Este capítulo introduce el ajuste de modelos multinivel en JAGS ejecutados desde R.
6.1 Por qué aprender JAGS
La función lmer() en R permite ajustar modelos multinivel lineales y generalizados con rapidez. Sin embargo, cuando el número de grupos es pequeño o el modelo es complejo, puede haber poca información para estimar con precisión los parámetros de varianza. En esos casos, la inferencia bayesiana mediante JAGS ofrece estimaciones más razonables al promediar sobre la incertidumbre de todos los parámetros.
6.1.1 Estrategia recomendada
Comenzar con regresiones clásicas usando lm() y glm().
Ajustar modelos multinivel con interceptos y pendientes variables mediante lmer().
Ajustar modelos bayesianos completos usando JAGS, obteniendo simulaciones que reflejan la incertidumbre inferencial.
Para modelos grandes o complejos, realizar programación adicional en R.
La rapidez de lmer() facilita la exploración de diferentes especificaciones, mientras que la flexibilidad de JAGS permite comprender los modelos más profundamente. Además, JAGS ofrece un formato abierto que permite expandir los modelos de forma más general.
6.2 Inferencia bayesiana y distribuciones previas
En un modelo multinivel, la dificultad principal radica en estimar simultáneamente el modelo de nivel de datos y el modelo de nivel de grupo. La inferencia bayesiana aborda esto considerando el modelo de nivel de grupo como información previa sobre los parámetros individuales.
6.2.1 Tipos de distribuciones previas
En este contexto, los parámetros suelen tener dos tipos de distribuciones previas:
Modelos de nivel de grupo (típicamente normales o regresiones lineales).
Distribuciones uniformes no informativas.
Estas últimas sirven como punto de partida o referencia en ausencia de información adicional.
6.2.2 Regresión clásica
La regresión clásica y los modelos lineales generalizados son casos particulares de los modelos multinivel, en los que no hay modelo de nivel de grupo. En términos bayesianos, esto equivale a usar distribuciones uniformes no informativas:
donde las distribuciones previas son uniformes para los componentes de \(\beta\) y para \(\sigma_y\) en el intervalo \((0, \infty)\). Para regresión logística:
Aquí, los interceptos de grupo \(\alpha_j\) tienen una distribución normal con media \(\mu_\alpha\) y desviación estándar \(\sigma_\alpha\), denominadas hiperparámetros, que también se estiman a partir de los datos. La distribución previa completa es:
Este modelo emplea una distribución normal bivariante para los parámetros de grupo, con distribuciones previas uniformes independientes sobre los hiperparámetros.
6.2.5 Modelo multinivel con predictores de nivel de grupo
Considere un modelo con un predictor a nivel individual (\(x_i\)) y otro a nivel de grupo (\(u_j\)):
La primera ecuación es el modelo de datos (verosimilitud), y la segunda es el modelo de grupo (prior). Los parámetros \(\alpha_j\) tienen medias esperadas \(\hat{\alpha}_j = \gamma_0 + \gamma_1 u_j\) y desviación estándar \(\sigma_\alpha\), lo que implica que no son intercambiables, pues sus distribuciones previas dependen de \(u_j\).
Alternativamente, puede interpretarse como un modelo con errores de grupo \(\eta_j\) con distribución común \(N(0, \sigma_\alpha^2)\), que representa la variación entre grupos.
6.2.6 Distribuciones previas no informativas
Las distribuciones previas no informativas permiten realizar inferencia bayesiana cuando se dispone de poca información externa. Se consideran modelos de referencia o punto de partida para comparaciones. Sin embargo, si el posterior resultante no tiene sentido o contradice conocimientos previos, el modelo debe modificarse para incluir esa información adicional.
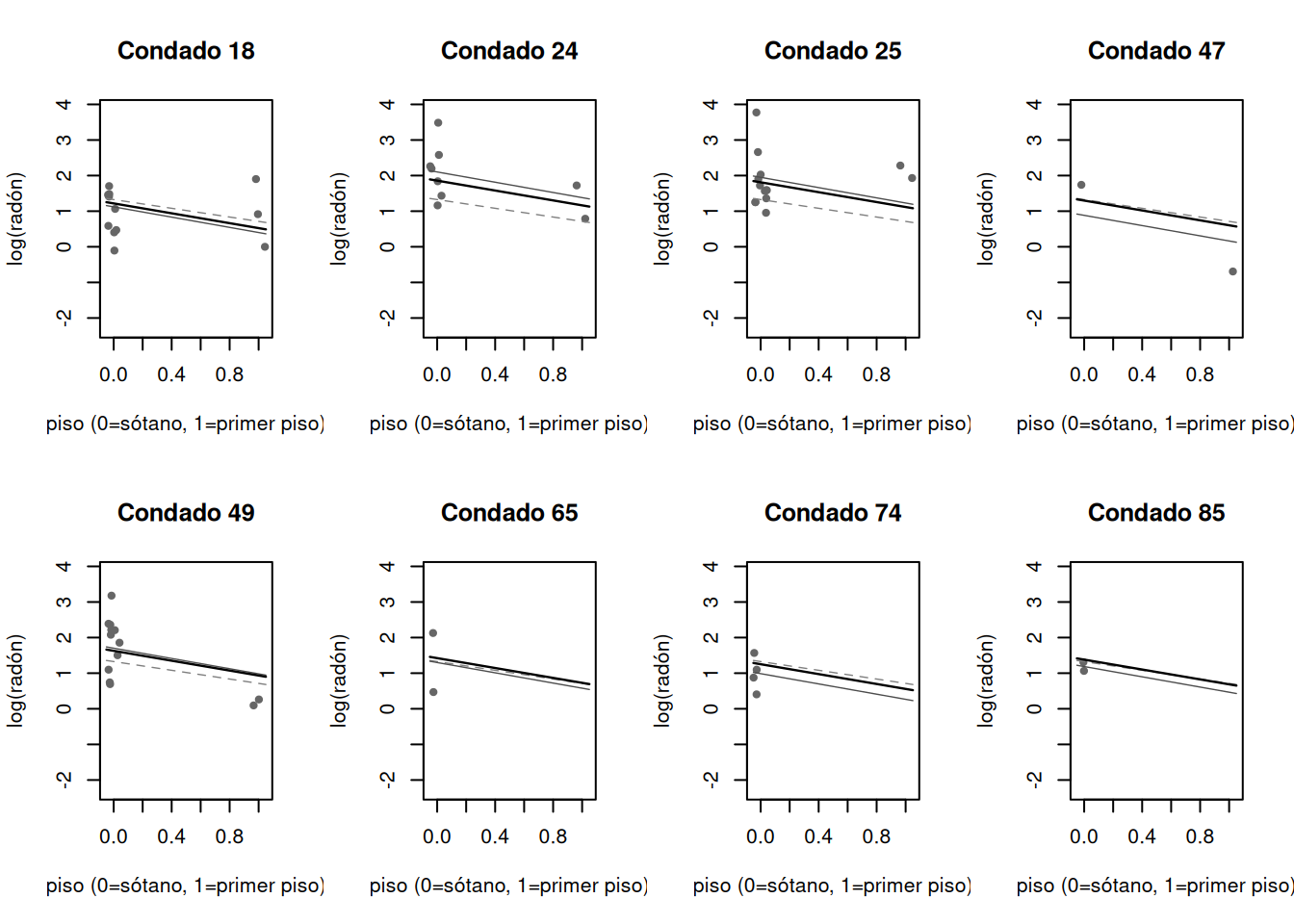
6.3 Ajuste y comprensión de un modelo multinivel de intercepto variable usando R y JAGS
Introducimos JAGS recorriendo el modelo de intercepto variable para niveles logarítmicos de radón. Primero se ajustan modelos clásicos con \(\operatorname{lm}()\), después un ajuste rápido multinivel con \(\operatorname{lmer}()\), y finalmente el modelo multinivel en JAGS llamado desde R.
6.3.1 Preparación de los datos en R
Se cargan mediciones de radón y el piso de medición para 919 viviendas de 85 condados de Minnesota. Por conveniencia, se trabaja con \(\log(\text{radón})\) y se corrige el valor 0.0 a 0.1 antes de aplicar logaritmo.
Indicadores de condado. Se crean índices de condado del 1 al 85.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.2
✔ ggplot2 4.0.0 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(tibble)# Versión tidyverse que respeta la lógica originalsrrs2 <-read.table("../ARM_Data/radon/srrs2.dat", header =TRUE, sep =",")mn <- srrs2$state =="MN"radon <- srrs2$activity[mn]y <-log(ifelse(radon ==0, 0.1, radon))n <-length(radon)x <- srrs2$floor[mn] # 0: sótano, 1: primer pisosrrs2_fips <- srrs2$stfips *1000+ srrs2$cntyfipscounty_name <-as.vector(srrs2$county[mn])uniq_name <-unique(county_name)J <-length(uniq_name)county <-rep(NA_integer_, length(county_name))for (i inseq_len(J)) { county[county_name == uniq_name[i]] <- i}
6.3.2 Regresión clásica con pooling completo en R
Se ajusta una regresión simple ignorando indicadores de condado (pooling completo):
lm.pooled <-lm(y ~ x)summary(lm.pooled)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-3.6293 -0.5383 0.0342 0.5603 2.5486
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.32674 0.02972 44.640 <2e-16 ***
x -0.61339 0.07284 -8.421 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8226 on 917 degrees of freedom
Multiple R-squared: 0.07178, Adjusted R-squared: 0.07077
F-statistic: 70.91 on 1 and 917 DF, p-value: < 2.2e-16
6.3.3 Regresión clásica sin pooling en R
Se incluyen un término constante y 84 indicadores de condado (referencia: condado 1):
lm.unpooled.0<-lm(y ~ x +factor(county))summary(lm.unpooled.0)
Las normales con media 0 y desviación 100 (precisión \(10^{-4}\)) dejan \(\mu_{\alpha}\) y \(\beta\) esencialmente sin información previa en escalas razonables. Las uniformes \((0,100)\) para desviaciones estándar se transforman a precisiones mediante \(\tau=\sigma^{-2}\).
6.5.4 Escala de las previas
Para que una previa sea no informativa, su rango debe exceder claramente el rango razonable de los parámetros. Transformar variables a escalas adecuadas (por ejemplo, logaritmos) ayuda a mantener coeficientes en órdenes de magnitud cercanos a 1 y evita problemas numéricos con previas excesivamente anchas.
6.5.5 Datos, valores iniciales y parámetros (llamada a JAGS con R2jags)
Se corre JAGS con varias cadenas y se descarta la mitad inicial de cada una. Se recomienda comenzar con pocas iteraciones para verificar ejecución y luego aumentar hasta lograr \(\widehat{R}\le 1.1\) para todos los parámetros.
6.5.7\(\widehat{R}\) y \(n_{\text{eff}}\)
Para cada parámetro, \(\widehat{R}\) aproxima la raíz cuadrada entre la varianza combinada de cadenas y la varianza promedio dentro de cadenas; valores significativamente mayores que 1 indican mezcla insuficiente. El tamaño efectivo \(n_{\text{eff}}\) refleja autocorrelación en las cadenas; valores \(\ge 100\) suelen ser deseables.
# Extraer simulaciones como mcmc.list desde el objeto R2jagsmcmc_sims <-as.mcmc(fit_jags)# Diagnóstico con codagelman.diag(mcmc_sims, autoburnin =FALSE)
# (Opcional) Si se dispone de CalvinBayes, mostrar diagnósticos con ese paqueteif (requireNamespace("CalvinBayes", quietly =TRUE)) {# Ejemplo de funciones hipotéticas de CalvinBayes:# CalvinBayes::rhat(mcmc_sims)# CalvinBayes::ess(mcmc_sims)"CalvinBayes disponible: utilice sus funciones de diagnóstico si lo desea."} else {"CalvinBayes no encontrado; se muestran diagnósticos con 'coda'."}
[1] "CalvinBayes disponible: utilice sus funciones de diagnóstico si lo desea."
6.5.8 Acceso y uso de simulaciones
Las simulaciones permiten calcular predicciones e intervalos de incertidumbre para funciones de los parámetros.
# Convertir a matriz posteriorpost_mat <-as.matrix(mcmc_sims)# Intervalo al 90% para bquantile(post_mat[,"b"], probs =c(0.05, 0.95), na.rm =TRUE)
5% 95%
-0.8114550 -0.5755833
# Probabilidad de que el radón promedio (controlando por piso)# sea mayor en el condado 36 que en el 26:a_cols <-grep("^a\\[", colnames(post_mat))prob_36_gt_26 <-mean(post_mat[, paste0("a[", 36, "]")] > post_mat[, paste0("a[", 26, "]")])prob_36_gt_26
[1] 0.9558333
6.5.9 Valores ajustados, residuales y otras cantidades
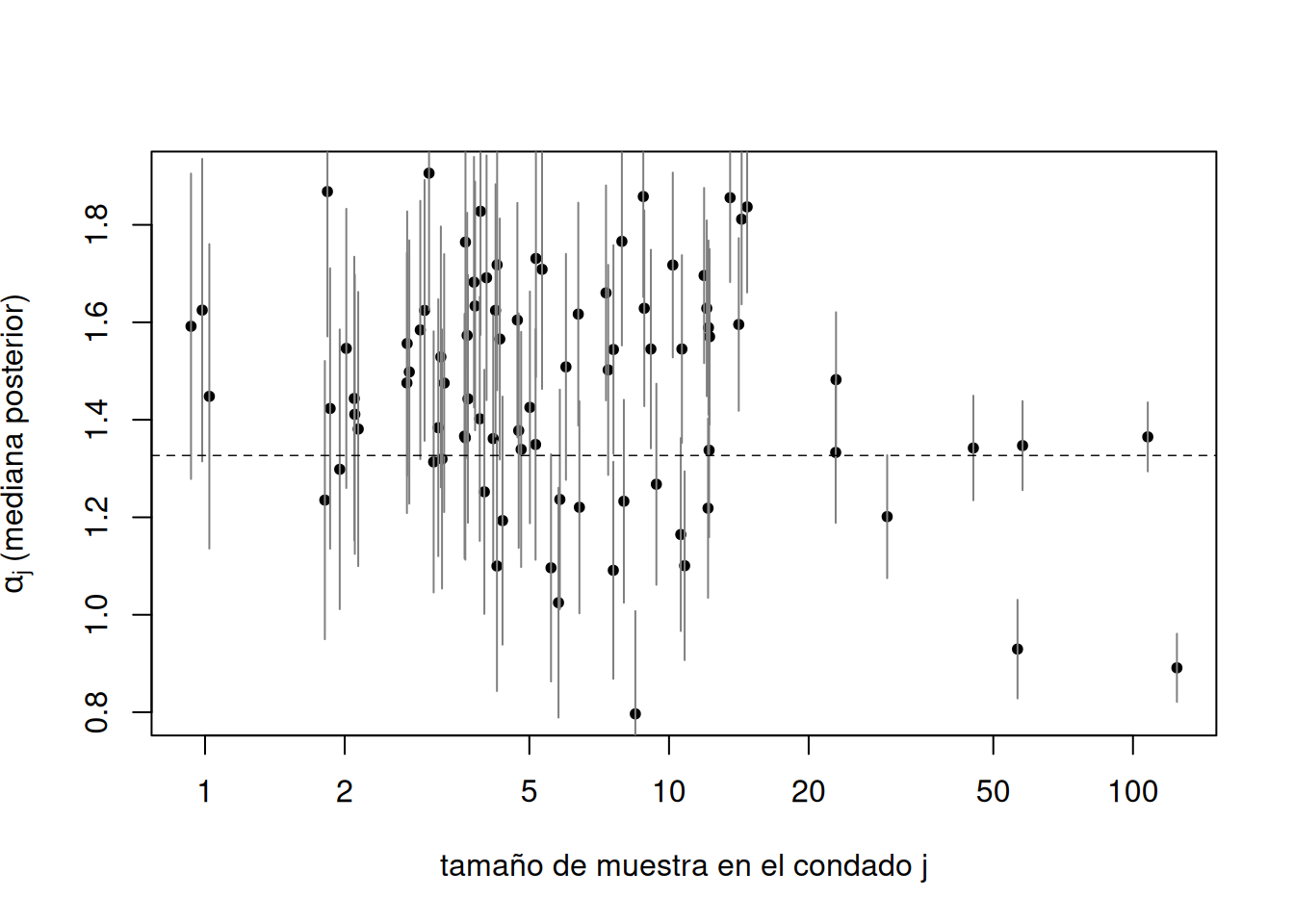
# Medianas posteriores para a[1:J] y ba_med <-apply(post_mat[, a_cols, drop =FALSE], 2, median, na.rm =TRUE)names(a_med) <-paste0("a[", seq_len(J), "]")b_med <-median(post_mat[, "b"], na.rm =TRUE)# Fitted y residuals (con medianas)a_vec <- a_med[paste0("a[", county, "]")]y_hat <- a_vec + b_med * xy_resid <- y - y_hattibble(y_hat = y_hat, y_resid = y_resid) |>head()
# A tibble: 1 × 2
media sd
<dbl> <dbl>
1 3.73 9.41
6.6 Regresiones clásicas con y sin agrupamiento
Los modelos clásicos y de regresión generalizada pueden ajustarse fácilmente en \(R\), aunque también pueden estimarse en JAGS, lo que resulta útil como paso previo a modelos más complejos.
6.6.1 Pooling completo
El modelo de pooling completo es una regresión lineal simple de \(\log(\text{radón})\) sobre el indicador de sótano:
model {
for (i in 1:n){
y[i] ~ dnorm(y_hat[i], tau_y)
y_hat[i] <- a + b * x[i]
}
a ~ dnorm(0, 0.0001)
b ~ dnorm(0, 0.0001)
tau_y <- pow(sigma_y, -2)
sigma_y ~ dunif(0, 100)
}
donde \(y_i = \log(\text{radón}_i)\) y \(x_i\) indica si la medición fue en sótano (\(x=0\)) o primer piso (\(x=1\)).
6.6.2 Sin agrupamiento (No pooling)
El modelo sin agrupamiento se puede ajustar de dos formas: (1) ejecutando regresiones separadas por condado, o (2) permitiendo interceptos \(\alpha_j\) independientes con previas no informativas.
model {
for (i in 1:n){
y[i] ~ dnorm(y_hat[i], tau_y)
y_hat[i] <- a[county[i]] + b * x[i]
}
b ~ dnorm(0, 0.0001)
tau_y <- pow(sigma_y, -2)
sigma_y ~ dunif(0, 100)
for (j in 1:J){
a[j] ~ dnorm(0, 0.0001)
}
}
6.6.3 Regresión clásica con múltiples predictores
El modelo puede ampliarse fácilmente agregando predictores adicionales, como una variable indicadora de invierno (winter).
En cada caso, los coeficientes tienen previas no informativas:
\[
b_k \sim \mathrm{N}(0, 0.0001)
\]
6.6.3.1 Notación vectorial
Puede definirse un vector de coeficientes \(\mathbf{b}\) y una matriz de predictores \(\mathbf{X}\):
y_hat[i] <- a + b[1]*x[i] + b[2]*winter[i] + b[3]*x[i]*winter[i]
for (k in 1:K){
b[k] ~ dnorm(0, 0.0001)
}
Si se desea incluir el intercepto en el vector \(\mathbf{b}\), se añade una columna de unos a \(\mathbf{X}\):
ones <- rep(1, n)
X <- cbind(ones, x, winter, x*winter)
K <- ncol(X)
y en el modelo JAGS:
y_hat[i] <- inprod(b[], X[i, ])
donde los coeficientes corresponden a \(b[1], \ldots, b[4]\).
6.6.4 Modelo multinivel con un predictor a nivel de grupo
El siguiente modelo incluye un predictor a nivel de grupo \(u_j\) (por ejemplo, el nivel de uranio del condado):
model {
for (i in 1:n){
y[i] ~ dnorm(y_hat[i], tau_y)
y_hat[i] <- a[county[i]] + b * x[i]
}
b ~ dnorm(0, 0.0001)
tau_y <- pow(sigma_y, -2)
sigma_y ~ dunif(0, 100)
for (j in 1:J){
a[j] ~ dnorm(a_hat[j], tau_a)
a_hat[j] <- g_0 + g_1 * u[j]
}
g_0 ~ dnorm(0, 0.0001)
g_1 ~ dnorm(0, 0.0001)
tau_a <- pow(sigma_a, -2)
sigma_a ~ dunif(0, 100)
}
donde:
\(a_j\) representa el intercepto del condado \(j\),
\(u_j\) es el predictor del nivel de uranio a nivel de grupo,
\(\sigma_a\) mide la variación entre condados.
6.6.5 Modelo multinivel con un predictor a nivel de grupo en JAGS (ajuste)
En este modelo multinivel, un predictor a nivel de grupo (por ejemplo, los niveles de uranio) influye en los interceptos específicos de cada condado.
A continuación se muestra el modelo equivalente en JAGS, junto con la preparación de los datos en R.
u[j]: predictor a nivel de grupo (por ejemplo, nivel promedio de uranio en cada condado).
a[j]: intercepto específico del condado, influido por el predictor grupal.
g.0, g.1: coeficientes de regresión que describen la relación entre el predictor de grupo y los interceptos del nivel inferior.
Este modelo permite capturar la variación tanto individual como grupal, incorporando información contextual de los grupos (condados) en el análisis.
6.7 Predicción para nuevas observaciones y nuevos grupos
6.7.1 Conceptos Principales
En modelos jerárquicos bayesianos, la predicción puede realizarse de dos formas:
Dentro de JAGS: agregando observaciones nuevas (con valores NA) directamente al modelo.
Desde R: usando las simulaciones de los parámetros obtenidos para generar distribuciones predictivas.
La predicción en un grupo existente utiliza los efectos aleatorios estimados de dicho grupo, mientras que la predicción en un nuevo grupo requiere simular nuevos efectos aleatorios basados en la distribución de segundo nivel.
6.7.2 Predicción de una nueva unidad en un nuevo grupo
A continuación, se presenta la extensión del conjunto de datos para incluir una nueva vivienda en un condado ya existente (condado 26).
# Extender el conjunto de datos para una nueva observación en un grupo existenten <- n +1y <-c(y, NA)county <-c(county, 26)x <-c(x, 1)
La predicción se realiza dentro del modelo JAGS agregando la línea:
# JAGS code
y.tilde <- y[n]
El modelo puede ejecutarse en R con R2jags y CalvinBayes como sigue:
data_jags_pred <-list(y = y, x = x, county = county, n = n, J = J)jags_model3 <-jags(model.file ="codigoJAGS/radon_model_pred1.jags",data = data_jags_pred,parameters.to.save =c("a", "b", "mu.a", "sigma.y", "sigma.a", "y.tilde"),n.iter =3000, n.burnin =1000, n.thin =2 )
Compiling model graph
Resolving undeclared variables
Allocating nodes
Graph information:
Observed stochastic nodes: 919
Unobserved stochastic nodes: 90
Total graph size: 3005
Initializing model
Posteriormente, se resumen las simulaciones obtenidas para la predicción:
library(CalvinBayes)
Loading required package: ggformula
Loading required package: scales
Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
Loading required package: ggiraph
Loading required package: ggridges
New to ggformula? Try the tutorials:
learnr::run_tutorial("introduction", package = "ggformula")
learnr::run_tutorial("refining", package = "ggformula")
Loading required package: bayesplot
This is bayesplot version 1.14.0
- Online documentation and vignettes at mc-stan.org/bayesplot
- bayesplot theme set to bayesplot::theme_default()
* Does _not_ affect other ggplot2 plots
* See ?bayesplot_theme_set for details on theme setting
Attaching package: 'CalvinBayes'
The following object is masked from 'package:bayesplot':
rhat
The following object is masked from 'package:datasets':
HairEyeColor
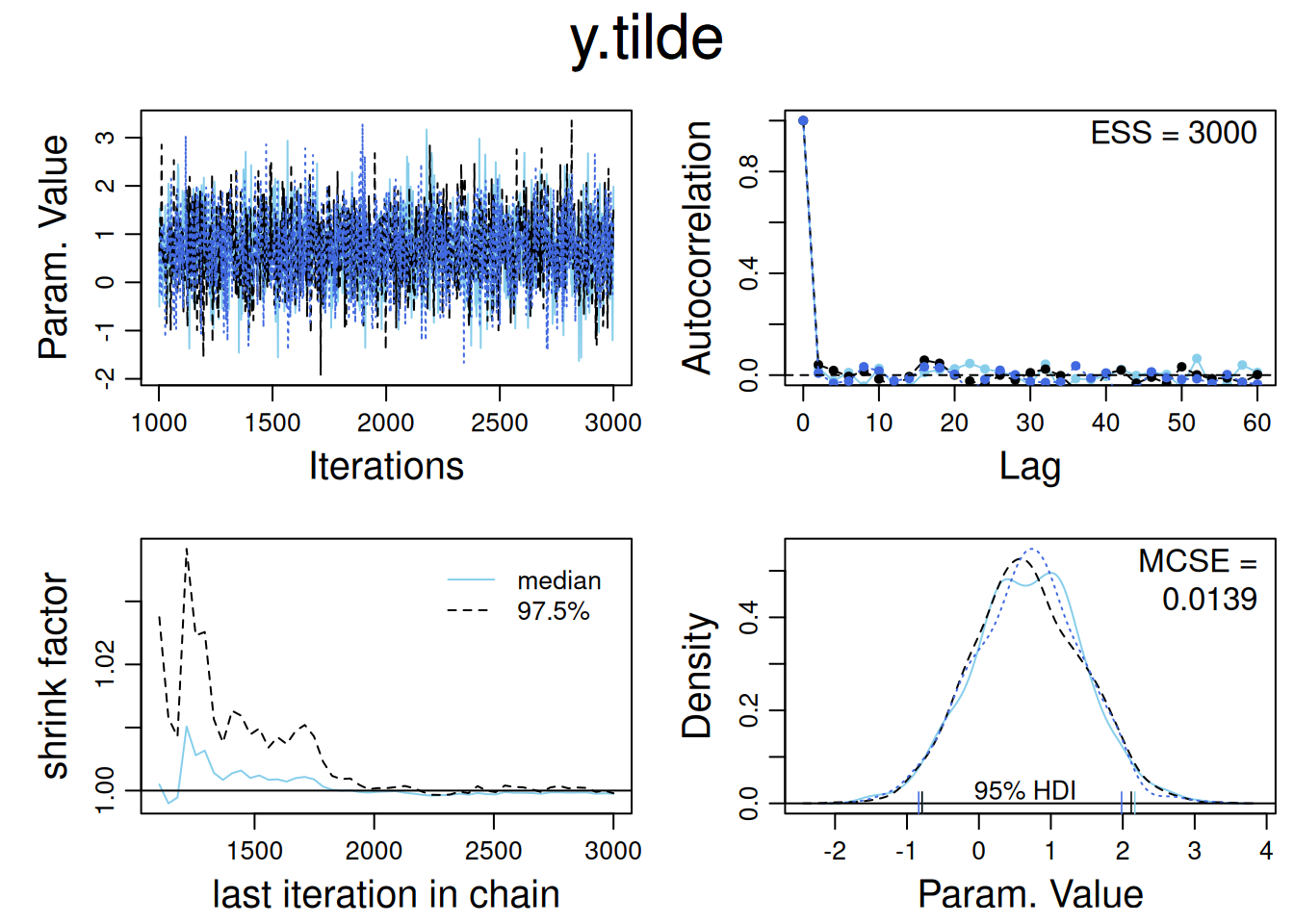
jags_model3_mcmc <-as.mcmc(jags_model3)# Diagnóstico y resumen de la prediccióndiag_mcmc(jags_model3_mcmc, parName ="y.tilde")
6.7.3 Predicción de una nueva unidad en un nuevo grupo
Para un grupo sin datos previos (nuevo condado), se define un predictor grupal promedio y se amplía el conjunto de datos:
# Definir predictor a nivel de grupo para el nuevo condadou.tilde <-mean(u)# Extender el conjunto de datos para incluir un nuevo condadon <- n +1y <-c(y, NA)county <-c(county, J +1)x <-c(x, 1)J <- J +1u <-c(u, u.tilde)data_jags_pred2 <-list(y = y, x = x, county = county, n = n, J = J, u = u)jags_model4 <-jags(model.file ="codigoJAGS/radon_model_pred2.jags",data = data_jags_pred2,parameters.to.save =c("a", "b", "mu.a", "sigma.y", "sigma.a", "y.tilde"),n.iter =3000, n.burnin =1000, n.thin =2 )
Compiling model graph
Resolving undeclared variables
Allocating nodes
Graph information:
Observed stochastic nodes: 919
Unobserved stochastic nodes: 94
Total graph size: 3270
Initializing model
En casi cualquier aplicación, es recomendable comenzar con modelos simples en R (por ejemplo, regresiones con pooling completo o sin pooling), y luego replicarlos en JAGS. El propósito de este paso inicial es verificar que los estimadores y errores estándar sean similares entre ambos enfoques.
Posteriormente, se debe aumentar gradualmente la complejidad del modelo, incorporando estructuras multinivel, predictores a nivel de grupo, pendientes variables o estructuras no anidadas. Esto no solo favorece la interpretación estadística, sino que también facilita la depuración de errores computacionales.
Generalmente, intentar programar un modelo demasiado complejo desde el inicio conduce a fallas en la ejecución. En tales casos, es mejor volver a versiones más simples hasta lograr una ejecución estable.
Si un modelo no se ejecuta correctamente, puede utilizarse la opción debug = TRUE en la llamada a JAGS, lo que mantiene abierta la ventana de JAGS para inspeccionar los errores.
6.8.2 Número de cadenas y longitud de las simulaciones
Normalmente se ejecutan tres cadenas (n.chains = 3). La decisión sobre cuántas iteraciones correr depende del equilibrio entre velocidad y convergencia.
Un flujo de trabajo típico es:
Ejecutar el modelo con pocas iteraciones en modo depuración (debug = TRUE) para garantizar que el script funcione.
Realizar una corrida corta, por ejemplo, con n.iter = 100 o n.iter = 500.
Evaluar el criterio de convergencia de Gelman-Rubin (\(\widehat{R}\)):
Si \(\widehat{R} < 1.1\) para todos los parámetros, se puede detener la simulación.
Si \(\widehat{R} < 1.5\), se recomienda continuar con un número mayor de iteraciones (por ejemplo, 1000 o 2000).
Si las cadenas no convergen tras varios minutos, se deben considerar alternativas como:
Simplificar el modelo,
Ajustar el modelo con una muestra reducida de los datos,
Mejorar la eficiencia del código JAGS.
En modelos muy complejos, puede ser necesario ejecutar decenas de miles de iteraciones. Sin embargo, esta estrategia de “fuerza bruta” no es recomendable durante la etapa de construcción del modelo, ya que ralentiza la experimentación y el refinamiento.
6.8.3 Valores iniciales (Initial values)
La función jags() acepta el argumento inits, que define una función encargada de generar los valores iniciales para cada cadena MCMC.
Aunque no es crítico cuáles sean estos valores exactos, es importante que:
estén dispersos (cada cadena comience en una región diferente del espacio de parámetros), y
sean razonables, evitando valores extremos como \(10^{-4}\) o \(10^{6}\) que pueden hacer que el algoritmo diverja.
Es común definir los valores iniciales como funciones con números aleatorios, garantizando así diversidad entre cadenas. Generalmente se utilizan distribuciones normales estándar \(\mathcal{N}(0,1)\) para parámetros no restringidos y distribuciones uniformes \(\text{Uniform}(0,1)\) para parámetros que deben ser positivos.
6.8.4 Ejemplo de especificación básica de valores iniciales
Si se desea usar una distribución \(\mathcal{N}(0, 2^2)\) para los parámetros normales y una distribución \(\text{Uniform}(0.1, 10)\) para los parámetros positivos:
Este enfoque permite generar diferentes condiciones iniciales de forma automática al iniciar múltiples cadenas, promoviendo una exploración más completa del espacio de parámetros y ayudando a evaluar la convergencia de manera confiable.