En esta sección se aborda el tema de la regresión logística multinivel, aplicada al análisis de encuestas políticas en los Estados Unidos. El objetivo es modelar la probabilidad de que un individuo apoye a un candidato republicano en función de características demográficas y geográficas, utilizando una estructura jerárquica que permite capturar la variabilidad entre estados y grupos de individuos.
8.1.1 Preparación de los datos
Se utilizan datos de encuestas y resultados electorales previos para construir el modelo. A continuación se muestra el código de preparación de datos, adaptado al entorno tidyverse.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.2
✔ ggplot2 4.0.0 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(arm)
Loading required package: MASS
Attaching package: 'MASS'
The following object is masked from 'package:dplyr':
select
Loading required package: Matrix
Attaching package: 'Matrix'
The following objects are masked from 'package:tidyr':
expand, pack, unpack
Loading required package: lme4
arm (Version 1.14-4, built: 2024-4-1)
Working directory is /home/lbarboza/Dropbox/Cursos/Actuales/SP1653_2025/NotasClase/ModelosMixtos
Cada observación \(y_i\) indica el voto del encuestado:
\(y_i = 1\): apoyo al candidato republicano.
\(y_i = 0\): apoyo al candidato demócrata.
Se modela la probabilidad de apoyo mediante una función logística:
\[
\Pr(y_i = 1) = \text{logit}^{-1}(X_i \beta)
\]
donde \(X_i\) representa los predictores demográficos y geográficos. Las observaciones se asumen independientes condicionalmente al conjunto de efectos aleatorios.
8.1.3 Modelo logístico multinivel simple
Este modelo considera dos predictores individuales (female y black) y un intercepto que varía por estado:
The following object is masked from 'package:arm':
rescale
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
Loading required package: ggiraph
Loading required package: ggridges
New to ggformula? Try the tutorials:
learnr::run_tutorial("introduction", package = "ggformula")
learnr::run_tutorial("refining", package = "ggformula")
Loading required package: bayesplot
This is bayesplot version 1.14.0
- Online documentation and vignettes at mc-stan.org/bayesplot
- bayesplot theme set to bayesplot::theme_default()
* Does _not_ affect other ggplot2 plots
* See ?bayesplot_theme_set for details on theme setting
Attaching package: 'CalvinBayes'
The following object is masked from 'package:bayesplot':
rhat
The following object is masked from 'package:datasets':
HairEyeColor
En la parte logística del modelo, la distribución de los datos se representa mediante una binomial con \(N=1\), lo que implica que \(y_i = 1\) con probabilidad \(p_i\) y \(0\) en caso contrario. Para asegurar que \(p_i\) permanezca entre 0 y 1, se define una restricción de borde (p.bound). El modelo incorpora una formulación multinivel completa, con bucles anidados que controlan las interacciones edad-educación.
Aunque este modelo puede ser lento en converger debido a su parametrización, conserva la estructura fundamental útil para la interpretación conceptual y puede mejorarse posteriormente mediante reparametrización (ver Sección 19.4 del texto base).
8.2 Modelo Logístico con params. redundantes
8.2.1 Ajuste del modelo con parámetros redundantes
#rm(y)attach(polls.subset)
The following object is masked _by_ .GlobalEnv:
state
The following objects are masked from polls.subset (pos = 9):
age, age.edu, black, edu, female, org, region.full, state, survey,
v.prev.full, weight, y, year
The following object is masked from package:MASS:
survey
# Prepare data for JAGSdata_jags <-list(y = y,female = female,black = black,age = age,edu = edu,state = state,region = region,v.prev = v.prev,n =length(y),n.age =length(unique(age)),n.edu =length(unique(edu)),n.state =length(unique(state)),n.region =length(unique(region)))# Initial values for the parametersinits <-function() {list(b.0 =rnorm(1),b.female =rnorm(1),b.black =rnorm(1),b.female.black =rnorm(1),b.age =rnorm(data_jags$n.age),b.edu =rnorm(data_jags$n.edu),b.age.edu =matrix(rnorm(data_jags$n.age * data_jags$n.edu), nrow = data_jags$n.age),b.state =rnorm(data_jags$n.state),b.region =rnorm(data_jags$n.region),b.v.prev =rnorm(1),sigma.age =runif(1, 0, 100),sigma.edu =runif(1, 0, 100),sigma.age.edu =runif(1, 0, 100),sigma.state =runif(1, 0, 100),sigma.region =runif(1, 0, 100),mu.age =rnorm(1),mu.edu =rnorm(1),mu.age.edu =rnorm(1),mu.region =rnorm(1) )}# Parameters to monitorparams <-c("mu.adj", "b.0", "b.female", "b.black", "b.female.black", "b.age.adj", "b.edu.adj", "b.age.edu.adj", "b.state", "b.region.adj", "b.v.prev", "sigma.age", "sigma.edu", "sigma.age.edu", "sigma.state", "sigma.region", "mu.age", "mu.edu", "mu.age.edu", "mu.region")# Fit the model with JAGSjags_fit <-jags(data = data_jags, inits = inits, parameters.to.save = params, model.file ="codigoJAGS/logistic_centered.jags", # Replace with the actual model file namen.chains =3, n.iter =5000, n.burnin =1000, n.thin =10)
Compiling model graph
Resolving undeclared variables
Allocating nodes
Graph information:
Observed stochastic nodes: 2015
Unobserved stochastic nodes: 270
Total graph size: 17254
Initializing model
8.2.2 Estimación de la opinión promedio por estado usando inferencias del modelo
8.2.2.1 Panorama general
El modelo de regresión logística ofrece una forma de estimar la probabilidad de que cualquier adulto de un grupo demográfico y estado dados prefiera a Bush. Usando estas probabilidades, podemos calcular promedios ponderados para estimar la proporción de simpatizantes de Bush en distintos subconjuntos de la población.
Preparación de datos
Usando datos del Censo de EE. UU., creamos un conjunto de 3264 celdas (cruces de demografía y estados) donde cada celda representa una combinación única de: — Sexo — Etnicidad — Edad — Nivel educativo — Estado.
Cada celda contiene el número de personas que encajan en esa combinación, almacenado en el data frame census.
Cálculo del apoyo esperado a Bush (y.pred)
Tras ajustar el modelo en JAGS y obtener n.sims réplicas simuladas, calculamos y.pred, la probabilidad predicha de apoyar a Bush para cada celda demográfica en cada simulación.
# Suponemos que `census` contiene la información demográfica y de estado por celdalibrary (foreign)library(tidyverse)census <-read.dta ("../ARM_Data/election88/census88.dta")census <- census %>%filter(state <=49)attach.jags(jags_fit)L <-nrow(census) # Número de celdas del censoy.pred <-array(NA, c(n.sims, L)) # Matriz para almacenar prediccionesfor (l in1:L) { y.pred[, l] <-invlogit( b.0+ b.female * census$female[l] + b.black * census$black[l] + b.female.black * census$female[l] * census$black[l] + b.age.adj[, census$age[l]] + b.edu.adj[, census$edu[l]] + b.age.edu.adj[, census$age[l], census$edu[l]] + b.state[, census$state[l]] )}
8.2.3 Estimación del apoyo promedio por estado
Para cada estado \(j\), estimamos la respuesta promedio tomando una suma ponderada de las predicciones a lo largo de las 64 categorías demográficas dentro del estado. Este promedio ponderado refleja la proporción esperada de simpatizantes de Bush en cada estado.
El promedio ponderado para el estado \(j\) se calcula como:
— \(N_l\) es el conteo poblacional del grupo demográfico \(l\) en el estado \(j\). — \(\theta_l\) es la probabilidad predicha de apoyo a Bush para el grupo \(l\).
n.state <-max(census$state) # Número de estados# Arreglo para almacenar predicciones a nivel de estadoy.pred.state <-array(NA, c(n.sims, n.state))# Promedios ponderados por estado de las prediccionesfor (s in1:n.sims) {for (j in1:n.state) { ok <- census$state == j # Celdas correspondientes al estado j y.pred.state[s, j] <-sum(census$N[ok] * y.pred[s, ok]) /sum(census$N[ok]) }}
8.2.4 Resumen de las predicciones por estado
Para cada estado, calculamos un estimador puntual y un intervalo de predicción del 50% a partir de las n.sims simulaciones. Esto resume la proporción de adultos en cada estado que se predice que apoyan a Bush.
# Arreglo para almacenar estadísticas resumidasstate.pred <-array(NA, c(3, n.state))# Cálculo del intervalo 50% (25–75) y la mediana para cada estadofor (j in1:n.state) { state.pred[, j] <-quantile(y.pred.state[, j], c(0.25, 0.5, 0.75))}
8.2.5 Interpretación
El objeto state.pred contiene: — El percentil 25 (límite inferior del intervalo 50%), — La mediana (predicción puntual) y — El percentil 75 (límite superior del intervalo 50%) de la proporción de adultos en cada estado que apoyaron a Bush. Estas estimaciones incorporan la variación demográfica dentro de cada estado y brindan información sobre el nivel predicho de apoyo por estado.
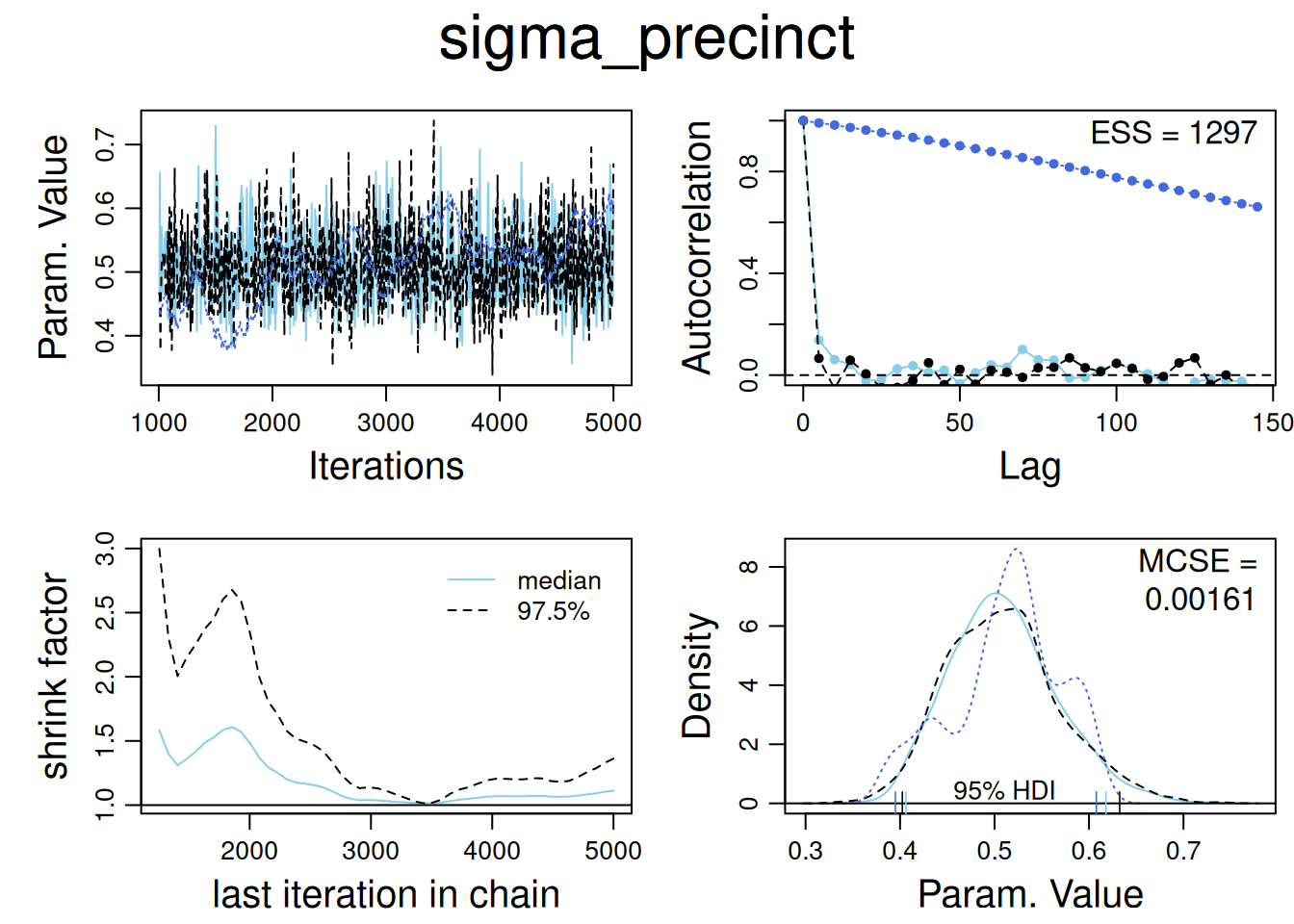
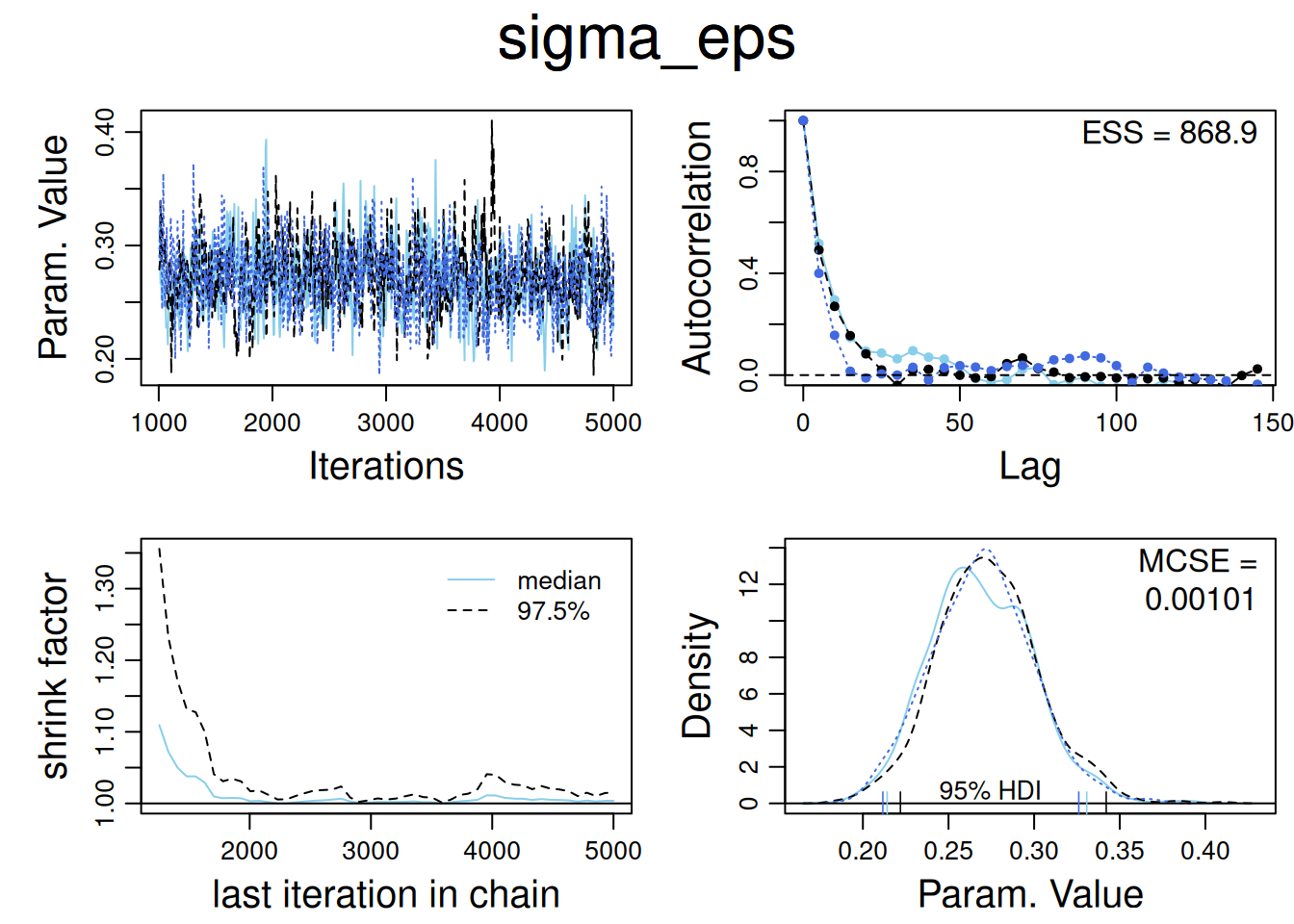
8.3 Modelo Poisson con sobredispersión en JAGS
8.3.1 Contexto general
El estudio analiza tasas de detenciones policiales en Nueva York diferenciadas por grupo étnico y precinto policial, permitiendo:
Efectos cruzados entre etnia y precinto (no anidados).
Un componente de sobredispersión a nivel observación.
Un offset logarítmico proporcional al número de arrestos del año previo, escalado a 15 meses.
Cada observación \((e,p)\) representa una combinación entre grupo étnico \(e\) y precinto \(p\). La variable respuesta \(y_{ep}\) es el número de detenciones en ese grupo y área.
\(\epsilon_{ep}\): término de sobredispersión a nivel observación.
\(\log\left(\frac{15}{12}n_{ep}\right)\) actúa como offset fijo (conocido).
8.3.3 Preparación de los datos en R
Simulación de los datos acorde al modelo descrito:
set.seed(5454) # para reproducibilidad# Parámetros "verdaderos" de la simulaciónE <-3# etniasP <-60# precintosmu <--1.0# intercepto en la escala logalpha_true <-c( 0.40, 0.10, -0.50 ) # efectos por etnia: blacks, hispanics, whites (suma != 0, luego centraremos)sigma_beta <-0.50# sd entre precintossigma_epsilon <-0.30# sd de sobredispersión (log-escala)lambda_arresto <-50# media base de arrestos por celda (antes de escalado)scale_15m <-15/12# factor de 15 meses# Diseño completo (todas las combinaciones etnia-precinto)design <-expand_grid(eth =factor(1:E, labels =c("black","hispanic","white")),precinct =factor(1:P)) %>%# Asignamos un ID único por observación (para OLRE)mutate(obs_id =row_number())# Efectos aleatorios por precintobeta_precinct <-rnorm(P, mean =0, sd = sigma_beta)names(beta_precinct) <-levels(design$precinct)# Sobredispersión a nivel observación (OLRE, normal en la escala log)eps_obs <-rnorm(nrow(design), mean =0, sd = sigma_epsilon)# Arrestos del año previo: n_ep ~ Poisson(lambda_arresto) (no negativos)n_prev <-rpois(nrow(design), lambda = lambda_arresto) %>%pmax(1)# Tasa esperada de "stops" (en escala log) siguiendo (15.1):# log E[y_ep] = log( (15/12) * n_ep ) + mu + alpha_e + beta_p + eps_eplinpred <-log(scale_15m * n_prev) + mu + alpha_true[as.integer(design$eth)] + beta_precinct[as.character(design$precinct)] + eps_obs# Respuesta: y_ep ~ Poisson( exp(linpred) )y <-rpois(nrow(design), lambda =exp(linpred))# Armamos el data frame finalsim_data <- design %>%mutate(n_prev = n_prev,y = y )glimpse(sim_data)