En este capítulo se introduce la inferencia bayesiana en el contexto de modelos estadísticos que involucran un único parámetro escalar, es decir, cuando el estimando \(\theta\) es unidimensional. Se presentan cuatro modelos fundamentales y ampliamente utilizados: el binomial, el normal, el de Poisson y el exponencial. Además, se introducen conceptos importantes y métodos computacionales para el análisis bayesiano de datos.
2.1 Estimación de una Probabilidad a partir de Datos Binomiales
El modelo binomial tiene como objetivo estimar una proporción poblacional desconocida a partir de los resultados de una serie de “ensayos de Bernoulli” (datos \(y_1, \ldots, y_n\), cada uno de los cuales es 0 o 1). Debido a la intercambiabilidad de los ensayos, los datos se pueden resumir mediante el número total de éxitos, denotado por \(y\). Se modela el parámetro \(\theta\) como la proporción de éxitos en la población o, equivalentemente, como la probabilidad de éxito en cada ensayo. La función de muestreo binomial se expresa como
2.1.1 Ejemplo: Estimación de la Probabilidad de un Nacimiento Femenino
Como aplicación específica del modelo binomial, se estima la razón de sexos en una población de nacimientos. Aquí, el parámetro \(\theta\) representa la proporción de nacimientos femeninos. Se asume que los \(n\) nacimientos son condicionalmente independientes dado \(\theta\), con la probabilidad de un nacimiento femenino igual a \(\theta\). Para simplificar, se utiliza una distribución a priori uniforme en \([0,1]\). Aplicando la regla de Bayes (ignorando factores constantes), se obtiene la densidad posterior:
Esta densidad se identifica como la forma no normalizada de una distribución beta, de modo que
\[
\theta \mid y \sim \operatorname{Beta}(y+1,\, n-y+1).
\]
2.1.2 Nota Histórica: Bayes y Laplace
Los primeros trabajos sobre probabilidad se centraron en el modelo binomial. Jacob Bernoulli, en su “ley débil de los grandes números”, mostró que la frecuencia relativa converge a \(\theta\) conforme aumenta el número de ensayos. Thomas Bayes, cuyo trabajo se publicó póstumamente en 1763, fue el primero en invertir la declaración de probabilidad para obtener inferencias sobre \(\theta\) dado \(y\). Utilizando una analogía física (una bola lanzada sobre una mesa rectangular), Bayes derivó fórmulas para calcular probabilidades condicionales de intervalos para \(\theta\).
Posteriormente, Pierre-Simon Laplace redescubrió el teorema de Bayes y desarrolló herramientas analíticas (como la aproximación normal) para evaluar integrales incompletas, aplicándolo en problemas como la estimación de la proporción de nacimientos femeninos.
Por ejemplo, Laplace analizó datos de nacimientos en París y mostró que la probabilidad de que la proporción de nacimientos femeninos sea al menos 0.5 era prácticamente cero, lo que le permitía estar “moralmente seguro” de que \(\theta < 0.5\).
2.2 Predicción en el Modelo Binomial
Con una distribución a priori uniforme, la distribución predictiva a priori para \(y\) se evalúa explícitamente, ya que todos los valores posibles de \(y\) son igualmente probables a priori. Para la predicción posterior, se puede interesar en el resultado de un nuevo ensayo, \(\tilde{y}\), que es intercambiable con los \(n\) ensayos iniciales. La probabilidad predictiva de que \(\tilde{y}=1\) se obtiene integrando la probabilidad condicional sobre la densidad posterior:
Este resultado, conocido como “la ley de sucesión de Laplace”, predice que, en el caso extremo de observar \(y=0\) o \(y=n\), las probabilidades de obtener éxito en un nuevo ensayo son \(\frac{1}{n+2}\) y \(\frac{n+1}{n+2}\), respectivamente.
2.3 Posterior como Compromiso entre Datos e Información a Priori
El proceso de inferencia bayesiana consiste en pasar de una distribución a priori, \(p(\theta)\), a una distribución posterior, \(p(\theta \mid y)\). Es natural esperar que existan relaciones generales entre ambas distribuciones. Por ejemplo, dado que la distribución posterior incorpora la información de los datos, se espera que su variabilidad sea, en promedio, menor que la de la distribución a priori.
Esta idea se formaliza en las siguientes expresiones:
La primera ecuación indica que la media a priori de \(\theta\) es el promedio de todas las medias posteriores posibles, ponderado por la distribución de los datos. La fórmula de la varianza es más interesante, ya que establece que, en promedio, la varianza posterior es menor que la varianza a priori; la reducción en la incertidumbre depende de la variación de las medias posteriores a lo largo de la distribución de los datos. En otras palabras, a mayor variación en las medias posteriores, mayor es la posibilidad de reducir nuestra incertidumbre sobre \(\theta\).
En el ejemplo binomial con una prior uniforme, la media a priori es \(1/2\) y la varianza a priori es \(1/12\). La media posterior, expresada como \((y+1)/(n+2)\), representa un compromiso entre la media a priori y la proporción muestral \(y/n\). A medida que aumenta el tamaño de la muestra, el peso de la información a priori disminuye y la influencia de los datos se hace predominante.
Esta característica general del enfoque bayesiano muestra que la distribución posterior se centra en un valor que resulta del compromiso entre la información previa y los datos observados, siendo cada vez más dominada por los datos conforme se incrementa el tamaño muestral.
2.4 Resumen de la Inferencia Posterior
La distribución de probabilidad posterior, \(p(\theta \mid y)\), contiene toda la información actual acerca del parámetro \(\theta\). Idealmente, se podría reportar la distribución completa, y en muchos casos resulta útil presentarla gráficamente. En problemas de múltiples parámetros se emplean gráficos de contorno y diagramas de dispersión, pero en el caso de un parámetro único la visualización resulta más sencilla.
Una ventaja clave del enfoque bayesiano, especialmente cuando se utiliza la simulación, es la gran flexibilidad para resumir inferencias posteriores, incluso tras realizar transformaciones complejas. No obstante, para fines prácticos es habitual resumir la distribución posterior mediante:
Resúmenes puntuales:
Por ejemplo, la media, mediana y la(s) moda(s) del parámetro. Cada uno tiene su propia interpretación; la media es la expectativa posterior, mientras que la moda puede considerarse el valor “más probable” dado el modelo y los datos. En modelos con forma cerrada, como el caso de la distribución beta en nuestro ejemplo, estos resúmenes pueden obtenerse en forma analítica. Por ejemplo, para el modelo binomial con prior uniforme se demuestra que la media posterior es \(\frac{y+1}{n+2}\) y la moda es \(\frac{y}{n}\).
Medidas de variabilidad:
La incertidumbre se resume mediante la desviación estándar, el rango intercuartílico u otros cuantiles.
Intervalos de probabilidad:
Es fundamental reportar la incertidumbre posterior. Un enfoque común es presentar intervalos centrales de probabilidad, es decir, un intervalo de \(100(1-\alpha)\%\) que deja \(100(\alpha/2)\%\) de probabilidad en cada cola de la distribución.
Alternativamente, se puede resumir la incertidumbre mediante la región de máxima densidad posterior (HPD, por sus siglas en inglés), que es el conjunto de valores de \(\theta\) que contiene \(100(1-\alpha)\%\) de la probabilidad y, además, en el que la densidad es siempre mayor que en el exterior.
En distribuciones unimodales y simétricas, el intervalo central y la HPD coinciden, pero pueden diferir notablemente en casos de distribuciones bimodales o altamente sesgadas.
En resumen, la inferencia bayesiana permite combinar de forma coherente la información previa con los datos para obtener una distribución posterior que, a su vez, se puede resumir mediante medidas puntuales y de dispersión, así como mediante intervalos que expresen la incertidumbre en la estimación de \(\theta\).
2.5 Distribuciones a Priori Informativas
En el ejemplo binomial se ha considerado hasta ahora la distribución a priori uniforme para \(\theta\). Sin embargo, ¿cómo se justifica esta especificación y, en general, cómo se construyen distribuciones a priori?
Existen dos interpretaciones básicas de una distribución a priori:
Interpretación poblacional:
La distribución a priori representa una población de posibles valores de \(\theta\) de la cual se extrae el valor actual.
Interpretación subjetiva (estado de conocimiento):
Se expresa el conocimiento (y la incertidumbre) sobre \(\theta\) como si su valor fuera una realización aleatoria de la distribución a priori.
En muchos problemas (por ejemplo, estimar la probabilidad de fallo en un proceso industrial), no existe una población relevante de \(\theta\)s, y la distribución a priori se elige de forma hipotética. La distribución a priori debe incluir todos los valores plausibles de \(\theta\), aunque no necesariamente esté concentrada alrededor del valor verdadero, ya que la información contenida en los datos suele dominar.
2.5.1 Ejemplo Binomial con Distribuciones a Priori Informativas
En el modelo binomial, se puede ampliar la especificación de la distribución a priori utilizando una familia paramétrica que incluye a la uniforme como caso especial. Para ello, se utiliza la distribución beta:
donde \(\alpha\) y \(\beta\) son los hiperparámetros. Esta formulación se interpreta como tener \(\alpha-1\) éxitos y \(\beta-1\) fracasos a priori. Al combinar esta distribución a priori con la función de verosimilitud binomial
la cual es un compromiso entre el valor muestral \(\frac{y}{n}\) y la media a priori \(\frac{\alpha}{\alpha+\beta}\). Además, la varianza posterior disminuye a medida que aumenta el tamaño muestral, de modo que en el límite la influencia de la información a priori se desvanece.
2.5.2 Conjugación y Distribuciones No Conjugadas
Una distribución a priori es conjugada para un modelo si la distribución posterior pertenece a la misma familia funcional. En el ejemplo binomial, la distribución beta es conjugada, lo que facilita el cómputo y permite interpretar los hiperparámetros como datos adicionales.
Cuando la información disponible no se ajusta bien a una familia conjugada, se pueden utilizar distribuciones a priori no conjugadas. Aunque estas pueden complicar la interpretación y el cómputo, no implican problemas conceptuales nuevos. En modelos complejos, las distribuciones conjugadas a menudo no son posibles, y se recurre a métodos numéricos o simulaciones.
2.5.3 Relación con Familias Exponenciales y Estadísticos Suficientes
Las distribuciones que pertenecen a una familia exponencial tienen conjugados naturales. Una familia exponencial se define por:
donde \(\phi(\theta)\) es el parámetro natural y \(u(y_i)\) es una función de la observación. Para una muestra de tamaño \(n\), la función de verosimilitud depende de los datos a través del estadístico suficiente
lo que confirma la propiedad de conjugación para las familias exponenciales.
2.5.4 Ejemplo: Probabilidad de un Nacimiento Femenino Dado Placenta Previa
En este ejemplo se analiza cómo la condición de placenta previa, en la que la placenta se implanta en la parte baja del útero impidiendo un parto vaginal normal, puede influir en la razón de sexos. Un estudio temprano en Alemania, realizado con 980 nacimientos con placenta previa, encontró que 437 de ellos fueron niñas. Esto plantea la pregunta: ¿cuánta evidencia hay para afirmar que la proporción de nacimientos femeninos en casos de placenta previa es menor a 0.485 (la proporción observada en la población general)?
2.5.4.1 Análisis con Distribución a Priori Uniforme
Distribución a Priori y Posterior:
Usando una distribución a priori uniforme para la probabilidad de un nacimiento femenino, se obtiene una distribución posterior:
\[
\theta \mid y \sim \operatorname{Beta}(438,544).
\]
Resúmenes Exactos de la Posterior:
Las propiedades de la distribución beta permiten calcular:
Media posterior: 0.446.
Desviación estándar posterior: 0.016.
Intervalo central del 95%: \([0.415,\, 0.477]\).
Estos resúmenes coinciden, a tres decimales, con los obtenidos mediante una aproximación normal basada en la media y la desviación estándar calculadas.
2.5.5 Análisis mediante Simulación
Dado que en muchas situaciones no es factible calcular la densidad posterior de forma analítica, se puede utilizar la simulación para obtener inferencias:
Se generan 1000 muestras de la posterior \(\operatorname{Beta}(438,544)\).
El intervalo del 95% obtenido a partir de los percentiles (25º y 976º de 1000 ordenados) es \([0.415,\, 0.476]\).
La mediana, el promedio y la desviación estándar de estas muestras simuladas son 0.446, 0.445 y 0.016, respectivamente, valores muy similares a los exactos.
Una aproximación normal al intervalo, \([0.445 \pm 1.96 \times 0.016]\), resulta en \([0.414,\, 0.476]\), lo que confirma la validez de la aproximación dado el gran tamaño muestral y la concentración de la distribución lejos de los extremos 0 y 1.
# Fijamos la semilla para reproducibilidadset.seed(123)# Generamos 1000 muestras de la distribución Beta(438,544)ps <-rbeta(1000, 438, 544)# Extraemos los percentiles 2.5% y 97.5%lower<-quantile(ps,probs =0.025) upper <-quantile(ps,probs =0.975)# Calculamos la mediana, la media y la desviación estándar de las muestras simuladasmedian_ps <-median(ps)mean_ps <-mean(ps)sd_ps <-sd(ps)# Calculamos el intervalo de confianza del 95% usando la aproximación normalnormal_lower <- mean_ps -qnorm(0.975) * sd_psnormal_upper <- mean_ps +qnorm(0.975) * sd_ps# Imprimimos los resultadoscat("Posterior median:", round(median_ps, 3), "\n")
En la escala logit se puede observar que, a partir de simulaciones, se obtiene: - Media: -0.220. - Desviación estándar: 0.065.
Al invertir el intervalo del 95% en la escala logit, es decir, calcular
\[
[-0.220 \pm 1.96 \times 0.065],
\]
se obtiene nuevamente un intervalo aproximado de \([0.414,\, 0.477]\) para \(\theta\).
A continuación se muestra un ejemplo en R que ilustra este procedimiento:
# Definimos la función de transformación logit y su inversalogit <-function(p) {log(p / (1- p))}inv_logit <-function(x) {exp(x) / (1+exp(x))}# Transformamos las muestras a la escala logittheta_logit <-logit(ps)# Calculamos la media y la desviación estándar en la escala logitmean_logit <-mean(theta_logit)sd_logit <-sd(theta_logit)# Calculamos el intervalo del 95% en la escala logit usando la aproximación normallower_logit <- mean_logit -1.96* sd_logitupper_logit <- mean_logit +1.96* sd_logit# Invertimos la transformación para obtener el intervalo para thetalower_theta <-inv_logit(lower_logit)upper_theta <-inv_logit(upper_logit)# Mostramos los resultadoscat("En la escala logit:\n")
A continuación se resume la posterior para \(\theta\) bajo diversas especificaciones de distribuciones a priori conjugadas (familia beta) con diferentes niveles de información previa. Se observa que:
Con un prior uniforme (equivalente a poca información previa), la posterior tiene una mediana de 0.446 y un intervalo del 95% de \([0.415,\, 0.477]\).
A medida que se aumenta la cantidad de información previa (es decir, aumentando \(\alpha+\beta\)), los resúmenes posteriores se desplazan ligeramente hacia la media a priori (por ejemplo, 0.485 en la población general), pero la diferencia es mínima en muestras grandes.
El siguiente código en R ilustra cómo calcular estos resúmenes para el ejemplo de placenta previa, donde se tienen \(y=437\) éxitos (nacimientos femeninos) en \(n=980\) ensayos:
# Datos del ejemplo: placenta previay <-437n <-980# Función para calcular la mediana y el intervalo del 95% de la posteriorposterior_summary <-function(alpha, beta, y, n) { post_alpha <- alpha + y post_beta <- beta + n - y median_post <-qbeta(0.5, post_alpha, post_beta) ci_lower <-qbeta(0.025, post_alpha, post_beta) ci_upper <-qbeta(0.975, post_alpha, post_beta)return(c(median = median_post, lower = ci_lower, upper = ci_upper))}# Especificaciones de priors:# Cada prior se define mediante su media deseada y el tamaño (alpha+beta).# Para un prior Beta, la media es alpha/(alpha+beta).prior_means <-c(0.5, 0.485, 0.485, 0.485, 0.485, 0.485, 0.485)prior_sizes <-c(2, 2, 5, 10, 20, 100, 200) # (alpha + beta)# Inicializamos una tabla para almacenar los resultadosresults <-data.frame(PriorMean =numeric(), PriorSize =numeric(), PostMedian =numeric(), CI_Lower =numeric(), CI_Upper =numeric())# Calculamos la mediana y el intervalo posterior para cada especificación del priorfor (i in1:length(prior_means)) { m0 <- prior_means[i] size <- prior_sizes[i] alpha <- m0 * size beta <- size - alpha sum_values <-posterior_summary(alpha, beta, y, n) results <-rbind(results, data.frame(PriorMean = m0, PriorSize = size, PostMedian =round(sum_values["median"], 3),CI_Lower =round(sum_values["lower"], 3), CI_Upper =round(sum_values["upper"], 3)))}print(results)
2.6 Estimación de la Media Normal con Varianza Conocida
2.6.1 Introducción
La distribución normal es fundamental en la modelización estadística, en parte debido al teorema central del límite, que justifica el uso de la verosimilitud normal en numerosos problemas. Incluso si la normal no es el modelo perfecto, puede formar parte de modelos más complejos (como los modelos \(t\) o mezclas finitas). En este tema, se desarrollan los resultados bayesianos asumiendo que el modelo normal es adecuado, comenzando con un único dato y luego extendiéndose a múltiples observaciones.
2.6.2 Caso de un Solo Dato
2.6.2.1 Verosimilitud
Para una única observación escalar \(y\), se asume que
La media posterior\(\mu_1\) es un promedio ponderado entre la media a priori \(\mu_0\) y el dato observado \(y\), donde los pesos son las precisiones (inversas de la varianza).
Así, la predicción incorpora la variabilidad del modelo (\(\sigma^2\)) y la incertidumbre en la estimación de \(\theta\) (\(\tau_1^2\)).
2.6.4 Extensión a Múltiples Observaciones
Cuando se dispone de una muestra \(y = (y_1, \ldots, y_n)\), donde cada \(y_i \sim \operatorname{N}(\theta,\, \sigma^2)\) de manera independiente, la verosimilitud es
Combinando esta verosimilitud con la prior normal, se obtiene que el posterior depende de los datos únicamente a través del promedio muestral \(\bar{y}\) (estadístico suficiente):
\[
\theta \mid y \sim \operatorname{N}(\mu_n,\, \tau_n^2),
\]
La precisión a priori, \(1/\tau_0^2\), y la precisión de los datos, \(n/\sigma^2\), se suman para formar la precisión posterior.
Con muestras grandes, la influencia del prior disminuye y el posterior se aproxima a
\[
\theta \mid y \approx \operatorname{N}\left(\bar{y},\, \frac{\sigma^2}{n}\right).
\]
2.7 Distribución Normal con Media Conocida y Varianza Desconocida
2.7.1 Introducción
El modelo normal con media conocida \(\theta\) y varianza desconocida \(\sigma^2\) es un ejemplo clave, no tanto por su aplicación directa, sino por servir de base para modelos más complejos. Además, este modelo ilustra la estimación de un parámetro de escala.
2.7.2 Modelo y Verosimilitud
Dado que \(\theta\) es conocida, consideramos que cada observación \(y_i\) se distribuye normalmente como
\[
v = \frac{1}{n} \sum_{i=1}^{n} (y_i-\theta)^2.
\]
2.7.3 Distribución a Priori Conjugada
Para estimar \(\sigma^2\), se utiliza una distribución a priori conjugada que es la gamma inversa. Una forma conveniente de parametrizarla es mediante la distribución escalada inversa-\(\chi^2\) (Scaled inverse chi-squared distribution):
donde \(\nu_0\) representa los grados de libertad a priori y \(\sigma_0^2\) es la escala a priori. Esta distribución puede interpretarse como si la información previa aportara la equivalencia a \(\nu_0\) observaciones con una desviación cuadrática promedio de \(\sigma_0^2\).
2.7.4 Distribución Posterior
La densidad posterior para \(\sigma^2\) se obtiene multiplicando la verosimilitud por la distribución a priori:
\[
\sigma^2 \mid y \sim \operatorname{Inv}-\chi^2\left(\nu_0+n,\; \frac{\nu_0\sigma_0^2+n\,v}{\nu_0+n}\right).
\]
En esta forma:
Los grados de libertad de la posterior son la suma de los grados de libertad previos y el tamaño muestral: \(\nu_0+n\).
La escala posterior es la media ponderada (por los grados de libertad) de la escala a priori y el estadístico \(v\) obtenido de los datos.
2.8 Modelo Poisson
2.8.1 Introducción
El modelo Poisson es fundamental para analizar datos en forma de conteos, siendo muy utilizado en áreas como la epidemiología para estudiar la incidencia de enfermedades. Este modelo describe la probabilidad de observar un número de eventos en un intervalo dado cuando estos ocurren de manera independiente y a una tasa constante.
2.8.2 Modelo y Verosimilitud
Distribución de un Dato:
Si un dato \(y\) sigue una distribución Poisson con tasa \(\theta\), su función de masa de probabilidad es
Esto corresponde a una distribución Gamma con parámetros \(\alpha\) y \(\beta\), denotada como \(\operatorname{Gamma}(\alpha,\beta)\).
La interpretación es que el prior equivale, en cierta medida, a haber observado un total de \(\alpha-1\) eventos en \(\beta\) observaciones previas.
Posterior:
Al combinar el prior con la verosimilitud, se obtiene que la distribución posterior es
lo que corresponde a la densidad de la distribución negativa binomial.
Esta derivación muestra que la distribución negativa binomial es una mezcla de distribuciones Poisson cuyas tasas \(\theta\) siguen una distribución Gamma.
2.8.5 Modelo Poisson Parametrizado en Términos de Tasa y Exposición
2.8.5.1 Introducción
En muchas aplicaciones, especialmente en epidemiología, es común extender el modelo Poisson para incorporar una variable explicativa que representa la exposición. Este tipo de modelo permite ajustar la tasa de ocurrencia de eventos en función de la exposición de cada unidad.
\(y_i\) es el número de eventos observados en la \(i\)-ésima unidad.
\(x_i\) es el valor conocido de la exposición para la \(i\)-ésima unidad (un número positivo).
\(\theta\) es el parámetro desconocido de interés, llamado tasa.
Este modelo no es intercambiable en los valores individuales \(y_i\), pero sí en los pares \((x_i, y_i)\).
2.8.5.3 Verosimilitud
La verosimilitud para \(\theta\) se obtiene a partir de la función de masa de probabilidad Poisson. Para un vector de datos \(y = (y_1, \ldots, y_n)\), la verosimilitud es
donde se ignoran factores constantes que no dependen de \(\theta\). Es decir, el estadístico suficiente es \(t(y)=\sum_{i=1}^n y_i\), y la verosimilitud se reescribe como
Esta formulación se interpreta, en cierto sentido, como que la distribución a priori equivale a haber observado un total de \(\alpha-1\) eventos en un “tiempo de exposición” de \(\beta\).
2.8.5.5 Distribución Posterior
Al combinar la verosimilitud con la distribución a priori, se obtiene la distribución posterior de \(\theta\):
La distribución exponencial se utiliza comúnmente para modelar “tiempos de espera” y otras variables continuas, positivas y medidas en una escala de tiempo. Es especialmente útil en el análisis de datos de supervivencia o tiempos de vida, debido a su propiedad “sin memoria”.
2.9.2 Función de Densidad
Para un resultado \(y\), dado el parámetro \(\theta\), la distribución de muestreo es
Aquí, \(\theta = 1/E(y \mid \theta)\) se denomina la “tasa”. Matemáticamente, la distribución exponencial es un caso especial de la distribución Gamma con parámetros \((\alpha, \beta) = (1, \theta)\). En este caso, se utiliza como distribución de muestreo para la variable \(y\), no como distribución a priori para un parámetro.
2.9.3 Propiedad de pérdida de memoria
La distribución exponencial posee la propiedad de pérdida de memoria, lo que significa que la probabilidad de que un objeto sobreviva un tiempo adicional \(t\) es independiente del tiempo ya transcurrido. Esto se expresa como
\[
\Pr(y > t+s \mid y > s, \theta) = \Pr(y > t \mid \theta) \quad \text{para cualquier } s, t.
\]
Esta propiedad hace que la distribución exponencial sea natural para modelar tiempos de supervivencia o “vida útil”.
2.9.4 Prior y Posterior Conjugadas
El prior conjugado para el parámetro \(\theta\) en el contexto de una variable exponencial es una distribución Gamma. Es decir, si se asume un prior
lo que, al considerarse como función de \(\theta\), es proporcional a una densidad Gamma con parámetros \((n+1, \, n\bar{y})\). De esta forma, el prior \(\operatorname{Gamma}(\alpha, \beta)\) para \(\theta\) se puede interpretar como si representara \(\alpha-1\) observaciones exponenciales con un tiempo total de espera de \(\beta\).
2.9.5 Ejemplo – Distribución a Priori Informativa para Tasas de Cáncer
2.9.5.1 Introducción
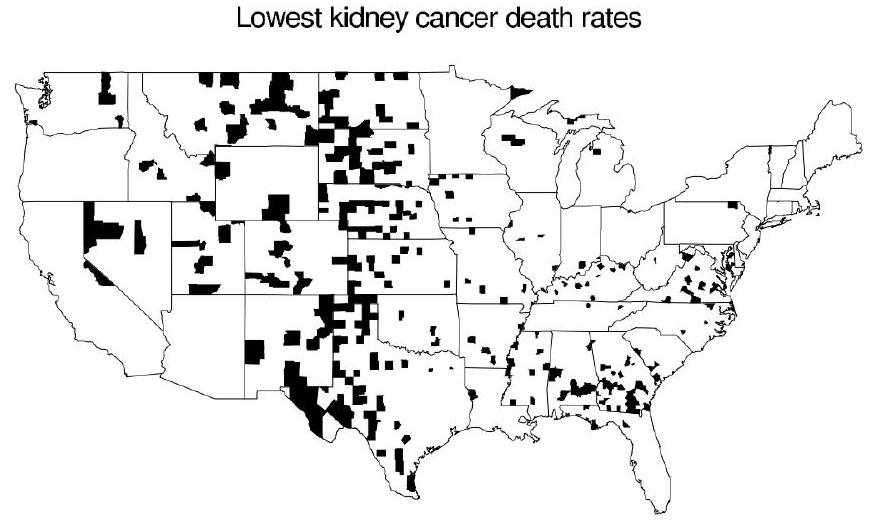
En este ejemplo se ilustra cómo una distribución a priori informativa afecta las inferencias en un problema epidemiológico, y se introduce el concepto de modelado jerárquico. Aquí se analizan las tasas de mortalidad por cáncer de riñón/uréter en los condados de Estados Unidos durante la década de 1980, enfocándose en los patrones dispersos en un mapa.
2.9.5.2 Patrón Inexplicable en Mapas de Tasas de Cáncer
Observación:
En los mapas de tasas crudas de mortalidad por cáncer, se destaca que muchos condados de las Grandes Llanuras (en el centro del país) aparecen tanto entre los más altos como entre los más bajos (ver Figura 2.7, Gelman).
Explicación:
Este fenómeno se debe al tamaño muestral. En condados con poblaciones pequeñas, el número de muertes es muy bajo, lo que genera alta variabilidad en las tasas. Por ejemplo, en un condado pequeño (n = 1000), es muy probable que se observe 0 muertes, pero también existe la posibilidad de observar 1 o 2 muertes, lo que produce tasas “extremas”. Así, tanto las tasas muy bajas como las muy altas se deben a la variabilidad muestral y no a diferencias reales en los riesgos subyacentes.
2.9.5.3 Modelo de Tasas con Información Priori
Para estimar la tasa subyacente de muerte por cáncer en cada condado \(j\), se utiliza el siguiente modelo:
donde: - \(y_j\) es el número de muertes por cáncer en el condado \(j\) durante 1980-1989. - \(n_j\) es la población del condado (en unidades tales que \(10n_j\) representa la exposición en el período de 10 años). - \(\theta_j\) es la tasa verdadera de mortalidad (muertes por persona por año).
Nota: Los mapas muestran las tasas crudas \(\frac{y_j}{10n_j}\).
Se elige una distribución a priori para \(\theta_j\) usando una distribución Gamma, que es conjugada al modelo Poisson. En este ejemplo, se utiliza:
La media posterior se interpreta como un promedio ponderado entre la tasa cruda (\(\frac{y_j}{10n_j}\)) y la media a priori (\(\frac{20}{430,000}\)).
2.9.5.5 Importancia Relativa de los Datos Locales y la Información Priori
En Condados Pequeños - Ejemplo: Condado con \(n_j = 1000\)
Si \(y_j = 0\): La tasa cruda es 0, pero la media posterior es \(\frac{20}{440,000} \approx 4.55 \times 10^{-5}\).
Si \(y_j = 1\): La tasa cruda es aproximadamente \(10^{-4}\), pero la media posterior es \(\frac{21}{440,000} \approx 4.77 \times 10^{-5}\).
Si \(y_j = 2\): La tasa cruda es \(2 \times 10^{-4}\), pero la media posterior es \(\frac{22}{440,000} \approx 5.00 \times 10^{-5}\).
En estos casos, al ser la población pequeña, los datos tienen menor peso y la estimación se ve influenciada mayormente por la prior.
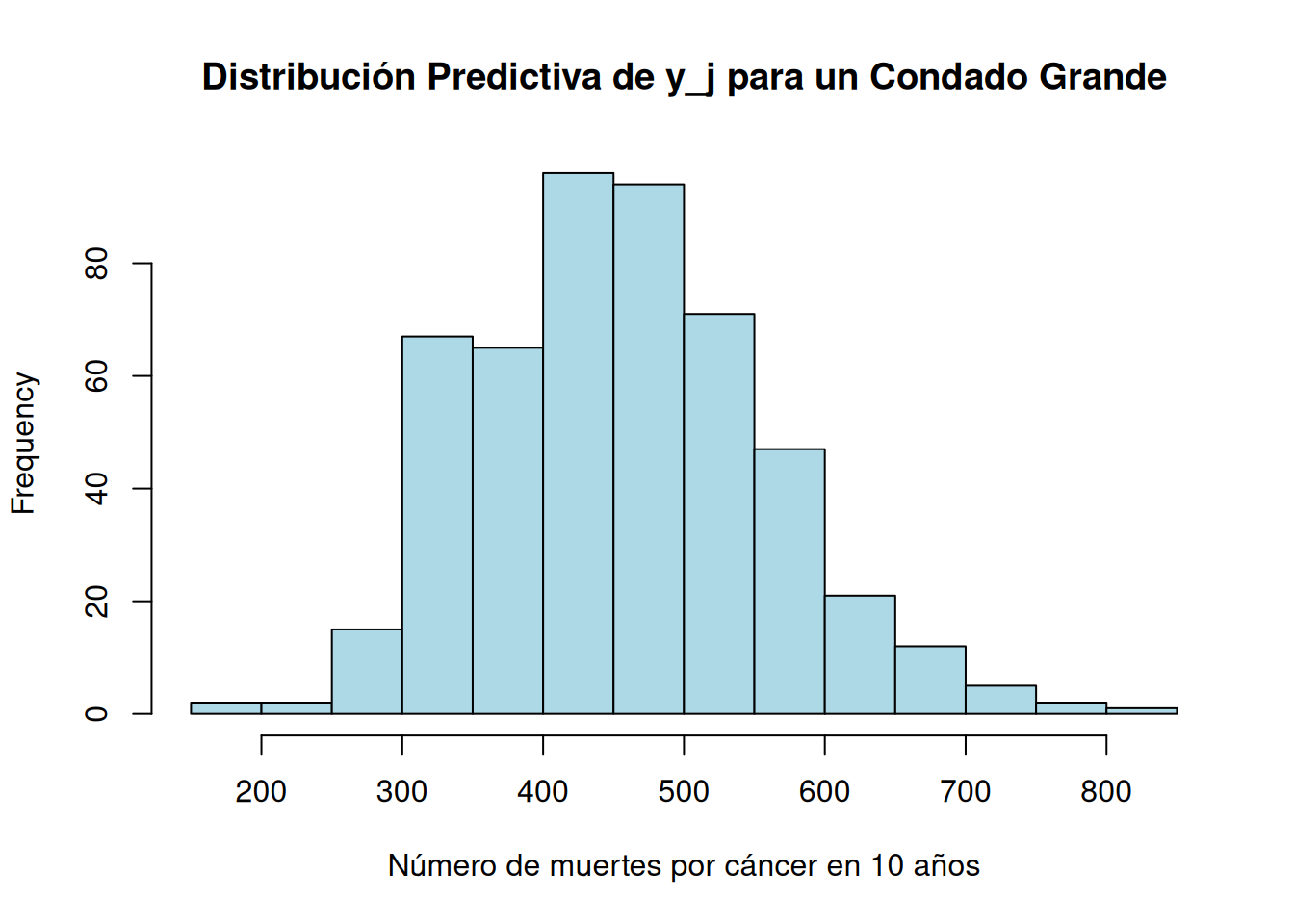
En Condados Grandes - Ejemplo: Condado con \(n_j = 1\) millón
Con datos de 10 años, se simulan 500 valores de \(y_j\) usando la combinación de la Gamma prior y la Poisson con exposición \(10^7\).
Se obtiene una mediana de \(473\) muertes y un intervalo intercuartílico de [393, 545].
# Fijar la semilla para reproducibilidadset.seed(123)# Parámetros del prior Gamma para theta_jalpha <-20beta <-430000# Parámetros del condado granden_j <-1e6# Población del condadoexposure <-10* n_j # Exposición para 10 años: 10^7# Número de simulacionesnsim <-500# Simular 500 valores de theta_j de la distribución Gammatheta_draws <-rgamma(nsim, shape = alpha, rate = beta)# Para cada theta_j, simular y_j de una distribución Poisson con lambda = exposure * theta_jy_sim <-rpois(nsim, lambda = exposure * theta_draws)# Calcular la mediana y los percentiles intercuartílicos de y_simmedian_y <-median(y_sim)iqr_y <-quantile(y_sim, probs =c(0.25, 0.75))ci95_y <-quantile(y_sim, probs =c(0.025, 0.975))# Imprimir resultadoscat("Resultados de 500 simulaciones para un condado grande (n_j = 1,000,000):\n")
Resultados de 500 simulaciones para un condado grande (n_j = 1,000,000):
# Graficar el histograma de las simulacioneshist(y_sim, breaks =20, col ="lightblue",main ="Distribución Predictiva de y_j para un Condado Grande",xlab ="Número de muertes por cáncer en 10 años")
En condados grandes, los datos observados tienden a dominar la distribución a priori, produciendo estimaciones Bayesianas que son muy cercanas a las tasas crudas. Por ejemplo:
Caso 1:
Si en un condado se observan \(y_j = 393\) muertes en un período determinado, la tasa cruda es:
En ambos casos, la estimación ajustada por Bayes solo se desvía levemente de la tasa cruda, lo que indica que, en un condado grande, la cantidad de datos es suficientemente alta como para que la influencia de la prior sea mínima.
2.9.5.6 Distribución Predictiva
Para evaluar cuán probable es obtener ciertos valores de \(y_j\) en un condado dado, se utiliza la distribución predictiva. En el modelo Poisson con Gamma prior, la distribución predictiva es negativa binomial:
# Parámetros del prior Gammaalpha <-20beta <-430000# Parámetro del condado: población n_jn_j <-1000# Por ejemplo, un condado pequeñoexposure <-10* n_j # Exposición total para 10 años# Calcular la probabilidad de éxito para la distribución negativa binomial# En este modelo, prob = beta / (exposure + beta)p_success <- beta / (exposure + beta)# Simular 500 valores de y_j a partir de la distribución negativa binomial:# y_j ~ Neg-Bin(size = alpha, prob = p_success)set.seed(123)y_sim <-rnbinom(500, size = alpha, prob = p_success)# Mostrar la tabla de frecuenciastable_y <-table(y_sim)print(table_y)
y_sim
0 1 2 3 4
308 152 31 8 1
# Calcular resúmenes de la distribución predictivamean_y <-mean(y_sim)median_y <-median(y_sim)ci_y <-quantile(y_sim, probs =c(0.025, 0.975))cat("Resumen de la distribución predictiva para un condado con n_j = 1000:\n")
Resumen de la distribución predictiva para un condado con n_j = 1000:
cat("Media =", mean_y, "\n")
Media = 0.484
cat("Mediana =", median_y, "\n")
Mediana = 0
cat("Intervalo 95% =", ci_y, "\n")
Intervalo 95% = 0 2
# Graficar el histograma de y_simhist(y_sim, breaks =seq(-0.5, max(y_sim) +0.5, by =1), col ="lightblue",main ="Distribución Predictiva de y_j para un Condado (n_j = 1000)",xlab ="Número de muertes (y_j)", ylab ="Frecuencia")
2.9.5.7 Construcción del Prior mediante Coincidencia de Momentos
Para justificar la elección de la prior Gamma\((20,430,000)\), se emparejan el valor medio y la varianza de las tasas crudas observadas \(\frac{y_j}{10 n_j}\) con las expectativas teóricas de la distribución Gamma:
En muchos problemas reales no contamos con una base poblacional sólida para construir un prior plenamente informativo. Desde los primeros trabajos de Bayes y Laplace se ha buscado, por tanto, especificar distribuciones previas que intervengan lo menos posible en el análisis: a este tipo de especificaciones se las denomina “noninformative”, “vagas” o “planas”. Su motivación es sencilla: si se dispone de pocos conocimientos previos, es preferible que las conclusiones dependan casi exclusivamente de los datos observados.
Con el tiempo ha surgido una noción intermedia, la de prior débilmente informativo. Estos priors no son totalmente planos: contienen la información mínima necesaria para “regularizar” la inferencia, es decir, para descartar valores claramente imposibles o implausibles sin imponer un conocimiento experto detallado. En la práctica moderna —donde los modelos suelen incluir muchos parámetros— resulta más seguro trabajar con priors débilmente informativos que con priors puramente impropios.
2.10.1 Priors propios e impropios
Llamamos propio a un prior cuya densidad \(p(\theta)\) integra a 1 y, por tanto, define una distribución de probabilidad en sentido estricto. A la inversa, un prior es impropio si su integral es infinita. Los impropios pueden usarse siempre que la combinación con la verosimilitud produzca un posterior propio (suma o integra a 1).
Un ejemplo clásico aparece al estimar la media \(\theta\) en un modelo normal con varianza conocida \(\sigma^{2}\). Si asumimos el prior impropio \(p(\theta)\propto1\), al menos con \(n\ge1\) observaciones el posterior se convierte en \[
\theta\mid y \sim N\!\left(\bar y,\;\frac{\sigma^{2}}{n}\right),
\] distribución perfectamente válida. De modo análogo, al estimar la varianza desconocida de un normal (con media conocida) es habitual emplear \(p(\sigma^{2})\propto1/\sigma^{2}\); el resultado posterior es entonces una distribución inversa-\(\chi^2\) con \(n\) grados de libertad y resulta propio mientras exista más de un dato.
Estos ejemplos ilustran la regla de oro con priors impropios: comprobar siempre que el posterior sea finito y razonable para todos los posibles valores de los datos.
2.10.2 Ventajas y precauciones
Los priors impropios son atractivos porque eliminan decisiones subjetivas aparentes y, en modelos sencillos, facilitan expresiones analíticas compactas. Sin embargo, presentan dos inconvenientes:
1. No definen un modelo completo para la pareja \((y,\theta)\), lo que complica interpretaciones predictivas o jerárquicas.
2. Pueden fallar en situaciones límite; por ejemplo, con el prior \(\text{Beta}(0,0)\) en el modelo binomial, los casos \(y=0\) o \(y=n\) conducen a un posterior impropio.
Por ello, en aplicaciones con muchos parámetros o estructuras complejas suele recomendarse introducir algo de información externa. Un prior débilmente informativo, aun modesto, actúa como cinturón de seguridad al impedir que la inferencia se desvíe hacia regiones absurdas del espacio paramétrico. Otra estrategia, ampliamente utilizada en la estadística bayesiana moderna, es incorporar la incertidumbre restante mediante modelos jerárquicos: en ellos los hiperparámetros de la distribución previa se tratan también como cantidades aleatorias y se estiman a partir de los datos, lo que permite que el modelo “aprenda” la forma adecuada del prior.
2.11 Principio de invarianza de Jeffreys
Harold Jeffreys propuso que, al buscar un prior no informativo, la distribución previa debe preservarse bajo cualquier reparametrización uno‑a‑uno.
Sea \(\phi=h(\theta)\) una transformación bijectiva. Usando el cambio de variable, el prior transformado cumple
de modo que se conserva la forma del prior y, por tanto, la regla es invariante a la parametrización.
Ejemplo binomial.
Para \(y\sim\text{Bin}(n,\theta)\) la log‑verosimilitud es \(\log p(y\mid\theta)=\text{cte}+y\log\theta+(n-y)\log(1-\theta)\).
Derivando y tomando esperanza se obtiene
Comparado con el prior uniforme de Bayes‑Laplace \(\text{Beta}(1,1)\), la versión de Jeffreys da algo más de peso a los extremos \(0\) y \(1\), reflejando la estructura de información del modelo. Si se trabaja en la escala natural \(\eta=\text{logit}(\theta)\) y se toma un prior constante en \(\eta\), se obtiene la forma impropia \(\text{Beta}(0,0)\) sobre \(\theta\). Las diferencias entre estas alternativas suelen ser pequeñas cuando el tamaño muestral es moderado, pero con priors impropios es indispensable comprobar la propiedad del posterior; por ejemplo, \(\text{Beta}(0,0)\) produce un posterior impropio si \(y\in\{0,n\}\).