En la práctica casi nunca trabajamos con un único parámetro desconocido. Los fenómenos reales suelen requerir varios componentes para describir adecuadamente la variabilidad y la estructura del problema. La perspectiva bayesiana resulta especialmente apropiada en este contexto porque, una vez formulada la distribución posterior conjunta de todos los parámetros, basta marginalizar (o simular) sobre los que no interesan en ese momento para obtener inferencias puntuales sobre el subconjunto relevante.
Con frecuencia solo queremos conclusiones sobre uno o dos parámetros y el resto se incorpora en el modelo para garantizar realismo, pero no nos interesa interpretarlos: a esos parámetros les llamamos nuisance parameters (parámetro molesto). Un ejemplo clásico es la varianza \(\sigma^{2}\) en un modelo normal: necesitamos cuantificar la dispersión para estimar correctamente la media, aunque raras veces la varianza es el foco de la investigación.
3.1 Promediando sobre parámetros de “nuisance”
Supongamos que el vector de parámetros se descompone como \(\theta = (\theta_{1},\;\theta_{2})\), donde \(\theta_{1}\) contiene la cantidad de interés y \(\theta_{2}\) representa los parámetros molestos. El objetivo es la densidad posterior marginal \(p(\theta_{1}\mid y)\). Partimos de la posterior conjunta
lo que revela que la distribución buscada es un promedio ponderado de las distribuciones condicionales \(p(\theta_{1}\mid\theta_{2},y)\), siendo \(p(\theta_{2}\mid y)\) la función de pesos. Por tanto, la información procedente de los datos y del prior se combina dos veces: primero para construir \(p(\theta_{2}\mid y)\) y después para mezclar las condicionales de \(\theta_{1}\).
En la práctica resulta poco habitual resolver la integral de manera analítica. En cambio, se recurre a estrategias de simulación:
Se genera un valor de \(\theta_{2}\) desde su posterior marginal \(p(\theta_{2}\mid y)\).
Condicionado en esa muestra, se genera \(\theta_{1}\) desde \(p(\theta_{1}\mid\theta_{2},y)\).
Repetido muchas veces, este procedimiento produce una muestra de la posterior conjunta cuyos subconjuntos ya incorporan la integración deseada. Así se evita la integración explícita y se obtienen, distribuciones marginales e intervalos creíbles para cualquier función de los parámetros.
El modelo normal con media y varianza desconocidas, tratado a continuación, es un ejemplo canónico de cómo marginalizar o simular sobre parámetros de “nuisance” para centrar las inferencias en la cantidad de interés.
3.2 Datos normales con prior no informativo
Imaginemos un conjunto \(y = (y_1,\dots,y_n)\) de observaciones independientes procedentes de una distribución normal \(\text{N}(\mu,\sigma^{2})\). Tomaremos el caso más tradicional de la estadística inferencial: estimar la media poblacional \(\mu\) cuando la varianza \(\sigma^{2}\) también es desconocida. Para destacar cómo la maquinaria bayesiana “promedia” los parámetros molestos, empezaremos adoptando el prior más difuso que suele usarse en este problema: se asume independencia a priori entre ubicación y escala y se fija
donde \(\bar y\) y \(s^{2}\) son la media y varianza muestral, respectivamente.
Estos dos estadísticos son suficientes: toda la información que contienen los datos respecto a \((\mu,\sigma^{2})\) se resume en \((\bar y,s^{2})\).
3.2.2 Condicional de \(\mu\) dado \(\sigma^{2}\)
Si fijamos \(\sigma^{2}\), la posterior de \(\mu\) reproduce la forma estudiada con varianza conocida:
Para eliminar \(\mu\) integramos la conjunta sobre toda la recta real. El resultado es una distribución inversa‑\(\chi^{2}\) escalada,
\[
\sigma^{2}\mid y \;\sim\; \text{Inv-}\chi^{2}\bigl(n-1,\;s^{2}\bigr),
\]
cuyo parámetro de escala coincide con la varianza muestral y cuyos grados de libertad son \(n-1\). Obsérvese que la distribución marginal posterior de \(\sigma^{2}\) replica la forma clásica de la teoría de muestreo: si se condiciona en \(\sigma^{2}\) (y en \(\mu\)), la cantidad pivotal \((n-1)s^{2}/\sigma^{2}\) sigue una \(\chi^{2}_{n-1}\). Es decir, el resultado bayesiano para \(\sigma^{2}\) mantiene la misma estructura que el estadístico \(\chi^{2}\) habitual basado en la varianza muestral.
3.2.4 Muestreo de la posterior conjunta
La descomposición \(p(\mu,\sigma^{2}\mid y)=p(\mu\mid\sigma^{2},y)\,p(\sigma^{2}\mid y)\) facilita la simulación:
Generar \(\sigma^{2}\) desde \(\text{Inv-}\chi^{2}(n-1,s^{2})\).
Condicionado en ese valor, generar \(\mu\) desde \(\text{N}(\bar y,\sigma^{2}/n)\).
Repetir estos pasos produce una muestra de la posterior conjunta; cada subvector ofrece la marginal correspondiente sin necesidad de integrar de forma analítica.
Ejemplo:
############################################################## Posterior sampling in the Normal(μ, σ²) model## non‑informative prior p(μ,log σ) ∝ 1/σ²############################################################set.seed(2025)## --- data -------------------------------------------------y <-c(5.2, 4.8, 5.4, 5.1, 4.7, 5.0, 4.9, 5.3, 5.2, 4.8) # n = 10n <-length(y)yb <-mean(y) # \bar ys2 <-var(y) # sample variance## --- posterior draws -------------------------------------S <-10000# number of Monte‑Carlo draws# 1) σ² | y ~ Inv‑χ²(n−1, s²)sigma2 <- (n -1) * s2 /rchisq(S, df = n -1)# 2) μ | σ², y ~ N( \bar y , σ² / n )mu <-rnorm(S, mean = yb, sd =sqrt(sigma2 / n))## --- quick numerical checks ------------------------------c(`E[μ|y] (MC mean)`=mean(mu),`sd[μ|y] (MC)`=sd(mu))
3.2.5 Marginal de \(\mu\) y comparación con la teoría clásica
Al integrar la conjunta sobre \(\sigma^{2}\) se obtiene
\[
\mu\mid y \;\sim\; t_{\,n-1}\!\left(\bar y,\; s^{2}/n\right),
\]
es decir, \[\frac{\mu-\bar y}{s/\sqrt n}\;\Big|\;y \;\sim\; t_{\,n-1}.\]
La distribución \(t\) también aparece en la inferencia frecuentista, pero allí se aplica al estadístico \(\frac{\bar y-\mu}{s/\sqrt n}\). Desde el punto de vista bayesiano, la aparición del mismo núcleo \(t\) muestra cómo el prior difuso deja paso a la información de los datos.
3.2.6 Distribución predictiva de una futura observación
Para predecir un nuevo valor \(\tilde y\) mezclamos la normal predictiva condicional con la posterior de los parámetros. El resultado es otra \(t\)‐student:
\[
\tilde y \mid y \;\sim\;
t_{\,n-1}\!\Bigl(\bar y,\;(1+\tfrac{1}{n})\,s^{2}\Bigr).
\]
Una manera intuitiva de visualizarlo es simular nuevamente: se extraen \((\mu,\sigma^{2})\) de su posterior conjunta y luego \(\tilde y\sim\text{N}(\mu,\sigma^{2})\). Esa mezcla automática reproduce la \(t\) anterior. Tal y como se analiza en el siguiente ejemplo:
3.2.7 Ejemplo
A continuación se ilustra, paso a paso, cómo reproducir el análisis bayesiano clásico que Simon Newcomb habría podido hacer para sus 66 mediciones del tiempo que tarda la luz en recorrer 7 442 m. Supondremos un modelo \(y_i \stackrel{\text{iid}}{\sim} \text{N}(\mu,\sigma^{2})\) y el prior no-informativo \(p(\mu,\sigma^{2}) \propto 1/\sigma^{2}\). Con este supuesto, la teoría nos dice que
de donde se deduce la marginal \(\,\mu\,|\,y \sim t_{\,n-1}\!\bigl(\bar y,\,s^{2}/n\bigr)\). La siguiente fracción de código confirma numéricamente los resultados analíticos usando los datos newcomb del paquete MASS:
A continuación ampliamos el análisis de Newcomb con un flujo completo en R que ilustra
(i) la construcción de muestras \(\bigl(\mu,\sigma^{2}\bigr)\) a partir de la ley posterior
(ii) la comparación de distintos intervalos creíbles para \(\mu\), y
(iii) la obtención de la distribución predictiva para una futura medición \(\tilde y\).
############################################################## 1. Cargar datos y explorar la muestra############################################################library(MASS) # contiene 'newcomb'data("newcomb")n_tot <-length(newcomb) # 66 observacionesybar <-mean(newcomb) # 26.2 (ns sobre 24 800)s2 <-var(newcomb) # 10.8^2
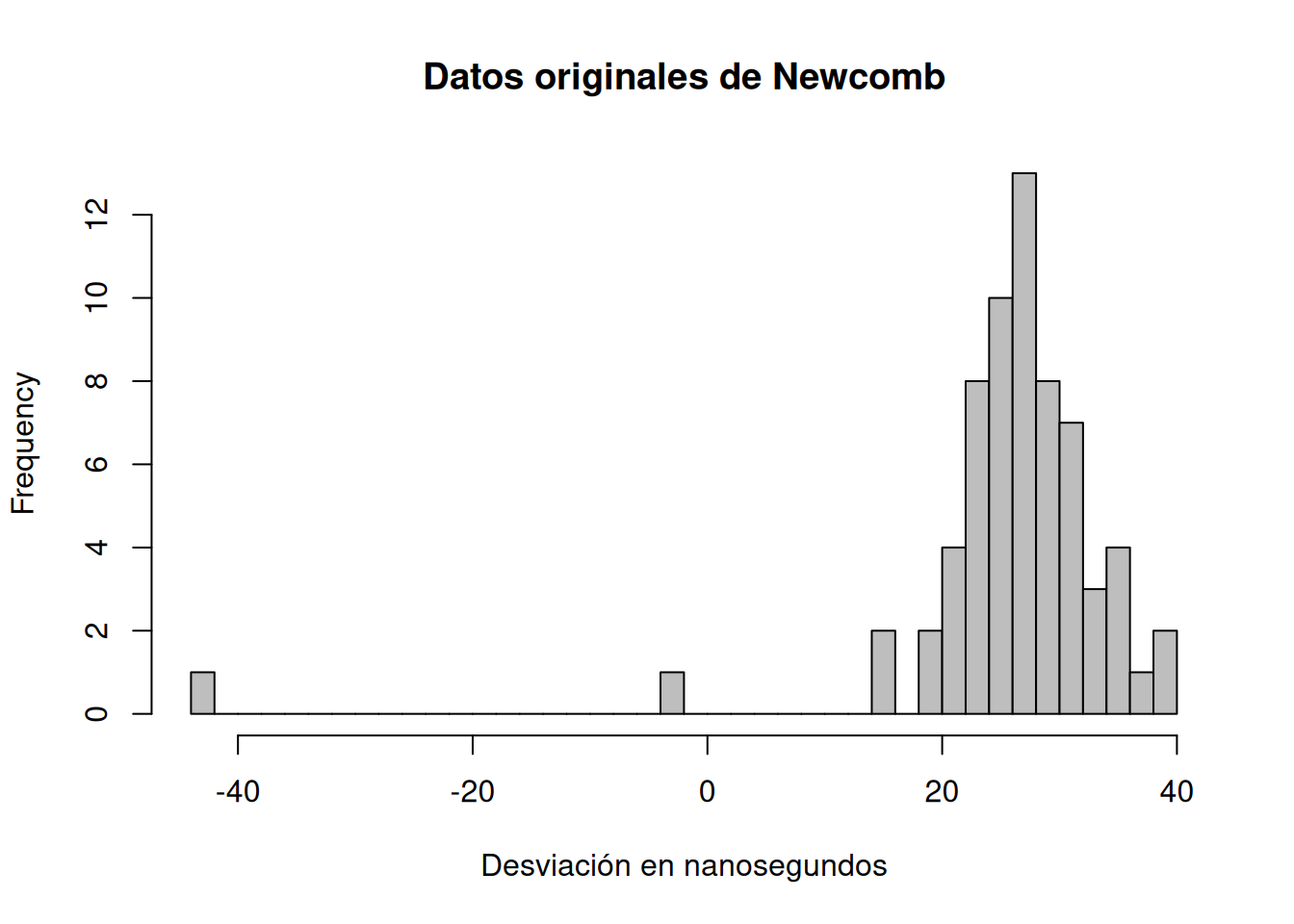
La figura siguiente muestra la densidad empírica: la mayoría de los tiempos se agrupan de forma aproximadamente simétrica, aunque hay dos observaciones claramente bajas.
hist(newcomb, breaks =40, col ="grey", main ="Datos originales de Newcomb",xlab ="Desviación en nanosegundos")
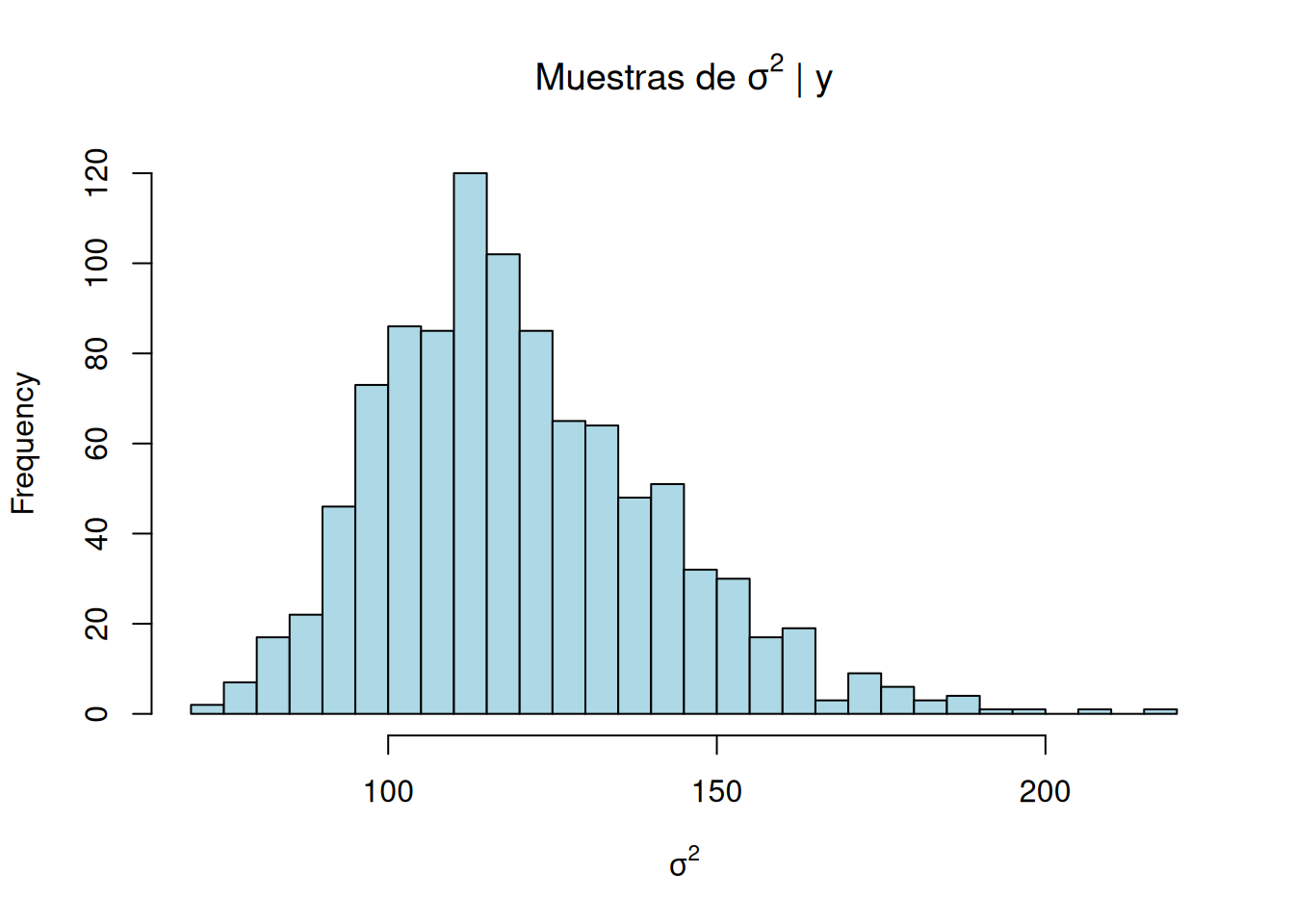
############################################################## 2. Muestreo desde la posterior conjunta p(μ,σ² | y)############################################################set.seed(123)B <-1000# tamaño de la simulación## 2.1 σ² | y ~ Inv-χ²(n−1, s²)sig2_post <- (n_tot -1) * s2 /rchisq(B, df = n_tot -1)hist(sig2_post, breaks =30, col ="lightblue",main =expression(paste("Muestras de ", sigma^2, " | y")),xlab =expression(sigma^2))
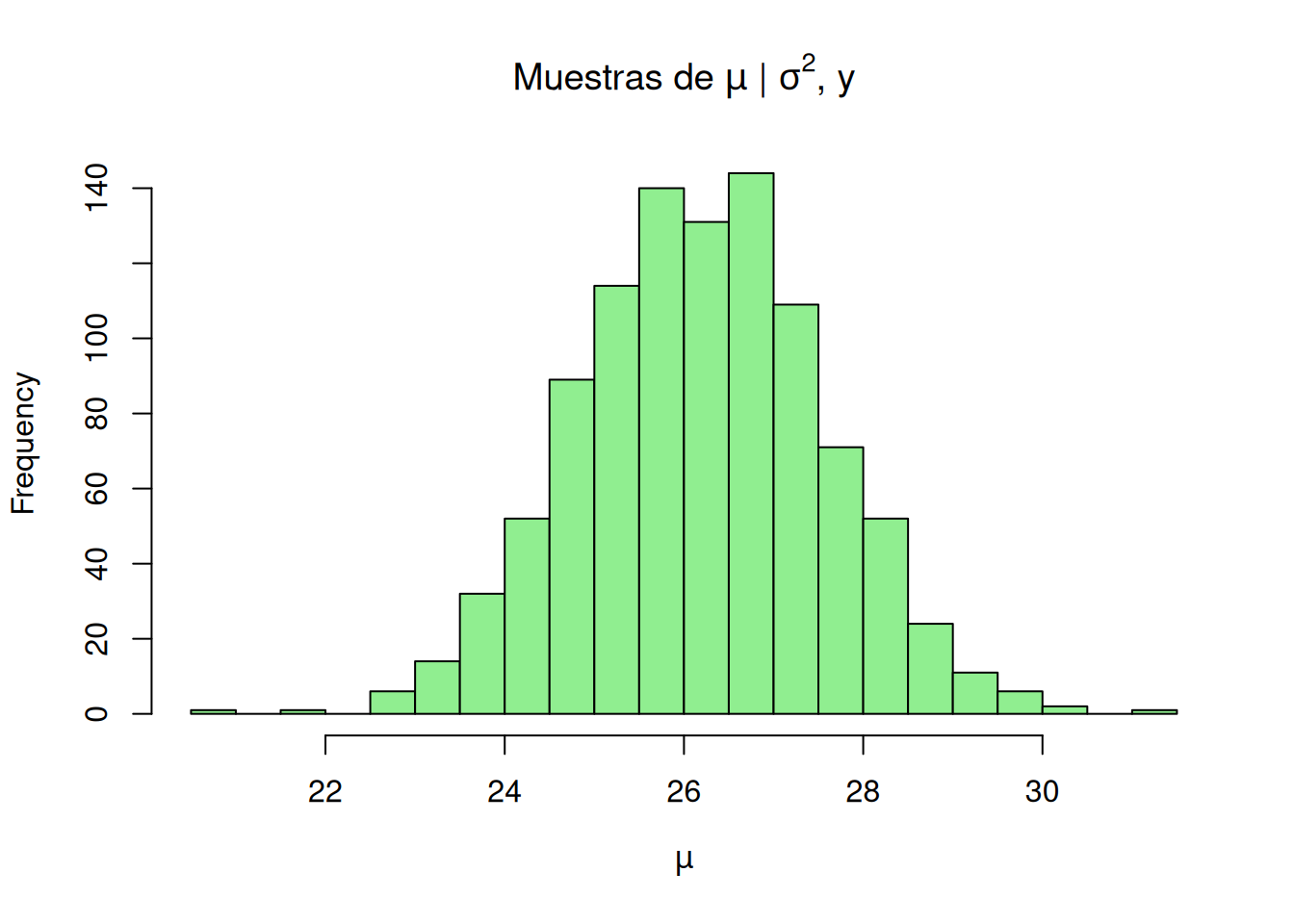
## 2.2 μ | σ², y ~ N( ybar , σ² / n )mu_post <-rnorm(B, mean = ybar, sd =sqrt(sig2_post / n_tot))hist(mu_post, breaks =30, col ="lightgreen",main =expression(paste("Muestras de ", mu, " | ", sigma^2, ", y")),xlab =expression(mu))
############################################################## 3. Intervalos creíbles para μ############################################################# 90 % basado en la simulacióncred90_mu_sim <-quantile(mu_post, probs =c(0.05, 0.95))# 90 % basado en la t_{65} (integra la incertidumbre en σ²)t_crit90 <-qt(0.95, df = n_tot -1)cred90_mu_t <- ybar +c(-1, 1) * t_crit90 *sqrt(s2 / n_tot)list(`IC 90% simulado`= cred90_mu_sim,`IC 90% t_(65)`= cred90_mu_t)
El intervalo simulado es más ancho porque incorpora implícitamente la variabilidad adicional de \(\sigma^{2}\).
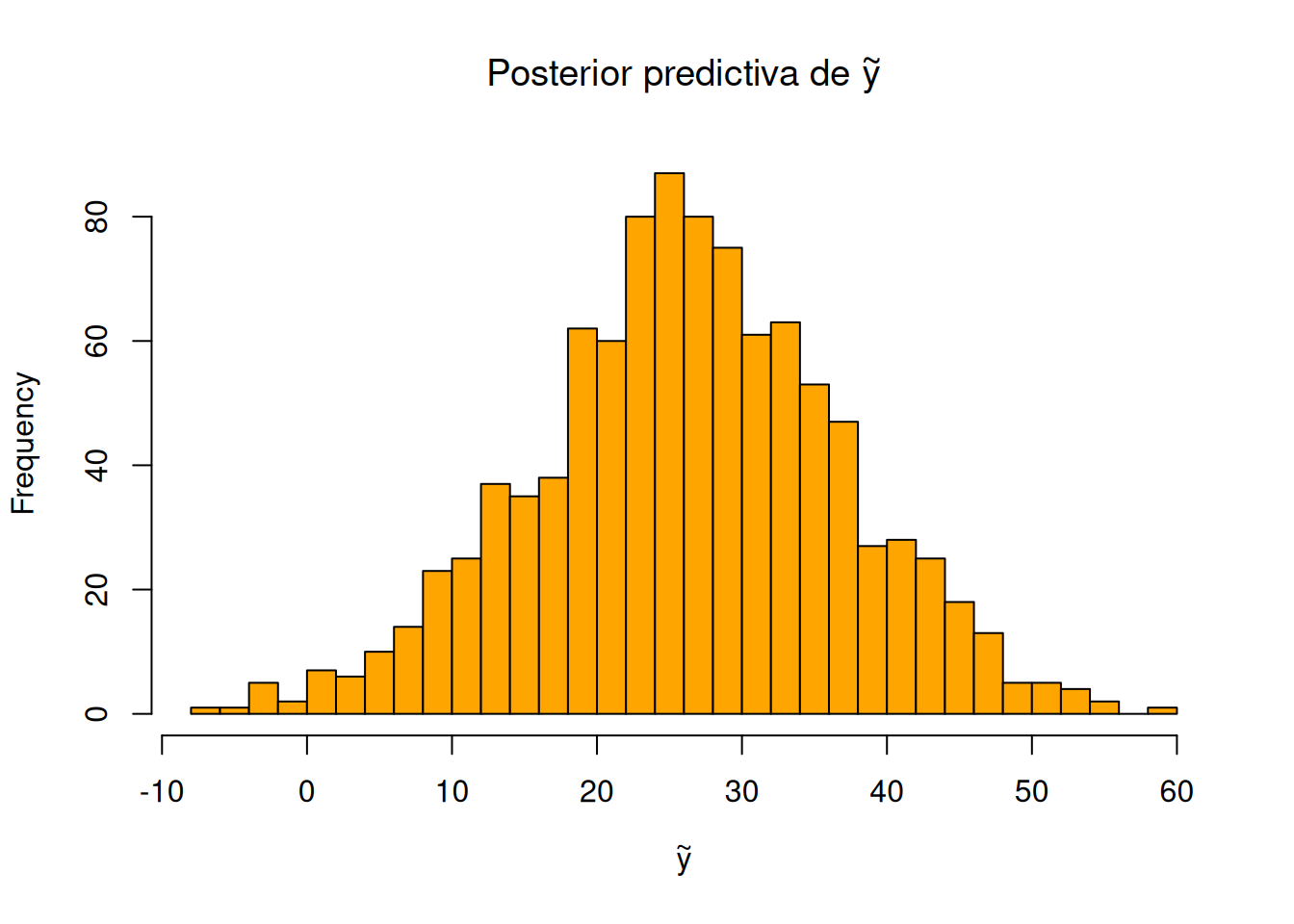
############################################################## 4. Distribución predictiva posterior para una nueva observación############################################################y_tilde_post <-rnorm(B, mean = mu_post, sd =sqrt(sig2_post))hist(y_tilde_post, breaks =30, col ="orange",main =expression(paste("Posterior predictiva de ", tilde(y))),xlab =expression(tilde(y)))
La mezcla normal resultante refleja tanto la dispersión intrínseca de los datos originales como la incertidumbre residual sobre los parámetros. Un intervalo de credibilidad al 95% para la nueva observación usando el resultado exacto es:
El modelo normal con media desconocida y varianza desconocida resulta más flexible cuando se combina con un prior conjugado en lugar del prior no-informativo de la sección anterior. La idea central es elegir una distribución previa que, al multiplicarse por la verosimilitud, produzca nuevamente una distribución de la misma familia y, por tanto, facilite la actualización bayesiana.
3.3.1 Construcción del prior conjugado
Sea \(y_1,\dots ,y_n \stackrel{\text{iid}}{\sim} \text{N}(\mu,\sigma^{2})\).
Para que el prior sea conjugado, debe factorizarse como \[
p(\mu,\sigma^{2}) \;=\; p(\sigma^{2})\,p(\mu\mid\sigma^{2}),
\] donde \(p(\sigma^{2})\) es una \(\text{Inv-}\chi^{2}\) escalada y \(p(\mu\mid\sigma^{2})\) es normal.
Un parámetro conveniente es \[
\begin{aligned}
\mu\mid\sigma^{2} &\sim \text{N}\!\left(\mu_{0}, \frac{\sigma^{2}}{\kappa_{0}}\right),\\[4pt]
\sigma^{2} &\sim \text{Inv-}\chi^{2}(\nu_{0},\sigma_{0}^{2}).
\end{aligned}
\] Notaremos este par de variable como: \[\text{N-Inv-}\chi^{2}(\mu_{0},\sigma_{0}^{2}/\kappa_{0};\;\nu_{0},\sigma_{0}^{2}).\]
La presencia de \(\sigma^{2}\) en la varianza de \(\mu\) introduce dependencia entre los parámetros, lo cual suele ser razonable: la incertidumbre previa sobre la media debería aumentar con la variabilidad de las observaciones.
3.3.2 Posterior conjunta y actualización de parámetros
Multiplicar la verosimilitud por el prior anterior genera otra distribución de la misma forma: \[
p(\mu,\sigma^{2}\mid y)
\;=\;
\text{N-Inv-}\chi^{2}\!\bigl(\mu_{n},\sigma_{n}^{2}/\kappa_{n};\;\nu_{n},\sigma_{n}^{2}\bigr),
\] con las actualizaciones \[
\begin{aligned}
\mu_{n} &= \frac{\kappa_{0}}{\kappa_{0}+n}\,\mu_{0} + \frac{n}{\kappa_{0}+n}\,\bar y,\\[4pt]
\kappa_{n} &= \kappa_{0} + n,\\[4pt]
\nu_{n} &= \nu_{0} + n,\\[4pt]
\nu_{n}\sigma_{n}^{2} &= \nu_{0}\sigma_{0}^{2} + (n-1)s^{2}
+ \frac{\kappa_{0}n}{\kappa_{0}+n}\,(\bar y-\mu_{0})^{2}.
\end{aligned}
\] Así, la media posterior \(\mu_{n}\) es un promedio ponderado entre la media previa y la muestral; los grados de libertad \(\nu_{n}\) crecen con \(n\), y la suma de cuadrados posterior combina la varianza previa y empírica más un ajuste por discrepancia entre \(\mu_{0}\) y \(\bar y\).
3.3.3 Condicionales útiles para la simulación
De la estructura conjugada se desprenden dos resultados clave:
Condicional de la media \[
\mu\mid\sigma^{2},y \;\sim\; \text{N}\!\left(\mu_{n},\frac{\sigma^{2}}{\kappa_{n}}\right).
\]
Marginal (y condicional) de la varianza \[
\sigma^{2}\mid y \;\sim\; \text{Inv-}\chi^{2}(\nu_{n},\sigma_{n}^{2}).
\]
Con estos dos bloques la generación de una muestra posterior conjunta es directa: primero se extrae \(\sigma^{2}\) de su \(\text{Inv-}\chi^{2}\), luego \(\mu\) del normal condicional dado el valor recién simulado de la varianza.
3.3.3.1 Marginal de \(\mu\) y ventajas prácticas
Al integrar \(\sigma^{2}\) se recupera la distribución \[
\mu\mid y \;\sim\; t_{\nu_{n}}\!\left(\mu_{n},\tfrac{\sigma_{n}^{2}}{\kappa_{n}}\right),
\] una extensión natural del resultado \(t\) obtenido con prior no-informativo.
Este marco conjugado ofrece varias ventajas:
Cálculo analítico de medias, varianzas e intervalos creíbles sin recurrir a métodos numéricos costosos.
Interpretación clara de cada hiper-parámetro como “pseudodatos”: por ejemplo, \(\kappa_{0}\) equivale a aportar \(\kappa_{0}\) observaciones con media \(\mu_{0}\).
Facilidad de muestreo gracias a la factorización condicional, lo que permite obtener simulaciones con apenas unas líneas de código en R o en cualquier software de propósito general.
3.3.4 Ejemplo
Para ver en acción el prior conjugado \(\text{N-Inv-}\chi^{2}\) analizamos la variable times del conjunto marathontimes del paquete LearnBayes. Supondremos que estos registros provienen de una distribución normal con media \(\mu\) y varianza \(\sigma^{2}\) desconocidas y actualizaremos nuestras creencias con un prior débilmente informativo.
3.3.4.1 Lectura y exploración preliminar
library(LearnBayes)data("marathontimes")# vector numérico de tiempos en minutosy <- marathontimes$timen <-length(y)ybar <-mean(y)s2 <-var(y)c(n = n, media_muestral = ybar, var_muestral = s2)
n media_muestral var_muestral
20.000 277.600 2454.042
3.3.4.2 Elección de hiper-parámetros
Para no influir demasiado en la inferencia elegimos:
\(\mu_{0} = 260\).
\(\kappa_{0} = 0.01\) (equivale a una centésima de observación).
\(\nu_{0} = 1\) (un grado de libertad previo).
\(\sigma_{0}^{2} = 2000\) (toma la dispersión empírica como referencia).
mu0 <-260kappa0 <-0.01nu0 <-1sigma02 <-2000
3.3.4.3 Parámetros posteriores
A partir de las fórmulas del resumen teórico calculamos:
3.3.4.4 Simulación de la distribución posterior conjunta
Conjugación significa facilidad de muestreo posterior: basta con obtener una muestra primero para \(\sigma^{2}\mid y\) y luego \(\mu\mid\sigma^{2},y\):
set.seed(123)S <-10000# tamaño de la muestra simulada# 1. varianza posterior: Inv-χ²(ν_n, σ_n²)sigma2_post <- (nu_n * sigma_n2) /rchisq(S, df = nu_n)# 2. media posterior condicionalmu_post <-rnorm(S, mean = mu_n, sd =sqrt(sigma2_post/kappa_n))# resúmenesquantile(mu_post, c(.025, .5, .975))
2.5% 50% 97.5%
255.0692 277.4023 299.9020
quantile(sigma2_post, c(.025, .5, .975))
2.5% 50% 97.5%
1386.747 2402.236 4718.420
3.3.4.5 Comparación con la teoría
El resultado analítico dice que \[
\mu\mid y\; \sim\; t_{\nu_{n}}\!\Bigl(\mu_{n},\frac{\sigma_{n}^{2}}{\kappa_{n}}\Bigr),
\] de modo que el intervalo quitando el efecto de la varianza se obtiene con:
En muchos estudios las observaciones no se reducen a «éxito / fracaso» sino que pueden caer en \(k\) categorías mutuamente excluyentes. Bajo esta situación el conteo \(\mathbf y=\,(y_1,\dots,y_k)\) describe cuántas veces aparece cada resultado a lo largo de \(n=\sum_{j=1}^{k}y_j\) ensayos. El modelo de muestreo más natural es el multinomial, cuya función de verosimilitud, condicionada al total \(n\), es
\[
p(\mathbf y \mid \boldsymbol\theta)\;\propto\;\prod_{j=1}^{k}\theta_j^{\,y_j}, \qquad
\theta_j\ge 0,\;\;\sum_{j=1}^{k}\theta_j=1 .
\]
Aquí \(\theta_j\) representa la probabilidad desconocida de observar la categoría \(j\) en un solo ensayo.
3.4.1 Distribución a priori conjugada
La familia conjugada del multinomial es la Dirichlet:
definida sobre el mismo simplex de probabilidad. Conceptualmente, cada parámetro \(\alpha_j\) puede interpretarse como «conteos previos» —equivalentes a haber observado \(\alpha_j\) veces la categoría \(j\) antes de recoger los datos reales. Esta interpretación facilita la especificación del prior: elegir \(\alpha_j=1\) para todos los \(j\) genera una densidad uniforme sobre el simplex, mientras que \(\alpha_j=0\) (impropio) asigna masa uniforme en la escala de los log‐proporciones y conduce a un posterior adecuado siempre que cada categoría aparezca al menos una vez.
3.4.2 Distribución a posteriori
Multiplicar la verosimilitud por el prior Dirichlet produce otra Dirichlet cuyos parámetros se actualizan sumando los conteos observados:
\[
\boldsymbol\theta \mid \mathbf y \;\sim\;
\text{Dirichlet}\bigl(\alpha_1+y_1,\ldots,\alpha_k+y_k\bigr).
\]
3.4.3 Ejemplo: sondeo pre-electoral de CBS News (octubre 1988)
En la encuesta se entrevistaron \(\,n=1447\,\) personas: \(y_1=727\) declararon intención de votar por Bush, \(y_2=583\) por Dukakis y \(y_3=137\) apoyaron a otro candidato o no tenían opinión.
Supondremos muestreo aleatorio simple y adoptaremos el prior uniforme (Dirichlet con parámetros 1). La posterior para el vector de proporciones \(\boldsymbol\theta=(\theta_1,\theta_2,\theta_3)\) es entonces
\[
\boldsymbol\theta \mid \mathbf y \;\sim\; \text{Dirichlet}(728,\,584,\,138).
\]
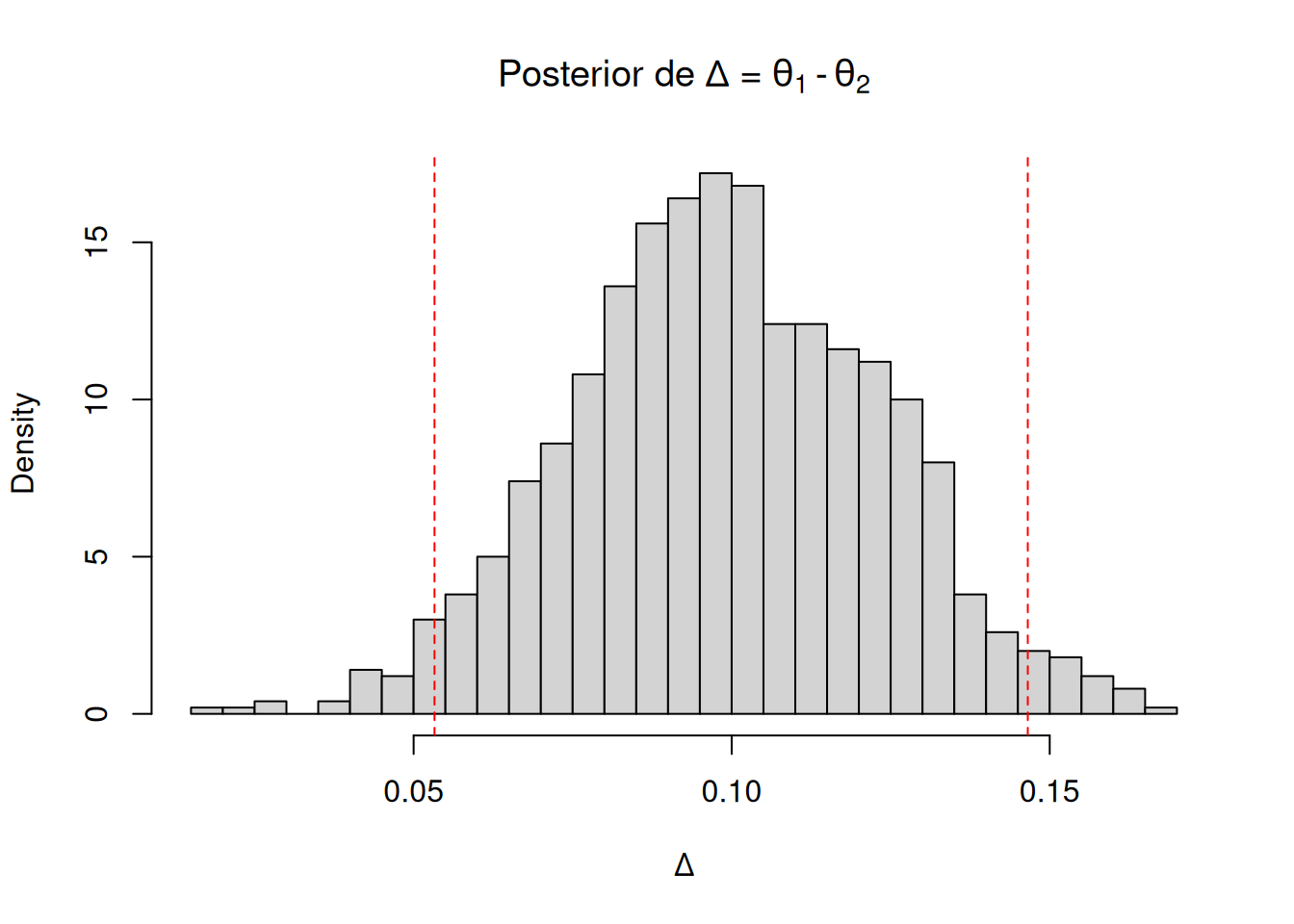
Nos interesa la diferencia de apoyo entre los dos principales candidatos, \(\Delta=\theta_1-\theta_2\). En lugar de integrar analíticamente, simularemos \(B=1000\) draws de la Dirichlet posterior y evaluaremos \(\Delta\) en cada réplica.
#--- paquetes --------------------------------------------------------------library(gtools) # para rdirichlet()
Attaching package: 'gtools'
The following object is masked from 'package:LearnBayes':
rdirichlet
#--- datos --------------------------------------------------------------y <-c(Bush =727, Dukakis =583, Otro_NA =137)alpha_post <- y +1# prior uniforme (1,1,1) + datos#--- simulación de la posterior -----------------------------------------set.seed(123) # reproducibilidadB <-1000theta_post <-rdirichlet(B, alpha_post) # B x 3 matriz de drawsdelta_post <- theta_post[,1] - theta_post[,2]#--- resúmenes -----------------------------------------------------------prob_Bush_gt_Dukakis <-mean(delta_post >0)ci_delta_95 <-quantile(delta_post, c(0.025, 0.975))list(`P(θ1 > θ2 | datos)`= prob_Bush_gt_Dukakis,`IC 95% Delta`= ci_delta_95)
La salida muestra una probabilidad posterior $ P(_1>_2)$ prácticamente igual a 1 (los 1000 draws dan \(\Delta>0\)) y un intervalo de credibilidad al 95 % cuyos límites son positivos, reforzando la conclusión de que Bush lideraba la intención de voto en la población encuestada.
#--- visualización -------------------------------------------------------hist(delta_post, breaks =30, freq =FALSE,main =expression(paste("Posterior de ", Delta," = ",theta[1]-theta[2])),xlab =expression(Delta))abline(v = ci_delta_95, lty =2, col ="red")
3.5 Modelo normal multivariado con varianza conocida
En muchos problemas aplicados se observan vectores de respuestas cuyos componentes pueden estar correlacionados. Para capturar esa dependencia el modelo natural es el normal multivariado, cuyo tratamiento bayesiano extiende de modo casi paralelo los resultados univariados, aunque introduce detalles algebraicos que serán claves en el estudio de modelos lineales.
Suponga que cada observación es un vector columna \(y\in\mathbb R^{d}\) con distribución
donde \(\mu\) es el vector de medias desconocido y \(\Sigma\) es la matriz de varianzas–covarianzas (\(d\times d\), simétrica y definida positiva). Aun cuando hablemos de “varianza conocida”, la presentación a continuación escribe la verosimilitud en la forma general —simplificarla requeriría fijar \(\Sigma\).
3.5.1 Verosimilitud para una sola observación
El análogo multivariado del núcleo gaussiano univariado es
Aquí \(|\Sigma|\) denota el determinante y la forma cuadrática interior mide la distancia de Mahalanobis entre \(y\) y \(\mu\).
3.5.2 Muestra independiente de tamaño \(n\)
Para vectores \(y_1,\ldots,y_n\) i.i.d. \(\mathsf N(\mu,\Sigma)\), la verosimilitud conjunta factoriza multiplicativamente y se escribe convenientemente con trazas de matrices,
es la matriz de “sumas de cuadrados” alrededor del vector media. Este resultado revela los estadisticos suficientes del muestreo multivariado: la media muestral \(\bar y\) y la matriz de dispersiones centradas.
3.5.3 Conjugado normal multivariado (varianza \(\Sigma\) conocida)
En el caso multivariado, si la matriz de covarianzas \(\Sigma\) se asume conocida, la lógica conjugada es idéntica a la univariada: el prior natural para el vector de medias\(\mu\) es una distribución normal multivariada.
Sea el prior \(\mu\sim\mathsf N(\mu_0,\Lambda_0)\), donde \(\Lambda_0\) representa la varianza previa (cuanto menor su precisión, más difusa la creencia en torno a \(\mu_0\)).
3.5.3.1 Posterior de \(\mu\)
Al multiplicar el prior por la verosimilitud del muestreo \(\mathsf N(\mu,\Sigma)\) se obtiene otra distribución gaussiana:
La interpretación es transparente: la media a posteriori es un promedio ponderado entre información previa y evidencia muestral, donde los pesos vienen dados por las matrices de precisión \(n\Sigma^{-1}\) (datos) y \(\Lambda_0^{-1}\) (prior). De igual modo, la precisión posterior es simplemente la suma de ambas precisiones.
3.5.3.2 Predictiva posterior
Si \(\tilde y\mid\mu,\Sigma\sim\mathsf N(\mu,\Sigma)\), la marginal posterior de \(\tilde y\) integra la incertidumbre sobre \(\mu\):
por lo que \[\tilde y\mid y\sim \mathsf N(\mu_n,\ \Sigma+\Lambda_n).\]
El término \(\Sigma\) refleja la variabilidad inherente a nuevas observaciones; \(\Lambda_n\) agrega la variabilidad debida a no conocer exactamente \(\mu\).
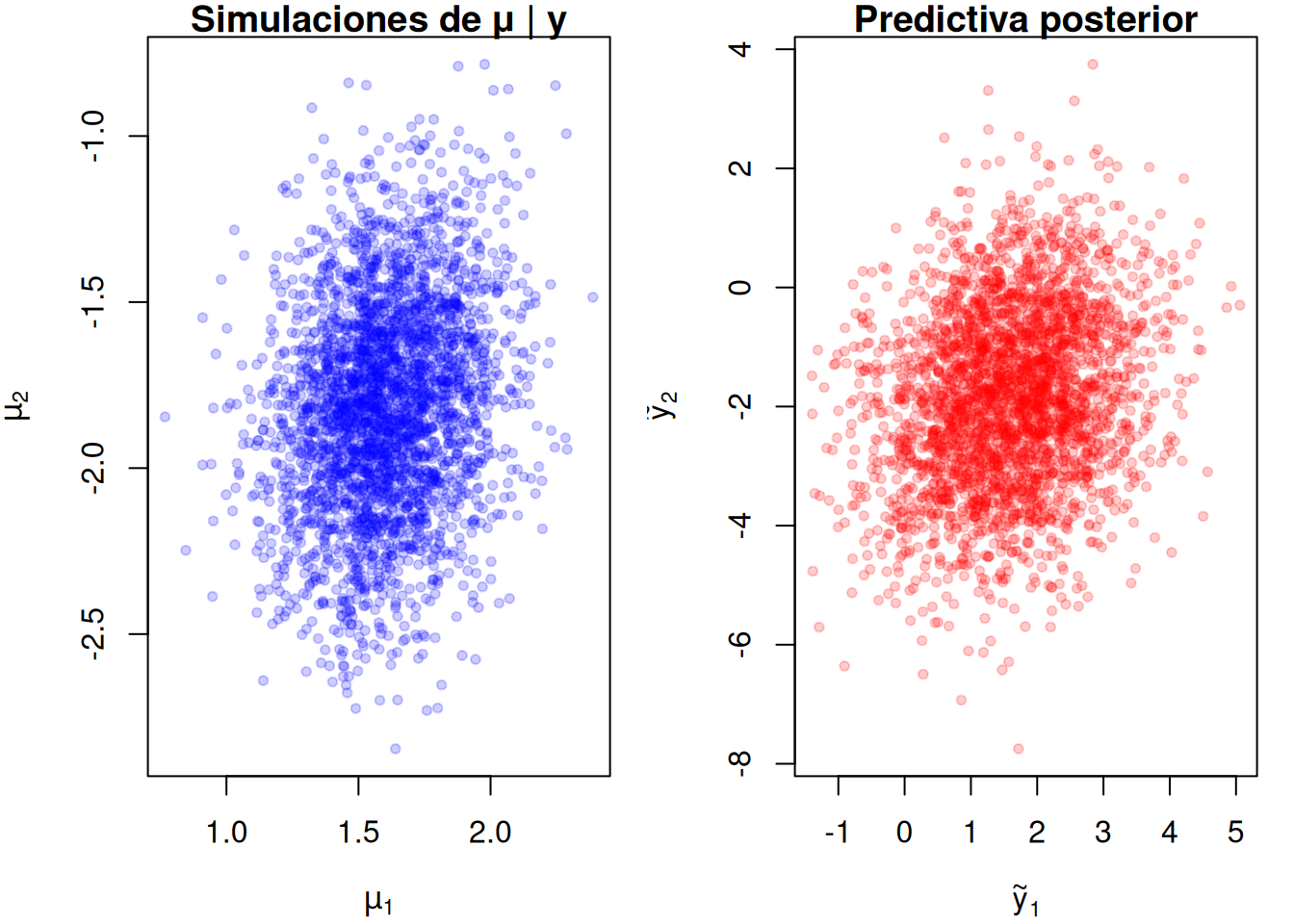
3.5.4 Ejemplo
En este ejemplo simularemos un problema bidimensional.
* La matriz de covarianzas del muestreo, \(\Sigma\), se toma conocida.
* El prior para el vector de medias \(\mu=(\mu_1,\mu_2)^{\!\top}\) es \(\mathsf N(\mu_0,\Lambda_0)\), con una alta varianza previa que refleje conocimiento débil.