El modelo de espacio-estado, también conocido como modelo lineal dinámico, fue introducido por Kalman y Bucy en el contexto de seguimiento espacial. Este enfoque generaliza muchos modelos estadísticos, al igual que la regresión lineal lo hace para otras áreas. Originalmente usado en investigación aeroespacial, hoy se aplica en economía, medicina y ciencias del suelo.
El modelo de espacio de estados se compone de dos partes:
Un proceso latente o de estado (\(x_t\)), que sigue una dinámica temporal propia.
Un proceso observado (\(y_t\)), que depende del estado y añade ruido de observación.
Principios del modelo
El modelo se basa en dos condiciones fundamentales:
El proceso de estado \(x_t\) es un proceso de Markov.
Las observaciones \(y_t\) son independientes dadas las variables de estado \(x_t\).
6.1 Modelo lineal gaussiano
El modelo lineal gaussiano de espacio-estado (DLM) se define mediante dos ecuaciones:
\[
x_t = \Phi x_{t-1} + w_t
\]
\[
y_t = A_t x_t + v_t
\]
donde:
\(w_t \sim \text{iid } N_p(0, Q)\) es el ruido del sistema,
\(v_t \sim \text{iid } N_q(0, R)\) es el ruido de observación,
\(x_0 \sim N_p(\mu_0, \Sigma_0)\) es el estado inicial.
En este modelo, las observaciones no corresponden directamente a los estados, sino a transformaciones lineales de ellos más ruido.
Inclusión de variables exógenas
Se pueden incorporar variables exógenas \(u_t\) mediante:
\[
x_t = \Phi x_{t-1} + \Upsilon u_t + w_t
\]
\[
y_t = A_t x_t + \Gamma u_t + v_t
\]
donde \(\Upsilon\) y \(\Gamma\) son matrices de efectos de entrada.
6.1.0.1 Ejemplo biomédico
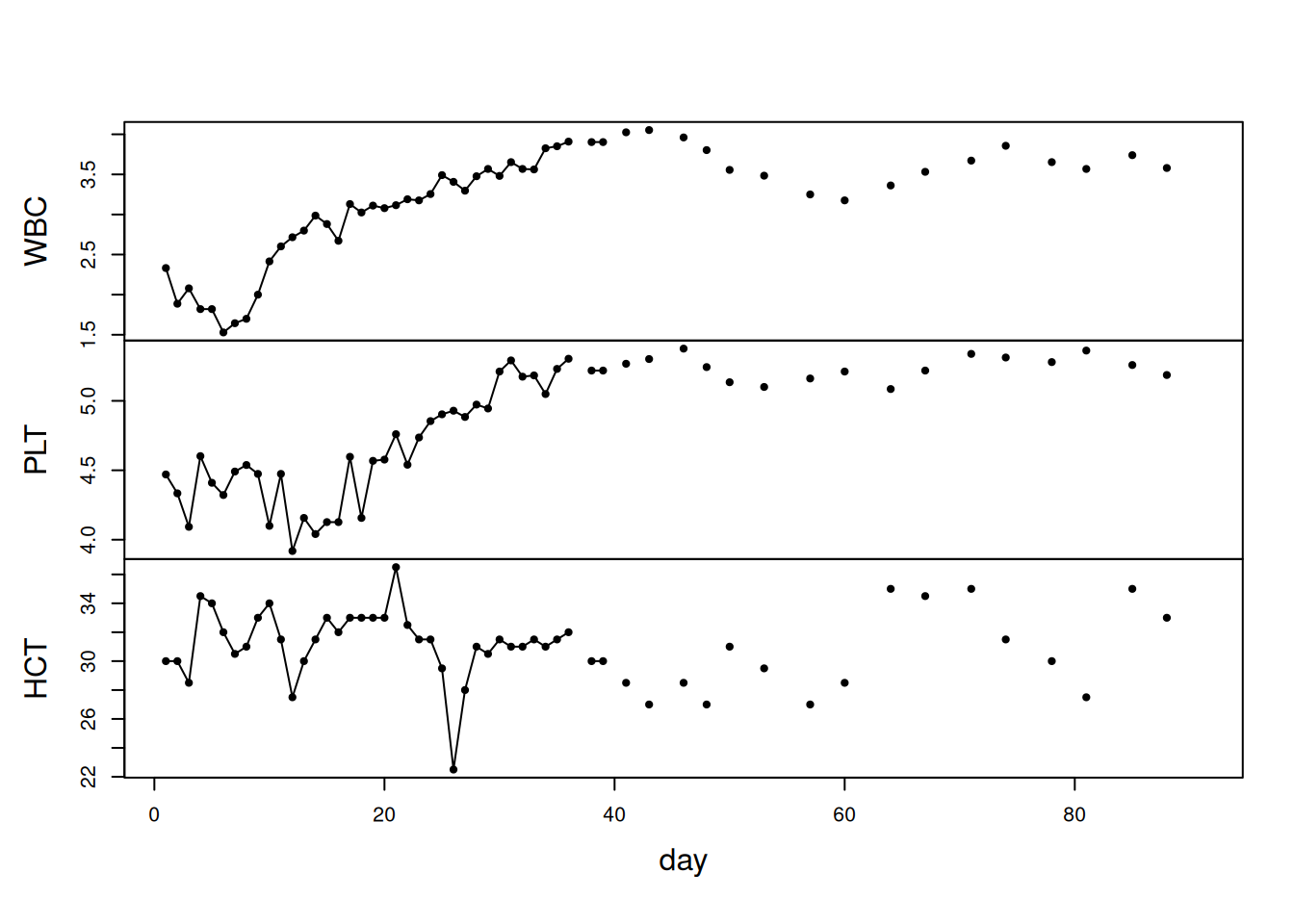
En un estudio de seguimiento de pacientes post-trasplante de médula ósea, se registraron tres marcadores: leucocitos (WBC), plaquetas (PLT) y hematocrito (HCT). Las observaciones contenían aproximadamente 40% de valores faltantes.
El modelo de observación fue \(y_t = A_t x_t + v_t\), donde \(A_t\) es la matriz identidad o nula dependiendo de si se observó o no la muestra en el día correspondiente.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.2
✔ ggplot2 4.0.0 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
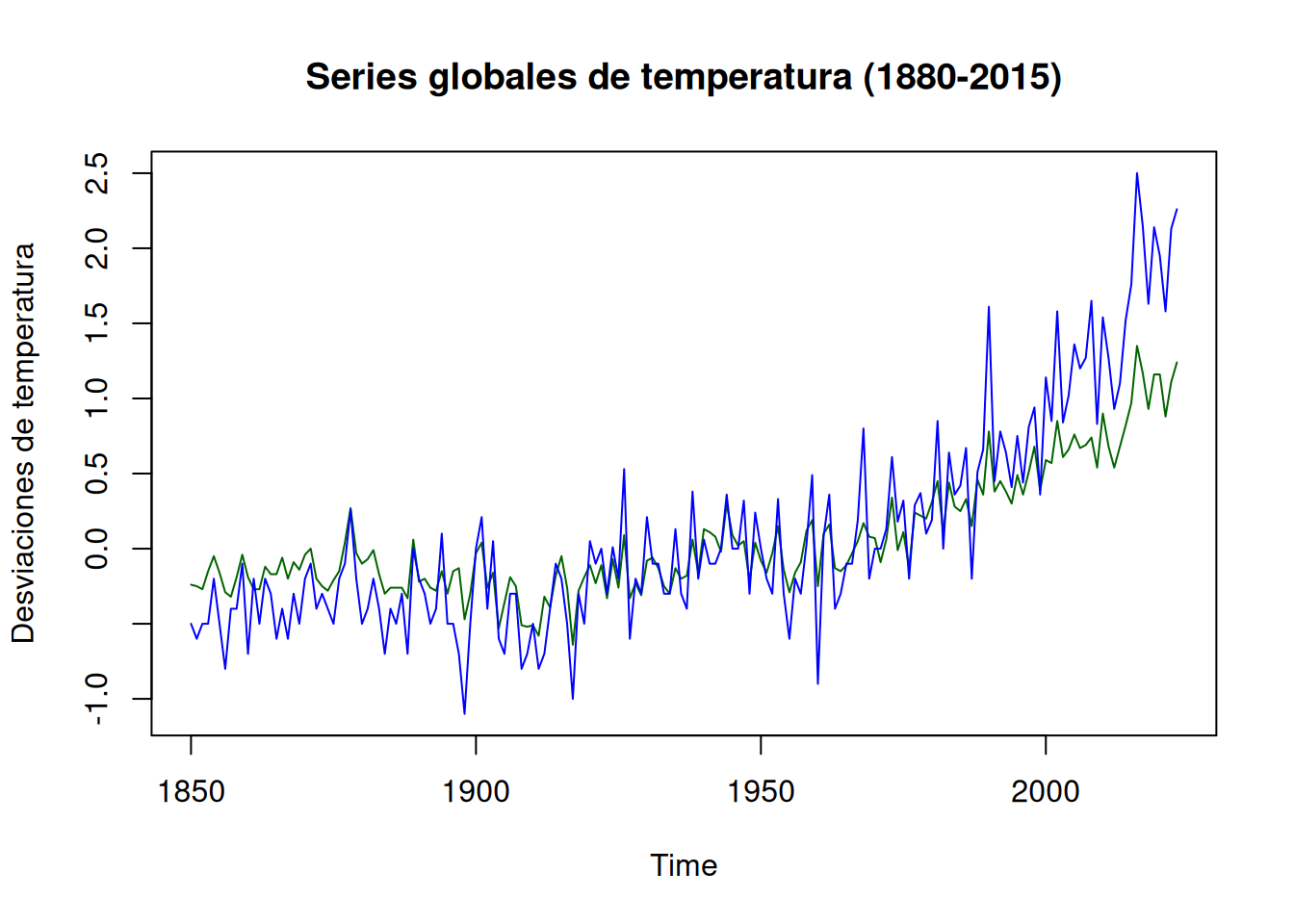
Se analizan dos series: gtemp_both (temperatura global tierra-oceano) y gtemp_land (solo tierra). Ambas observan un mismo proceso subyacente con diferentes ruidos de medición:
con \(Q= \text{var}(w_t)\). En este caso \(p=1\), \(q=2\), \(\Phi=1\) y \(\Upsilon= \delta\) con \(u_t=1\).
ts.plot(gtemp_both, gtemp_land, col =c("darkgreen", "blue"),ylab ="Desviaciones de temperatura",main ="Series globales de temperatura (1880-2015)")
6.1.1.2 Ejemplo: proceso AR(1) con ruido de observación
Se considera el modelo univariado:
\[
y_t = x_t + v_t
\]
\[
x_t = \phi x_{t-1} + w_t
\]
donde \(v_t \sim N(0, \sigma_v^2)\) y \(w_t \sim N(0, \sigma_w^2)\). Además \(x_0\sim N \left(0,\frac{\sigma_w^2}{1-\phi^2}\right)\); \(\{v_t\}\), \(\{w_t\}\) y \(x_0\) son independientes.
La función de autocovarianza del proceso de estado \(x_t\) es:
Esto muestra que \(y_t\)no sigue un AR(1) a menos que \(\sigma_v^2 = 0\). En general, puede representarse como un modelo ARMA(1,1):
\[
y_t = \phi y_{t-1} + \theta u_{t-1} + u_t
\]
donde \(u_t\) es ruido blanco gaussiano.
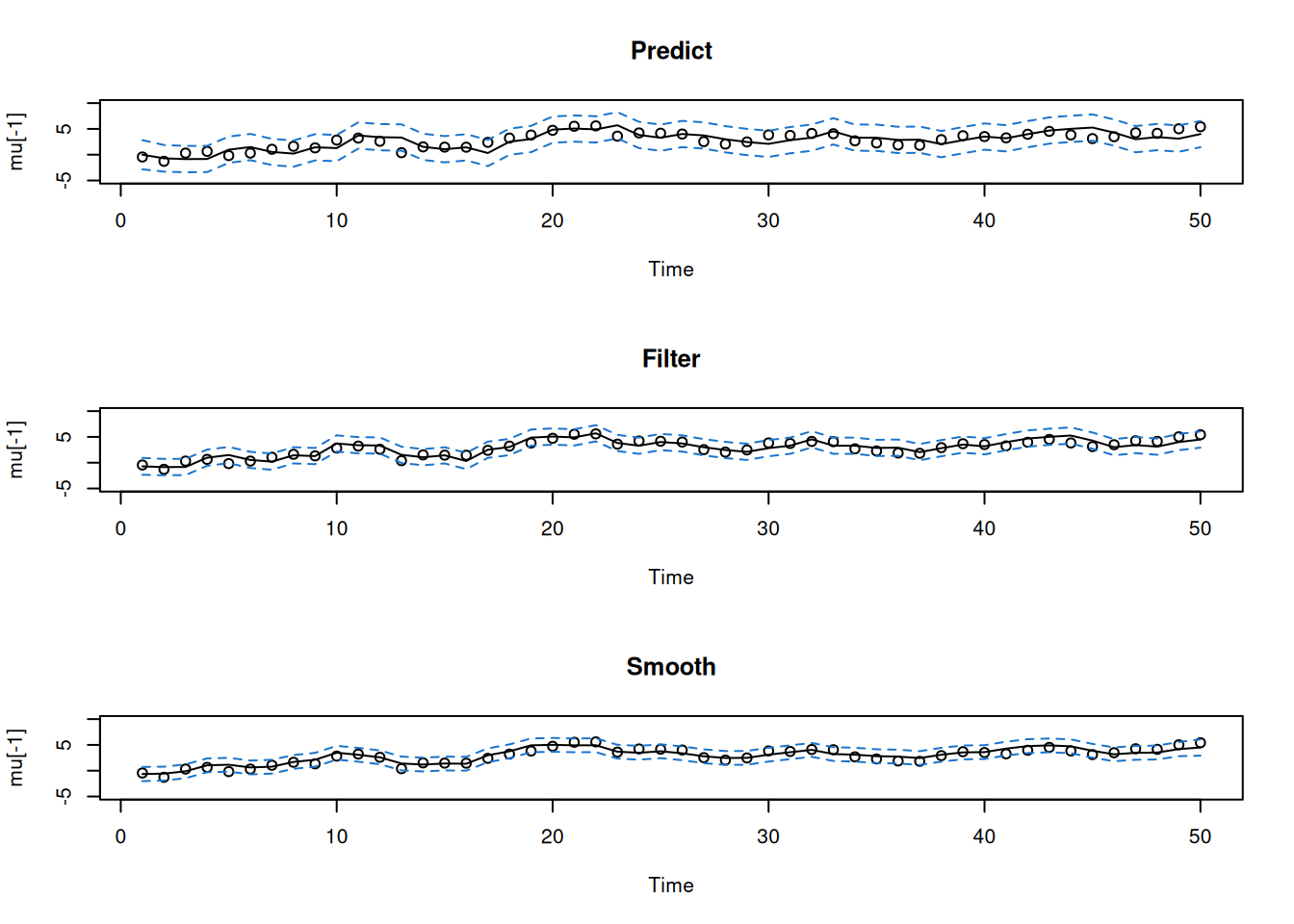
6.2 Estimación del estado: predicción, filtrado y suavizamiento
Esta sección introduce el problema de estimar el estado no observado \(x_t\) en modelos en espacio de estado lineales gaussianos, diferenciando entre predicción (\(s<t\)), filtrado (\(s=t\)) y suavizamiento (\(s>t\)). Se definen los estimadores y sus covarianzas, se deriva el Filtro de Kalman y el Suavizador de Kalman, se presenta la formulación en términos de densidades, y se ilustra con el modelo de nivel local y código R para simulación y aplicación del filtro/suavizador. Finalmente, se incluye el suavizador de covarianza a rezago uno necesario para EM.
6.2.1 Definiciones y objetivos
Sea el modelo en espacio de estado (lineal gaussiano) con entradas exógenas: \[
x_t = \Phi x_{t-1} + \Upsilon u_t + w_t, \quad w_t \sim \text{iid } \mathcal{N}_p(0,Q)
\]\[
y_t = A_t x_t + \Gamma u_t + v_t, \quad v_t \sim \text{iid } \mathcal{N}_q(0,R)
\]
Definimos los estimadores condicionales: \[
x_t^{s} = \mathrm{E}\left(x_t \mid y_{1:s}\right)
\]\[
P^{s}_{t_1,t_2} = \mathrm{E}\left\{\left(x_{t_1}-x_{t_1}^{s}\right)\left(x_{t_2}-x_{t_2}^{s}\right)'\right\}
\] Cuando \(t_1=t_2=t\), escribimos \(P_t^{s}\). En el caso gaussiano, \[
P^{s}_{t_1,t_2}=\mathrm{E}\left\{\left(x_{t_1}-x_{t_1}^{s}\right)\left(x_{t_2}-x_{t_2}^{s}\right)'\mid y_{1:s}\right\}.
\]
6.2.2 Propiedad: Filtro de Kalman
Para \(t=1,\ldots,n\), con \(x_0^{,0}=\mu_0\) y \(P_0^{,0}=\Sigma_0\):
Predicción (time update):\[
x_t^{t-1}=\Phi x_{t-1}^{t-1}+\Upsilon u_t
\]\[
P_t^{t-1}=\Phi P_{t-1}^{t-1}\Phi' + Q
\] las predicciones se realizan usando como valores iniciales \(x_n^n\) y \(P_n^n\).
Innovaciones y su varianza:\[
\epsilon_t = y_t - \mathrm{E}\left(y_t\mid y_{1:t-1}\right)= y_t - A_t x_t^{t-1} - \Gamma u_t
\]\[
\Sigma_t \stackrel{\mathrm{def}}{=}\operatorname{var}(\epsilon_t)
= A_t P_t^{t-1}A_t' + R
\]
Caso con parámetros dependientes del tiempo: Si \(\Phi,\Upsilon,Q,\Gamma,R\) o la dimensión \(q_t\) varían con \(t\), las ecuaciones anteriores se mantienen con las sustituciones correspondientes.
6.2.2.1 Enfoque mediante densidades
Sea \(\mathfrak{g}(x;\mu,\Sigma)\) la densidad normal multivariada con media \(\mu\) y matriz de covarianza \(\Sigma\). Para un modelo de espacio-estado:
Notación de Blight: \[
\{x;\mu,\sigma^2\}=\exp\left\{-\frac{1}{2\sigma^2}(x-\mu)^2\right\}
\] entonces se tiene: \[
\{x;\mu,\sigma^2\}=\{\mu;x,\sigma^2\}
\] Completando cuadrados: \[
\{x;\mu_1,\sigma_1^2\}\{x;\mu_2,\sigma_2^2\}
=\left\{x;\frac{\mu_1/\sigma_1^2+\mu_2/\sigma_2^2}{1/\sigma_1^2+1/\sigma_2^2},\left(1/\sigma_1^2+1/\sigma_2^2\right)^{-1}\right\}
\{\mu_1;\mu_2,\sigma_1^2+\sigma_2^2\} \tag{1}
\]
Usando lo anterior:
Predicción:\[
p(\mu_t\mid y_{1:t-1}) \propto \int \{\mu_t;\mu_{t-1},\sigma_w^2\}\{\mu_{t-1};\mu_{t-1}^{,t-1},P_{t-1}^{,t-1}\}d\mu_{t-1}
= \{\mu_t;\mu_{t-1}^{,t-1},P_{t-1}^{,t-1}+\sigma_w^2\}
\] y de lo anterior se concluye que:
\[
\mu_t\mid y_{1:t-1}\sim \mathcal{N}\left(\mu_t^{t-1},P_t^{t-1}\right)
\] donde
Las fórmulas anteriores cubren predicción (\(x_t^{,t-1}\)), filtrado (\(x_t^{,t}\)) y suavizamiento (\(x_t^{,n}\)) en el marco lineal gaussiano.
Las innovaciones \(\epsilon_t\) y sus covarianzas \(\Sigma_t\) son subproductos clave para diagnóstico y para máxima verosimilitud (e.g., EM).
6.3 Estimación por Máxima Verosimilitud
En esta sección se aborda cómo estimar, por máxima verosimilitud, los parámetros de un modelo de espacio de estados lineal gaussiano. Se aprovecha que, bajo gaussianidad, las innovaciones del filtro de Kalman son independientes y normales, lo que permite escribir la verosimilitud en una forma recursiva muy manejable. Se discuten dos enfoques de estimación: (i) Newton-Raphson, que usa derivadas de la verosimilitud de innovaciones, y (ii) EM (Baum–Welch), que alterna entre suavizar estados y actualizar parámetros como en una regresión multivariada. Finalmente, se presenta el resultado asintótico que garantiza normalidad de los MLE bajo condiciones de estabilidad del filtro.
6.3.1 Modelo de espacio de estados y verosimilitud de innovaciones
Formulación del modelo
Consideramos el modelo lineal gaussiano con entradas \[
x_t = \Phi x_{t-1} + \Upsilon u_t + w_t, \qquad w_t \sim \text{iid } N_p(0,Q),
\]\[
y_t = A_t x_t + \Gamma u_t + v_t, \qquad v_t \sim \text{iid } N_q(0,R),
\] con estado inicial \[
x_0 \sim N_p(\mu_0, \Sigma_0),
\] y suponiendo que \({w_t}\) y \({v_t}\) son independientes. Denotamos por \(\Theta\) al vector de todos los parámetros desconocidos: \[
\Theta = (\mu_0, \Sigma_0, \Phi, Q, R, \Upsilon, \Gamma).
\]
Innovaciones y su covarianza
Del filtro de Kalman obtenemos, para \(t=1,\dots,n\), el error de predicción u innovación\[
\epsilon_t = y_t - A_t x_t^{t-1} - \Gamma u_t,
\] donde \(x_t^{t-1} = \mathbb{E}(x_t \mid y_{1:t-1})\) es el predictor del estado. La covarianza de la innovación es \[
\Sigma_t = \operatorname{var}(\epsilon_t) = A_t P_t^{t-1} A_t' + R,
\] con \(P_t^{t-1}\) la covarianza de predicción del estado.
Como las innovaciones son normales, centradas e independientes a lo largo del tiempo, la verosimilitud puede escribirse como producto de densidades normales.
Nota: Aquí es clave que para cada evaluación de la verosimilitud hay que correr el filtro de Kalman completo con los parámetros actuales para obtener \(\epsilon_t(\Theta)\) y \(\Sigma_t(\Theta)\).
6.3.2 Estimación por Newton–Raphson
6.3.2.1 Idea general
La log-verosimilitud es no lineal y puede involucrar muchos parámetros. El procedimiento estándar:
initial value 81.313627
iter 2 value 80.169051
iter 3 value 79.866131
iter 4 value 79.222846
iter 5 value 79.021504
iter 6 value 79.014723
iter 7 value 79.014453
iter 7 value 79.014452
iter 7 value 79.014452
final value 79.014452
converged
El procedimiento converge en pocas iteraciones y entrega estimaciones cercanas a los valores reales, junto con sus errores estándar (a partir del Hessiano).
6.4 Estimación por EM
El algoritmo EM (Expectation-Maximization) es una alternativa para estimar los parámetros de un modelo de espacio de estados lineal gaussiano. La idea central es considerar los estados no observados como datos faltantes y alternar entre suavizar los estados dados los parámetros actuales (E-step) y actualizar los parámetros dados los estados suavizados (M-step). A continuación se describen ambos pasos. Idea original: Dempster, Laird y Rubin (1977); aplicación a espacio de estados: Shumway y Stoffer (1982).
6.4.1 Idea de datos completos
Si pudiéramos observar también los estados \(x_{0:n}\), la verosimilitud completa sería \[
p_\Theta(x_{0:n}, y_{1:n})
= p_{\mu_0, \Sigma_0}(x_0)
\prod_{t=1}^n p_{\Phi, Q}(x_t \mid x_{t-1})
\prod_{t=1}^n p_{R}(y_t \mid x_t).
\] y a \(\{x_{0:n},y_{1:n}\}\) le llamamos datos completos.
Bajo gaussianidad, ignorando constantes, \[
\begin{aligned}
-2 \ln L_{X,Y}(\Theta)
&= \ln|\Sigma_0| + (x_0 - \mu_0)'\Sigma_0^{-1}(x_0 - \mu_0) \\
&\quad + n \ln|Q| + \sum_{t=1}^n (x_t - \Phi x_{t-1})' Q^{-1} (x_t - \Phi x_{t-1}) \\
&\quad + n \ln|R| + \sum_{t=1}^n (y_t - A_t x_t)' R^{-1} (y_t - A_t x_t).
\end{aligned}
\] El principal objetivo del EM es minimizar esta expresión respecto de \(\Theta\), pero considerando que los estados \(x_{0:n}\) no se observan. En este caso a \(y_{1:n}\) se le llama datos completos o observados.
6.4.2 E-step
Como los estados no se observan, el EM propone tomar esperanza condicional de \(-2 \ln L_{X,Y}(\Theta)\) dado \(y_{1:n}\) y los parámetros actuales \(\Theta^{(j-1)}\):
\[
Q(\Theta \mid \Theta^{(j-1)}) =
\mathbb{E}\left\{ -2 \ln L_{X,Y}(\Theta) \mid y_{1:n}, \Theta^{(j-1)} \right\}.
\] Para calcular esta esperanza se necesitan los suavizadores de Kalman, es decir:
estimate SE
[1,] 0.80770475 0.07827525
[2,] 0.85642590 0.16295337
[3,] 0.86107346 0.13644243
[4,] -2.10378197 NA
[5,] 0.03807792 NA
Este ejemplo muestra que el EM converge más lento que Newton–Raphson (59 iteraciones, según el texto), pero lleva prácticamente al mismo punto de máximo.
6.4.5 Distribución asintótica y estado estable
6.4.5.1 Estabilidad del filtro
Si el modelo es invariante en el tiempo (\(A_t=A\)) y los autovalores de \(\Phi\) están dentro del círculo unitario, el filtro de Kalman entra en estado estable:
\(P_t^{t} \to P\),
\(K_t \to K\),
\(\Sigma_t \to \Sigma = A P A' + R\).
cuando \(t \to \infty\).
En ese caso el modelo puede escribirse en la forma de innovaciones en estado estable: \[
x_{t+1}^t = \Phi x_t^{t-1} + \Phi K \epsilon_t, \tag{6.72}
\]\[
y_t = A x_t^{t-1} + \epsilon_t, \tag{6.73}
\] con \(\epsilon_t \sim \text{iid } N(0, \Sigma)\).
6.4.5.2 Resultado asintótico
Bajo condiciones generales (identificabilidad, estabilidad del filtro, dimensión mínima del modelo, etc.), el estimador de máxima verosimilitud \(\widehat{\Theta}_n\) basado en la verosimilitud de innovaciones satisface: \[
\sqrt{n}(\widehat{\Theta}_n - \Theta_0)
\overset{d}{\longrightarrow} N\big(0, \mathcal{I}(\Theta_0)^{-1} \big),
\] donde $$ () = _{n } n^{-1} $$
es la matriz de información asociada a la verosimilitud de innovaciones. En la práctica, al final del Newton–Raphson o del EM se usa el Hessiano numérico de \(-\ln L_Y(\widehat{\Theta})\) para aproximar \(n\mathcal{I}(\Theta_0)\) y de ahí obtener errores estándar.
# Esquema genérico para errores estándar luego de estimar por Newton/EMhess <- est$hessian # o el que salga de fdHessIhat <- hess # aproximación de n * I(Theta0)SE <-sqrt(diag(solve(Ihat)))SE
[1] 0.08060636 0.17528895 0.14293192
Este resultado justifica el uso de intervalos de confianza y pruebas de hipótesis estándar sobre los parámetros estimados en modelos de espacio de estados lineales gaussianos.
6.5 Datos Faltantes
Se presentan modificaciones del modelo de espacio de estados lineal gaussiano para manejar observaciones faltantes o muestreo irregular. Se detalla cómo mantener la forma del filtro de Kalman y de la verosimilitud de innovaciones mediante sustituciones que preservan una ecuación de observación de dimensión fija. Luego se adapta el algoritmo EM para la estimación por máxima verosimilitud con datos faltantes. Finalmente, se ilustra con un ejemplo biomédico multivariado y su código en R.
6.5.1 Partición de observaciones y estructura de covarianzas
Sea \(y_t\in\mathbb{R}^q\) y, en el tiempo \(t\), particione: \[
\binom{y_{t}^{(1)}}{y_{t}^{(2)}}=\begin{bmatrix}
A_{t}^{(1)} \\
A_{t}^{(2)}
\end{bmatrix}x_t+\binom{v_{t}^{(1)}}{v_{t}^{(2)}} .
\]
La covarianza de los errores de medición entre partes observadas y no observadas es: \[
\operatorname{cov}\binom{v_{t}^{(1)}}{v_{t}^{(2)}}=\begin{bmatrix}
R_{11t} & R_{12t} \\
R_{21t} & R_{22t}
\end{bmatrix}.
\]
6.5.2 Modelo con datos faltantes y dimensión variable
Cuando \(y_t^{(2)}\) no se observa, el DLM se puede reescribir como \[
x_t=\Phi x_{t-1}+w_t \quad \text{y} \quad y_t^{(1)}=A_t^{(1)}x_t+v_t^{(1)}.
\] Si no hay observaciones en \(t\), se fija \(K_t=0_{p\times q}\) y entonces \(x_t^{t}=x_t^{t-1}\) y \(P_t^{t}=P_t^{t-1}\).
6.5.3 Sustituciones para mantener dimensión fija \(q\)
Es más conveniente computacionalmente conservar la dimensión \(q\) usando: \[
y_{(t)}=\binom{y_t^{(1)}}{0},\quad
A_{(t)}=\begin{bmatrix}
A_t^{(1)} \\
0
\end{bmatrix},\quad
R_{(t)}=\begin{bmatrix}
R_{11t} & 0\\
0 & I_{22t}
\end{bmatrix},
\] y, con estas sustituciones, las innovaciones cumplen que: \[
\epsilon_{(t)}=\binom{\epsilon_t^{(1)}}{0},\quad
\Sigma_{(t)}=
\begin{bmatrix}
A_t^{(1)}P_t^{t-1}A_t^{(1)'}+R_{11t} & 0 \\
0 & I_{22t}
\end{bmatrix}.
\]
6.5.4 Suavizado con datos faltantes
Los estimadores del estado con datos faltantes son \[
x_t^{(s)}=\mathrm{E}\left(x_t\mid y_1^{(1)},\ldots,y_s^{(1)}\right),
\] con matriz de error \[
P_t^{(s)}=\mathrm{E}\left\{(x_t-x_t^{(s)})(x_t-x_t^{(s)})'\right\}.
\] Las covarianzas lag-uno suavizadas se denotan \(P_{t,t-1}^{(n)}\).
6.5.5 Algoritmo EM con datos faltantes: E-step
Considere como datos incompletos los datos observados: \[
y_{1:n}^{(1)}=\{y_1^{(1)},\ldots,y_n^{(1)}\},
\] y como datos completos \(\{x_{0:n},y_{1:n}\}\). En la iteración \(j\) se evalúa: \[
\begin{aligned}
Q(\Theta\mid \Theta^{(j-1)})&=\mathrm{E}\left\{-2\ln L_{X,Y}(\Theta)\mid y_{1:n}^{(1)},\Theta^{(j-1)}\right\}\\
&=\mathrm{E}_*\left\{\ln|\Sigma_0|+\operatorname{tr}\big[\Sigma_0^{-1}(x_0-\mu_0)(x_0-\mu_0)'\big]\mid y_{1:n}^{(1)}\right\}\\
&\quad+\mathrm{E}_*\left\{n\ln|Q|+\sum_{t=1}^n \operatorname{tr}\big[Q^{-1}(x_t-\Phi x_{t-1})(x_t-\Phi x_{t-1})'\big]\mid y_{1:n}^{(1)}\right\} \\
&\quad+\mathrm{E}_*\left\{n\ln|R|+\sum_{t=1}^n \operatorname{tr}\big[R^{-1}(y_t-A_tx_t)(y_t-A_tx_t)'\big]\mid y_{1:n}^{(1)}\right\},
\end{aligned}
\] donde \(\mathrm{E}_*\) usa \(\Theta^{(j-1)}\). Los primeros dos términos son iguales a los del caso sin datos faltantes, pero el tercero requiere calcular términos adicionales que incluyen a \(E_*(y_t^{(2)}|y_{1:n}^{(1)})\) y \(E_*(y_t^{(2)}y_t^{(2)'}|y_{1:n}^{(1)})\). El desarrollo del tercer término puede ser consultado en el libro.
donde los suavizadores se calculan usando los parámetros \(\Theta^{(j-1)}\) y la modificación del modelo de espacio-estado. Las actualizaciones en la iteración \(j\) son \[
\Phi^{(j)}=S_{(10)}S_{(00)}^{-1},
\]
en donde en este último caso solamente se actualiza \(R_{11t}\). Las estimaciones iniciales se actualizan como \[
\mu_0^{(j)}=x_0^{(n)}, \qquad \Sigma_0^{(j)}=P_0^{(n)}.
\]
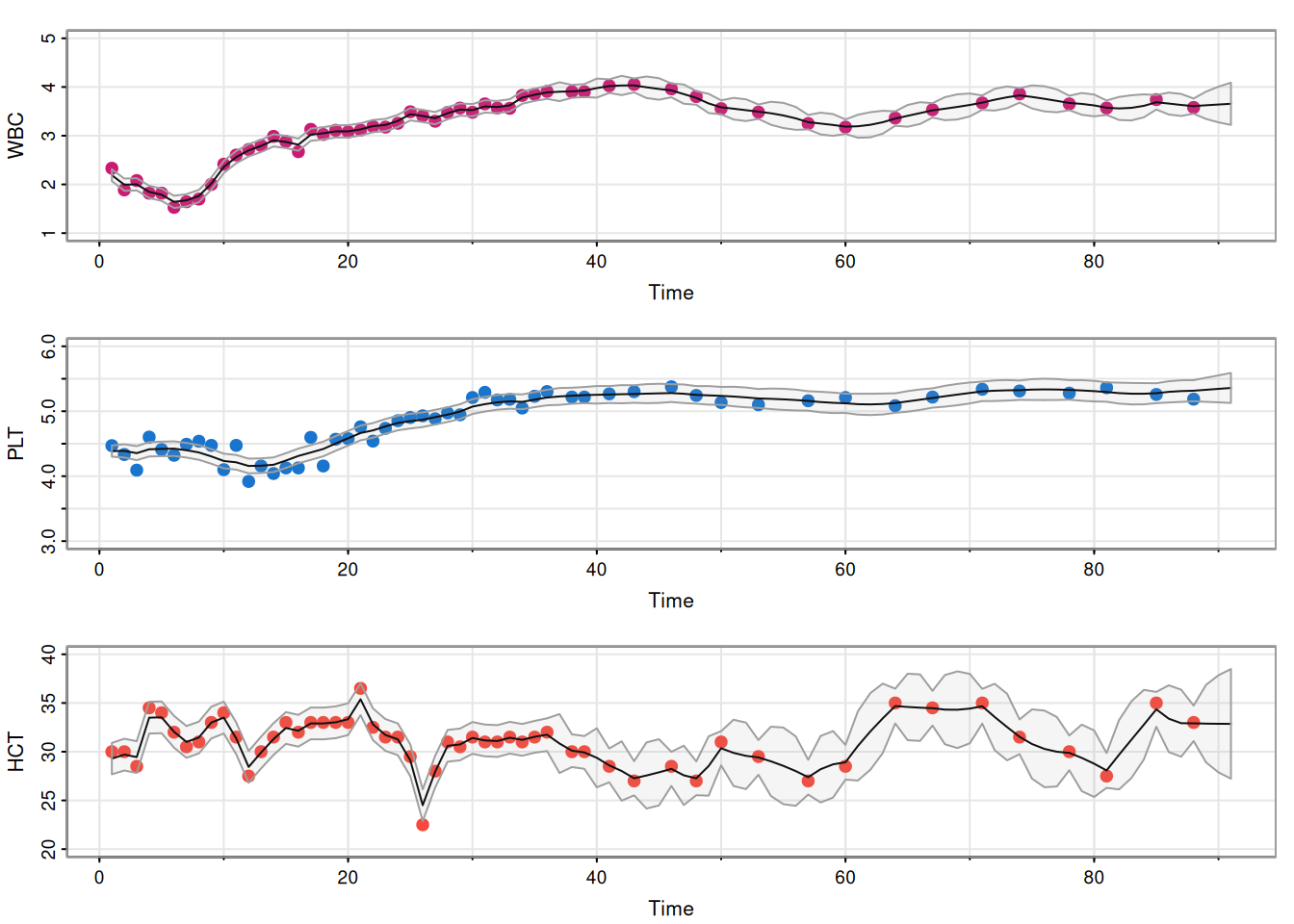
6.5.6.1 Ejemplo: Datos biomédicos longitudinales (faltantes)
Con muchos valores faltantes después del día 37, el EM converge en 65 iteraciones. La matriz de transición estimada indica acoplamiento débil entre la primera y segunda series, y una fuerte relación de HCT con las dos primeras: \[
\mathbf{H}\hat{\mathbf{C}}\mathbf{T}_t=-1.27\mathbf{WBC}_{t-1}+1.97\mathbf{PLT}_{t-1}+0.82\mathbf{HCT}_{t-1}.
\] Los valores suavizados \(\hat{x}_t^{(n)}\) y las bandas \(\pm 2\sqrt{\hat{P}_t^{(n)}}\) proporcionan trayectorias y márgenes de error.
y = blood # missing values are NAnum =nrow(y)A =array(diag(1,3), dim=c(3,3,num)) # measurement matricesfor (k in1:num) if (is.na(y[k,1])) A[,,k] =diag(0,3)# Initial valuesmu0 =matrix(0,3,1)Sigma0 =diag(c(.1,.1,1) ,3)Phi =diag(1, 3)Q =diag(c(.01,.01,1), 3)R =diag(c(.01,.01,1), 3)# Run EM(em =EM(y, A, mu0, Sigma0, Phi, Q, R)) # partial output shown
# Run smoother at the estimatessQ = em$Q %^% .5# matrix square root (elementwise shown como en el texto)sR =sqrt(em$R)ks =Ksmooth(y, A, em$mu0, em$Sigma0, em$Phi, sQ, sR)# Pull out the valuesy1s = ks$Xs[1,,]y2s = ks$Xs[2,,]y3s = ks$Xs[3,,]p1 =2*sqrt(ks$Ps[1,1,])p2 =2*sqrt(ks$Ps[2,2,])p3 =2*sqrt(ks$Ps[3,3,])# plotspar(mfrow=c(3,1))tsplot(WBC, type="p", pch=19, ylim=c(1,5), col=6, lwd=2, cex=1)lines(y1s) xx =c(time(WBC), rev(time(WBC))) # same for all yy =c(y1s-p1, rev(y1s+p1))polygon(xx, yy, border=8, col=astsa.col(8, alpha = .1))tsplot(PLT, type="p", ylim=c(3,6), pch=19, col=4, lwd=2, cex=1)lines(y2s) yy =c(y2s-p2, rev(y2s+p2))polygon(xx, yy, border=8, col=astsa.col(8, alpha = .1))tsplot(HCT, type="p", pch=19, ylim=c(20,40), col=2, lwd=2, cex=1)lines(y3s) yy =c(y3s-p3, rev(y3s+p3))polygon(xx, yy, border=8, col=astsa.col(8, alpha = .1))
6.6 Modelos Estructurales
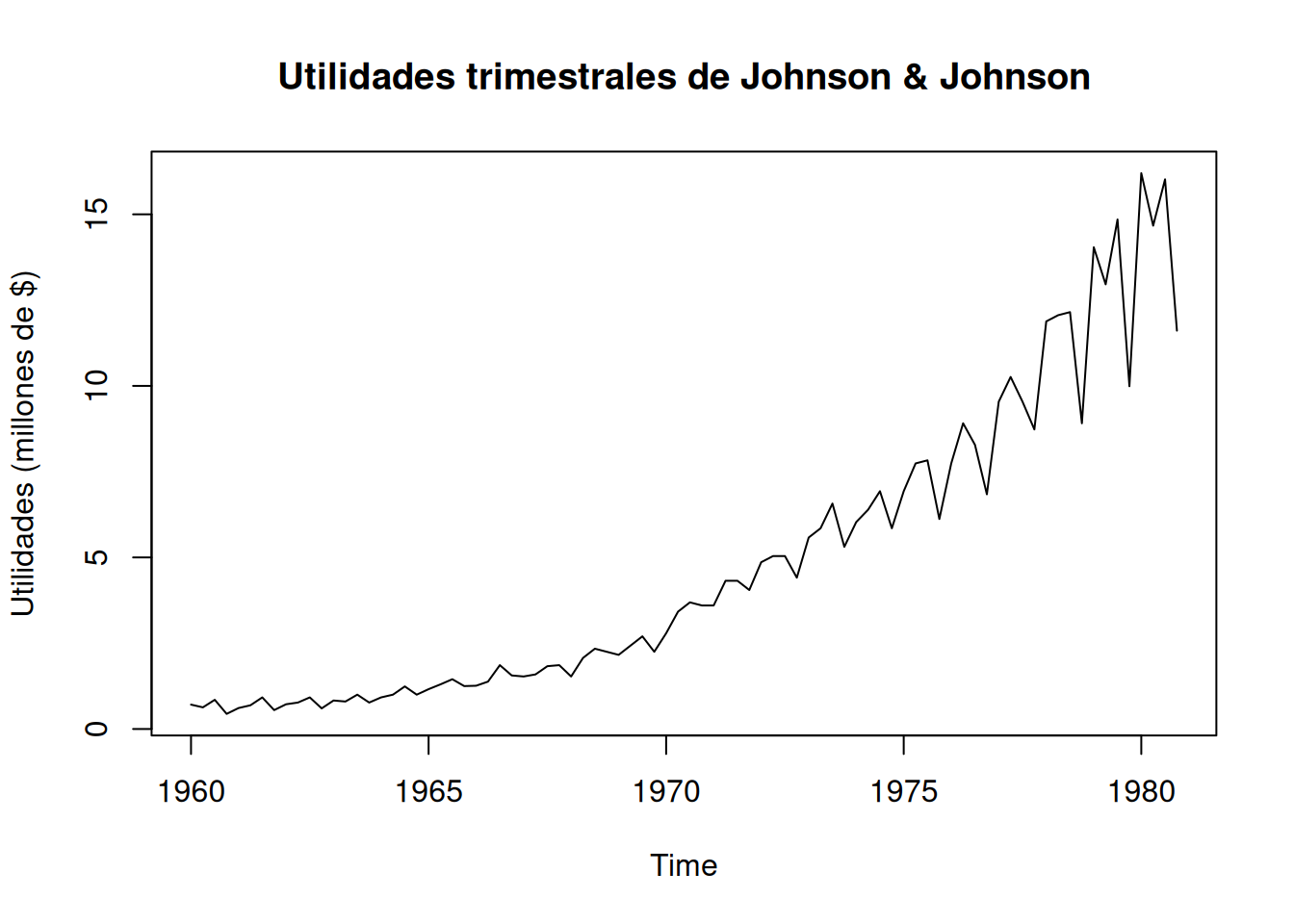
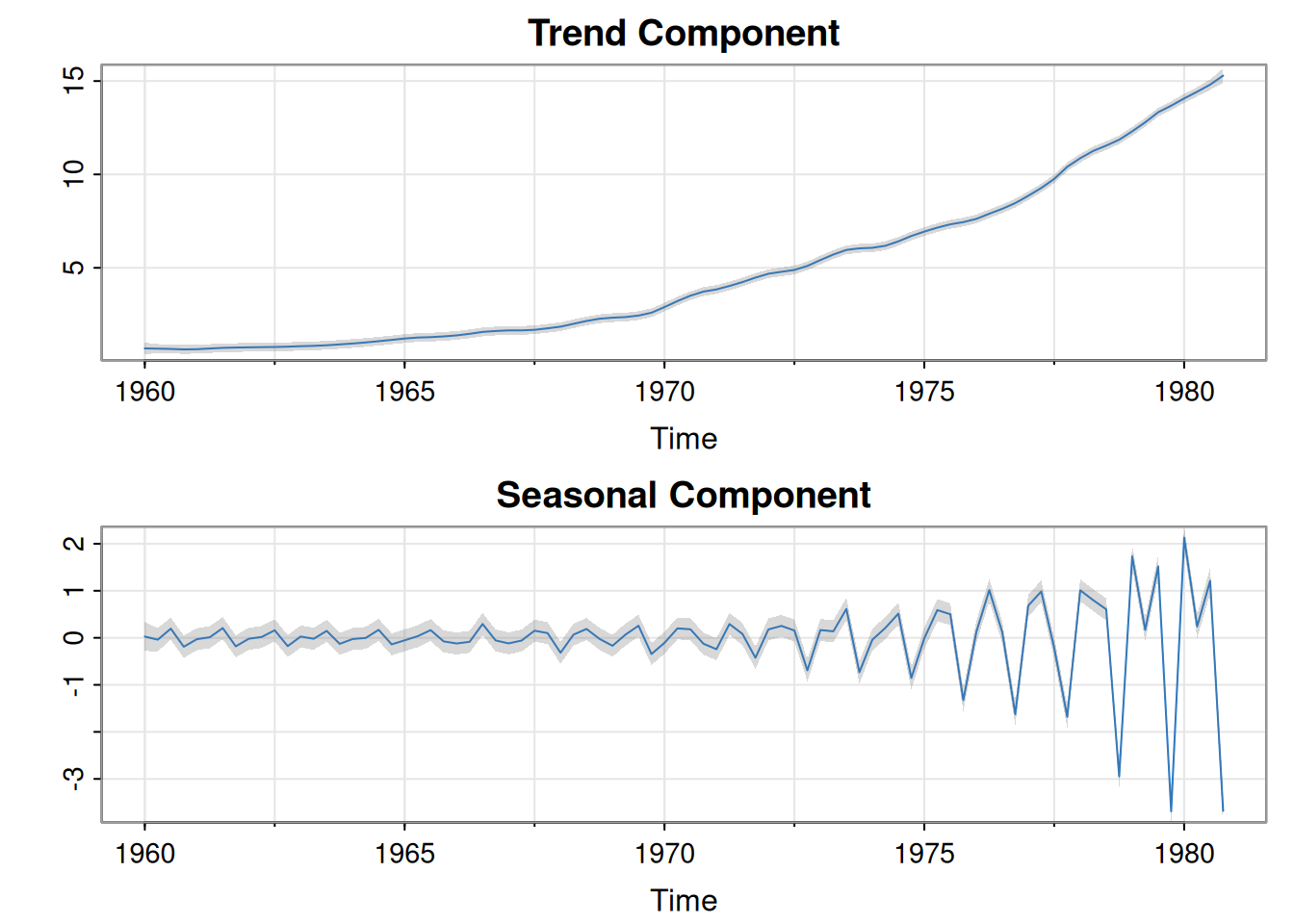
Los modelos estructurales descomponen una serie temporal en componentes con interpretación directa (tendencia, estacionalidad y ruido). Se integran naturalmente al marco de espacio de estados, lo que facilita la extracción de señal (filtro/suavizador de Kalman) y el pronóstico. Se ilustra con las utilidades trimestrales de Johnson & Johnson, donde se modelan tendencia creciente y estacionalidad trimestral.
6.6.1 Modelo estructural y componentes
Usamos como datos para motivar el modelo estructural, los datos de Johnson y Johnson:
data(jj)plot(jj, main="Utilidades trimestrales de Johnson & Johnson", ylab="Utilidades (millones de $)")
Sea la serie observada \[
\begin{equation*}
y_{t}=T_{t}+S_{t}+v_{t},
\end{equation*}
\] donde \(T_t\) es la tendencia, \(S_t\) la estacionalidad y \(v_t\) ruido blanco. Se asume tendencia con crecimiento exponencial: \[
\begin{equation*}
T_{t}=\phi T_{t-1}+w_{t1},
\end{equation*}
\] con \(\phi>1\). Para la estacionalidad trimestral: \[
\begin{equation*}
S_{t}+S_{t-1}+S_{t-2}+S_{t-3}=w_{t2}.
\end{equation*}
\]
6.6.2 Formulación como modelo de espacio-estado
Defina el estado \(x_t=\left(T_t,S_t,S_{t-1},S_{t-2}\right)'\).
Ecuación de observación:\[
y_t=\begin{pmatrix}1&1&0&0\end{pmatrix}
\begin{pmatrix}T_t\\ S_t\\ S_{t-1}\\ S_{t-2}\end{pmatrix}+v_t.
\]
Por lo tanto el modelo planteado es de espacio-estado con \(p=4\), \(q=1\).
Parámetros e inicialización
Parámetros a estimar: \(r_{11}\), \(q_{11}\), \(q_{22}\) y \(\phi\). Se parte de crecimiento anual cercano a \(3%\) con \(\phi=1.03\). Media inicial \(\mu_0=(.7,0,0,0)'\) y covarianza inicial diagonal con \(\Sigma_{0ii}=.04\) (\(i=1,\dots,4\)). Valores iniciales: \(q_{11}=.01\), \(q_{22}=.01\), \(r_{11}=.25\).
6.6.3 Resultados de estimación y extracción de señal
Tras ~20 iteraciones (Newton–Raphson), \(\hat{\phi}=1.035\) (crecimiento \(\approx 3.5%\) anual). Incertidumbre de medición pequeña: \(\sqrt{\hat r_{11}}=.0005\) frente a las incertidumbres de modelo \(\sqrt{\hat q_{11}}=.1397\) y \(\sqrt{\hat q_{22}}=.2209\). Se obtienen los estimadores suavizados \(T_t^{n}\) y \(S_t^{n}\) (con bandas de error RMS ×3), mostrando tendencia creciente y estacionalidad que aumenta con el tiempo.
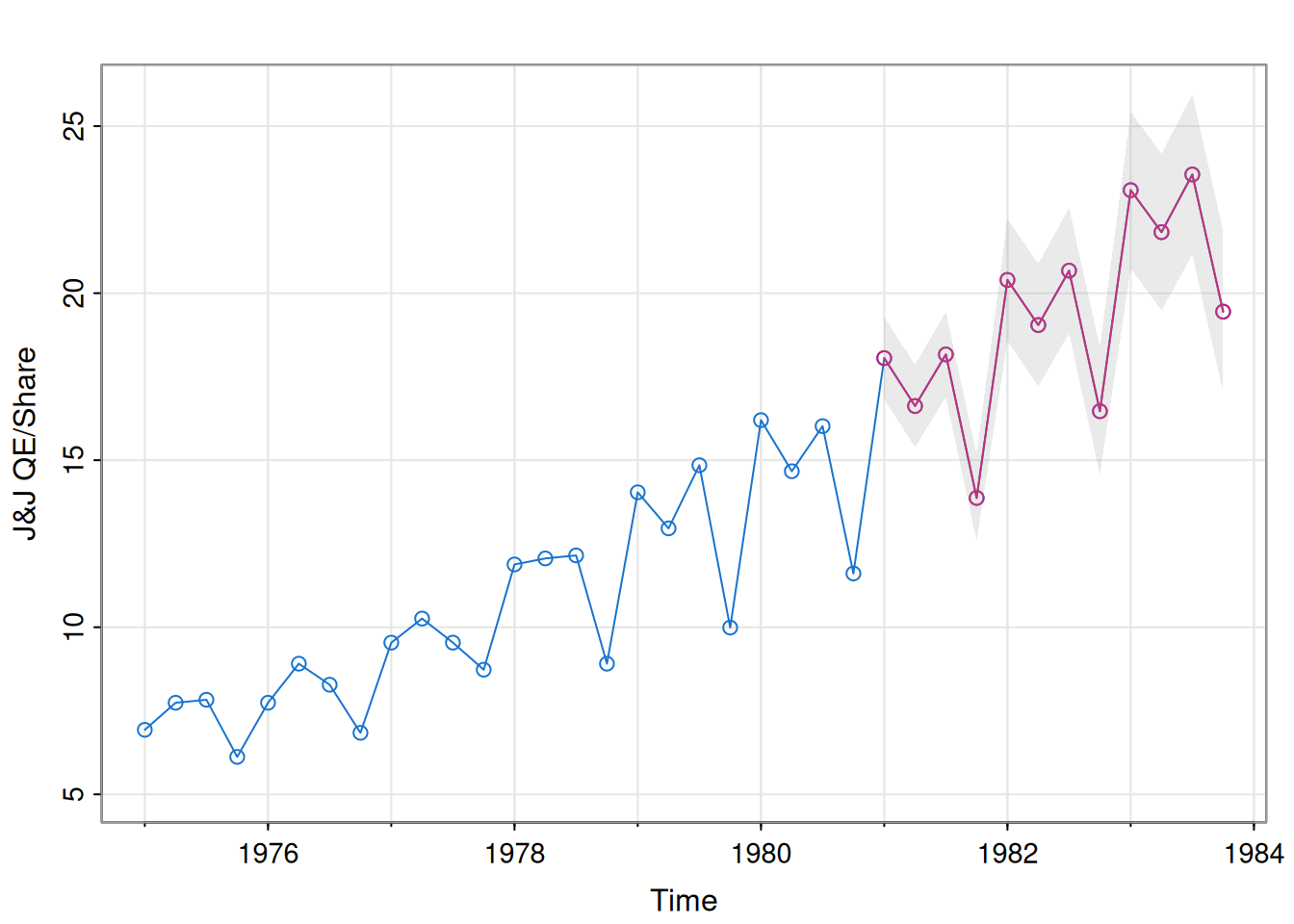
6.6.4 Pronóstico
Se realiza un pronóstico a 12 trimestres, esencialmente continuando la dinámica reciente de la serie (extensión de los últimos datos observados) usando la forma de innovaciones y la propagación del estado/covarianza.
6.6.5 Código R: estimación por máxima verosimilitud y suavizado
A =cbind(1,1,0,0) # measurement matrix# Function to Calculate LikelihoodLinn =function(para){ Phi =diag(0,4) Phi [1,1] = para[1] Phi [2,]=c(0,-1,-1,-1); Phi [3,]=c(0,1,0,0); Phi [4,]=c(0,0,1,0) sQ1 = para[2]; sQ2 = para[3] # sqrt q11 and sqrt q22 sQ =diag(0,4); sQ[1,1]=sQ1; sQ[2,2]=sQ2 sR = para[4] # sqrt r11 kf =Kfilter(jj, A, mu0, Sigma0, Phi, sQ, sR)return(kf$like) }# Initial Parametersmu0 =c(.7,0,0,0)Sigma0 =diag(.04, 4)init.par =c(1.03, .1, .1, .5) # Phi[1,1], the 2 sQs and sR# Estimationest =optim(init.par, Linn, NULL, method="BFGS", hessian=TRUE,control=list(trace=1,REPORT=1))
initial value 2.693644
iter 2 value -0.853526
iter 3 value -9.416505
iter 4 value -10.241752
iter 5 value -19.419809
iter 6 value -30.441188
iter 7 value -31.825543
iter 8 value -32.248413
iter 9 value -32.839918
iter 10 value -33.019870
iter 11 value -33.041749
iter 12 value -33.050583
iter 13 value -33.055492
iter 14 value -33.078152
iter 15 value -33.096870
iter 16 value -33.098405
iter 17 value -33.099018
iter 18 value -33.099385
iter 19 value -33.099498
iter 19 value -33.099498
final value -33.099498
converged
6.7 Modelos de espacio-estado con errores correlacionados
Se estudia una formulación del modelo de espacio de estados que permite correlación contemporánea entre el ruido del estado y el ruido de observación. Con esta formulación se obtienen expresiones de filtro y predicción y se muestran aplicaciones a ARMAX y a regresión multivariante con errores autocorrelados. Se proporciona una forma general en estado para ARMAX, un ejemplo univariante ARMAX(1,1), y un estudio aplicado sobre mortalidad semanal con temperatura y contaminación, incluyendo código de estimación mediante filtro de Kalman y comparaciones con enfoques preliminares.
6.7.1 Modelo de espacio de estados con errores correlacionados
Es ventajoso escribir el modelo como \[
\begin{equation*}
x_{t+1}=\Phi x_{t}+\Upsilon u_{t+1}+w_{t} \quad t=0,1, \ldots, n
\end{equation*}
\]
con \(x_{0}\sim \mathrm{N}_{p}(\mu_{0},\Sigma_{0})\), \(w_t\sim \text{iid }\mathrm{N}_{p}(0,Q)\), \(v_t\sim \text{iid }\mathrm{N}_{q}(0,R)\), y ruidos correlacionados en tiempo \(t\): \[
\begin{equation*}
\operatorname{cov}\left(w_{s}, v_{t}\right)=S \delta_{s}^{t}.
\end{equation*}
\] donde \(\delta_s^t\) es una delta de Kronecker. La diferencia respecto al modelo de espacio-estado originalmente definido es que el ruido de estado inicia en \(t=0\) para manejar la covarianza concurrente entre \(w_t\) y \(v_t\).
Para obtener innovaciones \(\epsilon_t=y_t-A_t x_t^{t-1}-\Gamma u_t\) y su varianza \(\Sigma_t=A_t P_t^{t-1}A_t'+R\), se requieren los predictores un paso adelante y las actualizaciones filtradas.
6.7.2 Propiedad: Filtro de Kalman con ruido correlacionado
Para el modelo de espacio-estado correlacionado, con condiciones iniciales \(x_{1}^{0}\) y \(P_{1}^{0}\), para \(t=1,\ldots,n\): \[
\begin{gather*}
x_{t+1}^{t}=\Phi x_{t}^{t-1}+\Upsilon u_{t+1}+K_{t} \epsilon_{t} \\
P_{t+1}^{t}=\Phi P_{t}^{t-1} \Phi^{\prime}+Q-K_{t} \Sigma_{t} K_{t}^{\prime}
\end{gather*}
\] donde \(\epsilon_t=y_t-A_t x_t^{t-1}-\Gamma u_t\) y la ganancia es \[
\begin{equation*}
K_{t}=\left[\Phi P_{t}^{t-1} A_{t}^{\prime}+S\right]\left[A_{t} P_{t}^{t-1} A_{t}^{\prime}+R\right]^{-1}.
\end{equation*}
\] Los valores filtrados son \[
\begin{gather*}
x_{t}^{t}=x_{t}^{t-1}+P_{t}^{t-1} A_{t}^{\prime}\left[A_{t} P_{t}^{t-1} A_{t}^{\prime}+R\right]^{-1} \epsilon_{t} \\
P_{t}^{t}=P_{t}^{t-1}-P_{t}^{t-1} A_{t+1}^{\prime}\left[A_{t} P_{t}^{t-1} A_{t}^{\prime}+R\right]^{-1} A_{t} P_{t}^{t-1}.
\end{gather*}
\] Con la siguiente inicialización del filtro: \[
x_{1}^{0}=\mathrm{E}(x_1)=\Phi \mu_{0}+\Upsilon u_{1},\quad
P_{1}^{0}=\operatorname{var}(x_1)=\Phi \Sigma_{0}\Phi'+Q.
\]
6.7.3 Modelos ARMAX y su forma en espacio de estados
Propiedad: Una forma en espacio de estados para ARMAX
Para \(p\ge q\), defina \[
F=\left[\begin{array}{ccccc}
\Phi_{1} & I & 0 & \cdots & 0 \\
\Phi_{2} & 0 & I & \cdots & 0 \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
\Phi_{p-1} & 0 & 0 & \cdots & I \\
\Phi_{p} & 0 & 0 & \cdots & 0
\end{array}\right],\quad
G=\left[\begin{array}{c}
\Theta_{1}+\Phi_{1} \\
\vdots \\
\Theta_{q}+\Phi_{q} \\
\Phi_{q+1} \\
\vdots \\
\Phi_{p}
\end{array}\right],\quad
H=\left[\begin{array}{c}
\Gamma \\
0 \\
\vdots \\
0
\end{array}\right],
\] donde \(F\) es \(kp\times kp\), \(G\) es \(kp\times k\) y \(H\) es \(kp\times r\). Entonces \[
\begin{align*}
x_{t+1} & =F x_{t}+H u_{t+1}+G v_{t} \\
y_{t} & =A x_{t}+v_{t},
\end{align*}
\] con \(A=[I,0,\ldots,0]\) (\(k\times pk\)), implica el modelo ARMAX recién definido. Si \(p<q\), tome \(\Phi_{p+1}=\cdots=\Phi_q=0\) para que \(p=q\) y que el modelo de espacio-estado aplique. El estado es \(kp\)-dimensional y la observación \(k\)-dimensional.
6.7.3.1 Ejemplo: ARMAX(1,1) univariante en forma de estado
Considere \(\operatorname{ARMAX}(1,1)\): \[
y_{t}=\alpha_{t}+\phi y_{t-1}+\theta v_{t-1}+v_{t},\quad \alpha_t=\Gamma u_t.
\] Por la propiedad anterior: \[
\begin{gather*}
x_{t+1}=\phi x_{t}+\alpha_{t+1}+(\theta+\phi) v_{t} \\
y_{t}=x_{t}+v_{t}.
\end{gather*}
\] ver la página 348 del libro para detalles de la verificación directa.
6.7.4 Regresión multivariante con errores autocorrelacionados
Se ajusta \[
\begin{equation*}
y_{t}=\Gamma u_{t}+\varepsilon_{t},
\end{equation*}
\] donde \(y_t\) es \(k\times 1\), \(u_t\in\mathbb{R}^r\) y \(\varepsilon_t\) es ARMA\((p,q)\) vectorial. Como \(\varepsilon_t=y_t-\Gamma u_t\) es ARMA\((p,q)\), tomando \(H=0\) y agregando \(\Gamma u_t\) en la formulación del modelo de espacio-estado: \[
\begin{align*}
x_{t+1} & =F x_{t}+G v_{t}, \\
y_{t} & =\Gamma u_{t}+A x_{t}+v_{t}, \
\end{align*}
\] donde \(A,F,G\) provienen de la definición del modelo de espacio-estado anterior. Así, \(\varepsilon_t=y_t-\Gamma u_t\) es ARMA\((p,q)\) vectorial.