set.seed(5454) # para reproducibilidad
# Parámetros "verdaderos" de la simulación
E <- 3 # etnias
P <- 60 # precintos
mu <- -1.0 # intercepto en la escala log
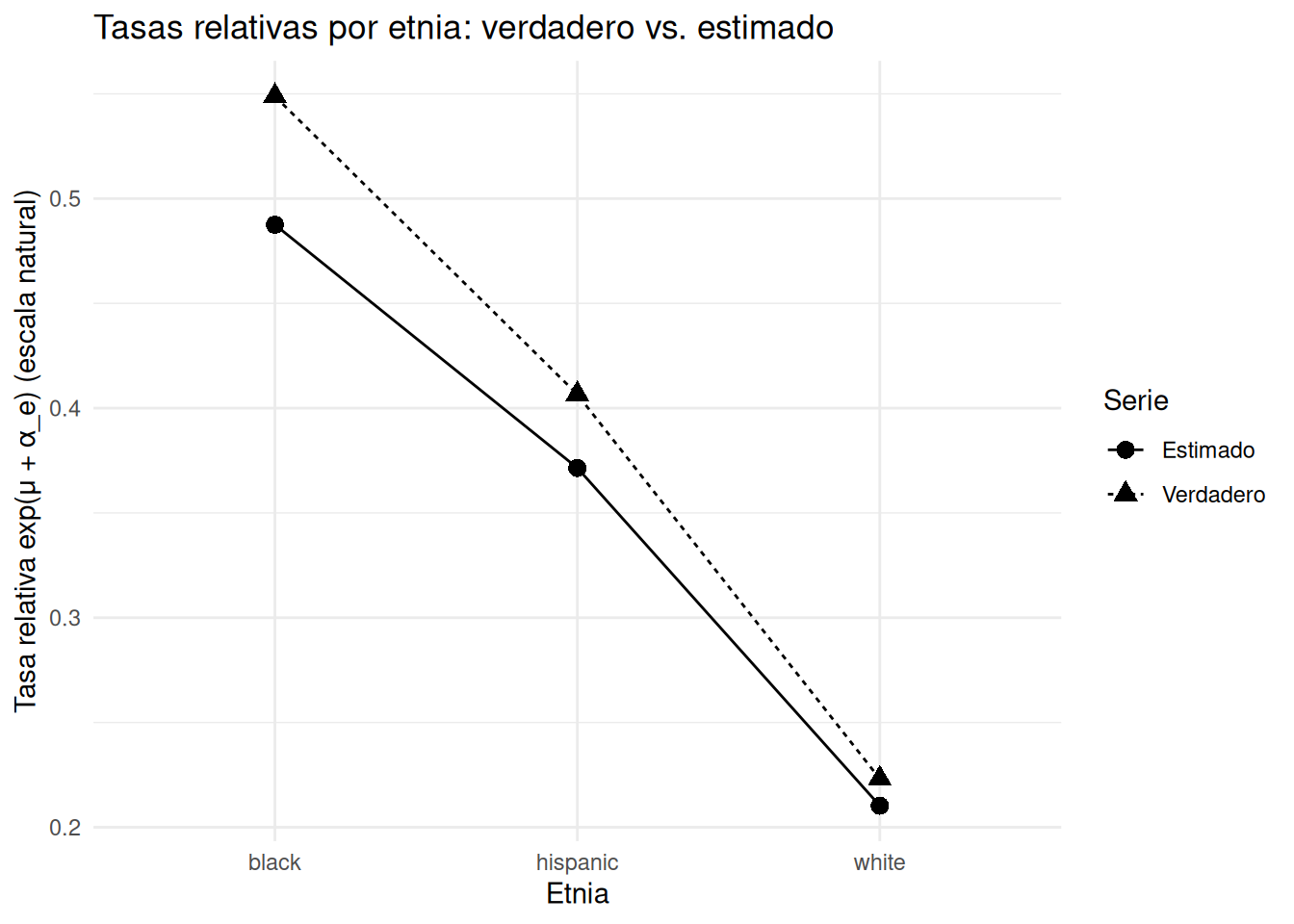
alpha_true <- c( 0.40, 0.10, -0.50 ) # efectos por etnia: blacks, hispanics, whites (suma != 0, luego centraremos)
sigma_beta <- 0.50 # sd entre precintos
sigma_epsilon <- 0.30 # sd de sobredispersión (log-escala)
lambda_arresto <- 50 # media base de arrestos por celda (antes de escalado)
scale_15m <- 15/12 # factor de 15 meses
# Diseño completo (todas las combinaciones etnia-precinto)
design <- expand_grid(
eth = factor(1:E, labels = c("black","hispanic","white")),
precinct = factor(1:P)
) %>%
# Asignamos un ID único por observación (para OLRE)
mutate(obs_id = row_number())
# Efectos aleatorios por precinto
beta_precinct <- rnorm(P, mean = 0, sd = sigma_beta)
names(beta_precinct) <- levels(design$precinct)
# Sobredispersión a nivel observación (OLRE, normal en la escala log)
eps_obs <- rnorm(nrow(design), mean = 0, sd = sigma_epsilon)
# Arrestos del año previo: n_ep ~ Poisson(lambda_arresto) (no negativos)
n_prev <- rpois(nrow(design), lambda = lambda_arresto) %>% pmax(1)
# Tasa esperada de "stops" (en escala log) siguiendo (15.1):
# log E[y_ep] = log( (15/12) * n_ep ) + mu + alpha_e + beta_p + eps_ep
linpred <- log(scale_15m * n_prev) +
mu +
alpha_true[as.integer(design$eth)] +
beta_precinct[as.character(design$precinct)] +
eps_obs
# Respuesta: y_ep ~ Poisson( exp(linpred) )
y <- rpois(nrow(design), lambda = exp(linpred))
# Armamos el data frame final
sim_data <- design %>%
mutate(
n_prev = n_prev,
y = y
)
glimpse(sim_data)Rows: 180
Columns: 5
$ eth <fct> black, black, black, black, black, black, black, black, black…
$ precinct <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18…
$ obs_id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18…
$ n_prev <dbl> 54, 45, 46, 38, 45, 56, 50, 39, 42, 49, 56, 51, 46, 48, 55, 5…
$ y <int> 80, 37, 48, 87, 43, 39, 24, 23, 6, 23, 45, 23, 53, 27, 46, 10…