de 5 mediciones dentro de un condado.
Correlación intraclase: \(\sigma_\alpha^2 / (\sigma_\alpha^2 + \sigma_y^2)\). Este indicador va de 0 (agrupamiento no informativo) a 1 (todos los miembros del grupo son identicos). En este caso, vale 0.16, indicando que el 16% de la variabilidad total se debe a diferencias entre condados.
2.4.4 Regresión clásica como caso especial
Si \(\sigma_\alpha \to 0\), el modelo se reduce a pooling completo.
Si \(\sigma_\alpha \to \infty\), se obtiene no pooling.
Los modelos multinivel permiten estimar \(\sigma_\alpha\) directamente a partir de los datos, evitando elegir arbitrariamente uno de los extremos.
2.4.5 Ejemplos gráficos comparativos
2.4.5.1 Pooling completo vs no pooling con una covariable
Warning in data.frame(county_s = sub("county", "",
names(coef_df)[grep("county", : row names were found from a short variable and
have been discarded
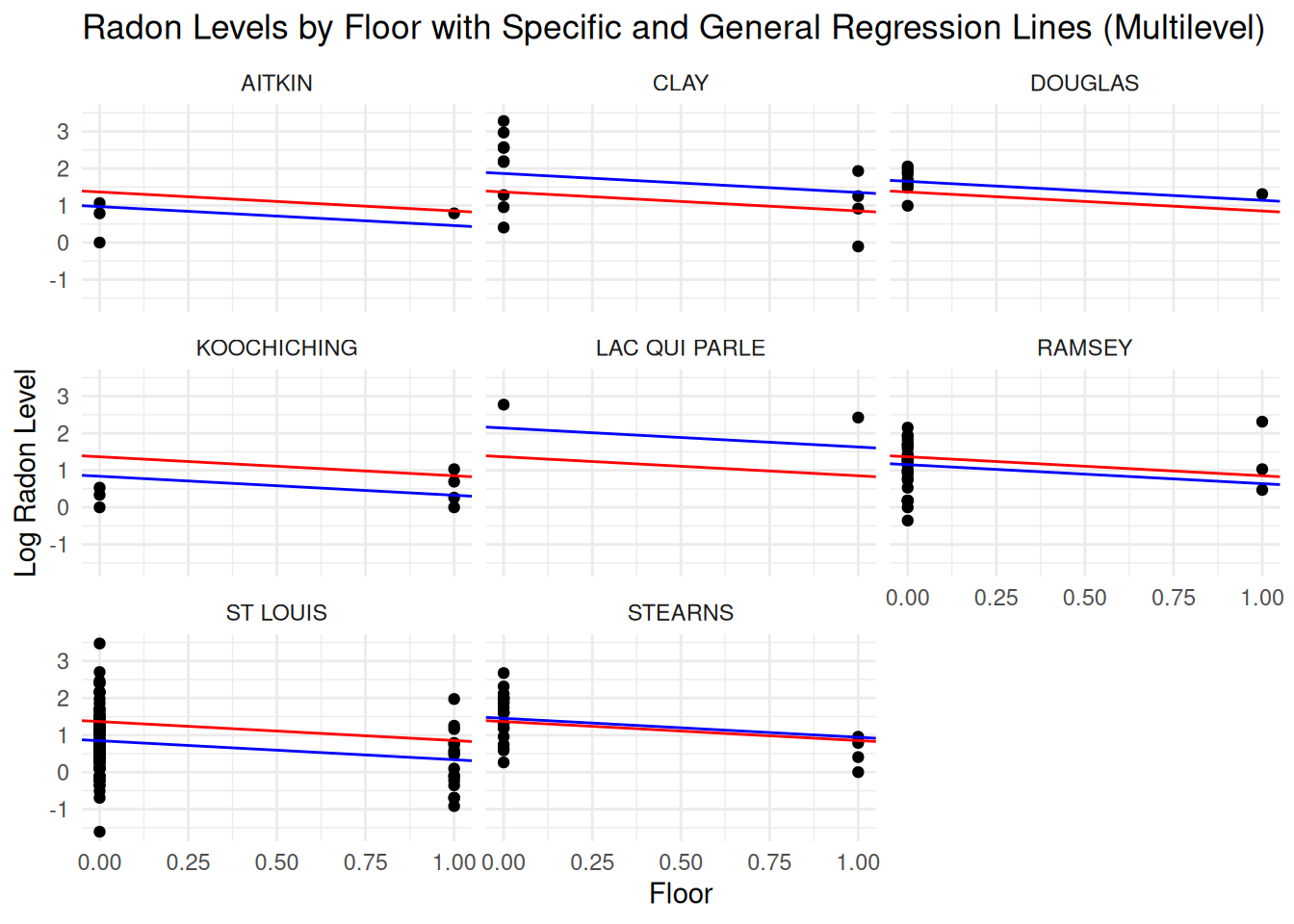
radon_data_r <- radon_data_r %>%left_join(coef_data, by ="county_s")ggplot(data = radon_data_r) +geom_point(aes(x = floor, y = log_radon)) +geom_abline(aes(intercept = intercept, slope = slope), color ="blue") +# Líneas específicas por condadogeom_abline(intercept =coef(regresion_pooling)[1], slope =coef(regresion_pooling)[2], color ="red") +# Línea generalfacet_wrap(~county_s) +labs(title ="Radon Levels by Floor with Specific and General Regression Lines",x ="Floor", y ="Log Radon Level") +theme_minimal()
Warning: Removed 209 rows containing missing values or values outside the scale range
(`geom_abline()`).
2.4.5.2 Pooling parcial con una covariable (Multinivel)
Warning in data.frame(county_s = rownames(random_effects), intercept_lmer =
fixed_effect[1] + : row names were found from a short variable and have been
discarded
radon_data_r <- radon_data_r %>%left_join(coef_data_lmer, by ="county_s")ggplot(data = radon_data_r) +geom_point(aes(x = floor, y = log_radon)) +geom_abline(aes(intercept = intercept_lmer, slope = slope_lmer), color ="blue") +# Regresiones por condadogeom_abline(intercept = fixed_effect[1], slope = fixed_effect[2], color ="red") +# Línea general (efectos fijos)facet_wrap(~county_s) +labs(title ="Radon Levels by Floor with Specific and General Regression Lines (Multilevel)",x ="Floor", y ="Log Radon Level") +theme_minimal()
2.5 Ajuste rápido de modelos multinivel en R
En esta sección se presenta cómo ajustar modelos multinivel de manera rápida en R utilizando la función lmer(). Estos modelos permiten estimar interceptos y pendientes que pueden variar entre grupos. Se ilustra el procedimiento con los datos de radón, donde las viviendas están anidadas en condados.
2.5.1 Modelo con intercepto variable sin predictores
El modelo más sencillo incluye únicamente un intercepto que varía entre condados:
MO <-lmer(log_radon ~1+ (1| county), data = radon_data)summary(MO)
Linear mixed model fit by REML ['lmerMod']
Formula: log_radon ~ 1 + (1 | county)
Data: radon_data
REML criterion at convergence: 2259.4
Scaled residuals:
Min 1Q Median 3Q Max
-4.4661 -0.5734 0.0441 0.6432 3.3516
Random effects:
Groups Name Variance Std.Dev.
county (Intercept) 0.09581 0.3095
Residual 0.63662 0.7979
Number of obs: 919, groups: county, 85
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.31258 0.04891 26.84
2.5.2 Modelo con intercepto variable y un predictor individual
Ahora se añade el predictor a nivel individual (piso de medición):
M1 <-lmer(log_radon ~ floor + (1| county), data = radon_data)summary(M1)
Linear mixed model fit by REML ['lmerMod']
Formula: log_radon ~ floor + (1 | county)
Data: radon_data
REML criterion at convergence: 2171.3
Scaled residuals:
Min 1Q Median 3Q Max
-4.3989 -0.6155 0.0029 0.6405 3.4281
Random effects:
Groups Name Variance Std.Dev.
county (Intercept) 0.1077 0.3282
Residual 0.5709 0.7556
Number of obs: 919, groups: county, 85
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.46160 0.05158 28.339
floor -0.69299 0.07043 -9.839
Correlation of Fixed Effects:
(Intr)
floor -0.288
Este modelo supone una pendiente común para todos los condados, pero permite interceptos distintos.
2.5.3 Coeficientes estimados por condado
Podemos extraer las líneas de regresión por condado:
Podemos comparar pooling completo, no pooling y pooling parcial (multinivel):
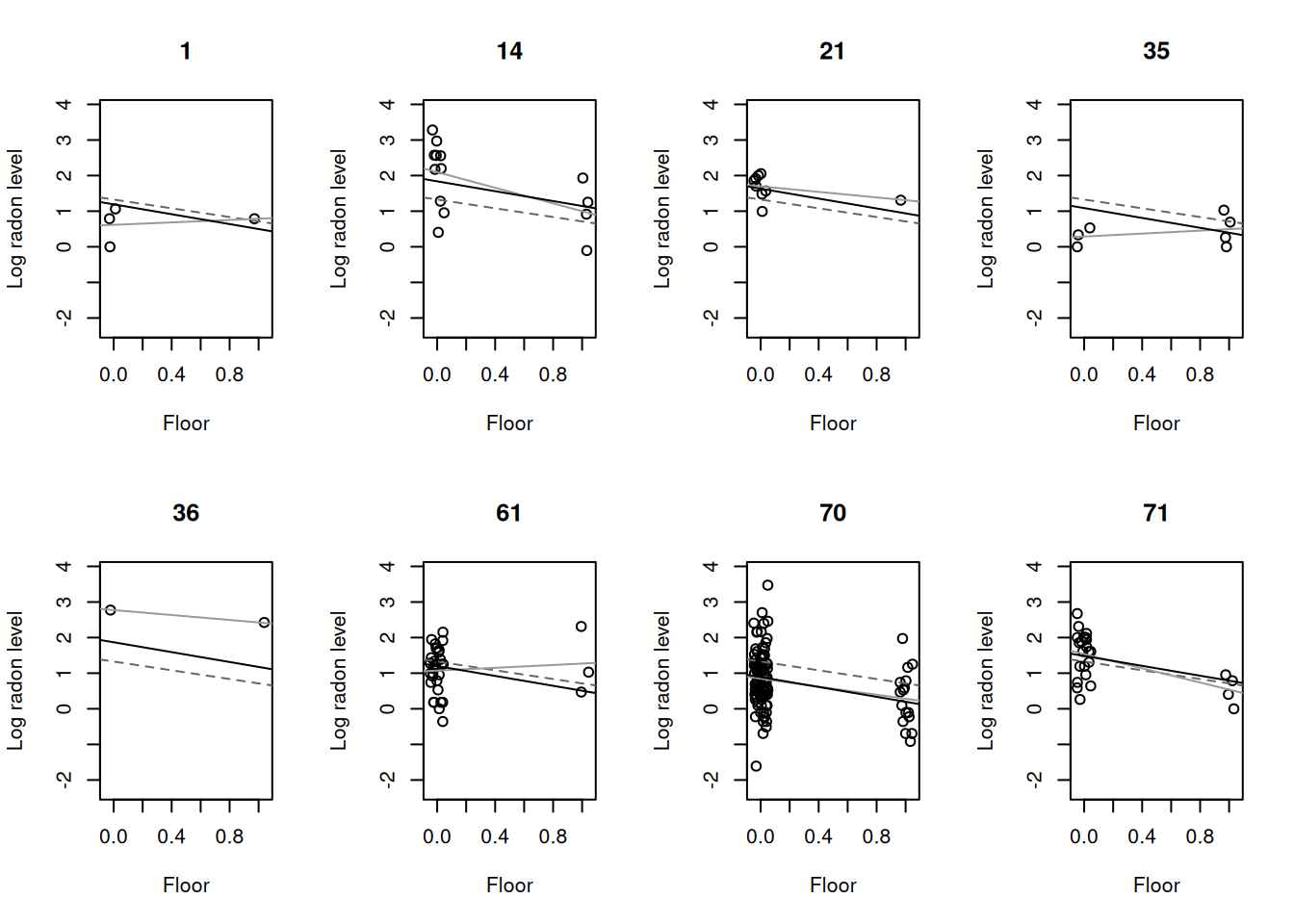
a.hat.M1 <-coef(M1)$county[,1] # interceptosb.hat.M1 <-coef(M1)$county[,2] # pendientes (iguales aquí)x.jitter <- radon_data$floor +runif(nrow(radon_data), -0.05, 0.05)# Ejemplo con algunos condados seleccionados#display8 <- sample(unique(radon_data$county), 8)display8 <-unique(radon_data_r$county)par(mfrow=c(2,4))for (j in display8) { idx <- radon_data$county == jplot(x.jitter[idx], radon_data$log_radon[idx],xlim=c(-.05,1.05), ylim=range(radon_data$log_radon),xlab="Floor", ylab="Log radon level", main=j)# Línea de pooling completoabline(coef(lm(log_radon ~ floor, data = radon_data)), lty=2, col="gray40")# Línea de no poolingabline(coef(lm(log_radon ~ floor, data = radon_data[idx,])), col="gray60")# Línea multinivelabline(a.hat.M1[j], b.hat.M1[j], col="black")}
2.5.8 Modelos más complejos
La función lmer() permite ajustar modelos con interceptos y pendientes que varían entre grupos, predictores de nivel superior y estructuras más complejas. En casos con pocos grupos o modelos complicados, puede ser conveniente emplear métodos bayesianos como JAGS, que permiten un tratamiento más detallado de la incertidumbre.
2.6 Cinco formas de escribir el mismo modelo
En esta sección se presentan cinco formas equivalentes de expresar un modelo multinivel. El contexto es el análisis de radón en viviendas de condados de Minnesota, donde se dispone de predictores a nivel individual (por ejemplo, el piso donde se tomó la medición) y a nivel de condado (el logaritmo del contenido de uranio en el suelo). Se muestra cómo un mismo modelo puede representarse de manera diferente, ya sea mediante regresiones locales, modelos mixtos, errores correlacionados o matrices de diseño ampliadas.
2.6.1 Coeficientes de regresión que varían entre grupos
Se añade un predictor de nivel de grupo para mejorar la inferencia de los coeficientes de grupo \(\alpha_j\). Continuamos con el ejemplo de radón: modelo con predictor individual (piso, \(x_i\)) y un predictor a nivel de condado (log de uranio del suelo, \(u_j\)). Mostramos cómo integrar ambos niveles en un modelo multinivel, cómo extraer e interpretar los coeficientes, y cómo el predictor de grupo reduce la variación entre condados.
Rows: 3194 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (4): stfips, ctfips, st, cty
dbl (3): lon, lat, Uppm
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
radon_data <- radon_data %>%mutate(fips = stfips *1000+ cntyfips)# Obtener el FIPS a nivel de EE.UU.usa.fips <-1000*as.numeric(cty$stfips) +as.numeric(cty$ctfips)# Encontrar las filas correspondientes a los condados únicos en Minnesotausa.rows <-match(unique(radon_data$fips), usa.fips)uranium <- cty[usa.rows, "Uppm"]u <-log(uranium)county_u_data <-data.frame(county_name =unique(radon_data$county_name),u = u)radon_data <- radon_data %>%left_join(county_u_data, by ="county_name") %>%rename(u = Uppm)
2.7.1 Agregar un predictor de nivel de grupo para mejorar la inferencia de \(\alpha_j\)
Formulación jerárquica con predictor individual \(x_i\) (piso) y predictor de condado \(u_j\) (uranio):
Ajustar el modelo multinivel con intercepto aleatorio por condado e incluir el predictor de condado (uranio) en la parte fija. Se asume que el data.frameradon_data contiene:
log_radon: respuesta en log,
floor: indicador de piso (0 = sótano, 1 = primer piso),
u: medida (log) de uranio por condado,
county_name: factor de condado.
# Ajuste del modelo multinivel con predictor de grupo (uranio) y predictor individual (piso)M2 <-lmer(log_radon ~ floor + u + (1| county_name), data = radon_data)# Resumen amigable del ajuste (coeficientes fijos y varianzas de niveles)display(M2)
lmer(formula = log_radon ~ floor + u + (1 | county_name), data = radon_data)
coef.est coef.se
(Intercept) 1.47 0.04
floor -0.67 0.07
u 0.72 0.09
Error terms:
Groups Name Std.Dev.
county_name (Intercept) 0.16
Residual 0.76
---
number of obs: 919, groups: county_name, 85
AIC = 2144.2, DIC = 2111.4
deviance = 2122.8
2.7.2 Extracción e interpretación de coeficientes
El modelo promedio sobre condados es: \(y_i = \text{Intercepto} + \beta x_i + \gamma u_{j[i]}\).
Efectos fijos (fixef): promedios sobre condados.
Efectos aleatorios (ranef): desviaciones de cada condado respecto al promedio.
coef(M2): combina fijos + aleatorios para obtener coeficientes por condado.
Objetivo del bloque de código
Extraer efectos fijos y aleatorios, y construir la ecuación por condado con base en la salida del modelo.
# Efectos fijos (promedio sobre condados)fx <-fixef(M2)# Efectos aleatorios por condado (desviación de intercepto)re_county <-ranef(M2)$county_name %>%rownames_to_column(var ="county_name") %>%as_tibble() %>%rename(rand_intercept =`(Intercept)`)# Coeficientes por condado (intercepto específico + pendientes fijas)coef_county <-coef(M2)$county_name %>%rownames_to_column(var ="county_name") %>%as_tibble()# Vista rápidahead(fx)
(Intercept) floor u
1.4657628 -0.6682448 0.7202676
El modelo promedio estimado: \(y_i = \hat{\mu}_{\alpha} - \hat{\beta}x_i + \hat{\gamma}u_{j[i]}\). Para un condado particular (p. ej., 85), la línea ajustada puede obtenerse:
desde coef(M2) (intercepto específico + pendientes fijas),
o como fixef(M2) más el ajuste del intercepto dado por ranef(M2).
Objetivo del bloque de código
Ilustrar cómo calcular la línea ajustada para un condado específico a partir de las salidas fixef, ranef y coef.
# Seleccione un condado de ejemplo (ajustar el nombre según exista en radon_data)ejemplo_county <- radon_data %>%pull(county_name) %>%as.character() %>%unique() %>% .[1]# Línea con coeficientes específicos por condado desde coef(M2)coef_ejemplo <- coef_county %>%filter(county_name == ejemplo_county)intercepto_ej <- coef_ejemplo$`(Intercept)`beta_floor_ej <- coef_ejemplo$floorgamma_u_ej <- coef_ejemplo$u# Alternativa: fixed effects + random interceptrand_adj <- re_county %>%filter(county_name == ejemplo_county) %>%pull(rand_intercept)intercepto_via_fx_re <- fx[1] + rand_adj # (Intercepto promedio + desviación de condado)beta_via_fx <- fx["floor"]gamma_via_fx <- fx["u"]tibble(county_name = ejemplo_county,intercepto_via_coef = intercepto_ej,intercepto_via_fx_re = intercepto_via_fx_re,beta_floor_via_coef = beta_floor_ej,beta_floor_via_fx = beta_via_fx,gamma_u_via_coef = gamma_u_ej,gamma_u_via_fx = gamma_via_fx)
2.7.4 Efecto del predictor de grupo en la variación entre condados
La inclusión de \(u_j\)no cambia la variación dentro de condado (\(\sigma_y\)), pero reduce la variación entre condados (\(\sigma_\alpha\)), al explicar parte de la heterogeneidad sistemática de los interceptos con un predictor de nivel grupo.
Objetivo del bloque de código
Extraer las desviaciones estándar estimadas a nivel condado (intercepto aleatorio) y residual para discutir \(\hat{\sigma}_\alpha\) y \(\hat{\sigma}_y\).
# Extraer componentes de varianza del modelovc <-VarCorr(M2)sd_alpha <-attr(vc$county_name, "stddev")[1] # sd del intercepto a nivel condadosd_y <-attr(vc, "sc") # sd residual (nivel individual)tibble(`sd_intercepto_condado (hat{sigma}_alpha)`= sd_alpha,`sd_residual (hat{sigma}_y)`= sd_y)
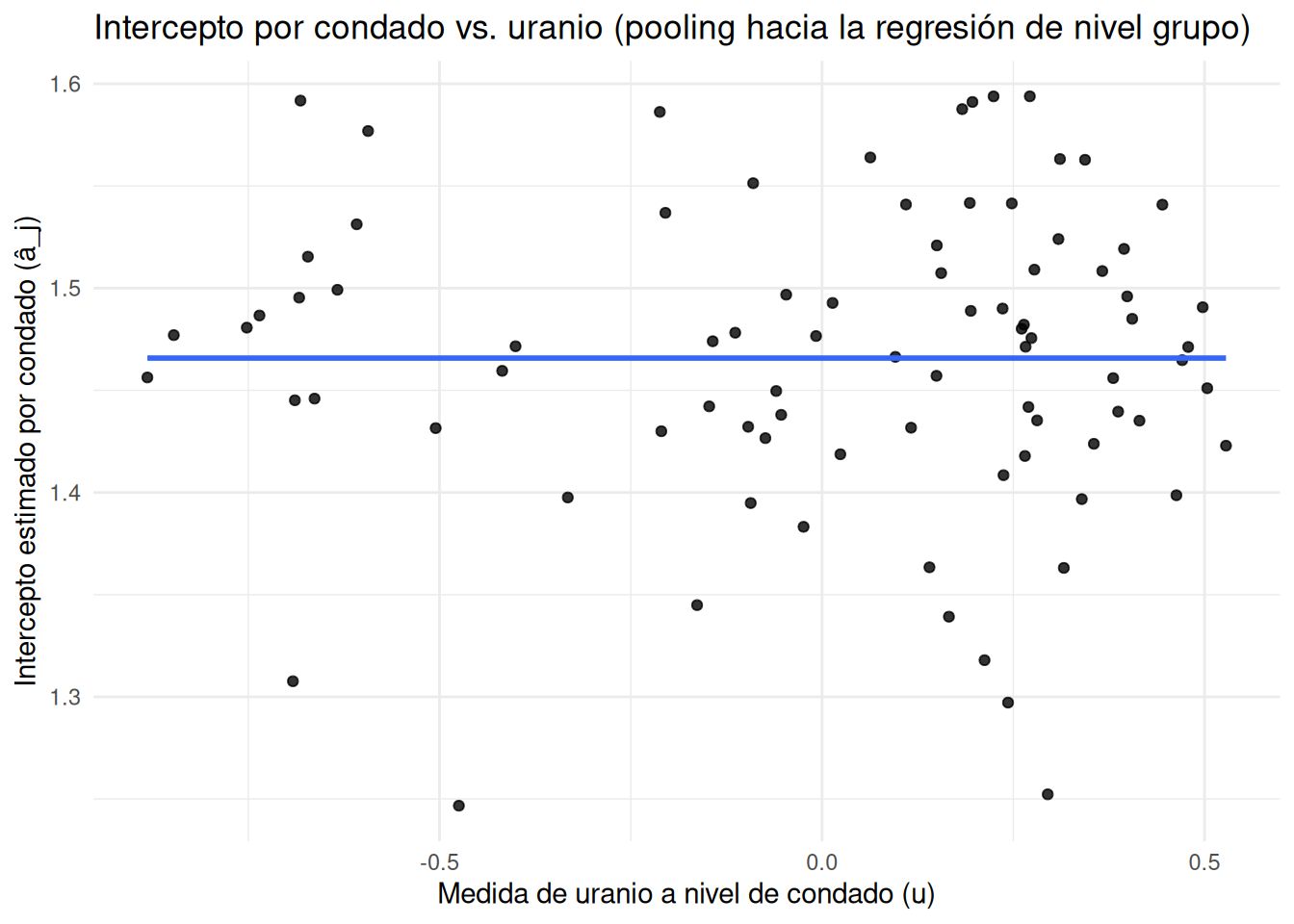
2.7.5 Visualización: intercepto por condado vs. uranio de condado
La estimación de \(\alpha_j\) se encoge hacia la regresión de nivel grupo \(\alpha_j = \gamma_0 + \gamma_1 u_j\). Para ilustrarlo, graficamos el intercepto estimado por condado frente a la media de uranio de su condado y sobreponemos la recta de regresión.
2.7.6 Objetivo del bloque de código
Construir un resumen por condado (media de u) y el intercepto específico estimado; luego, graficar y ajustar una recta para visualizar la relación.
# Media de uranio por condadou_county <- radon_data %>%group_by(county_name) %>%summarise(u_mean =mean(u, na.rm =TRUE), .groups ="drop")# Intercepto específico por condado desde coef(M2)intercepts_county <- coef_county %>% dplyr::select(county_name, `(Intercept)`) %>%rename(a_hat =`(Intercept)`)# Unimos para graficar: intercepto vs uranioplot_data <- u_county %>%inner_join(intercepts_county, by ="county_name")# Gráfico: puntos + recta OLS de referenciaggplot(plot_data, aes(x = u_mean, y = a_hat)) +geom_point(alpha =0.8) +geom_smooth(method ="lm", formula = y ~ x, se =FALSE) +labs(x ="Medida de uranio a nivel de condado (u)",y ="Intercepto estimado por condado (â_j)",title ="Intercepto por condado vs. uranio (pooling hacia la regresión de nivel grupo)" ) +theme_minimal()
2.7.7 Inclusión de indicadores de condado y predictor de condado
En regresión clásica, los indicadores de condado junto con un predictor de condado suelen ser colineales. En el modelo multinivel, este problema se evita porque los \(\alpha_j\) se modelan con pooling parcial hacia la regresión de nivel grupo, permitiendo estimar simultáneamente los interceptos por condado y la pendiente de \(u_j\).
2.7.8 Pooling parcial de \(\alpha_j\) con predictores de grupo
Con \(\alpha_j \sim \mathrm{N}(U_j\gamma,\sigma_\alpha^2)\), los \(\alpha_j\) se encogen hacia \(\hat{\alpha}_j=U_j\gamma\). De forma aproximada, la estimación de \(\alpha_j\) combina la evidencia del grupo \(j\) y la de la regresión de nivel grupo:
\[
\begin{aligned}
\text{estimate of } \alpha_j \approx
\frac{\frac{n_j}{\sigma_y^2}}{\frac{n_j}{\sigma_y^2}+\frac{1}{\sigma_\alpha^2}}
\cdot (\text{estimate from group } j)
+\frac{\frac{1}{\sigma_\alpha^2}}{\frac{n_j}{\sigma_y^2}+\frac{1}{\sigma_\alpha^2}}
\cdot (\text{estimate from regression}).
\end{aligned}
\]
Equivalente para los errores de nivel grupo \(\eta_j\):
2.8 Construcción de modelos y significancia estadística
2.8.1 De regresión clásica a regresión multinivel
Ante datos multinivel, se recomienda comenzar con modelos clásicos sencillos y avanzar hacia un modelo multinivel completo. Cuatro puntos de partida naturales:
Modelo de pooling completo: una sola regresión clásica que ignora la información de grupos (un único modelo para todos los datos), pudiendo incluir predictores de nivel grupo pero sin coeficientes por indicadores de grupo.
Modelo sin pooling: una sola regresión clásica que incluye indicadores de grupo (sin predictores de nivel grupo) y sin modelar los coeficientes de grupo.
Modelos separados por grupo: una regresión clásica en cada grupo. Puede ser inviable cuando hay grupos con tamaños muestrales pequeños (p. ej., si un condado solo tiene casas con sótano no se puede estimar la pendiente \(\beta\) para ese condado).
Análisis en dos pasos: partir del sin pooling o de modelos separados, y luego ajustar una regresión clásica a nivel grupo usando como “datos” los coeficientes estimados por grupo.
Cada uno puede ser informativo por sí mismo y, además, prepara la comprensión del pooling parcial en un modelo multinivel.
2.8.2 ¿Cuándo es más efectivo el modelado multinivel?
El modelado multinivel es más importante cuando está cerca del pooling completo para al menos algunos grupos (p. ej., Lac Qui Parle en la figura citada). En esta situación se permite que las estimaciones varíen por grupo y se estimen con precisión. Como sugiere la referencia a la fórmula vista anteriormente, el pooling es mayor cuando la desviación estándar a nivel grupo es pequeña, esto es, cuando los grupos son similares: \(\sigma_{\alpha}\) pequeño \(\Rightarrow\) mayor pooling. En contraste, si \(\sigma_{\alpha}\) es grande (grupos muy distintos), el enfoque multinivel se aproxima al sin pooling y aporta poco frente a éste.
Esto no contradice la motivación del enfoque como compromiso entre extremos: el estimador multinivel puede ser cercano al pooling completo para grupos con \(n_j\) pequeños y cercano al sin pooling para grupos con \(n_j\) grandes, funcionando bien en ambos casos automáticamente.
2.8.3 Uso de predictores de nivel grupo para hacer más efectivo el pooling parcial
Además de su interés intrínseco, los predictores de nivel grupo reducen la variación no explicada entre grupos y, con ello, disminuyen \(\sigma_{\alpha}\). Esto incrementa la cantidad de pooling del estimador multinivel, obteniendo estimaciones más precisas de los \(\alpha_j\), especialmente cuando \(n_j\) es pequeño. Siguiendo la plantilla de regresión clásica, se procede agregando predictores a ambos niveles y reduciendo la varianza no explicada en cada nivel. (No obstante, puede haber situaciones en que añadir un predictor de nivel grupo aumente la varianza no explicada).
2.8.4 Significancia estadística
No es apropiado usar significancia estadística como criterio para incluir indicadores de grupo en un modelo multinivel. En el ejemplo de radón con interceptos variables y sin predictor de nivel grupo, el promedio \(\mu_{\alpha}\) se estima en \(1.46\) y los interceptos por condado \(\alpha_j\) muestran desviaciones con sus errores estándar (p. ej., país 1 cerca de 1 error estándar, país 2 a más de 4 errores estándar, país 85 a menos de 1). Aun así, se deben incluir todos los grupos: el objetivo no es probar si ciertos condados difieren significativamente del promedio de Minnesota, sino estimar lo mejor posible en cada condado con la incertidumbre adecuada. En vez de umbrales de significancia, se permiten interceptos que varían y se reconoce que la precisión por grupo puede ser limitada.
El mismo principio se extiende a modelos con pendientes variables, estructuras no anidadas, datos discretos, etc. Una vez incluida una fuente de variación, no se usa la significancia para decidir qué indicadores incluir o excluir.
En la práctica, las mayores restricciones para no usar modelos extremadamente elaborados (con todos los coeficientes variando respecto de todos los factores de agrupación) son: ajuste (el software puede fallar con muchos factores de agrupación) y comprensión (interpretar modelos complejos). La función lmer() suele funcionar bien cuando puede, pero puede fallar con estructuras muy complejas; JAGS es más general, pero puede ser lento con muestras grandes o modelos complejos. Por ello, se recomienda empezar simple y construir gradualmente, ganando también comprensión del modelo ajustado.
2.9 Predicción
2.9.1 Repaso de predicción en regresión clásica
En una regresión clásica, la predicción se basa en definir una matriz de predictores \(\tilde{X}\) para nuevas observaciones y calcular el predictor lineal \(\tilde{X}\beta\). Posteriormente se simulan los valores de respuesta añadiendo errores adecuados:
La predicción resultante es más incierta que en un condado ya observado, dado que se introduce incertidumbre adicional por el nuevo término \(\tilde{\alpha}\). El intervalo predictivo para el nuevo condado resulta alrededor de un 3% más ancho que el del condado 26.
2.9.4 Comparación de predicciones dentro de grupo y entre grupos
Dentro de un grupo conocido: precisión ≈ \(\pm \sigma_y = \pm 0.76\).
La diferencia es pequeña en este caso porque la varianza entre condados (\(\sigma_\alpha^2\)) es baja comparada con la varianza dentro de condados (\(\sigma_y^2\)).
2.10 Aspectos finales
2.10.1 ¿Cuántos grupos se necesitan?
Cuando el número de grupos \(J\) es pequeño, es difícil estimar la variación entre grupos. En este escenario, los modelos multinivel tienden a comportarse de manera similar a un modelo sin pooling, ya que la estimación de \(\sigma_{\alpha}\) suele ser imprecisa y tiende a sobreestimarse, lo que lleva a resultados cercanos al no pooling. Sin embargo, aun así los modelos multinivel no son peores que una regresión sin pooling y pueden resultar más fáciles de interpretar, al permitir incluir indicadores de todos los grupos sin necesidad de elegir una categoría base.
2.10.2 Casos con uno o dos grupos
Con uno o dos grupos, los modelos multinivel se reducen esencialmente a la regresión clásica, salvo que se incorpore información previa de manera explícita. Un ejemplo sería modelar el sexo como un predictor binario en lugar de como un modelo multinivel con dos niveles. Aun en este escenario, los modelos multinivel pueden resultar útiles para realizar predicciones sobre nuevos grupos.
2.10.3 ¿Cuántas observaciones por grupo se necesitan?
Incluso con dos observaciones por grupo es posible ajustar un modelo multinivel. De hecho, puede aceptarse que haya grupos con una sola observación. En esos casos, los interceptos de grupo \(\alpha_j\) no se estimarán con precisión, pero aun así aportan información parcial que permite estimar los coeficientes y parámetros de varianza de los niveles individual y grupal.
2.10.4 Conjuntos de datos más grandes y modelos más complejos
Cuando se dispone de más datos, se justifica añadir más parámetros al modelo. Por ejemplo, un estudio médico podría comenzar con un modelo simple, luego incluir estimaciones separadas para hombres y mujeres, desagregar por otras variables demográficas, regiones, estados, áreas más pequeñas e interacciones. Estas complejidades siempre existen de forma latente, pero en conjuntos de datos pequeños no es posible aprender tanto, y el ajuste de modelos muy complejos puede no ser útil debido a las grandes incertidumbres resultantes.