En este capítulo se introduce la regresión lineal múltiple en el contexto de series de tiempo, así como métodos de selección de modelos y técnicas de análisis exploratorio. Se consideran el tratamiento de series no estacionarias (por ejemplo, mediante detrending o diferenciación), la estabilización de varianza y el suavizamiento no paramétrico.
2.1 Regresión clásica en series de tiempo
Se asume una serie dependiente \(x_t\) influida por series independientes \(z_{t1}, z_{t2}, \ldots, z_{tq}\):
# Mostrar explícitamente el mejor modelo según BIC (el de menor BIC)mejor <- bic_tbl %>%slice_min(BIC, n =1)cat("Mejor modelo según BIC:", mejor$modelo, "\nBIC:", mejor$BIC, "\n")
Mejor modelo según BIC: (2.21) Trend + Temp + Temp^2 + Part
BIC: 4.771699
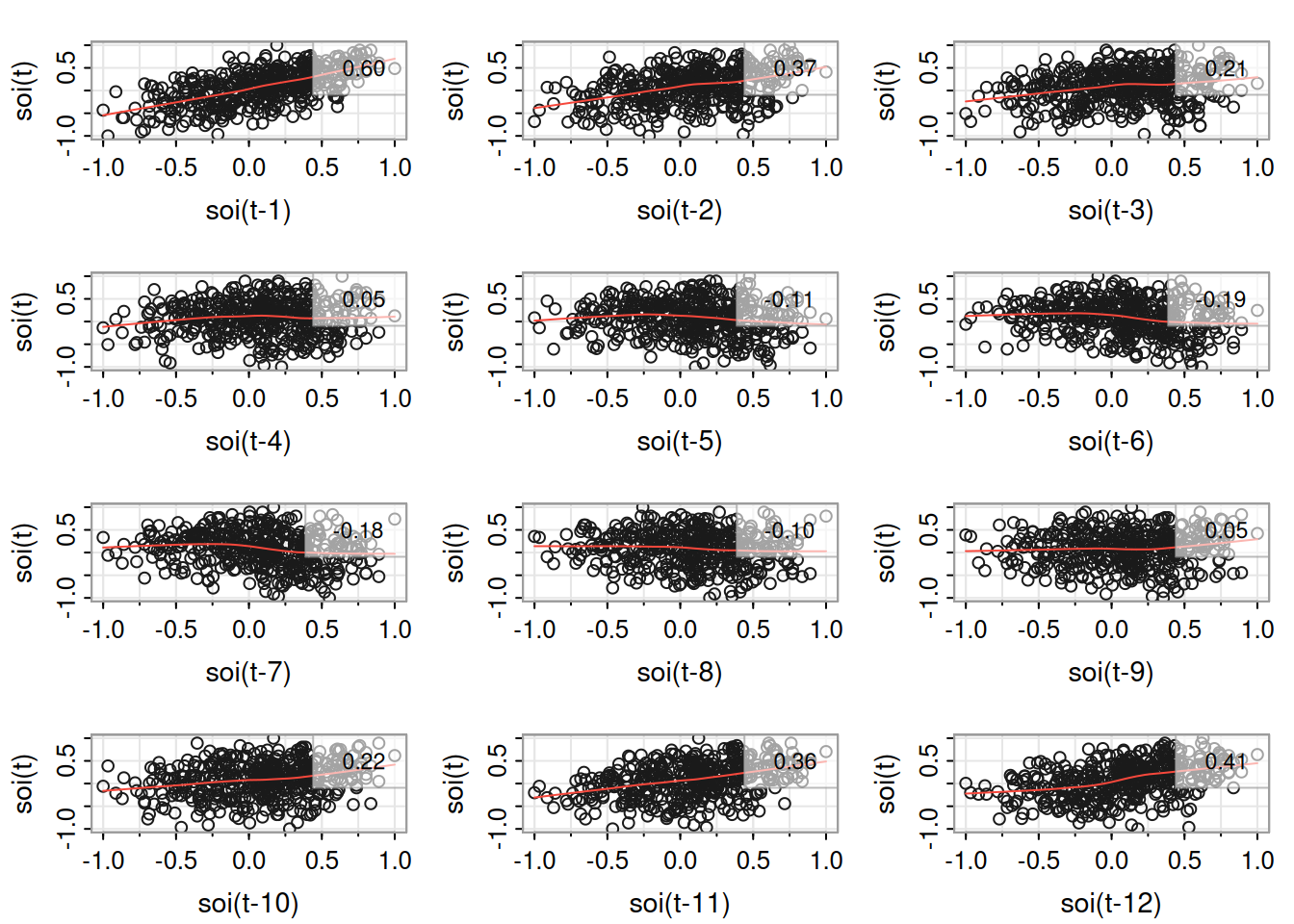
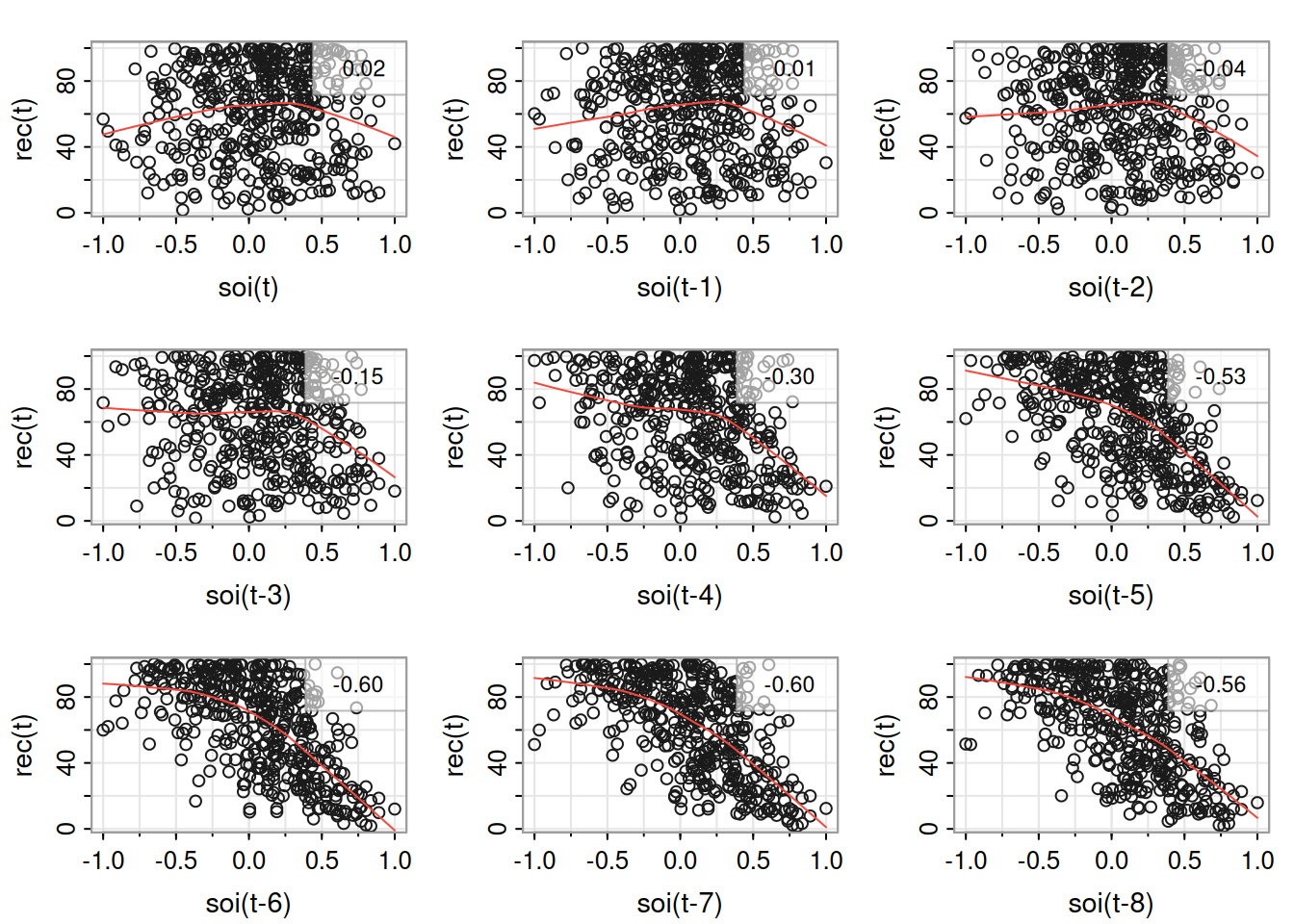
fish <-ts.intersect(rec, soiL6=stats::lag(soi,-6), dframe=TRUE)summary(fit1 <-lm(rec ~ soiL6, data=fish, na.action=NULL))
Call:
lm(formula = rec ~ soiL6, data = fish, na.action = NULL)
Residuals:
Min 1Q Median 3Q Max
-65.187 -18.234 0.354 16.580 55.790
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 65.790 1.088 60.47 <2e-16 ***
soiL6 -44.283 2.781 -15.92 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 22.5 on 445 degrees of freedom
Multiple R-squared: 0.3629, Adjusted R-squared: 0.3615
F-statistic: 253.5 on 1 and 445 DF, p-value: < 2.2e-16
library(dynlm)
Loading required package: zoo
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
summary(fit2 <-dynlm(rec ~L(soi,6)))
Time series regression with "ts" data:
Start = 1950(7), End = 1987(9)
Call:
dynlm(formula = rec ~ L(soi, 6))
Residuals:
Min 1Q Median 3Q Max
-65.187 -18.234 0.354 16.580 55.790
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 65.790 1.088 60.47 <2e-16 ***
L(soi, 6) -44.283 2.781 -15.92 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 22.5 on 445 degrees of freedom
Multiple R-squared: 0.3629, Adjusted R-squared: 0.3615
F-statistic: 253.5 on 1 and 445 DF, p-value: < 2.2e-16
2.2 Análisis exploratorio de datos en series de tiempo
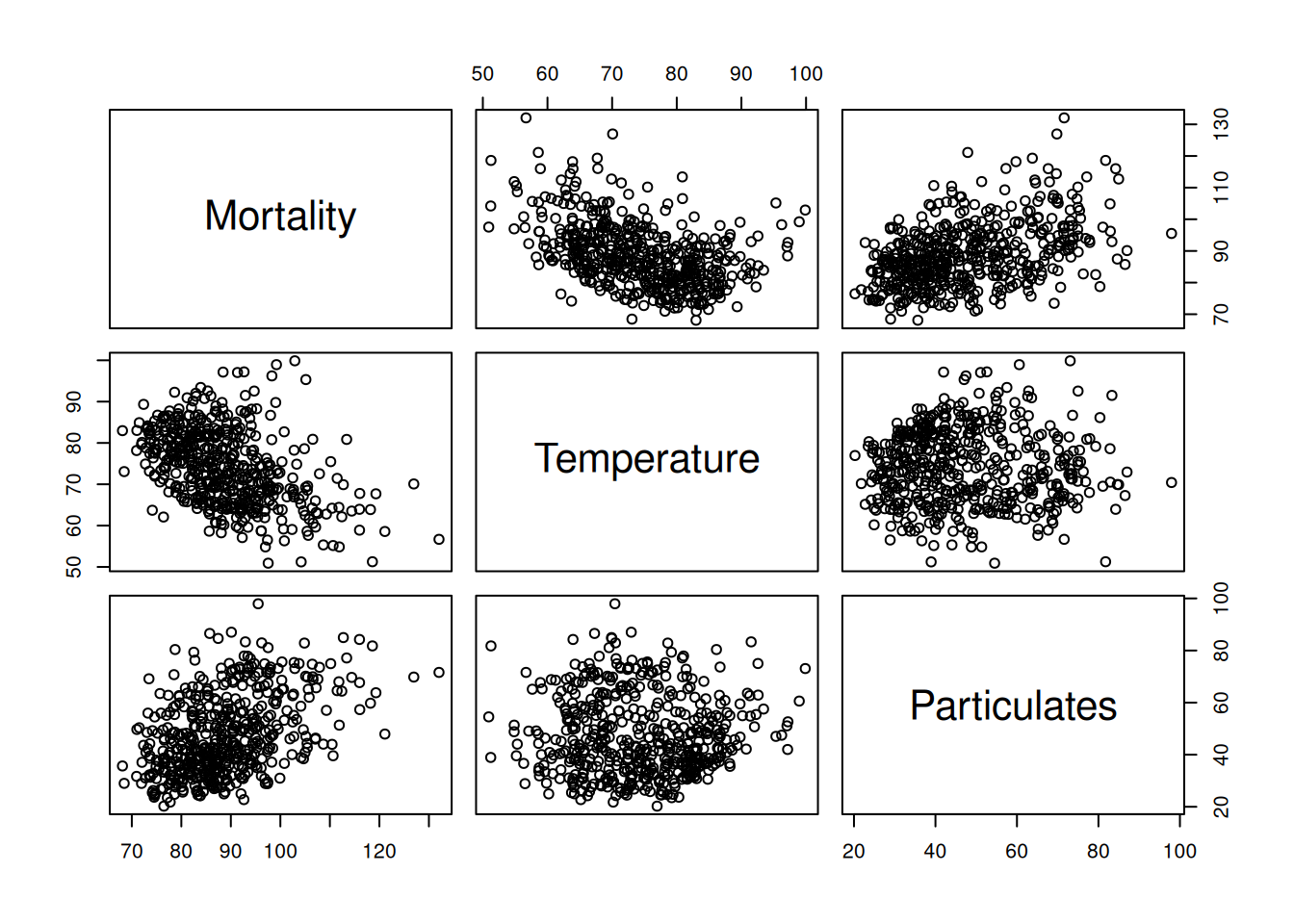
En esta sección se estudian técnicas de análisis exploratorio de datos en series de tiempo, con énfasis en la necesidad de estacionariedad para aplicar métodos estadísticos significativos. Se presentan procedimientos para eliminar tendencias, aplicar diferencias, utilizar el operador de rezago, realizar transformaciones, explorar relaciones no lineales mediante matrices de dispersión, y detectar señales periódicas usando regresión.
2.2.1 Estacionariedad y modelo con tendencia
Para realizar inferencia en series de tiempo es crucial que, al menos en un intervalo, las funciones de media y autocovarianza sean estacionarias. Cuando no lo son, se utiliza el modelo con tendencia estacionaria:
\[
x_{t} = \mu_{t} + y_{t}
\]
donde \(\mu_{t}\) es la tendencia y \(y_{t}\) es estacionario. Se estima \(\hat{\mu}_{t}\) y se define el residual:
\[
\hat{y}_{t} = x_{t} - \hat{\mu}_{t}
\]
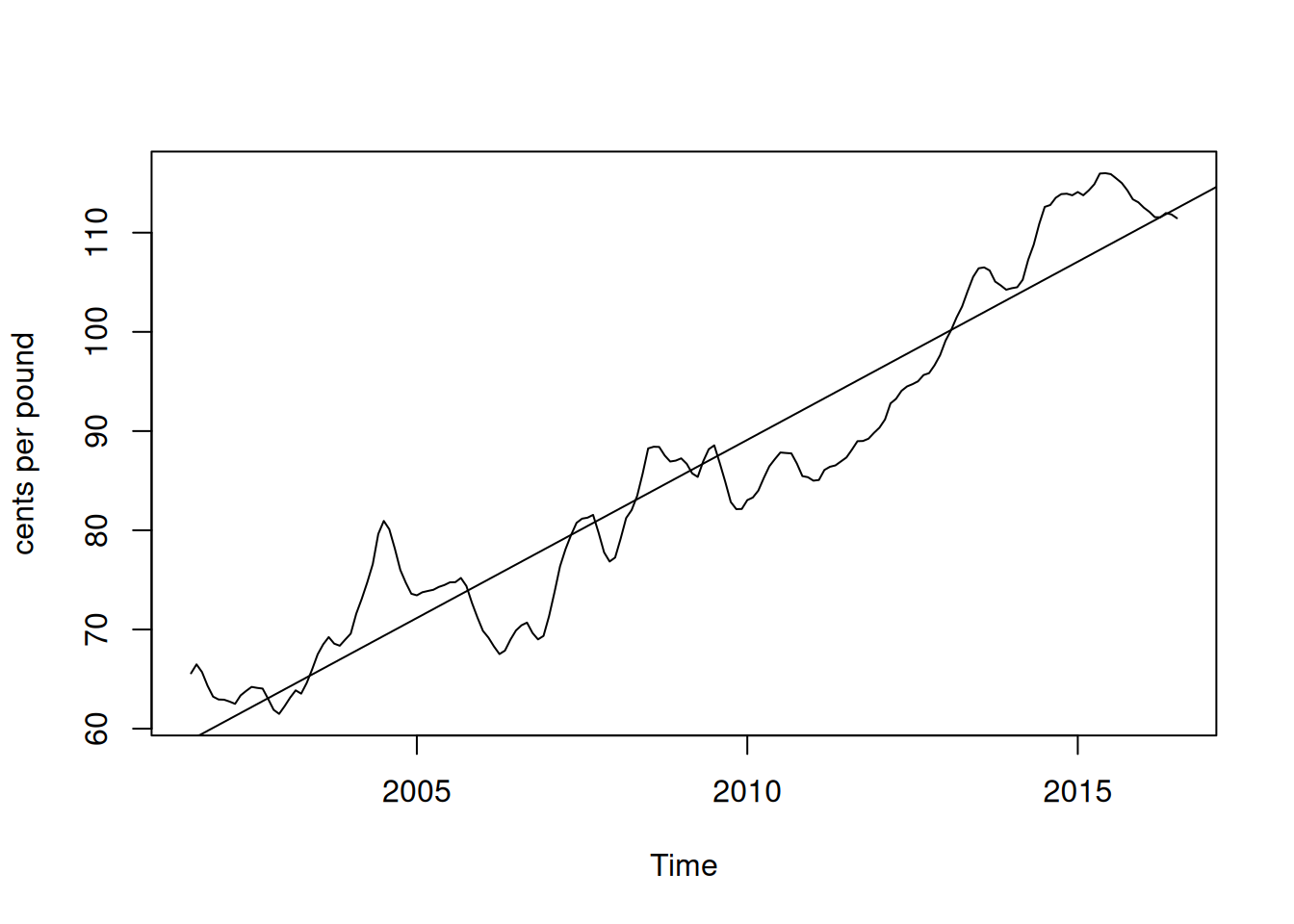
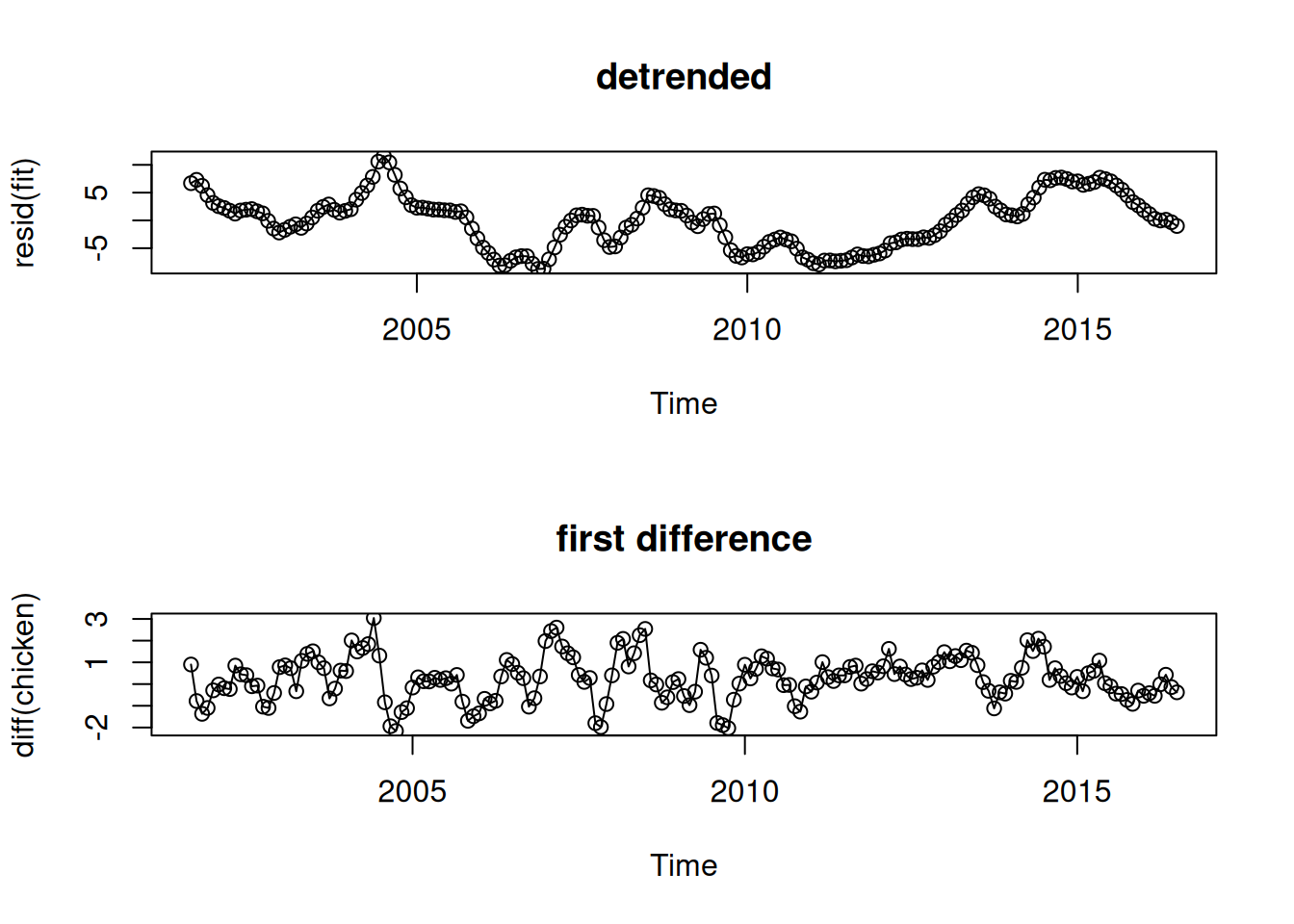
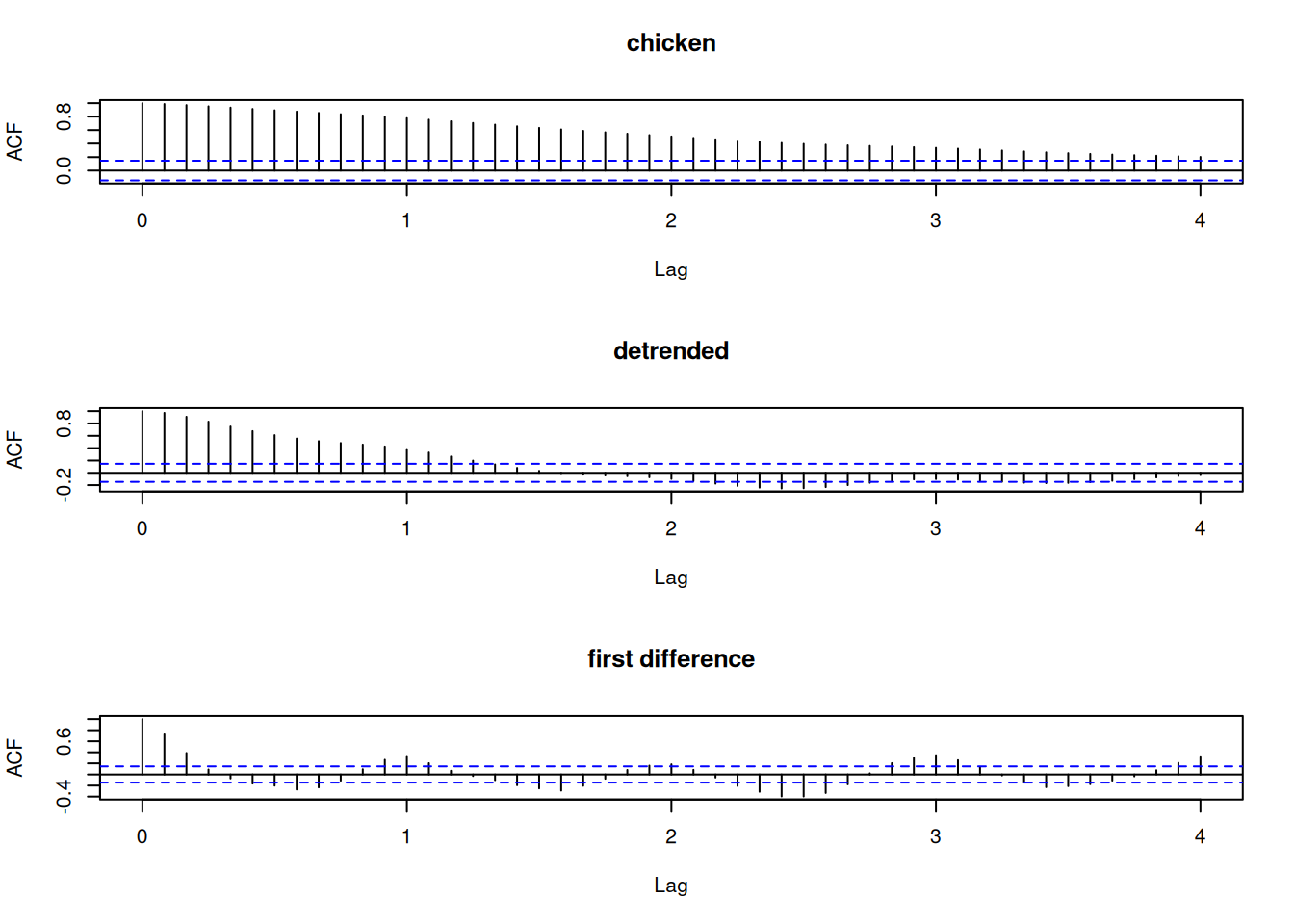
2.2.1.1 Ejemplo: Eliminación de tendencia en precios de pollo
Se plantea \(\mu_{t} = \beta_{0} + \beta_{1} t\). Usando mínimos cuadrados se obtiene:
2.2.2.1 Ejemplo: Diferenciación de precios de pollo
La primera diferencia elimina el ciclo de 5 años, revelando un ciclo anual en el ACF.
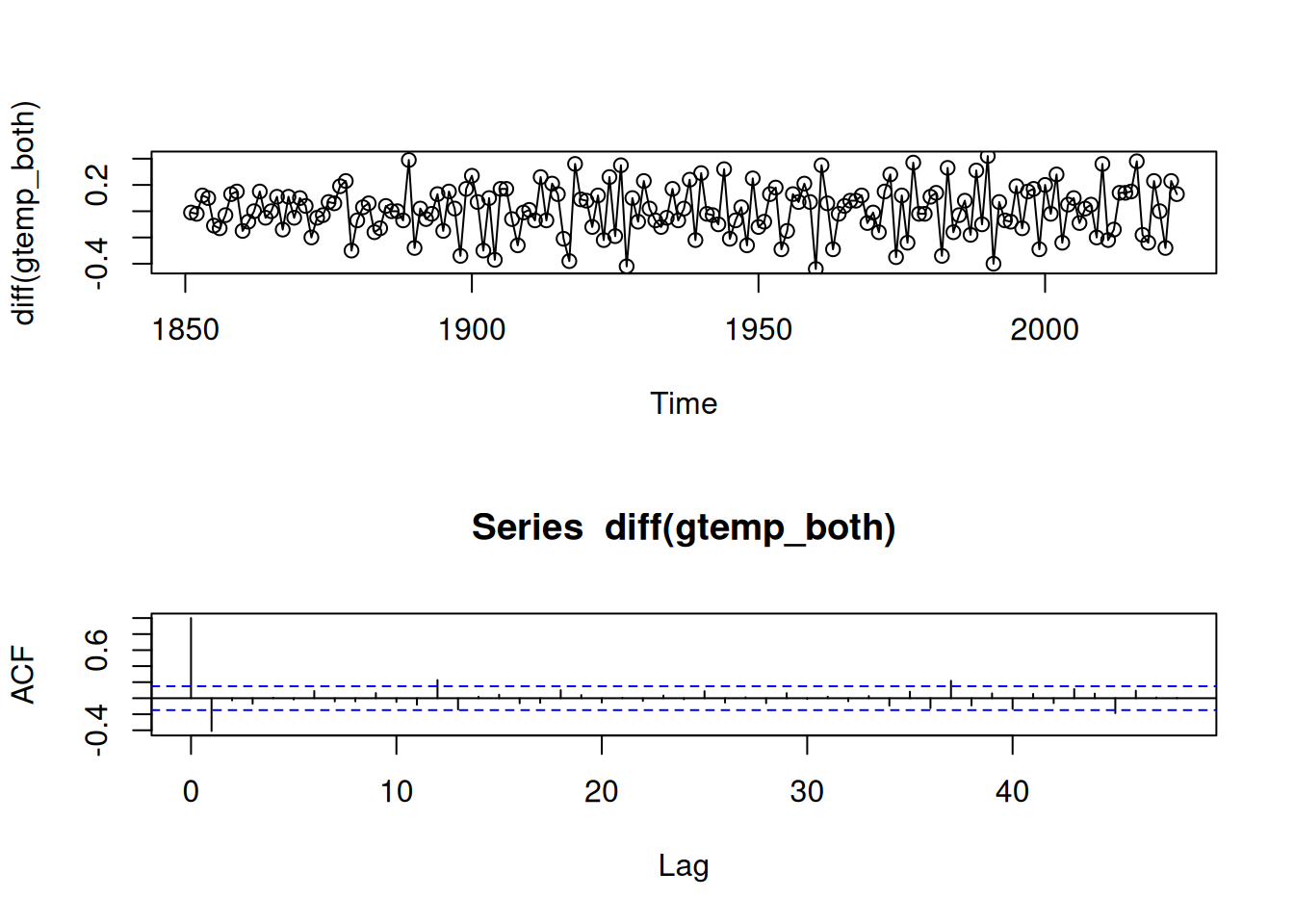
2.2.2.2 Ejemplo: Diferenciación de temperatura global
La serie de temperatura global se asemeja a una caminata aleatoria con drift. La diferencia primera produce estacionariedad y un incremento promedio de 0.008 grados por año.
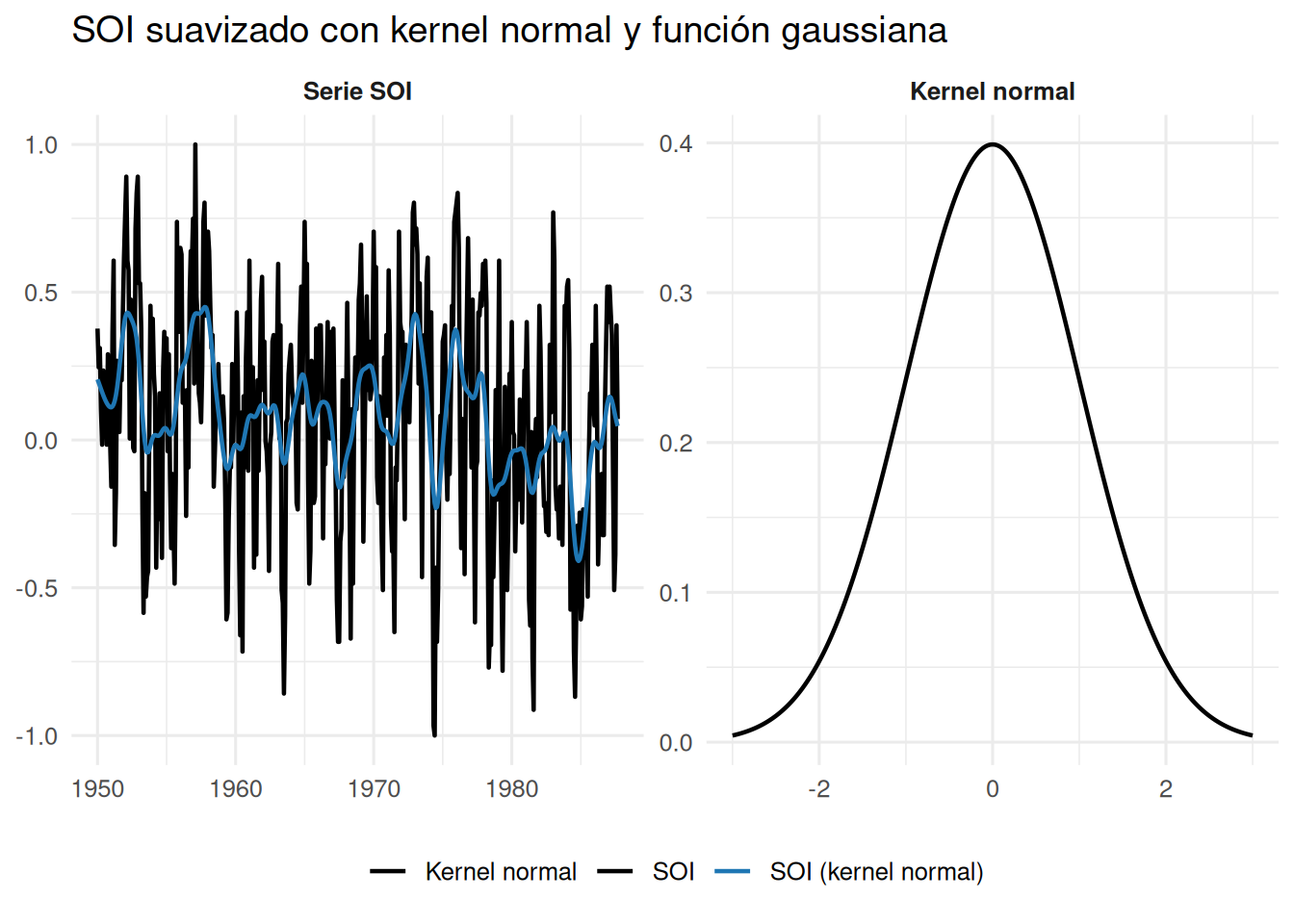
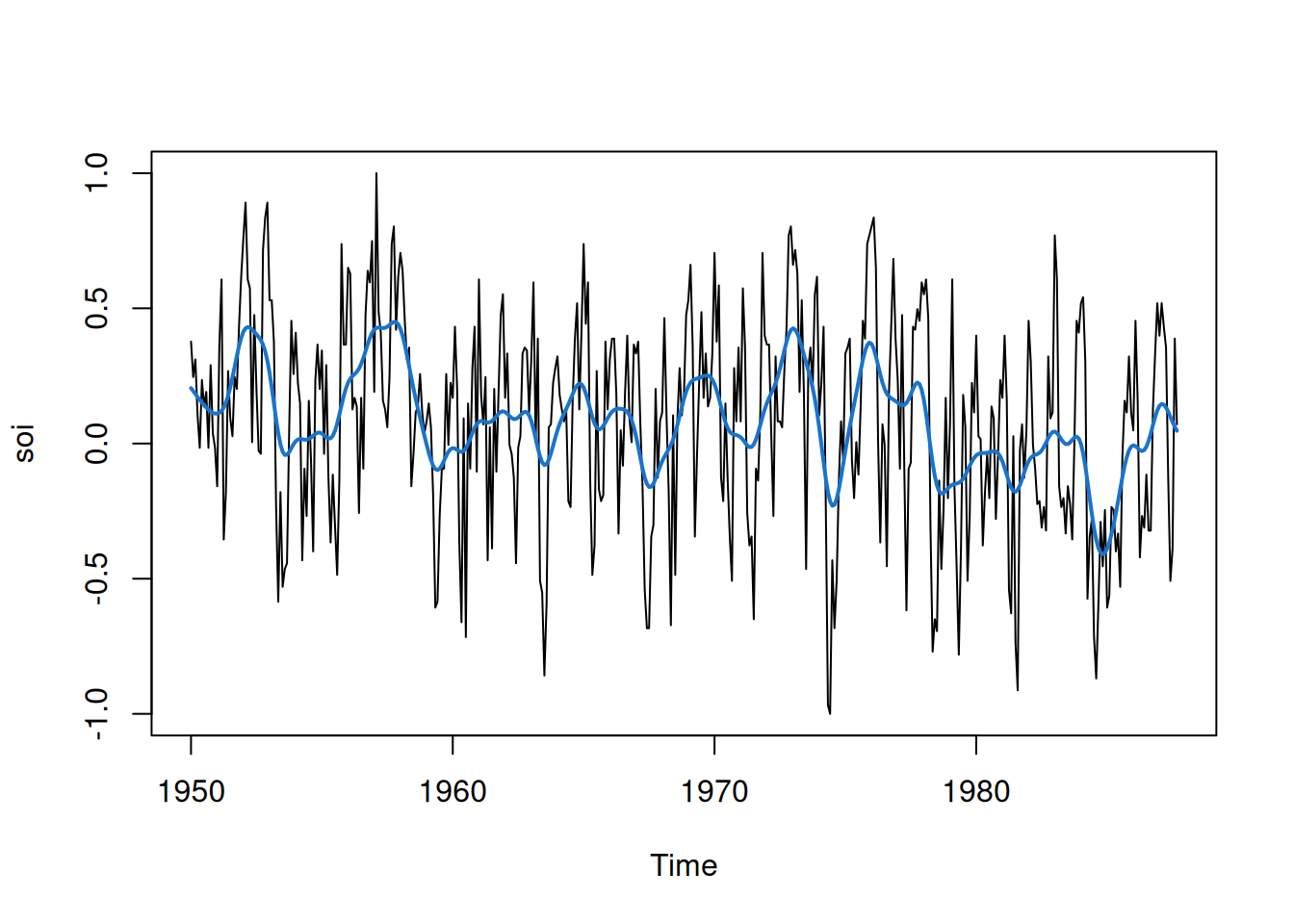
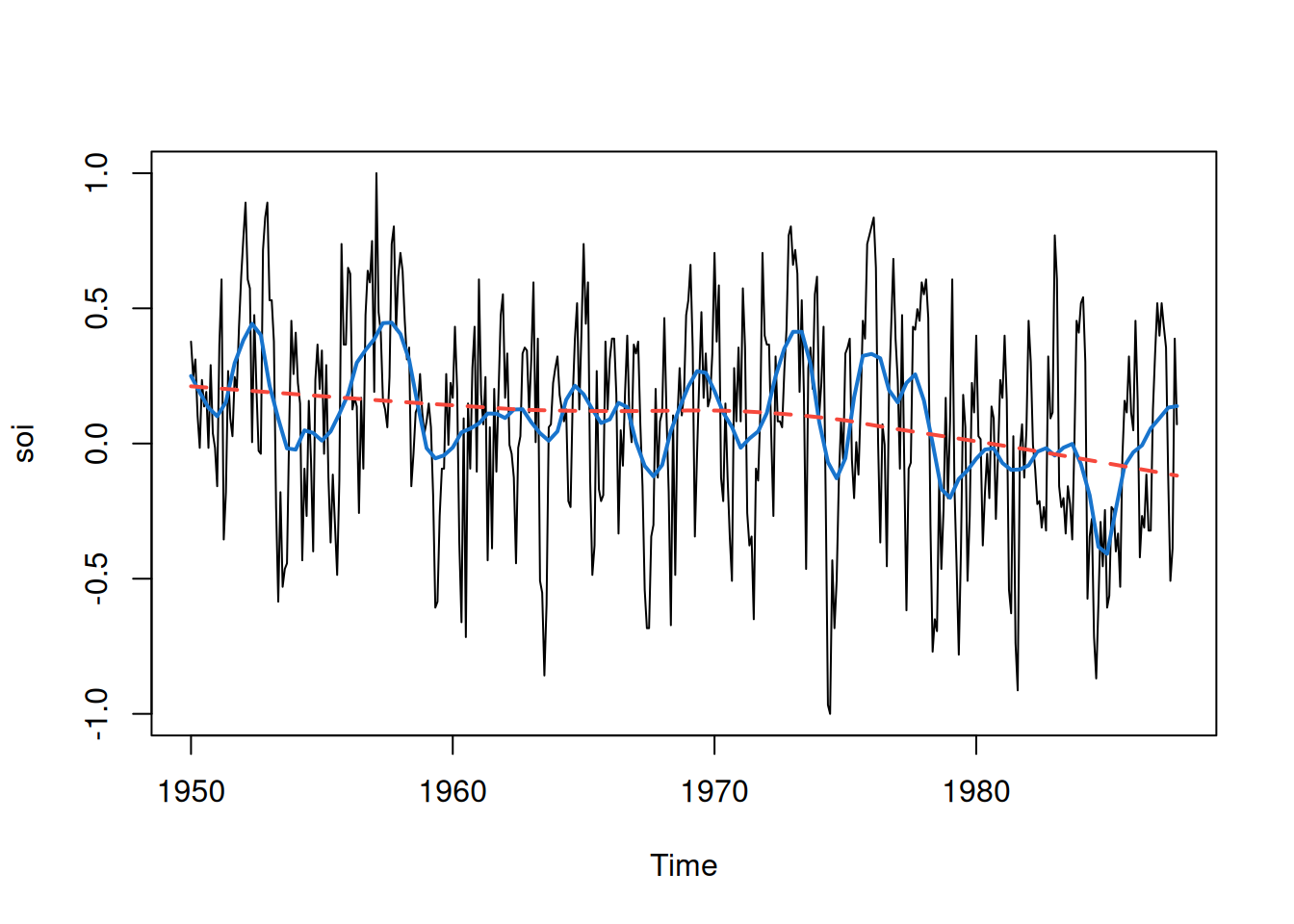
2.3 Suavizamiento en el contexto de series de tiempo
En esta sección se estudian distintas técnicas de suavizamiento en series de tiempo. El objetivo es reducir fluctuaciones de corto plazo y resaltar tendencias o patrones cíclicos, como los relacionados con El Niño. Se presentan varios métodos: promedio móvil, suavizamiento por kernel, lowess, splines de suavizamiento y suavizamiento de una serie en función de otra.
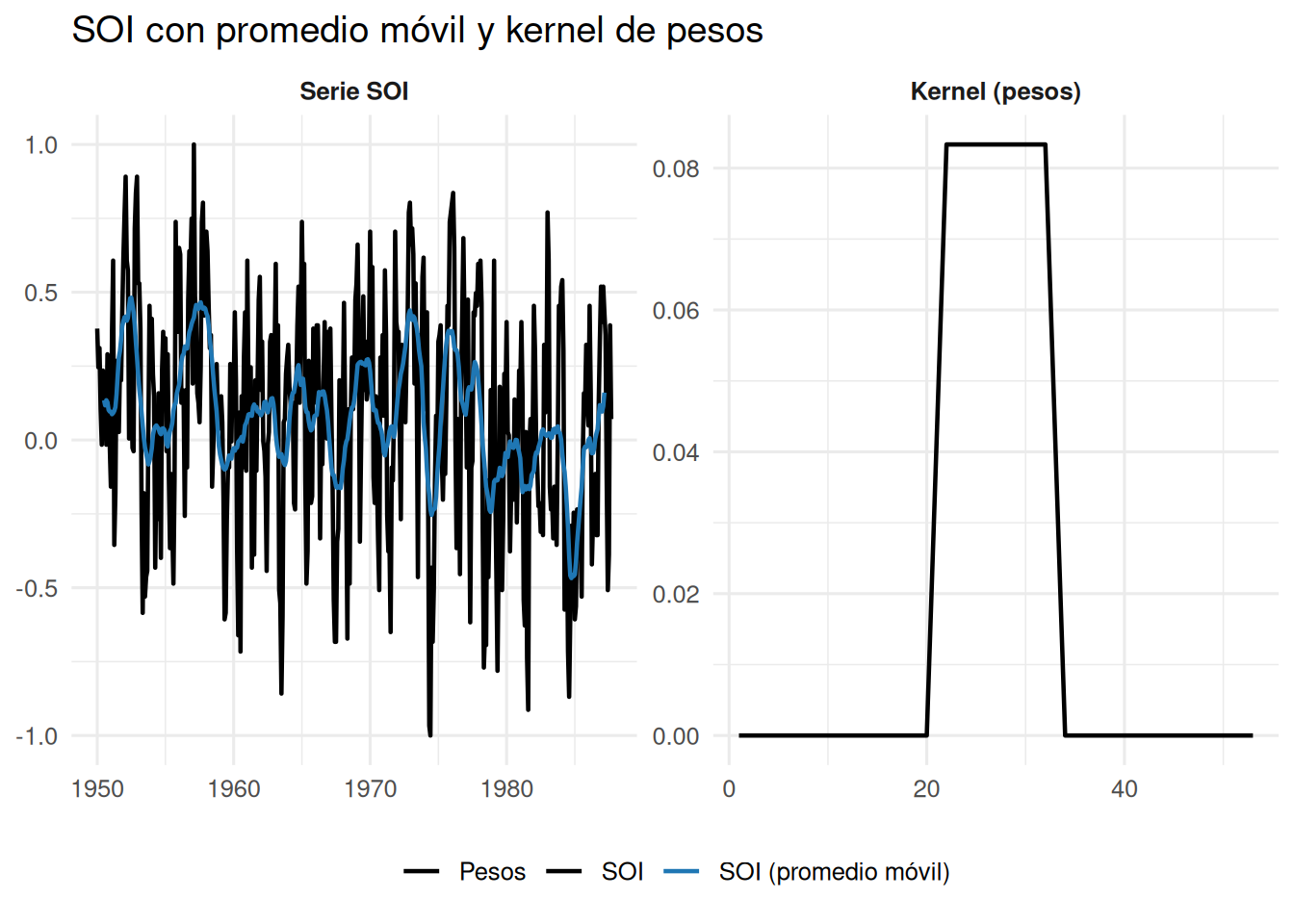
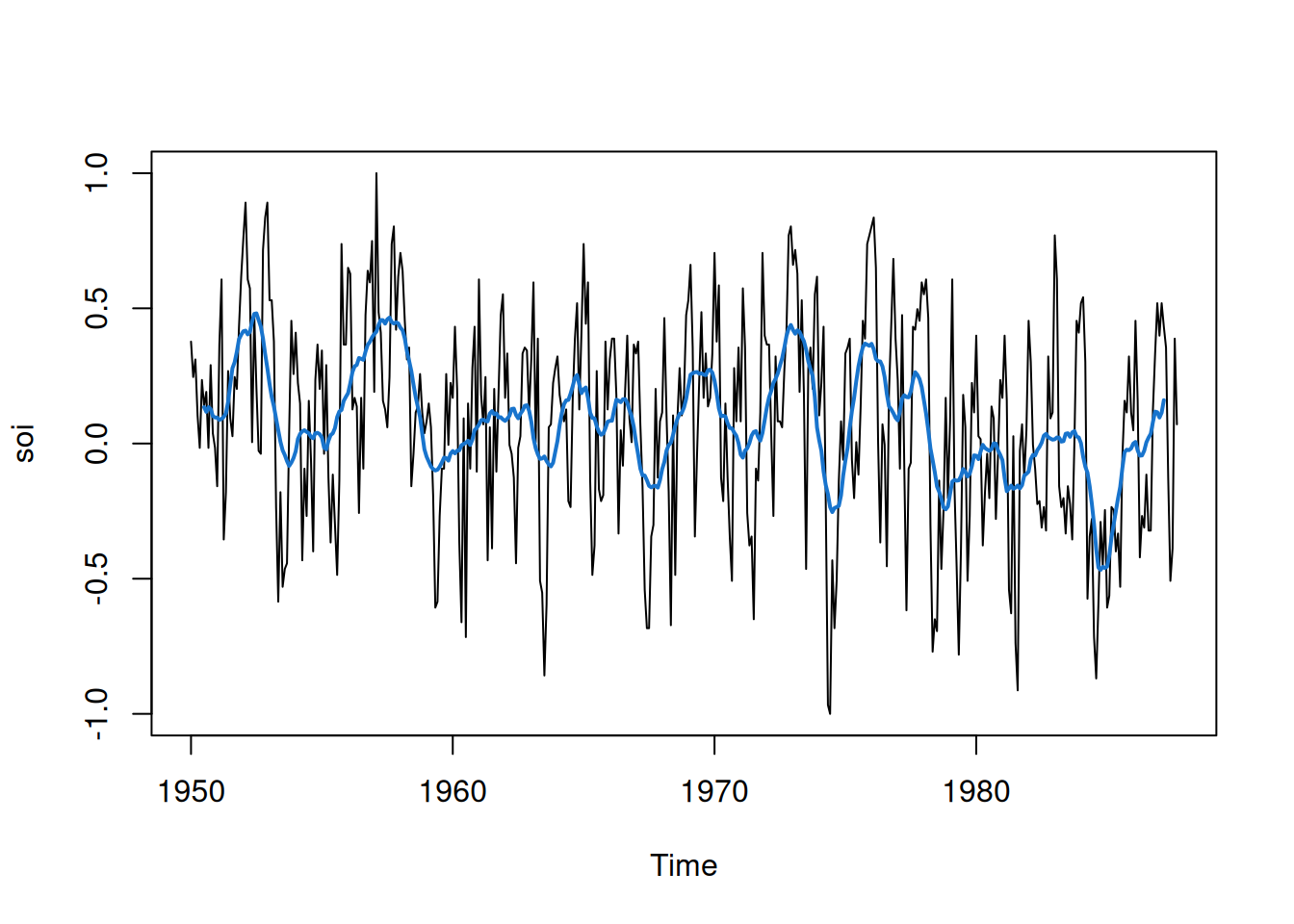
2.3.1 Promedio móvil
Para una serie \(x_t\), el suavizamiento mediante promedio móvil simétrico se define como
2.3.5 Suavizamiento de una serie como función de otra
Además del tiempo, puede suavizarse una serie en función de otra.
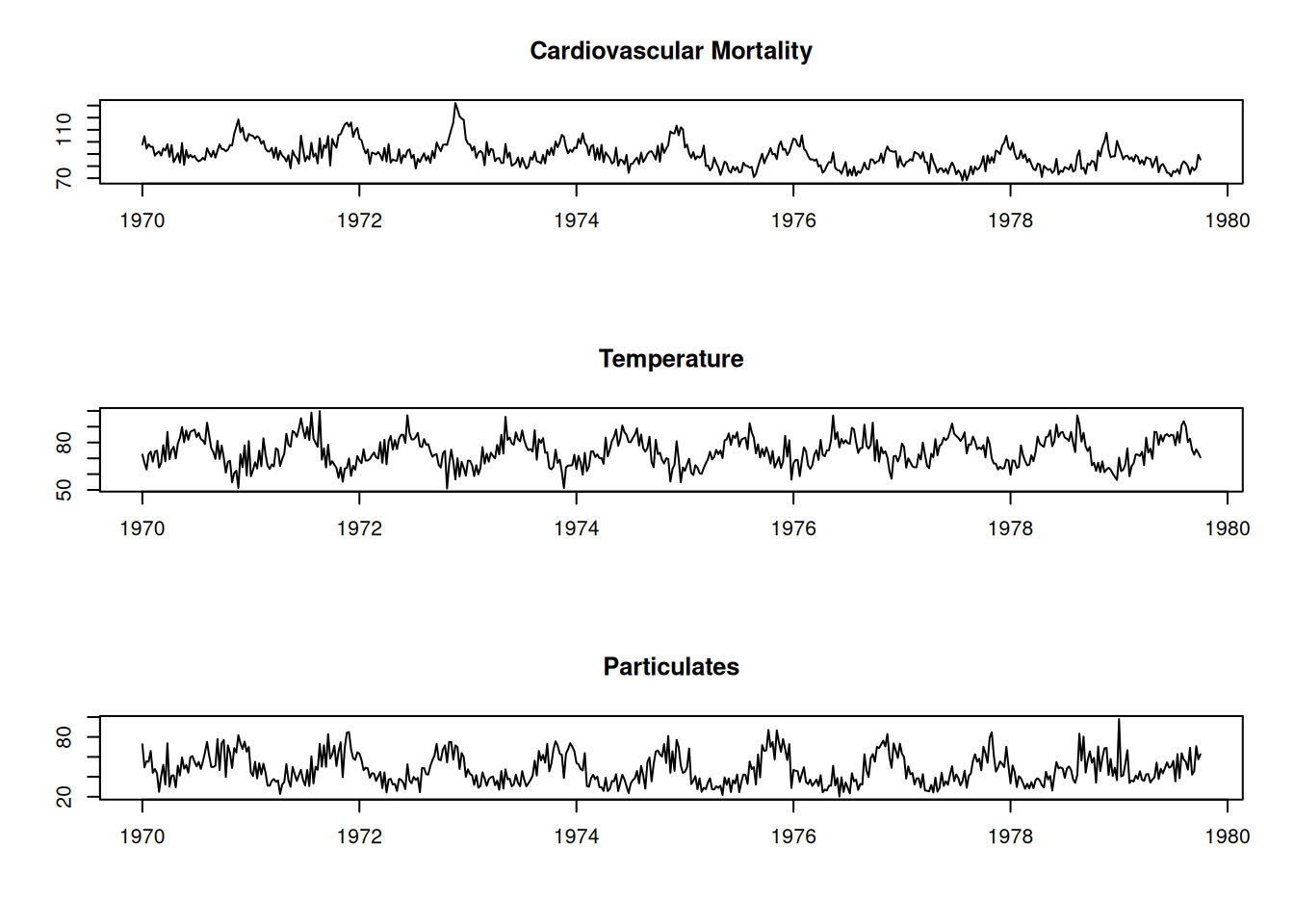
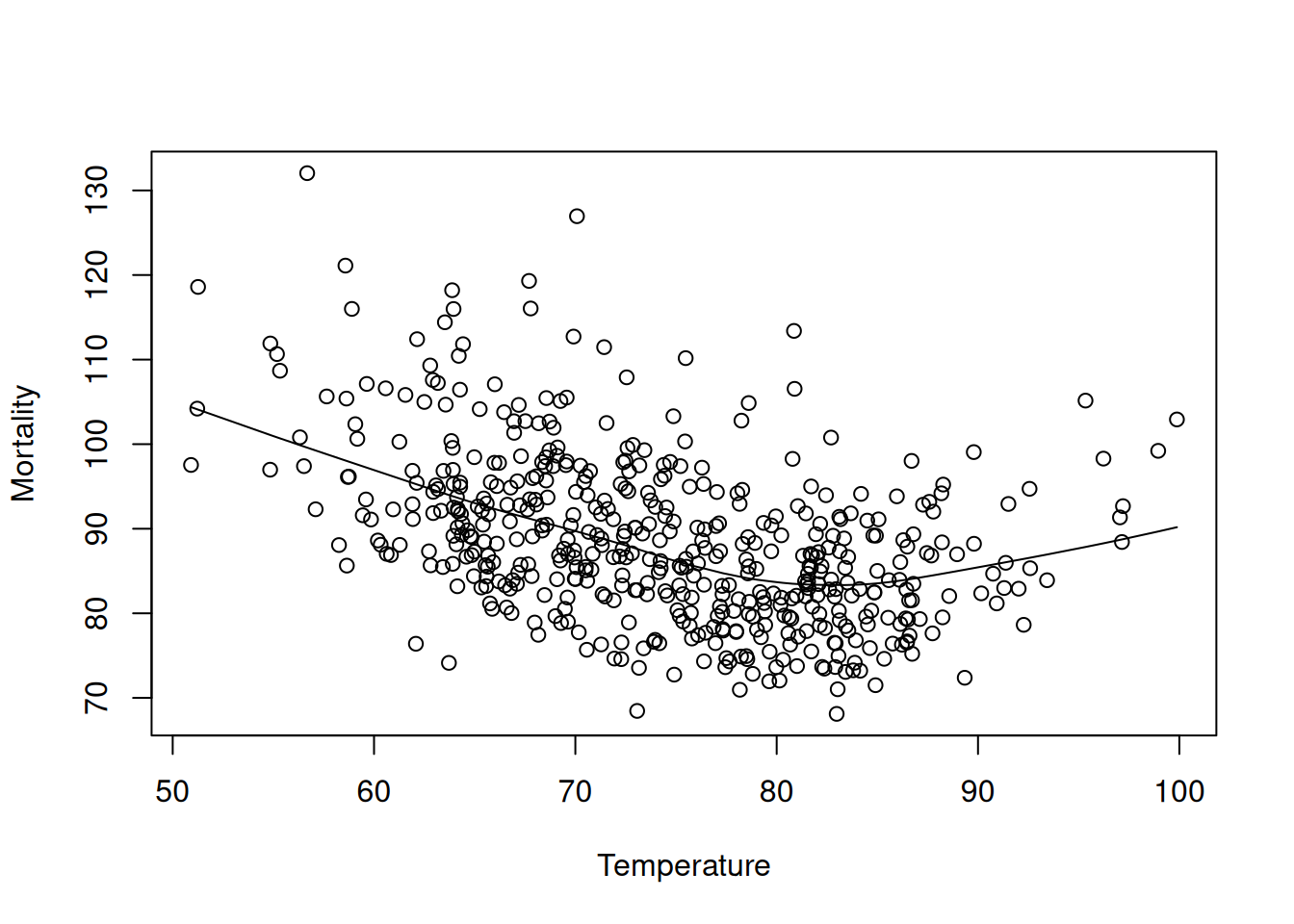
2.3.5.1 Ejemplo: Mortalidad y temperatura
Se suaviza mortalidad (\(M_t\)) como función de temperatura (\(T_t\)). El resultado muestra que la mortalidad mínima ocurre alrededor de \(83^\circ F\), siendo mayor en temperaturas bajas que en altas.