Una cadena de Markov discreta describe una secuencia de movimientos aleatorios entre un conjunto finito de estados, donde la probabilidad de pasar al siguiente estado depende únicamente del estado actual. En nuestro ejemplo, imaginemos a una persona que camina sobre los enteros \({1,2,3,4,5,6}\). Si está en un estado interior (\(2,3,4,5\)), al segundo siguiente tiene igual probabilidad de quedarse donde está o moverse a un vecino, y si decide moverse, es igualmente probable ir a la izquierda o a la derecha. En los extremos (\(1\) o \(6\)) la única vecindad es el estado adyacente.
Estas reglas se codifican en la matriz de transición\(P\), donde la fila \(i\) contiene las probabilidades de pasar del estado \(i\) a cada uno de los estados \(1,\dots,6\) en un paso:
Esta cadena es irreducible (se puede ir de cualquier estado a cualquier otro en uno o más pasos) y aperiódica (no está confinada a ciclos de longitud fija). Si \(p^j=(p^j_1,\dots,p^j_6)\) es el vector de probabilidades de estar en cada estado tras \(j\) pasos, entonces
\[
p^{\,j+1}=p^j\,P.
\]
Un vector de probabilidades \(w=(w_1,\dots,w_6)\) tal que
\[
w\,P = w
\]
se llama distribución estacionaria. En cadenas irreducibles y aperiódicas, \(w\) es único y la distribución de \(p^j\) tiende a él conforme \(j\to\infty\).
5.1.1 Simulación en R y estimación empírica de la estación
Podemos ilustrar la convergencia a la distribución estacionaria \((0.1,0.2,0.2,0.2,0.2,0.1)\) mediante una simulación:
# Definir la matriz de transición PP <-matrix(c( .5, .5, 0, 0, 0, 0, .25, .5, .25, 0, 0, 0,0, .25, .5, .25, 0, 0,0, 0, .25, .5, .25, 0,0, 0, 0, .25, .5, .25,0, 0, 0, 0, .5, .5), nrow =6, byrow =TRUE)# Número de pasos y almacenamientonsteps <-50000s <-integer(nsteps)s[1] <-3# comenzamos en el estado 3# Simular la caminata de Markovfor (j in2:nsteps) { s[j] <-sample(1:6, size =1, prob = P[s[j-1], ])}# Calcular frecuencias relativas tras distintos números de pasosm <-c(500, 2000, 8000, nsteps)for (steps in m) {cat("Después de", steps, "pasos:\n")print(table(s[1:steps]) / steps)}
Después de 500 pasos:
1 2 3 4 5 6
0.042 0.090 0.112 0.298 0.318 0.140
Después de 2000 pasos:
1 2 3 4 5 6
0.0855 0.1770 0.2050 0.2240 0.2165 0.0920
Después de 8000 pasos:
1 2 3 4 5 6
0.094875 0.185250 0.206625 0.209875 0.202375 0.101000
Después de 50000 pasos:
1 2 3 4 5 6
0.09804 0.19218 0.19660 0.20226 0.20564 0.10528
Al ejecutar este código, las frecuencias relativas de los estados convergen aproximadamente a
Estado
1
2
3
4
5
6
w
0.1
0.2
0.2
0.2
0.2
0.1
Finalmente, podemos verificar algebraicamente que \(w\) es estacionaria:
w <-matrix(c(.1, .2, .2, .2, .2, .1), nrow =1)w %*% P
Con ello confirmamos que la caminata aleatoria converge a la distribución estacionaria \(w=(0.1,0.2,0.2,0.2,0.2,0.1)\). La distribución estacionaria exacta se calcula a través del vector propio asociado al valor propio igual a 1 de la matriz \(P^T\):
5.2 Introducción al Algoritmo de Metropolis-Hastings
5.2.1 Un político descubre el algoritmo de Metropolis
Imaginemos a un político que recorre una cadena de islas y desea pasar tiempo en cada isla en proporción a su población, sin conocer de antemano ni el número total de islas ni sus poblaciones. Su única fuente de información local es preguntar al alcalde de la isla actual o de la isla vecina cuánta gente vive allí.
El procedimiento que sigue es el siguiente:
Con una moneda decide proponer la isla vecina de la izquierda o de la derecha.
Denotemos por \(P_{\text{current}}\) la población de la isla donde está y por \(P_{\text{proposed}}\) la población de la isla propuesta.
Si \(P_{\text{proposed}}\ge P_{\text{current}}\), se traslada seguro a la isla propuesta.
Si \(P_{\text{proposed}}<P_{\text{current}}\), se traslada con probabilidad \[
p_{\text{move}} \;=\;\frac{P_{\text{proposed}}}{P_{\text{current}}}.
\] Para ello, gira una ruleta continua de \([0,1]\) y avanza sólo si el resultado es menor que \(p_{\text{move}}\).
Aunque este heurístico sólo requiere información local y decisión aleatoria, su gran virtud es que en el largo plazo la frecuencia con la que el político visita cada isla converge exactamente a la distribución proporcional a sus poblaciones. Esto es, el político implementa sin saberlo un algoritmo de Metropolis, cuyo equilibrio estacionario es la proporción de poblaciones buscada.
5.2.2 Caminata aleatoria
En este ejemplo aplicamos el algoritmo de Metropolis a un “caminante” que salta entre siete islas dispuestas en línea, indexadas por \(\theta=1,\dots,7\), cuyas poblaciones relativas crecen linealmente \(P(\theta)=\theta\). El político parte de la isla \(\theta=4\) y en cada paso decide proponer moverse a la isla adyacente al este o al oeste con probabilidad \(0.5\) cada una. Si la isla propuesta tiene población mayor o igual que la actual, el movimiento se acepta siempre; de lo contrario, se acepta con probabilidad \[
p_{\text{move}}
=\frac{P(\theta_{\text{propuesta}})}
{P(\theta_{\text{actual}})}.
\] Este criterio genera una cadena de Markov irreducible y aperiódica cuyo modo estacionario coincide con la distribución de probabilidades proporcional a \((1,2,\dots,7)\). Tras muchos pasos, las frecuencias relativas de visita a cada isla convergen a \[
\frac{P(\theta)}{\sum_{i=1}^7P(i)} \;=\;\frac{\theta}{28}\,.
\]
5.2.2.1 Ejemplo en R
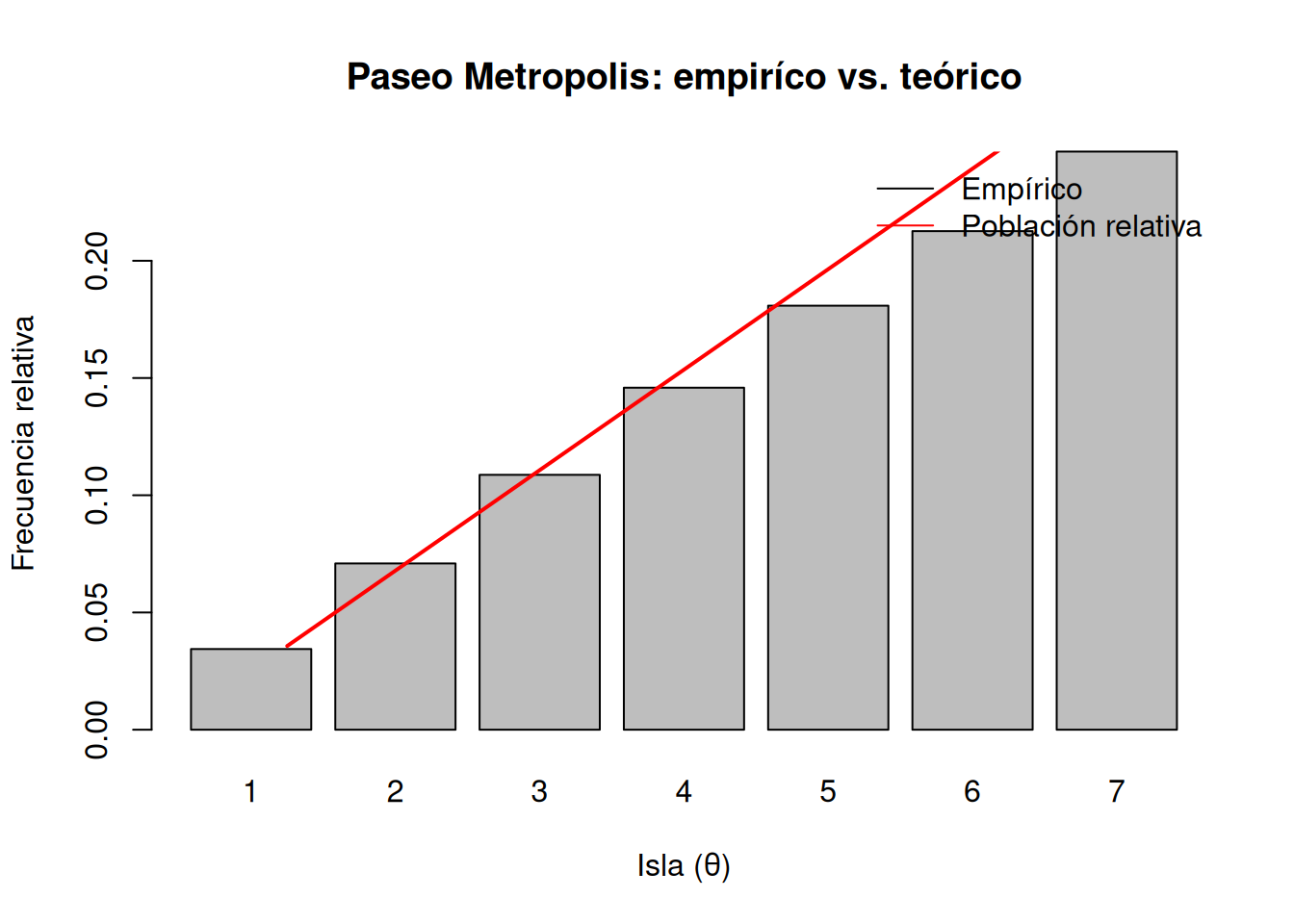
El siguiente código simula 100000 pasos de este paseo y compara las frecuencias empíricas con la distribución teórica:
# Simulación de un paseo Metropolis en la cadena de 7 islasset.seed(123)n_steps <-100000# número de pasospop <-1:7# poblaciones relativascurrent <-4# isla inicialtheta <-integer(n_steps)theta[1] <- currentfor (t in2:n_steps) {# propuesta al azar: izquierda o derecha prop <-if (runif(1) <0.5) current -1else current +1# aceptar solo si está en 1:7 y con probabilidad p_moveif (prop >=1&& prop <=7) { p_move <- pop[prop] / pop[current]if (runif(1) < p_move) current <- prop } theta[t] <- current}# calcular frecuencias relativasfreqs <-table(theta) / n_steps# comparar con la distribución teóricabarplot(freqs,names.arg =1:7,xlab ="Isla (θ)",ylab ="Frecuencia relativa",main ="Paseo Metropolis: empiríco vs. teórico")lines(1:7, pop /sum(pop), col ="red", lwd =2)legend("topright",legend =c("Empírico", "Población relativa"),col =c("black", "red"),lty =1,bty ="n")
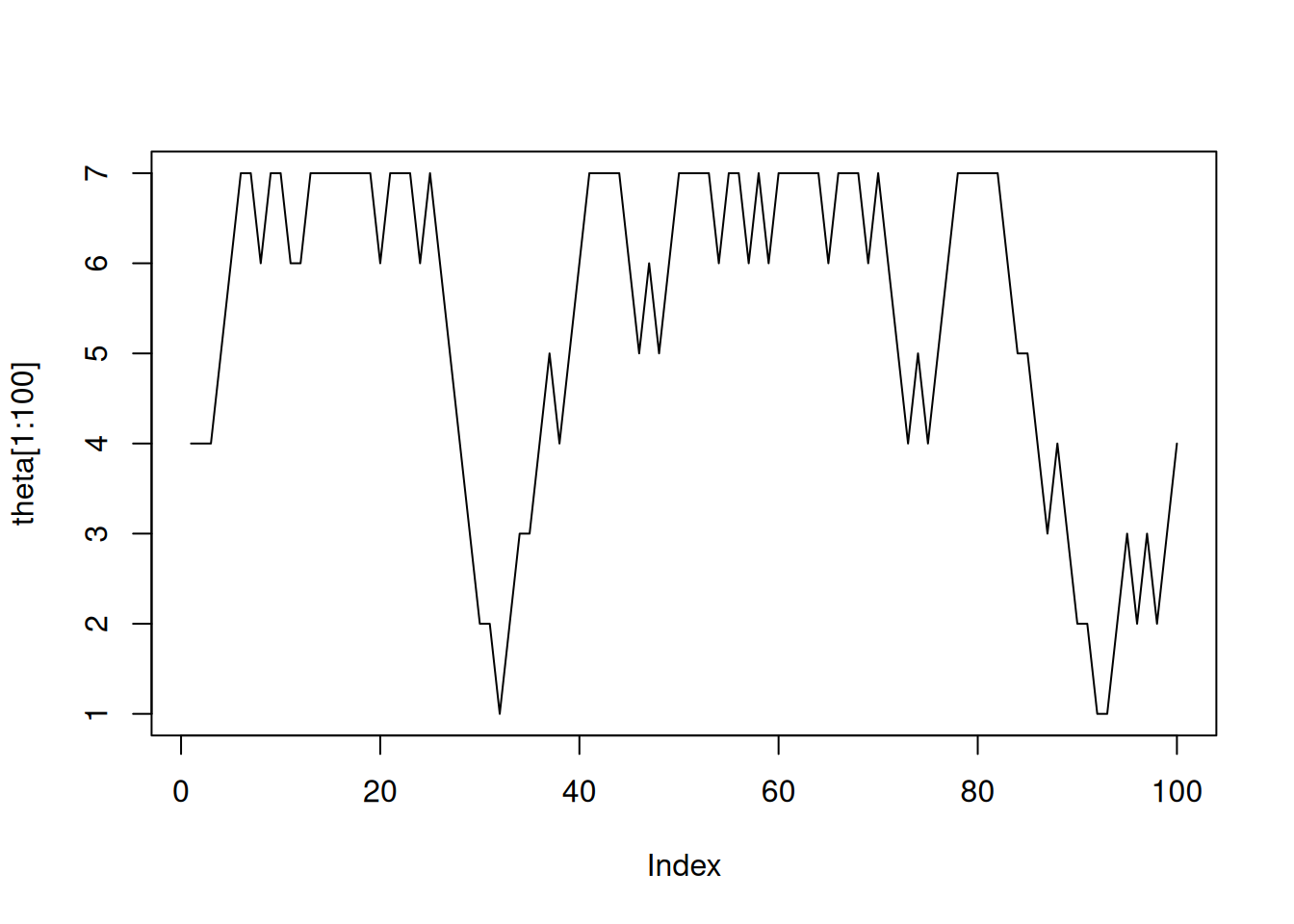
Y la caminata del político en sus primeros 100 pasos se puede visualizar así:
plot(theta[1:100],type='l')
5.3 Propiedades generales del muestreo aleatorio por Metropolis
En un muestreo aleatorio (random walk) con Metropolis, el camino específico que recorre el algoritmo es estocástico: en cada iteración se propone un movimiento (por ejemplo, hacia la izquierda o hacia la derecha con probabilidad \(50%\) cada uno) y se acepta con probabilidad
donde \(P(\theta)\) es la función objetivo (que no necesita estar normalizada). Si la propuesta lleva a un valor con mayor \(P\), siempre se acepta; de lo contrario, se acepta sólo con probabilidad proporcional a la razón de los valores.
Aunque las trayectorias individuales son muy diferentes cada vez que se corre el algoritmo, en el largo plazo la frecuencia relativa de visitas a cada estado converge hacia la distribución objetivo. Al inicio (\(t=1\)) uno está en un estado puntual (p. ej. \(\theta=4\) con probabilidad 1). Tras un paso (\(t=2\)) las probabilidades pueden calcularse analíticamente: con probabilidad \(0.5\) se propone ir a \(\theta=5\) y siempre se acepta (porque \(P(5)>P(4)\)), y con probabilidad \(0.5\) se propone ir a \(\theta=3\) y se acepta sólo con probabilidad \(3/4\), lo que da una probabilidad final de \(0.375\) de terminar en \(\theta=3\), \(0.5\) de ir a \(\theta=5\) y \(0.125\) de quedarse en \(\theta=4\). Para pasos posteriores, se repite el mismo razonamiento, de modo que a medida que \(t\) crece las “acumulaciones” de probabilidad sobre el estado inicial se difuminan y la curva de probabilidades se aproxima cada vez más a la forma de \(P(\theta)\).
En la práctica, en lugar de hacer estos cálculos exactos, simulamos un caminante que salta según esta regla durante muchos pasos y luego estimamos la distribución objetivo contando las visitas. A continuación se muestra un ejemplo en R que ilustra cómo, tanto de forma analítica (con potencias de la matriz de transición) como de forma empírica (simulando un gran número de saltos), la frecuencia de visitas se acerca a la distribución objetivo \(P(\theta)\propto \theta\) para \(\theta=1,\dots,7\).
# Definimos población relativa y matriz de transición para theta=1..7pop <-1:7n <-length(pop)P <-matrix(0, n, n)for(i in1:n){for(dir inc(-1,1)){ # proponer izquierda o derecha con prob 0.5 j <- i + dirif(j>=1&& j<=n){ accept_prob <-min(pop[j]/pop[i], 1) P[j, i] <- P[j, i] +0.5* accept_prob P[i, i] <- P[i, i] +0.5* (1- accept_prob) } else { P[i, i] <- P[i, i] +0.5# propuesta fuera de rango → rechazada } }}# Función para elevar una matriz P a la k-ésima potenciamat_pow <-function(P, k) { result <-diag(nrow(P))for (i inseq_len(k)) { result <- result %*% P } result}# 1) Cálculo analítico de la distribución en tiempos t = 1, 2, 3, 99times <-c(1,2,3,99)probs <-matrix(0, nrow=length(times), ncol=n)p0 <-rep(0, n); p0[4] <-1# empezamos en theta=4for(k inseq_along(times)){ step <- times[k] -1# mat_pow(P, step) equivale a P^step probs[k, ] <-mat_pow(P, step) %*% p0}rownames(probs) <-paste0("t=", times)colnames(probs) <-1:nprint(round(probs, 3))
Para \(t=99\), la distribución calculada analíticamente es muy cercana a \((1,2,3,4,5,6,7)/28\).
Las frecuencias empíricas tras \(10^5\) saltos reproducen con buena precisión esa misma proporción.
De este modo confirmamos que, sin necesidad de normalizar \(P(\theta)\), el algoritmo de Metropolis random walk explora correctamente la distribución objetivo.
En el proceso de caminata aleatoria (Metropolis), solo necesitamos tres habilidades básicas: generar propuestas de movimiento según una distribución sencilla, evaluar la densidad objetivo \(P(\theta)\) en cualquier punto propuesto —lo que nos da la razón de aceptación \(P(\theta_{\text{propuesto}})/P(\theta_{\text{actual}})\)— y extraer un número uniforme para decidir si aceptamos o rechazamos la propuesta. Con eso, obtenemos muestras de la distribución objetivo sin necesidad de normalizarla, es decir, sin calcular la constante de normalización \(p(D)\). Esto resulta crucial en inferencia bayesiana: basta con evaluar la función no normalizada \(p(D\mid\theta),p(\theta)\) para generar muestras representativas del posterior, evitando el costoso cómputo de la evidencia. Gracias a los algoritmos MCMC y la potencia de cómputo actual, ahora es factible aplicar métodos bayesianos a modelos complejos y grandes volúmenes de datos.
5.3.1 El algoritmo de Metropolis en su forma general
El método de Metropolis extiende la caminata aleatoria simple a espacios continuos de cualquier dimensión y a propuestas de movimiento más flexibles. Supongamos que queremos muestrear de una distribución objetivo \(P(\theta)\) definida sobre un espacio \(\theta\in\mathbb{R}^d\), donde basta que \(P(\theta)\ge0\) (no es necesario conocer la constante de normalización). En aplicaciones bayesianas, \(P(\theta)\) suele ser la función no normalizada del posterior, es decir, la multiplicación de la verosimilitud y la prior.
La caminata comienza en un punto \(\theta^{(0)}\) tal que \(P(\theta^{(0)})>0\). En cada iteración se genera una propuesta de movimiento \(\theta^*\) a partir de una distribución sencilla de simular—por ejemplo, una normal multivariada centrada en la posición actual,
theta_star <- theta_curr +rnorm(d, mean =0, sd = sigma_prop)
donde sigma_prop controla la escala de los pasos. Luego se calcula la razón de aceptación
Finalmente, se genera un número uniforme en \([0,1]\) con
u <-runif(1)
y aceptamos la propuesta si u < p_move; en caso contrario, nos quedamos en \(\theta_{\mathrm{curr}}\). Repetir este ciclo produce una cadena de Markov cuya distribución estacionaria es precisamente \(P(\theta)\).
La clave para la eficiencia del algoritmo es escoger una propuesta que explore bien las regiones de alta densidad de \(P(\theta)\), balanceando la probabilidad de aceptar saltos grandes frente a los pequeños. Gracias a este sencillo mecanismo de proponer y aceptar/rechazar, podemos generar muestras del posterior sin necesidad de calcular su constante de normalización, lo cual hace de Metropolis una herramienta fundamental en inferencia bayesiana para modelos complejos.
5.3.2 Metropolis con verosimilitud Bernoulli y prior Beta
Para ilustrar el algoritmo de Metropolis en un caso clásico, consideremos el problema de inferir la probabilidad \(\theta\) de “cara” al lanzar una moneda \(N\) veces y observar \(z\) caras. Asumimos la verosimilitud binomial
y un prior \(\theta\sim \mathrm{Beta}(a,b)\). Nuestro objetivo es generar una cadena de Markov cuya distribución de estados converge a la densidad posterior
Si \(\theta^*\notin(0,1)\), tomamos \(p_{\mathrm{move}}=0\).
Se simula \(u\sim\mathrm{Uniform}(0,1)\) y se acepta \(\theta^{(i)}=\theta^*\) si \(u<p_{\mathrm{move}}\), o bien \(\theta^{(i)}=\theta^{(i-1)}\) en caso contrario.
Repetir hasta acumular suficientes iteraciones.
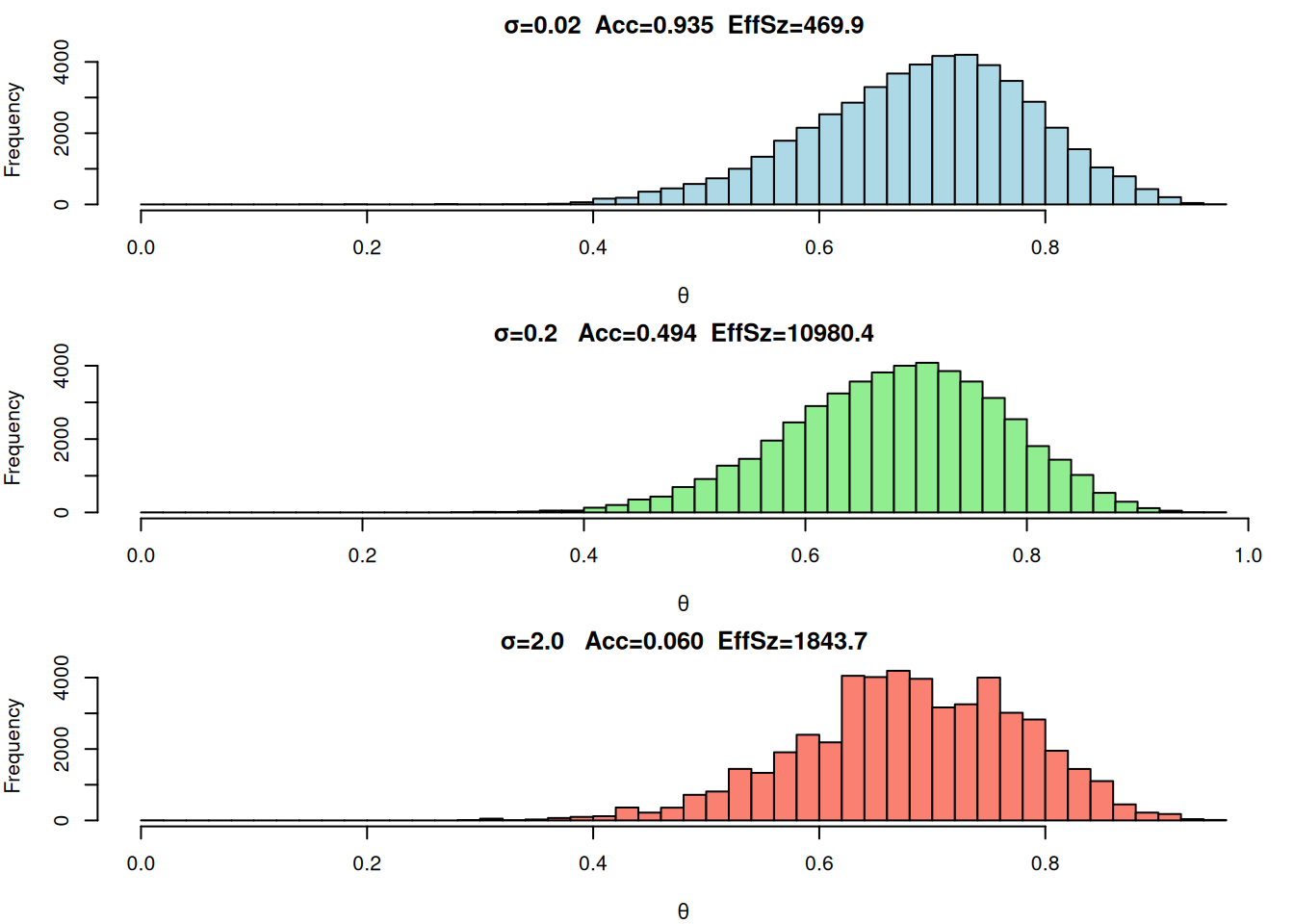
El parámetro clave es \(\sigma\), la desviación típica de la propuesta: si es muy pequeña la cadena avanza lentamente (alta autocorrelación), y si es muy grande la mayoría de propuestas se rechazan. A continuación se muestra un ejemplo en R con \(N=20\), \(z=14\), prior beta no informativo \((a=b=1)\), 50 000 iteraciones y tres valores de \(\sigma\). Para cada caso calculamos la tasa de aceptación y el “tamaño efectivo” con el paquete coda.
#--- Definición de log-posterior no normalizada ---logpost <-function(theta, z, N, a, b) {if(theta <=0|| theta >=1) return(-Inf) dbin <-dbinom(z, N, theta, log=TRUE) dbet <-dbeta(theta, a, b, log=TRUE)return(dbin + dbet)}#--- Función Metropolis ---metropolis <-function(z, N, a, b, sigma, init=0.01, n=50000) { chain <-numeric(n) chain[1] <- init acc <-0for(i in2:n) { theta_cur <- chain[i-1] theta_prop <- theta_cur +rnorm(1, 0, sigma) lp_cur <-logpost(theta_cur, z, N, a, b) lp_prop <-logpost(theta_prop, z, N, a, b) p_move <-min(1, exp(lp_prop - lp_cur))if(runif(1) < p_move) { chain[i] <- theta_prop acc <- acc +1 } else { chain[i] <- theta_cur } }list(chain=chain, acc_rate=acc/(n-1))}#--- Parámetros y simulaciones ---library(coda)z <-14; N <-20; a <-1; b <-1set.seed(42)res1 <-metropolis(z, N, a, b, sigma=0.02)res2 <-metropolis(z, N, a, b, sigma=0.2)res3 <-metropolis(z, N, a, b, sigma=2.0)#--- Cálculo de tamaño efectivo ---ess1 <-effectiveSize(mcmc(res1$chain))ess2 <-effectiveSize(mcmc(res2$chain))ess3 <-effectiveSize(mcmc(res3$chain))#--- Histogramas comparativos ---par(mfrow=c(3,1), mar=c(4,4,2,1))hist(res1$chain, breaks=50,main=sprintf("σ=0.02 Acc=%.3f EffSz=%.1f", res1$acc_rate, ess1),xlab=expression(theta), col="lightblue")hist(res2$chain, breaks=50,main=sprintf("σ=0.2 Acc=%.3f EffSz=%.1f", res2$acc_rate, ess2),xlab=expression(theta), col="lightgreen")hist(res3$chain, breaks=50,main=sprintf("σ=2.0 Acc=%.3f EffSz=%.1f", res3$acc_rate, ess3),xlab=expression(theta), col="salmon")
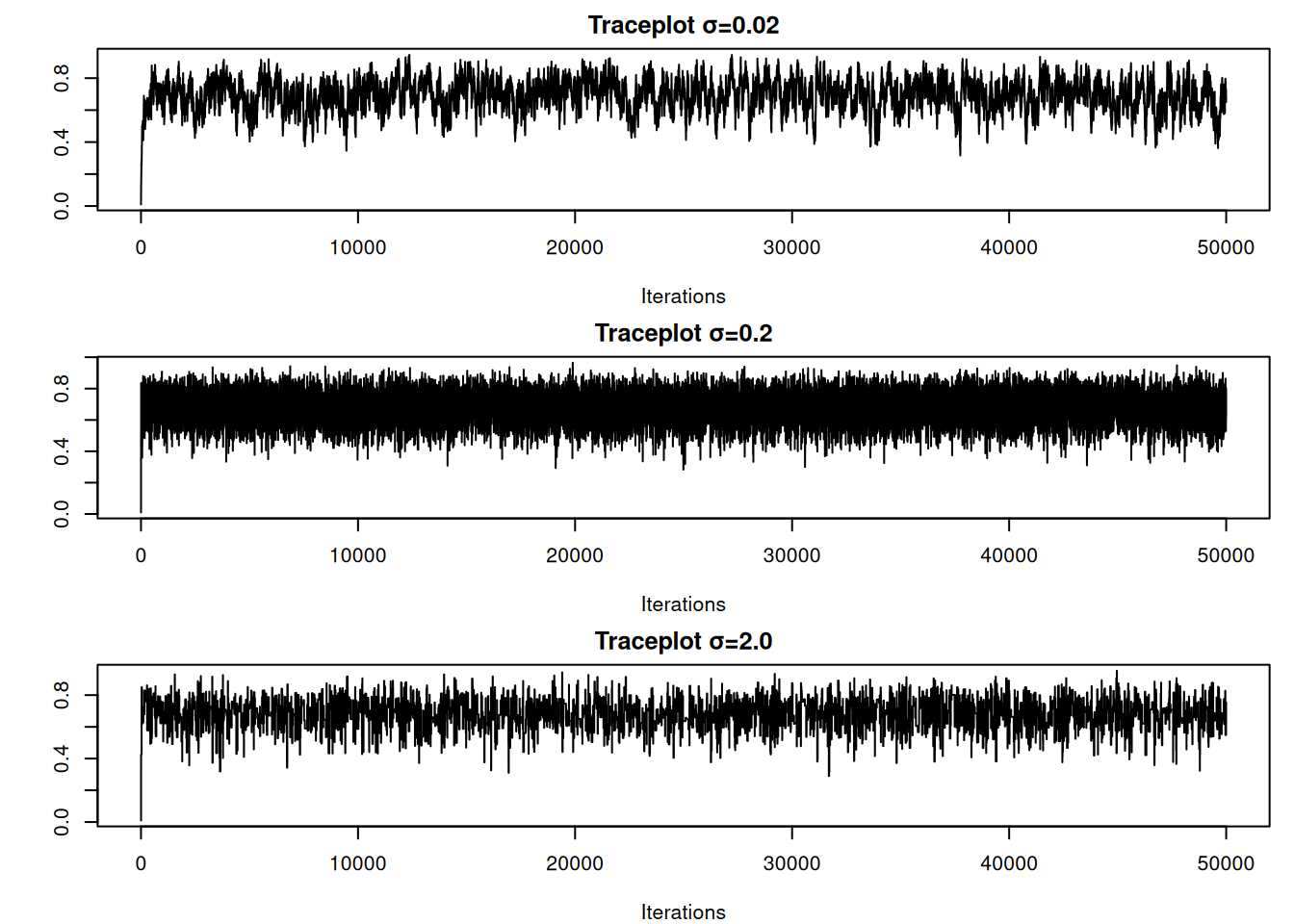
#--- Traceplots de theta para cada σ ---par(mfrow=c(3,1), mar=c(4,4,2,1))traceplot(mcmc(res1$chain), main="Traceplot σ=0.02")traceplot(mcmc(res2$chain), main="Traceplot σ=0.2")traceplot(mcmc(res3$chain), main="Traceplot σ=2.0")
En este ejemplo se observa que:
σ=0.02: propuesta muy estrecha → alta aceptación pero cadena “pegada” (EffSz≈469).
σ=0.2: balance óptimo → aceptación cercana a 0.5 y EffSz≈11724.
σ=2.0: propuesta muy amplia → baja exploración y EffSz≈2113.
Independientemente de σ, la cadena converge al mismo histograma (que se superpone bien con la Beta posterior analítica), pero la eficiencia varía enormemente. Una regla práctica es ajustar σ para lograr una tasa de aceptación intermedia (≈0.3–0.5) y así maximizar el tamaño efectivo de la muestra.
5.4 Algoritmos de Metropolis–Hastings
En problemas donde la posterior \(g(\theta\mid y)\) no tiene una forma conocida para muestrear directamente, podemos construir una cadena de Markov continua cuya distribución estacionaria sea precisamente la posterior. El algoritmo de Metropolis–Hastings se basa en generar una secuencia \({\theta^{t}}\) de manera que, tras un número suficiente de iteraciones, los valores de \(\theta^{t}\) se distribuyan según \(g(\theta\mid y)\).
Partimos de un valor inicial \(\theta^{0}\) y, en cada paso, proponemos un candidato \(\theta^{*}\) utilizando una densidad propuesta\(p(\theta^{*}\mid \theta^{t-1})\). A continuación, calculamos el cociente
\[
R \;=\;\frac{g(\theta^{*})\,p(\theta^{t-1}\mid \theta^{*})}{g(\theta^{t-1})\,p(\theta^{*}\mid \theta^{t-1})}
\]
y la probabilidad de aceptación\(P=\min\{R,1\}\). Con probabilidad \(P\) aceptamos \(\theta^{*}\) (y fijamos \(\theta^t=\theta^{*}\)); en caso contrario rehusamos el candidato y repetimos el paso manteniendo \(\theta^t=\theta^{t-1}\). Bajo condiciones de irreducibilidad y aperiodicidad, esta cadena converge a la posterior deseada.
Existen dos variantes muy utilizadas:
Cadena de independencia: la propuesta no depende del estado actual, es decir \(p(\theta^{*}\mid \theta^{t-1}) = p(\theta^{*}).\)
Cadena de caminata aleatoria: la propuesta se construye como un desplazamiento simétrico, \(p(\theta^{*}\mid \theta^{t-1})=h(\theta^{*}-\theta^{t-1}),\) con \(h\) simétrica alrededor de 0. En este caso la fórmula de \(R\) se simplifica a \(R=\frac{g(\theta^{*})}{g(\theta^{t-1})}.\)
En el paquete LearnBayes de R, las funciones rwmetrop e indepmetrop implementan, respectivamente, la caminata aleatoria y la cadena de independencia usando propuestas normales multivariadas. El usuario debe especificar la densidad log-posterior y los parámetros de la propuesta (media y matriz de covarianza, y en rwmetrop además un factor de escala). El resultado es una matriz de iteraciones (par) y la tasa de aceptación (accept), que permite evaluar la eficiencia del muestreo.
Un buen diseño de la propuesta depende de la dimensión y la forma de la posterior. Para cadenas de independencia, conviene que \(p\) se aproxime a \(g\) sin descuidar las colas (debe cumplirse \(g/p\) acotado). Para caminatas aleatorias normales, es habitual buscar tasas de aceptación entre 25 % y 45 %, descendiendo al aumentar la dimensión del parámetro. Estos consejos también se aplican a variantes que combinan Metropolis–Hastings con actualizaciones condicionales (Metropolis-within-Gibbs).
5.5 Hacia el muestreo de Gibbs: estimando dos sesgos de monedas
El método de Metropolis es muy general, pero puede resultar ineficiente cuando el número de parámetros crece. Para ilustrar una alternativa más eficaz, introducimos un ejemplo con dos parámetros: estimar simultáneamente los sesgos de dos monedas independientes. Este problema se modela de forma análoga a comparar proporciones en dos grupos, como en un ensayo clínico (12 de 51 pacientes mejoran con el fármaco frente a 5 de 46 con placebo) o en un experimento sobre estado de ánimo (32 de 42 aciertan tras una película dramática frente a 27 de 41 tras una comedia).
Denotemos por \(\theta_j\) el sesgo de la moneda \(j\) (\(j=1,2\)), por \(N_j\) el número de lanzamientos y por \(z_j\) el número de caras observadas. Bajo la suposición de independencia entre las dos series de lanzamientos, el modelo conjunto se factoriza en dos binomiales
y podemos asignar una prior Beta independiente a cada \(\theta_j\).
En este contexto, el muestreo de Gibbs explota el hecho de que las distribuciones condicionales completas de cada parámetro \(\theta_j\) tienen forma Beta conjugada, dada la otra componente y los datos. Así, en lugar de proponer cambios en el vector completo \((\theta_1,\theta_2)\) (como en Metropolis), alternamos entre:
y así sucesivamente, obteniendo una cadena de Markov que converge mucho más rápido y con movimientos “sin rechazos” en cada paso.
Este sencillo ejemplo de dos proporciones muestra la gran ventaja de Gibbs: al diseñar modelos con varios parámetros que admiten condicionales fáciles de muestrear (p.ej., conjugados), evitamos el rechazo y la afinación de tasas de aceptación, consiguiendo una exploración más eficiente del espacio de parámetros.
5.5.1 Prior, verosimilitud y posterior para dos sesgos
Para estimar de forma bayesiana los sesgos de dos monedas, denotamos por \(\theta_{1}\) y \(\theta_{2}\) los parámetros de interés, cada uno tomando valores en \([0,1]\). Antes de ver los datos, necesitamos especificar nuestra distribución a priori conjunta \(p(\theta_{1},\theta_{2})\), que asigna credibilidad a cada par \((\theta_{1},\theta_{2})\) y satisface
aunque podría considerarse una dependencia si se desea vincular los sesgos de ambas monedas.
A continuación, tras recoger los datos independientes de cada moneda —\(z_{1}\) caras en \(N_{1}\) lanzamientos para la moneda 1, y \(z_{2}\) caras en \(N_{2}\) lanzamientos para la moneda 2— la verosimilitud conjunta de \((\theta_{1},\theta_{2})\) es el producto de dos funciones binomiales:
donde el denominador es la constante de normalización (evidencia) que asegura que el área total bajo la densidad posterior sea 1.
En la práctica, para visualizar y simular desde esta posterior de dos parámetros podemos emplear métodos de muestreo de Gibbs, aprovechando la independencia previa y la factoración de la verosimilitud, o métodos de Monte Carlo como Metropolis–Hastings en el espacio bidimensional \((\theta_{1},\theta_{2})\).
5.5.2 Análisis Formal
Cuando la verosimilitud es binomial y se tiene un par de sesgos independientes \(\theta_{1},\theta_{2}\), resulta natural elegir distribuciones beta como priors, pues son conjugadas. En particular, si asumimos
5.5.3 El posterior vía el algoritmo de Metropolis (ejemplo de dos sesgos de moneda)
Para ilustrar el algoritmo de Metropolis en un modelo con dos parámetros, consideremos nuevamente el problema de estimar los sesgos de dos monedas, con datos independientes de cada una. Denotemos por \(z_1\) el número de caras en \(N_1\) lanzamientos de la moneda 1, y por \(z_2\) el número de caras en \(N_2\) lanzamientos de la moneda 2. Asumimos priors independientes \(\theta_j\sim\mathrm{Beta}(a_j,b_j)\), de modo que la densidad no normalizada del posterior es \[
P(\theta_1,\theta_2)\;\propto\;\theta_1^{z_1+a_1-1}(1-\theta_1)^{N_1-z_1+b_1-1}\;\times\;\theta_2^{z_2+a_2-1}(1-\theta_2)^{N_2-z_2+b_2-1}.
\]
En cada paso de Metropolis generamos un salto \((\Delta_1,\Delta_2)\) desde una normal bivariante centrada en cero (por ejemplo, con covarianza \(\sigma^2I\)), proponemos \[
(\theta_1^*,\theta_2^*)=(\theta_1^{(t)}+\Delta_1,\;\theta_2^{(t)}+\Delta_2),
\]
y aceptamos este nuevo par con probabilidad \[
p_{\mathrm{move}}=\min\!\bigl(1,\;P(\theta_1^*,\theta_2^*)/P(\theta_1^{(t)},\theta_2^{(t)})\bigr).
\]
Si el salto se rechaza, volvemos a contar el punto actual.
A continuación se muestra un ejemplo en R que implementa este procedimiento, genera una cadena y calcula algunos estadísticos. Sustituye z1, N1, z2, N2, a1, b1, a2, b2 por tus valores de datos y prior.
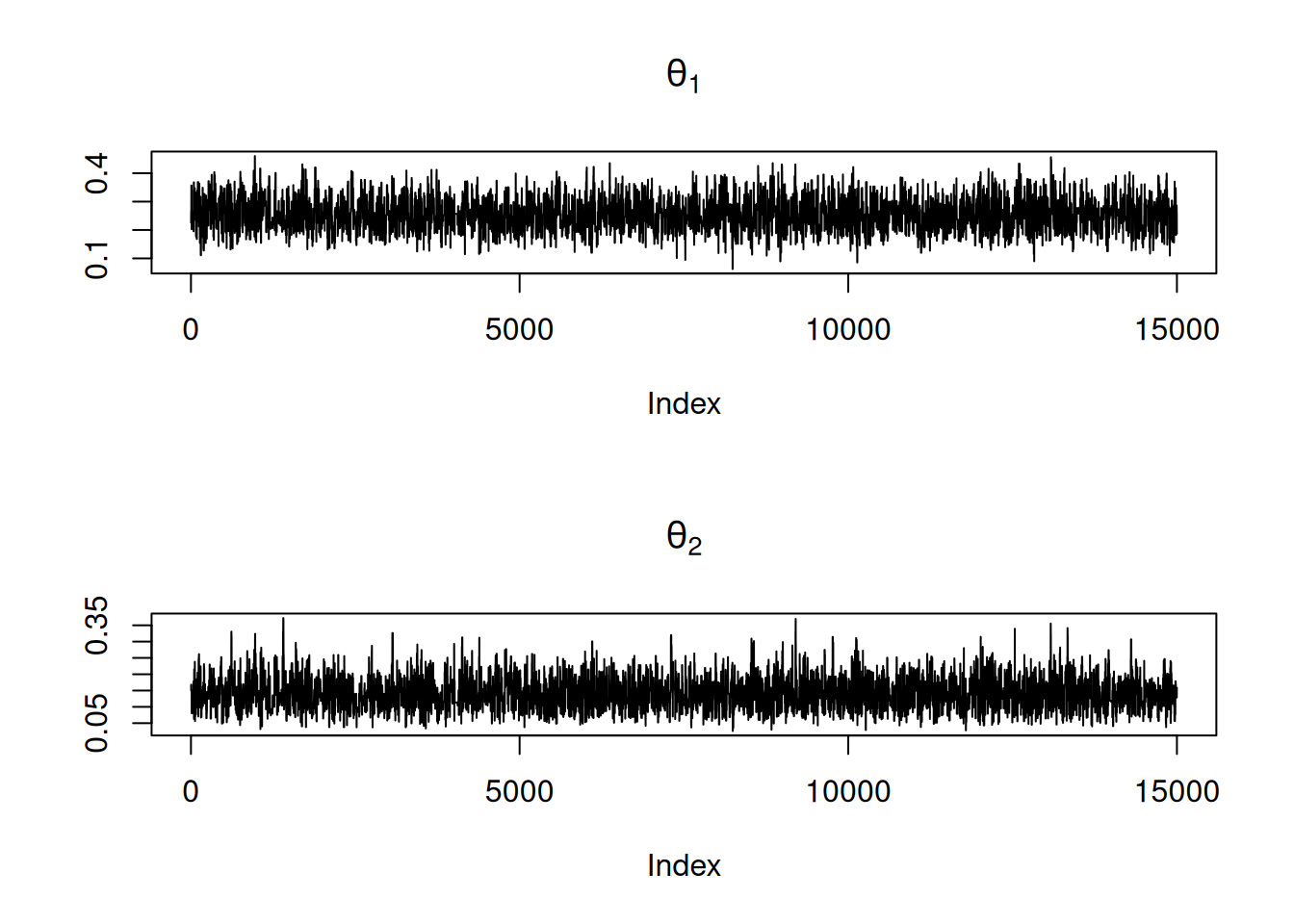
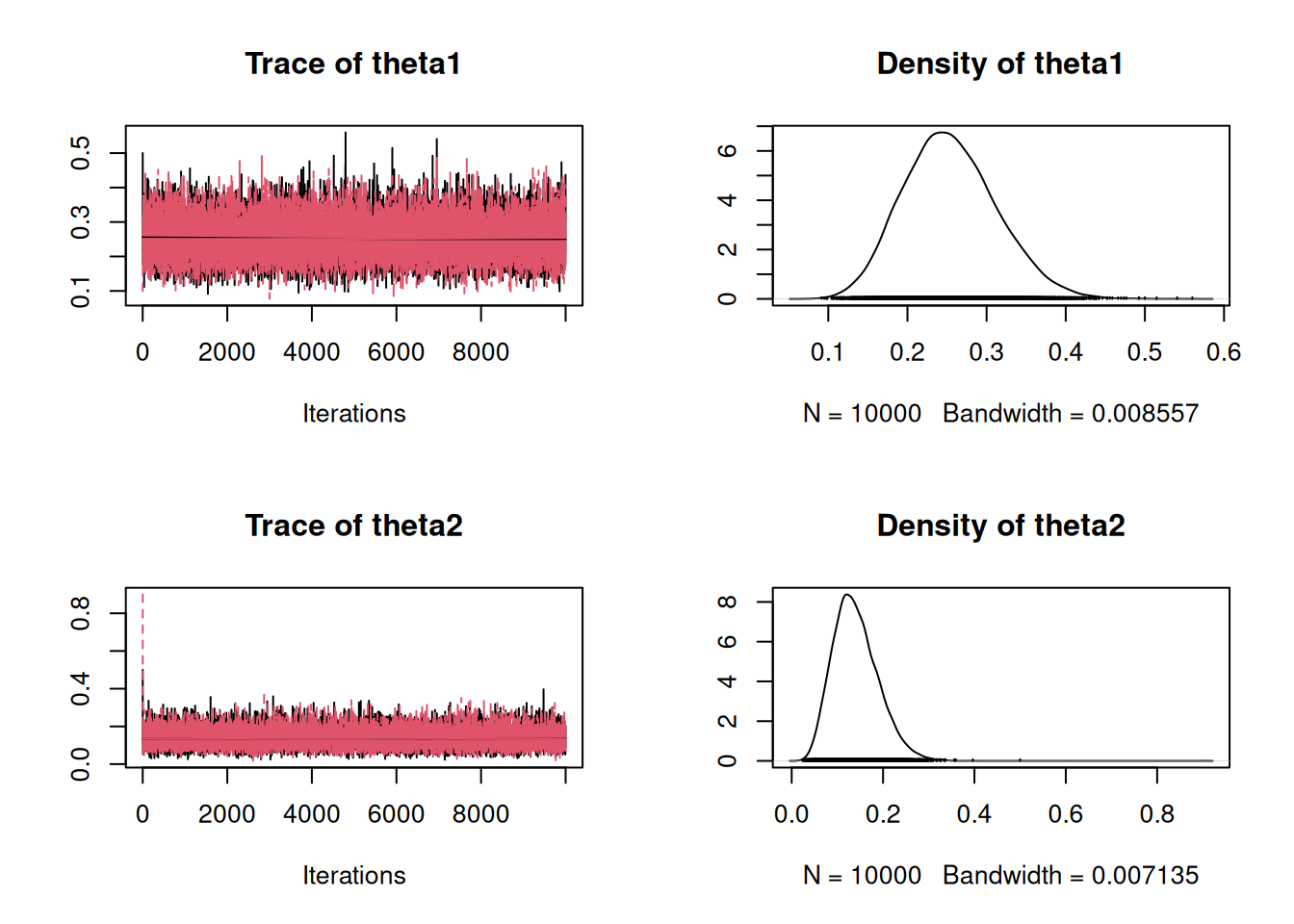
En este ejemplo, runMetropolis genera una muestra de la densidad conjunta de \((\theta_1,\theta_2)\). Los traceplots permiten inspeccionar la mezcla de la cadena.
El muestreo de Gibbs es una alternativa al algoritmo de Metropolis que evita la afinación de una distribución propuesta y garantiza que cada paso sea aceptado. Su conveniencia radica en que, si podemos derivar y muestrear directamente las distribuciones posteriores condicionales de cada parámetro, cada actualización es exacta y sin rechazos.
En el caso de los sesgos de dos monedas, con datos
- Moneda 1: \(z_1\) éxitos de \(N_1\) lanzamientos
- Moneda 2: \(z_2\) éxitos de \(N_2\) lanzamientos
y priors independientes \[
\theta_1\sim\mathrm{Beta}(a_1,b_1),\quad
\theta_2\sim\mathrm{Beta}(a_2,b_2),
\]
las condicionales vienen dadas por
Este método no requiere rechazo de propuestas y, en muchos casos, obtiene un ESS muy superior al de Metropolis para la misma longitud de cadena.
5.5.5 ¿Hay diferencia entre los sesgos?
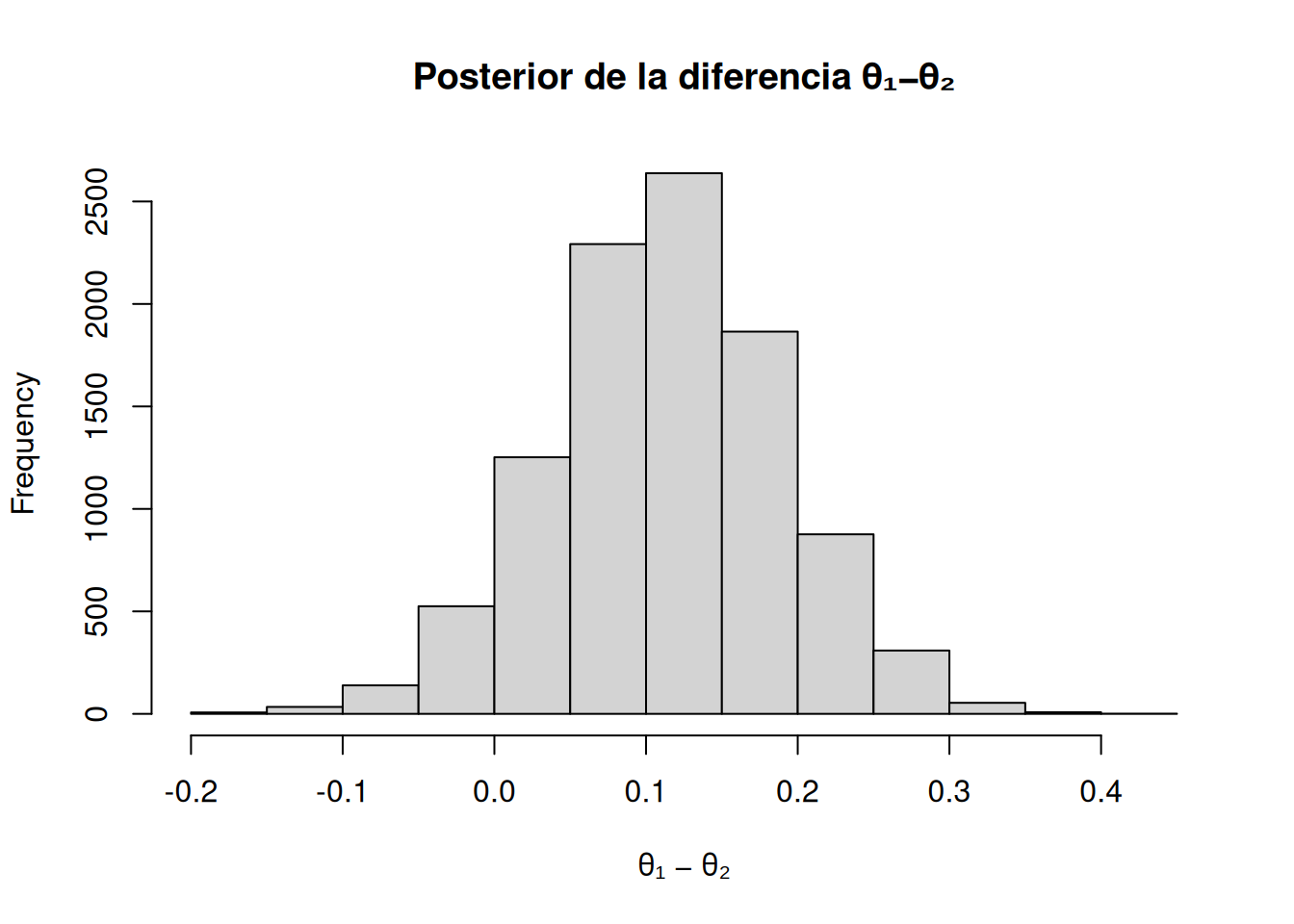
El interés central ya no es tanto la mecánica del muestreo, sino la inferencia sobre la diferencia real entre los sesgos de las dos monedas, \(\theta_1-\theta_2\). A partir de la muestra conjunta posterior (ya sea obtenida por Metropolis o por Gibbs), cada par \((\theta_1,\theta_2)\) simulado nos da una realización de dicha diferencia. Al recolectar todas estas diferencias a lo largo de la cadena, formamos un histograma posterior de \(\delta = \theta_1-\theta_2\), que resume nuestra incertidumbre sobre cuán distintos pueden ser los sesgos.
En la práctica, tras descartar el burn‐in, basta con calcular
delta <- theta[,1] - theta[,2]hist(delta, main="Posterior de la diferencia θ₁−θ₂", xlab="θ₁ − θ₂")
quantile(delta, c(0.025, 0.975))
2.5% 97.5%
-0.03800962 0.26550451
para visualizar la distribución y obtener su intervalo de credibilidad al 95 %.
5.6 Representatividad, precisión y eficiencia de MCMC
Al generar una muestra MCMC del posterior, tenemos tres objetivos fundamentales.
Primero, los valores de la cadena deben representar fielmente la distribución posterior, sin verse dominados por el valor inicial ni quedarse “atorados” en zonas reducidas del espacio de parámetros. Segundo, la cadena debe ser lo bastante larga para que las estimaciones (medianas, modos, límites del \(95\%\) HDI, etc.) sean estables: al repetir el análisis con otras semillas, los resultados no deberían cambiar sustancialmente. Tercero, queremos lograr todo ello de la forma más eficiente posible, con el menor número de iteraciones, para no agotar recursos de tiempo o memoria.
En la práctica trabajamos con cadenas finitas, por lo que: - Debemos aplicar un período de burn-in para descartar las primeras iteraciones no representativas. - Debemos comprobar que la cadena explore todo el soporte posterior y mezcle bien. - Debemos estimar la incertidumbre de Monte Carlo en nuestras cantidades de interés, reconociendo que la autocorrelación reduce el número de “muestras efectivas”.
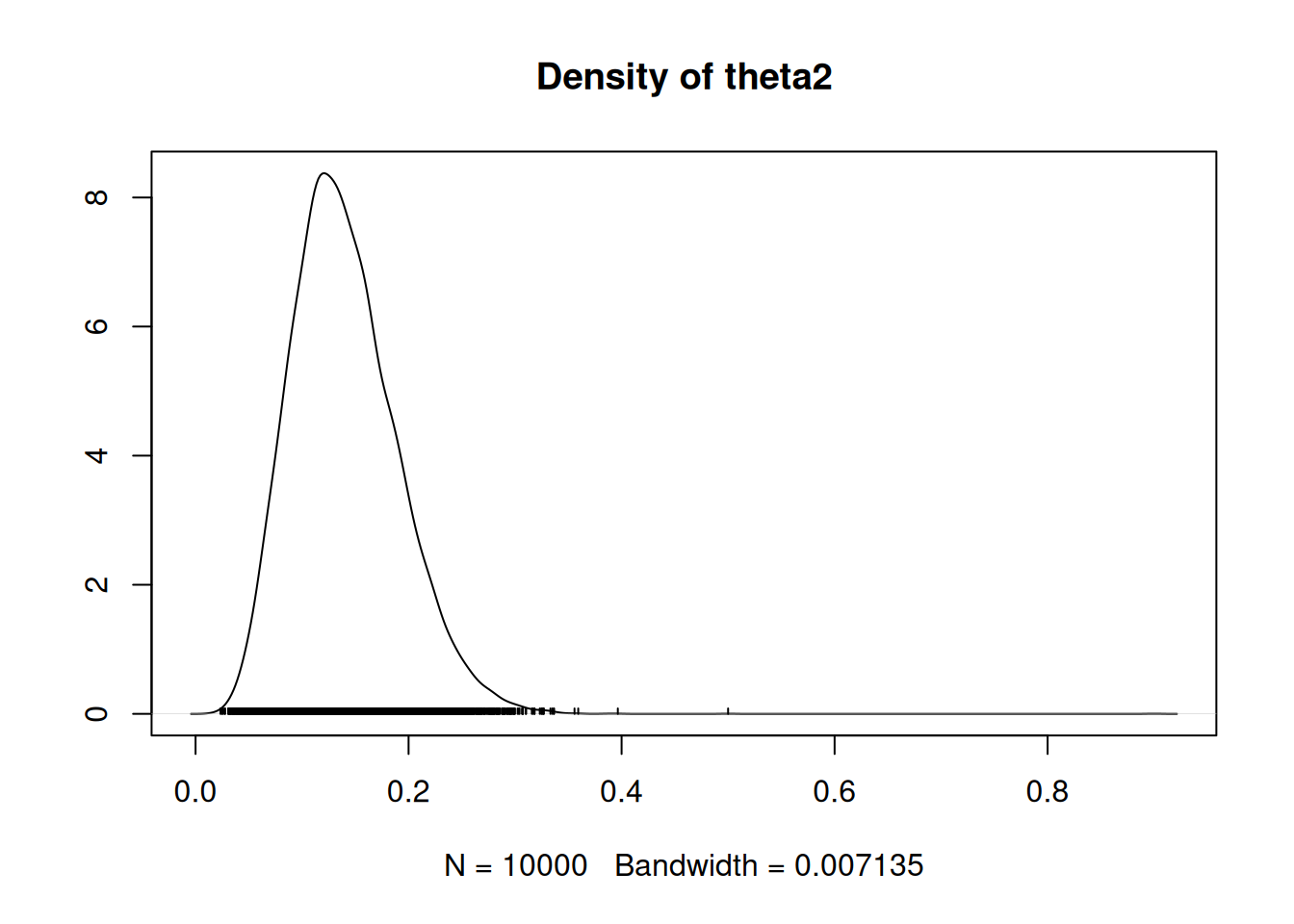
5.6.1 Representatividad de MCMC
Para diagnosticar la representatividad se usan principalmente dos métodos:
Inspección visual
Trace plots de varios parámetros superpuestos (o de varias cadenas iniciadas en diferentes valores). Si tras el burn-in las cadenas se solapan y vagan por el espacio paramétrico sin quedarse mucho tiempo en un mismo valor, es señal de buena representatividad.
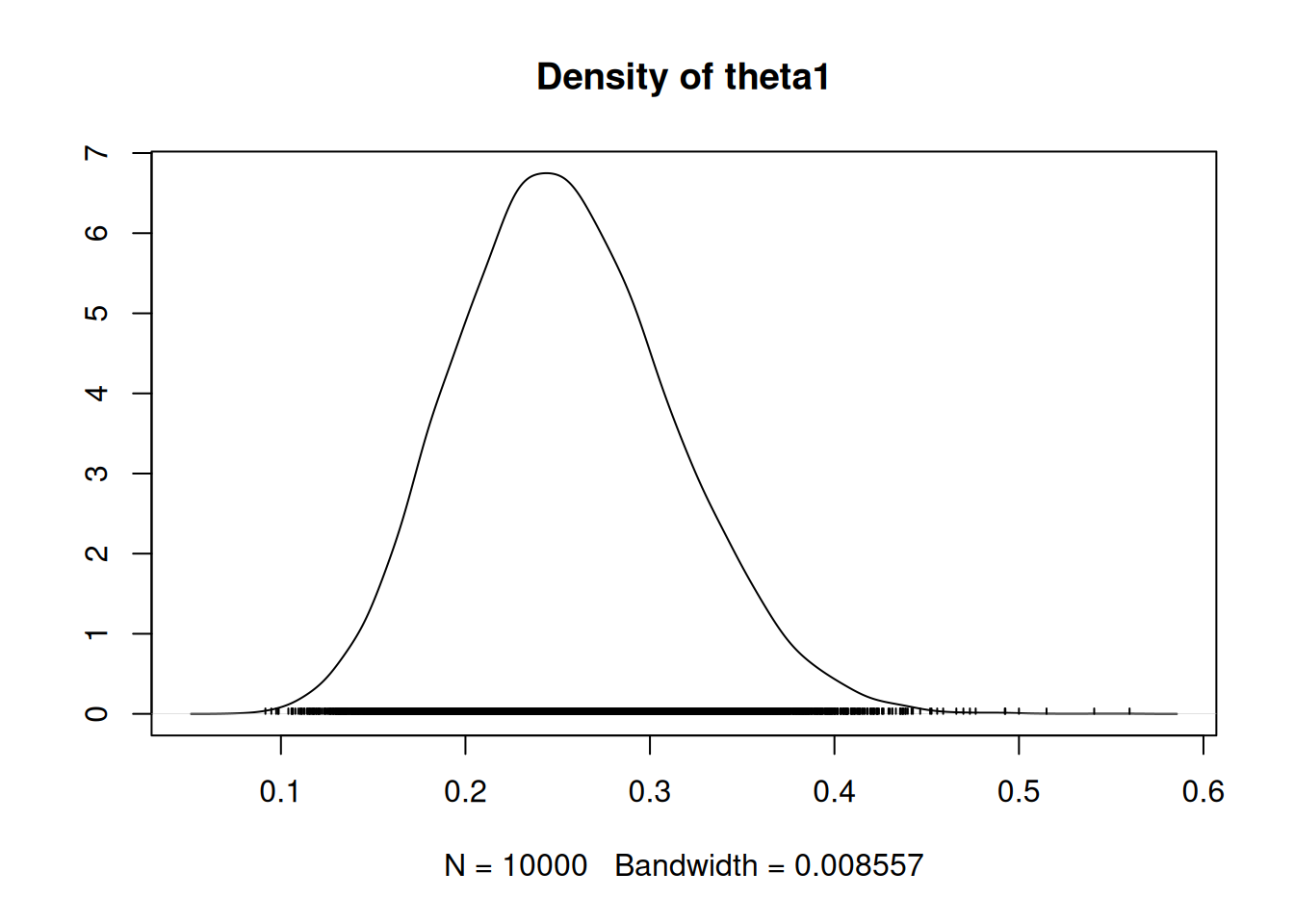
Densidades suavizadas (density plots) de cada cadena: durante el burn-in las densidades difieren, pero después deben coincidir y abarcar el mismo rango.
Diagnósticos numéricos
El estadístico de Gelman–Rubin (o factor de reducción de escala potencial) compara la varianza entre cadenas con la varianza interna a cada cadena. Un valor cercano a 1.0 indica convergencia; valores mayores (por ejemplo > 1.1) advierten de falta de representatividad.
Estas herramientas (trace plots, density plots y Gelman–Rubin), disponibles en el paquete coda de R, permiten decidir cuántas iteraciones de burn-in descartar y si es necesario alargar la cadena o ajustar el algoritmo para mejorar la exploración del espacio posterior.
# 3) Estadístico de Gelman–Rubingelman <-gelman.diag(mcmc_chains, autoburnin=FALSE)print(gelman)
Potential scale reduction factors:
Point est. Upper C.I.
theta1 1 1
theta2 1 1
Multivariate psrf
1
5.6.2 Precisión de MCMC
Una vez que hemos comprobado que nuestras cadenas convergieron y son representativas, el siguiente objetivo es que la muestra sea lo suficientemente larga para que las estimaciones numéricas (medias, medianas, límites del 95 % HDI, etc.) resulten estables y precisas. Sin embargo, debido a que los pasos sucesivos de una cadena MCMC suelen autocorrelacionarse, no todos aportan información independiente sobre la distribución posterior.
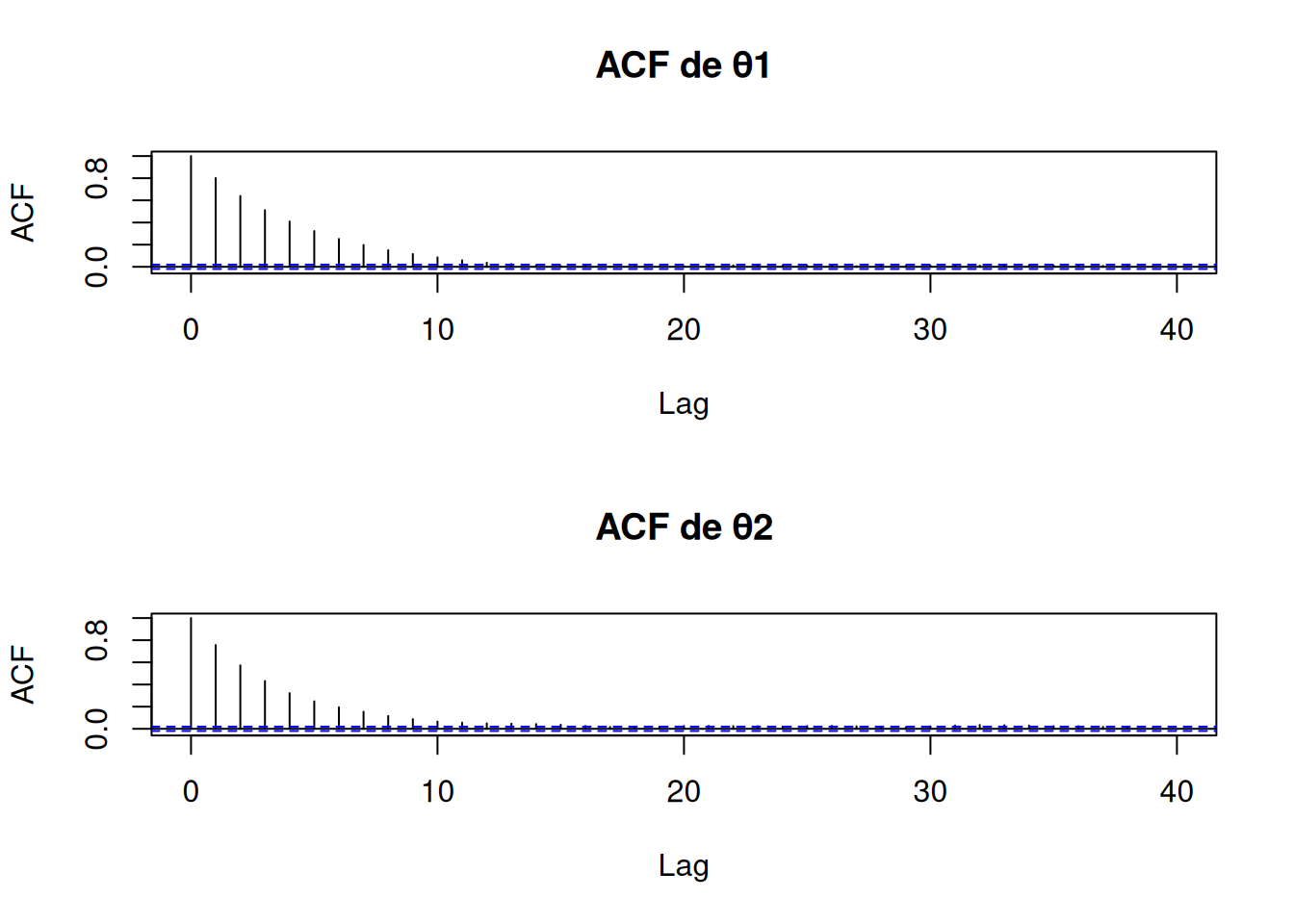
La autocorrelación a lag \(k\) se define como la correlación entre los valores \({\theta^t}\) y \({\theta^{t+k}}\). Graficar la función de autocorrelación (ACF) nos muestra cuánto tarda la cadena en “olvidarse” de su valor actual; cadenas muy “pesadas” mantienen ACF(\(k\)) alta incluso para lags grandes. Para cuantificar cuánta información independiente hay en una cadena de longitud real \(N\), se emplea el concepto de tamaño efectivo de muestra (ESS), definido informalmente como
donde la suma suele truncarse cuando \(\mathrm{ACF}(k)<0.05\). En la práctica, la función effectiveSize() del paquete coda calcula el ESS de cada parámetro sin necesidad de implementar la suma explícita.
Un ESS elevado significa que, pese a la autocorrelación, la cadena proporciona casi tantas “muestras independientes” como sugiere su longitud real. Como regla empírica, para estimar con fiabilidad los límites del 95 % HDI conviene un ESS de al menos un 20% del total de muestras MCMC, pues las regiones de cola requieren muchos puntos para definirse con precisión.
Para medir directamente la incertidumbre de un estimador (por ejemplo, la media posterior), se utiliza el error estándar Monte Carlo (MCSE). Una formulación sencilla es reemplazar \(N\) por ESS en la fórmula clásica de la desviación estándar de la media:
donde SD es la desviación estándar de la cadena. El MCSE da la escala de la imprecisión del estimador debido al ruido de muestreo MCMC y resulta particularmente útil cuando necesitamos cuantificar la estabilidad de cantidades puntuales.
En resumen, para garantizar precisión en un análisis MCMC conviene revisar la ACF (o el ESS) para evaluar la autonomía de los pasos, y calcular el MCSE para saber cuán confiables serán nuestras estimaciones de media, medianas o límites de intervalo. Una ESS de orden \(10^4\) suele ser un buen punto de partida para asegurar estimaciones robustas de los cuantiles del posterior.
# Effective Sample Sizeess <-effectiveSize(mcmc.chain)# Monte Carlo SE (MCSE) para la media de cada parámetrosds <-apply(chain, 2, sd)mcse <- sds /sqrt(ess)# Resultadosess
var1 var2
1104.717 1387.524
mcse
var1 var2
0.001814120 0.001287625
5.6.3 Eficiencia de MCMC
Uno de los objetivos principales en MCMC, además de representatividad y precisión, es la eficiencia: queremos obtener una muestra suficientemente informativa sin agotar nuestro tiempo de cómputo o la paciencia. En aplicaciones reales suele haber alta autocorrelación en algunos parámetros, lo que obliga a cadenas muy largas para alcanzar un ESS o un MCSE aceptables. A continuación se indican tres estrategias generales para mejorar la eficiencia:
Ejecución en paralelo. Aprovechar múltiples núcleos o procesadores para correr cadenas simultáneas. Aunque cada cadena conserva la misma autocorrelación, obtenemos más información por unidad de tiempo real. Paquetes como runjags facilitan este paralelismo.
Elegir un método de muestreo más eficiente. A menudo un muestreador distinto —por ejemplo, pasar de Metropolis a Gibbs o a Hamiltonian Monte Carlo— puede reducir drásticamente la autocorrelación y aumentar el ESS. La versión de HMC en Stan es un ejemplo moderno de muestreo muy eficiente.
Reparametrización del modelo. Una transformación algebraica de los parámetros puede “romper” correlaciones fuertes y acelerar la convergencia. Por ejemplo, en regresión se suele centrear la variable predictora para reducir la correlación entre intercepto y pendiente. Cada modelo puede requerir un truco distinto.
Una práctica común pero engañosa es el thinning: conservar sólo cada \(k\)-ésimo paso de la cadena. Aunque reduce la autocorrelación en la serie almacenada, también pierde información útil y no ahorra tiempo de simulación. Sólo está justificado si hay limitaciones de memoria o de velocidad al procesar el resultado.
5.7 Muestreo de Gibbs
El muestreo de Gibbs es una estrategia MCMC que explota la simplicidad de las distribuciones condicionales si estas son accesibles. Sea el vector de parámetros \(\theta=(\theta_{1},\dots,\theta_{p})\) con posterior conjunta \([\theta\mid\text{data}]\). Si podemos identificar cada una de las distribuciones condicionales
bastará simular cíclicamente un valor de cada \(\theta_{i}\) de su distribución condicional, manteniendo fijas las demás componentes, para construir una cadena de Markov cuya distribución estacionaria es la posterior conjunta. Bajo condiciones estándar de irreducibilidad y aperiodicidad, las iteraciones convergen a la posterior deseada.
En muchos modelos estas distribuciones condicionales son conocidas y se muestrea directamente. Cuando no es así, se puede incorporar un paso de Metropolis (un “Metropolis dentro de Gibbs”) para cada componente: dado el estado actual \(\theta_{i}^{t}\), se propone
\[
P \;=\;\min\Bigl\{1,\;\frac{g(\theta_{i}^{*}\mid\theta_{-i},\text{data})}{g(\theta_{i}^{t}\mid\theta_{-i},\text{data})}\Bigr\},
\]
donde \(g(\theta_{i}\mid\theta_{-i},\text{data})\) es la densidad condicional (suponiendo fijos los demás parámetros \(\theta_{-i}\)). Esta variante permite aplicar Gibbs aún cuando las condicionales no estén en forma cerrada.
En R, la función gibbs del paquete LearnBayes automatiza este esquema: el usuario define la función log‐posterior, proporciona un valor inicial \(\theta^{0}\), el número de iteraciones y un vector de escalas \(c_{1},\dots,c_{p}\). El resultado incluye la matriz de simulaciones y las tasas de aceptación de cada paso de Metropolis, lo que facilita ajustar las escalas para obtener una buena mezcla.
5.8 Análisis de salidas en MCMC
Después de ejecutar un algoritmo MCMC (Metropolis‐Hastings, Gibbs u otro), los valores \(\theta^{(j)}\) generados convergen teóricamente al posterior \(g(\theta\mid\text{data})\) cuando \(j\to\infty\). Sin embargo, en la práctica no sabemos cuántas iteraciones son suficientes para aproximar bien esa distribución. El análisis de salida de MCMC consiste en evaluar si la cadena ha “mezclado” adecuadamente y si sus iteraciones ya reflejan el posterior.
Un primer aspecto a vigilar es el periodo de burn‐in. Al inicio, los primeros valores de la cadena dependen demasiado de la condición inicial y se comportan como la posterior. Para estimar cuántas iteraciones descartar, se suelen examinar diagramas de trazas (traceplots) de alguno de los componentes de \(\theta\) (o de alguna función de interés). Cuando la traza se asienta en una banda constante, podemos considerar superado el burn‐in.
Una segunda preocupación es la autocorrelación de la cadena. Dado que cada \(\theta^{(j+1)}\) depende de \(\theta^{(j)}\), valores sucesivos están correlacionados y aportan menos información que si fuesen poco correlacionados o independientes. Para cuantificar este efecto se calculan las autocorrelaciones a distintos lags\(L\), graficando \(\text{cor}(\theta^{(j)},\theta^{(j+L)})\) frente a \(L\). Una buena mezcla se refleja en autocorrelaciones que decaen rápidamente hacia cero.
Por último, al estimar un resumen de la posterior, por ejemplo la media posterior de \(\theta_i\):
surge la pregunta de su error de simulación. Debido a la dependencia entre iteraciones, no es válido usar la fórmula de muestra independiente. Un método sencillo es el de medias por bloques: se divide la cadena de longitud \(m\) en \(b\) bloques de tamaño \(v=m/b\), se calcula la media en cada bloque,
y se estima el error estándar como la desviación estándar de estas medias dividida por \(\sqrt{b}\). Si las autocorrelaciones entre bloques consecutivos son bajas, esta aproximación es válida y permite cuantificar la precisión de los estimadores obtenidos por MCMC.