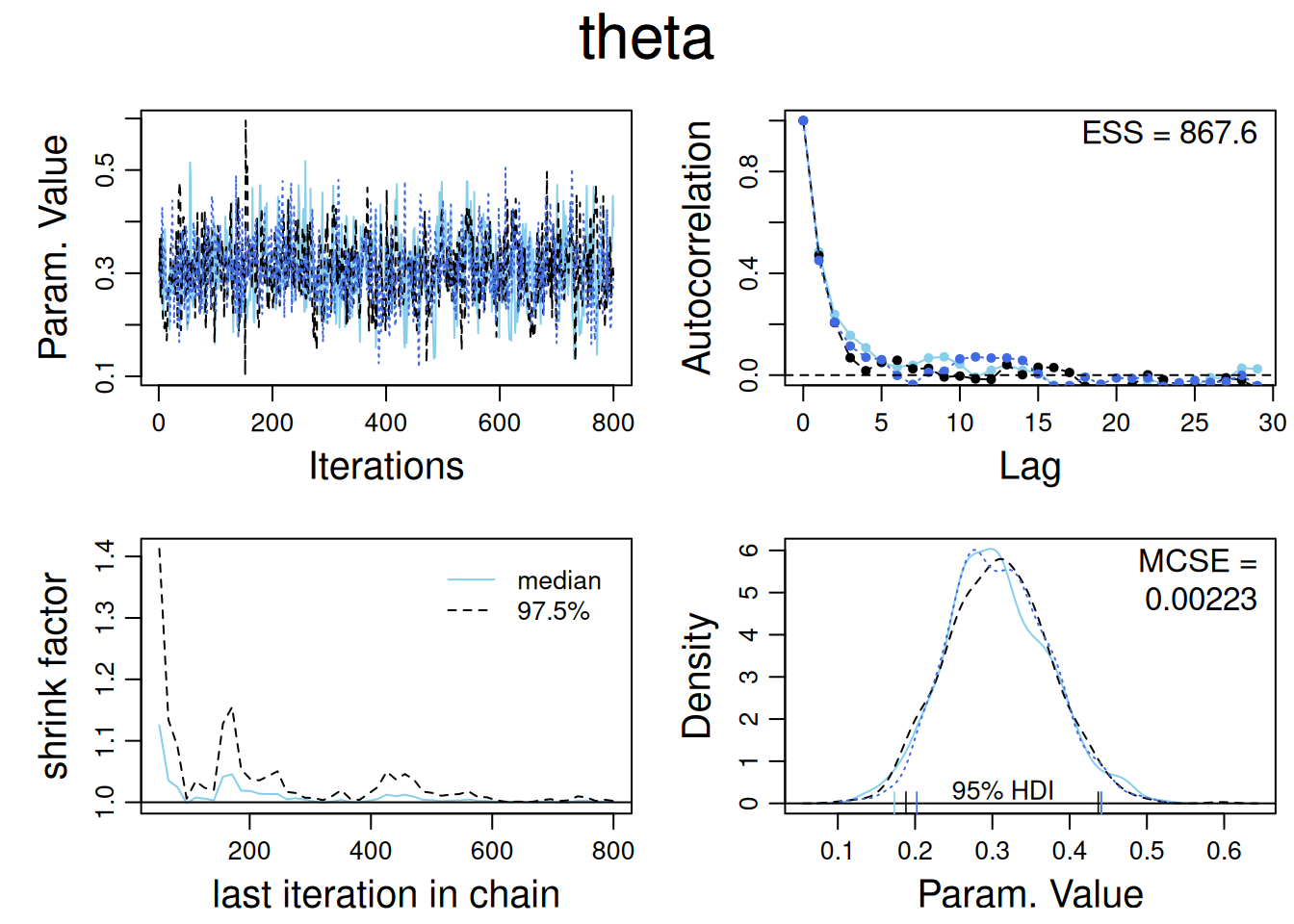
En este ejemplo estimamos la probabilidad de “cara” de una moneda, \(\theta\), a partir de una muestra de lanzamientos, usando JAGS (vía rjags) para automatizar el muestreo MCMC.
6.1.1 Carga de librerías y datos
Cargamos el paquete rjags y las utilidades de Kruschke, luego leemos un archivo CSV con los resultados (0=escudo, 1=corona):
library(rjags)
Loading required package: coda
Linked to JAGS 4.3.2
Loaded modules: basemod,bugs
source("DBDA2Eprograms/DBDA2E-utilities.R")
*********************************************************************
Kruschke, J. K. (2015). Doing Bayesian Data Analysis, Second Edition:
A Tutorial with R, JAGS, and Stan. Academic Press / Elsevier.
*********************************************************************
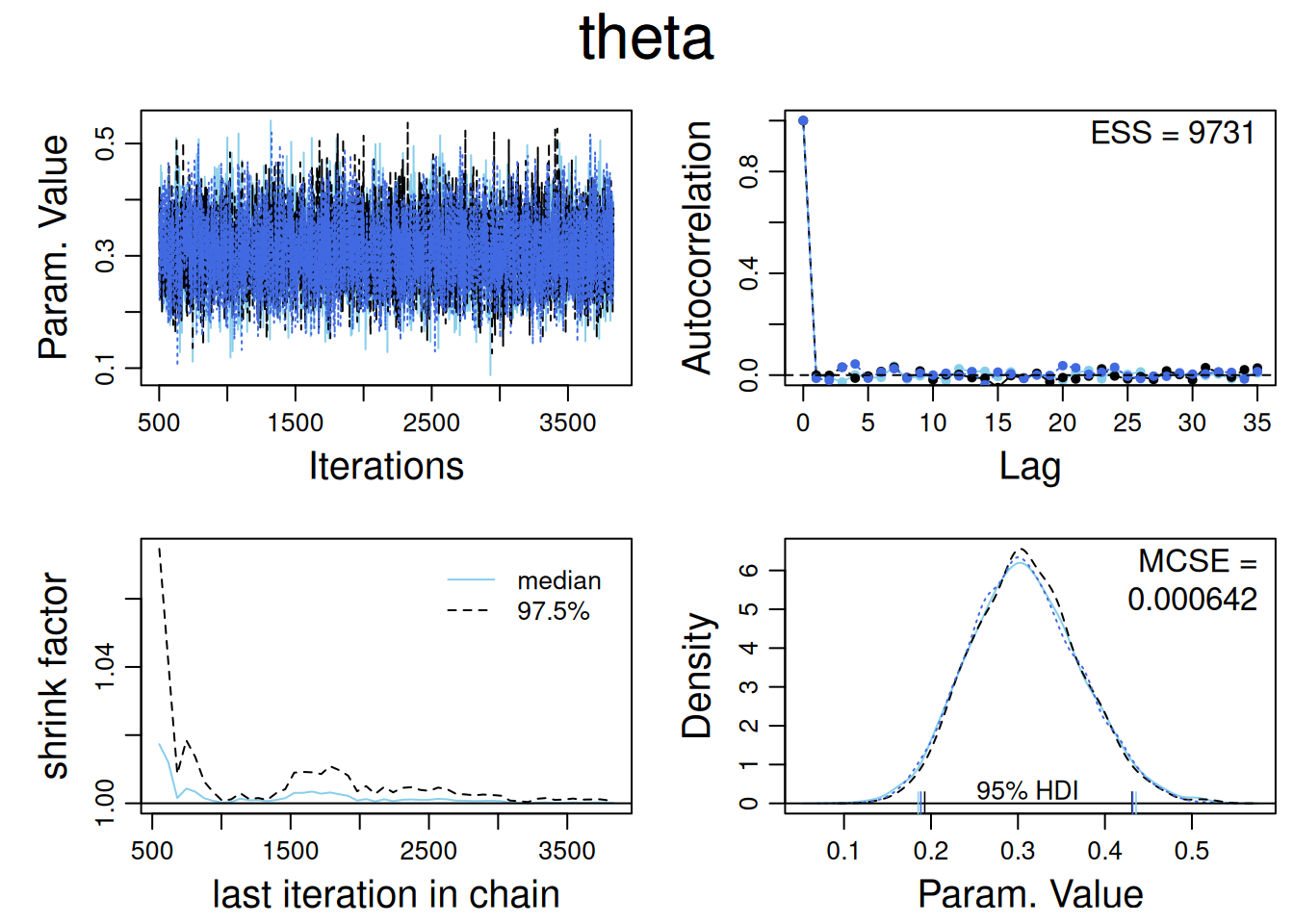
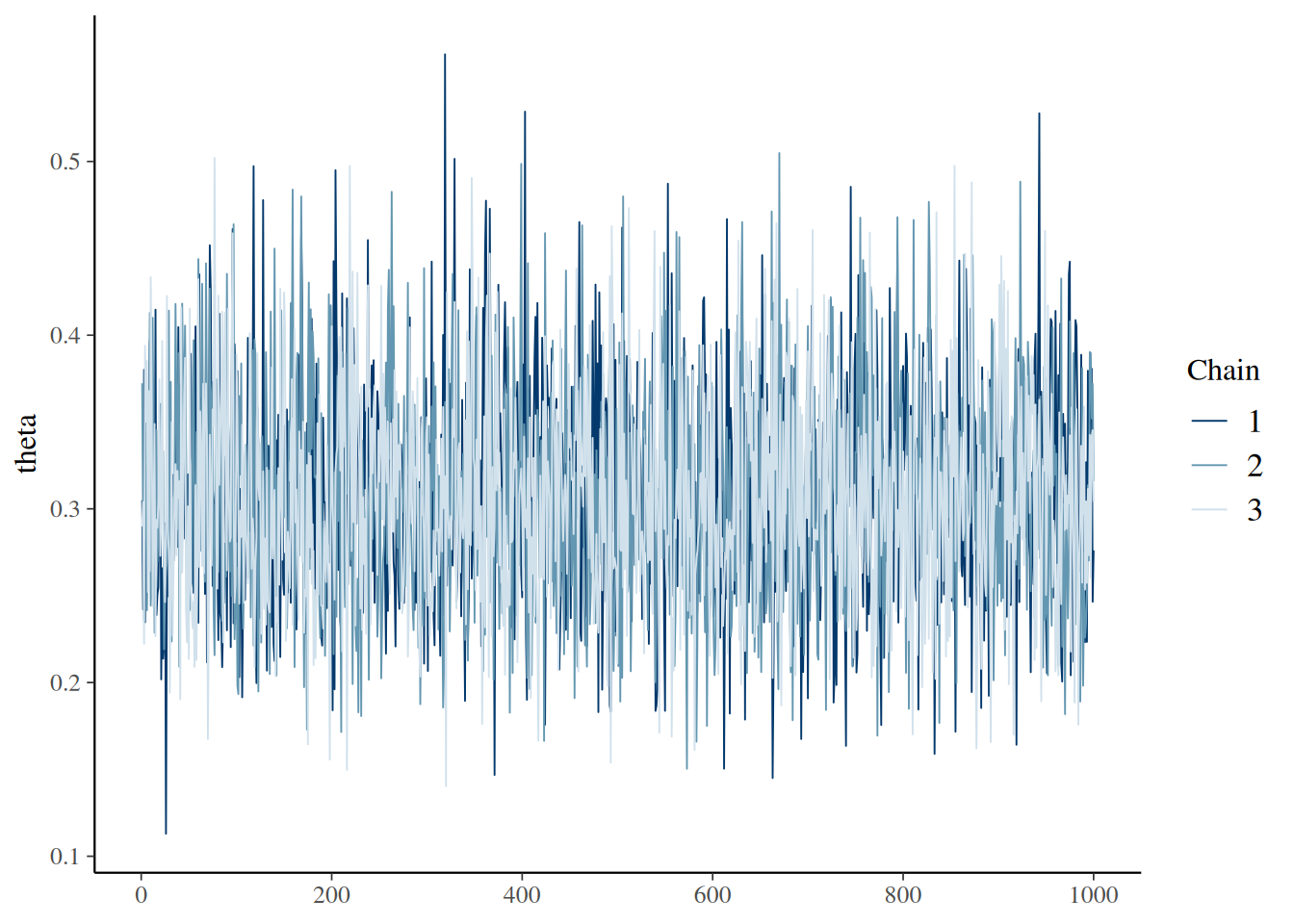
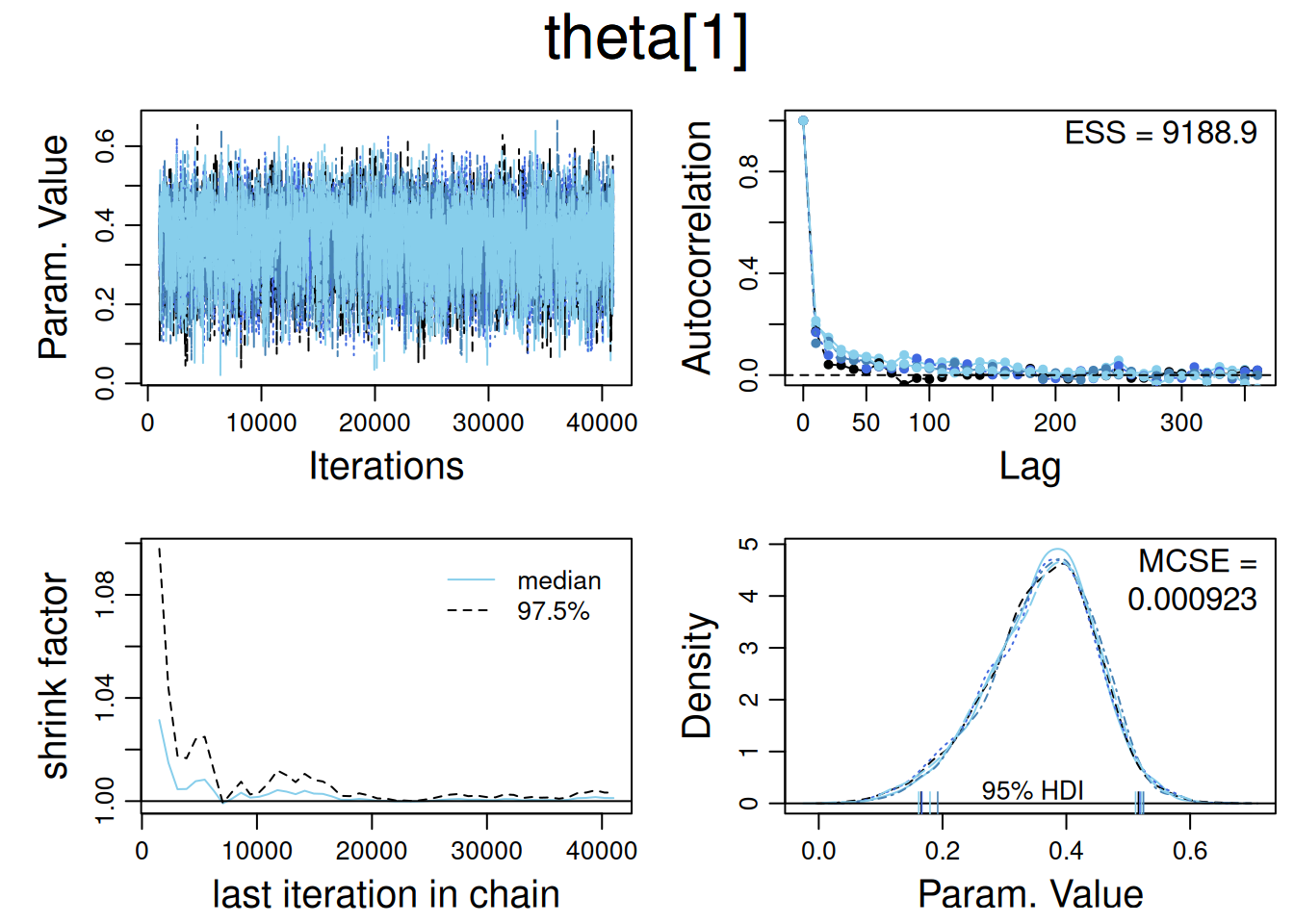
Usamos la función diagMCMC (de DBDA2E–utilities) que emplea coda:
diagMCMC(codaObject=codaSamples, parName="theta")
Aquí se trazan las trace plots, los densidades superpuestas, el Gelman–Rubin y la ACF, mostrando representatividad y un ESS cercano al total.
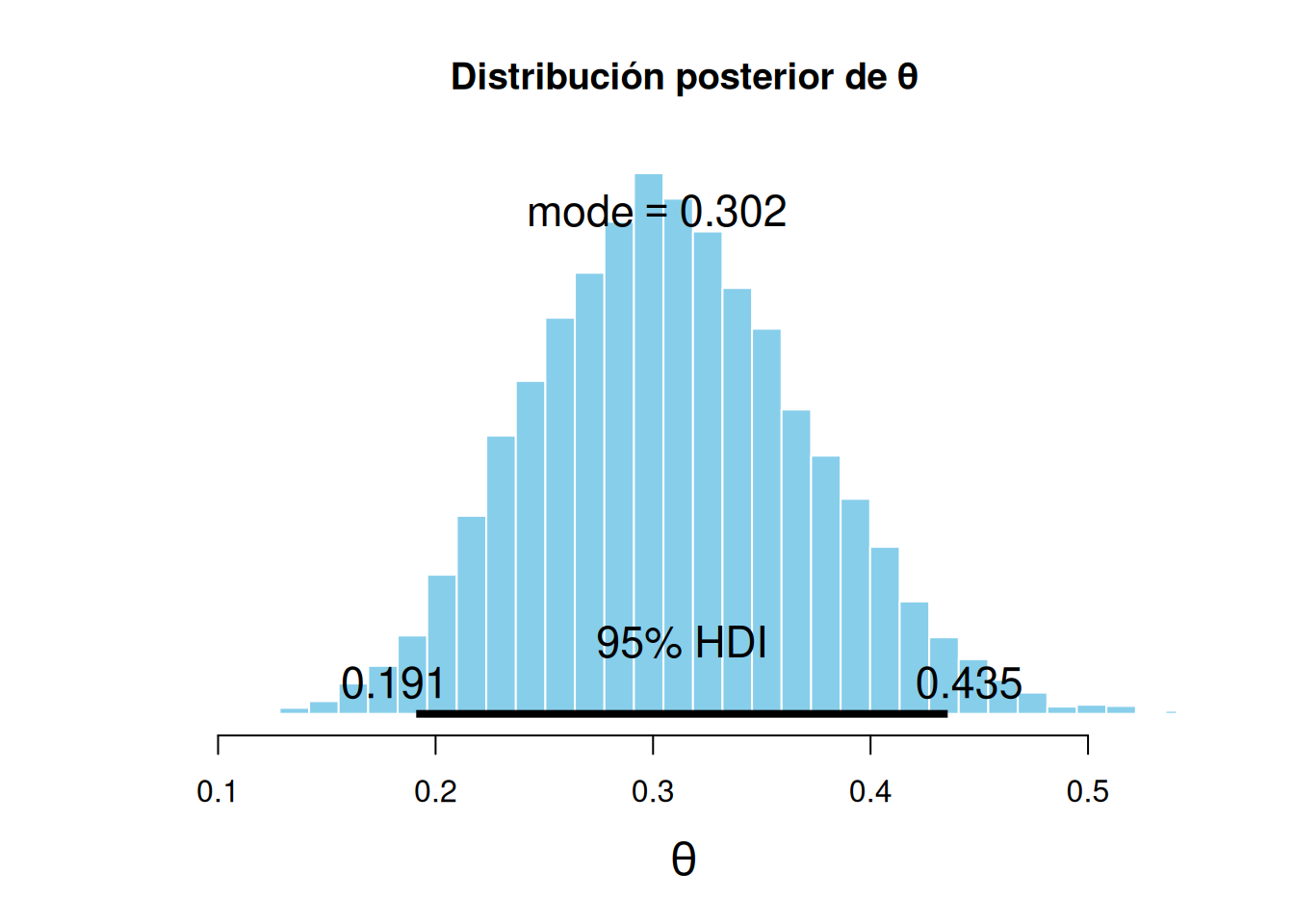
6.1.6 Visualización de la posterior
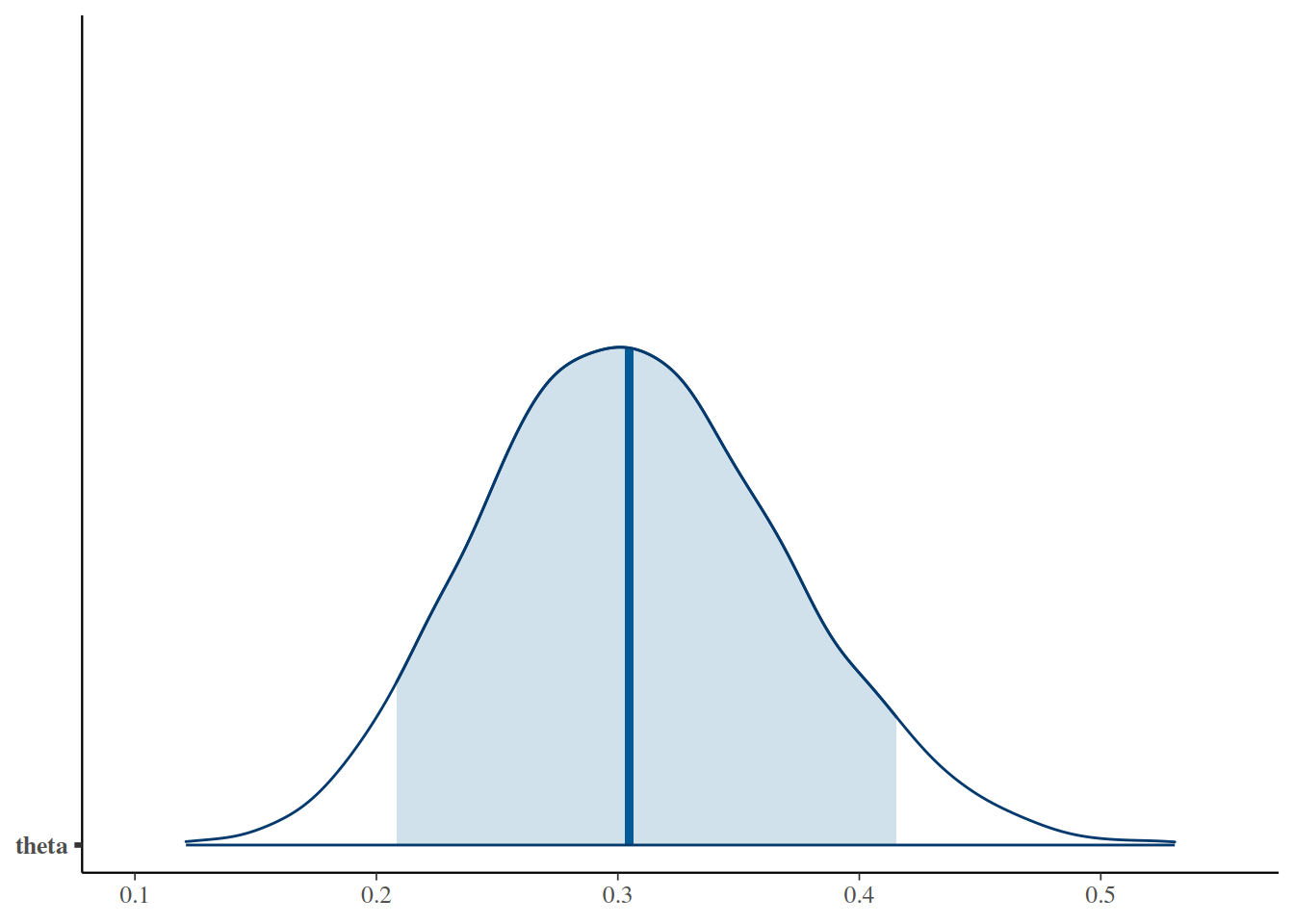
Con plotPost (DBDA2E):
plotPost(codaSamples[,"theta"],main="Distribución posterior de θ",xlab=bquote(theta))
ESS mean median mode hdiMass hdiLow hdiHigh compVal
theta 10002 0.3083362 0.3058889 0.3017988 0.95 0.1910977 0.4354811 NA
pGtCompVal ROPElow ROPEhigh pLtROPE pInROPE pGtROPE
theta NA NA NA NA NA NA
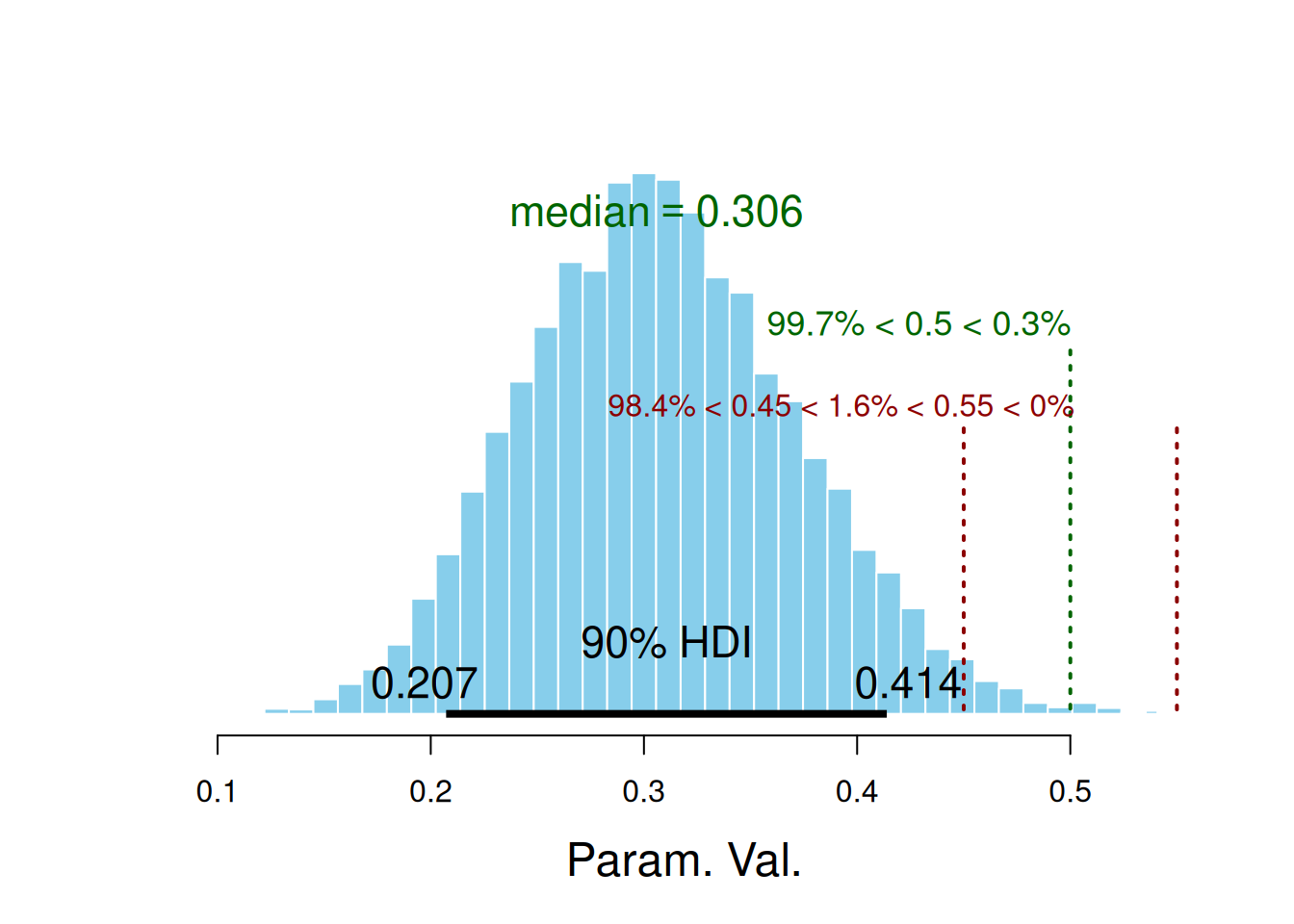
ESS mean median mode hdiMass hdiLow hdiHigh
Param. Val. 10002 0.3083362 0.3058889 0.3017988 0.9 0.2072132 0.4139092
compVal pGtCompVal ROPElow ROPEhigh pLtROPE pInROPE pGtROPE
Param. Val. 0.5 0.00289942 0.45 0.55 0.9841032 0.01589682 0
Estadísticos básicos de la posterior de \(\theta\):
summary(codaSamples)
Iterations = 501:3834
Thinning interval = 1
Number of chains = 3
Sample size per chain = 3334
1. Empirical mean and standard deviation for each variable,
plus standard error of the mean:
Mean SD Naive SE Time-series SE
0.3083362 0.0633048 0.0006330 0.0006422
2. Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
0.1922 0.2639 0.3059 0.3500 0.4378
6.1.7 Alternativa con R2jags y bayesplot
Otra forma de ajustar con R2jags:
library(R2jags)
Attaching package: 'R2jags'
The following object is masked from 'package:coda':
traceplot
Compiling model graph
Resolving undeclared variables
Allocating nodes
Graph information:
Observed stochastic nodes: 50
Unobserved stochastic nodes: 1
Total graph size: 53
Initializing model
Y variar inicializaciones:
# Todas las cadenas empiezan en theta~Beta(3,3)bern_jags3 <-jags(data =list(y = myData$y, N =nrow(myData)),model.file = bern_model,inits =function() list(theta=rbeta(1,3,3)),parameters.to.save="theta")
Compiling model graph
Resolving undeclared variables
Allocating nodes
Graph information:
Observed stochastic nodes: 50
Unobserved stochastic nodes: 1
Total graph size: 53
Initializing model
# Inicio manual de cada cadenabern_jags4 <-jags(data =list(y = myData$y, N =nrow(myData)),model.file = bern_model,inits =list(list(theta=0.5), list(theta=0.7), list(theta=0.9) ),parameters.to.save="theta")
Compiling model graph
Resolving undeclared variables
Allocating nodes
Graph information:
Observed stochastic nodes: 50
Unobserved stochastic nodes: 1
Total graph size: 53
Initializing model
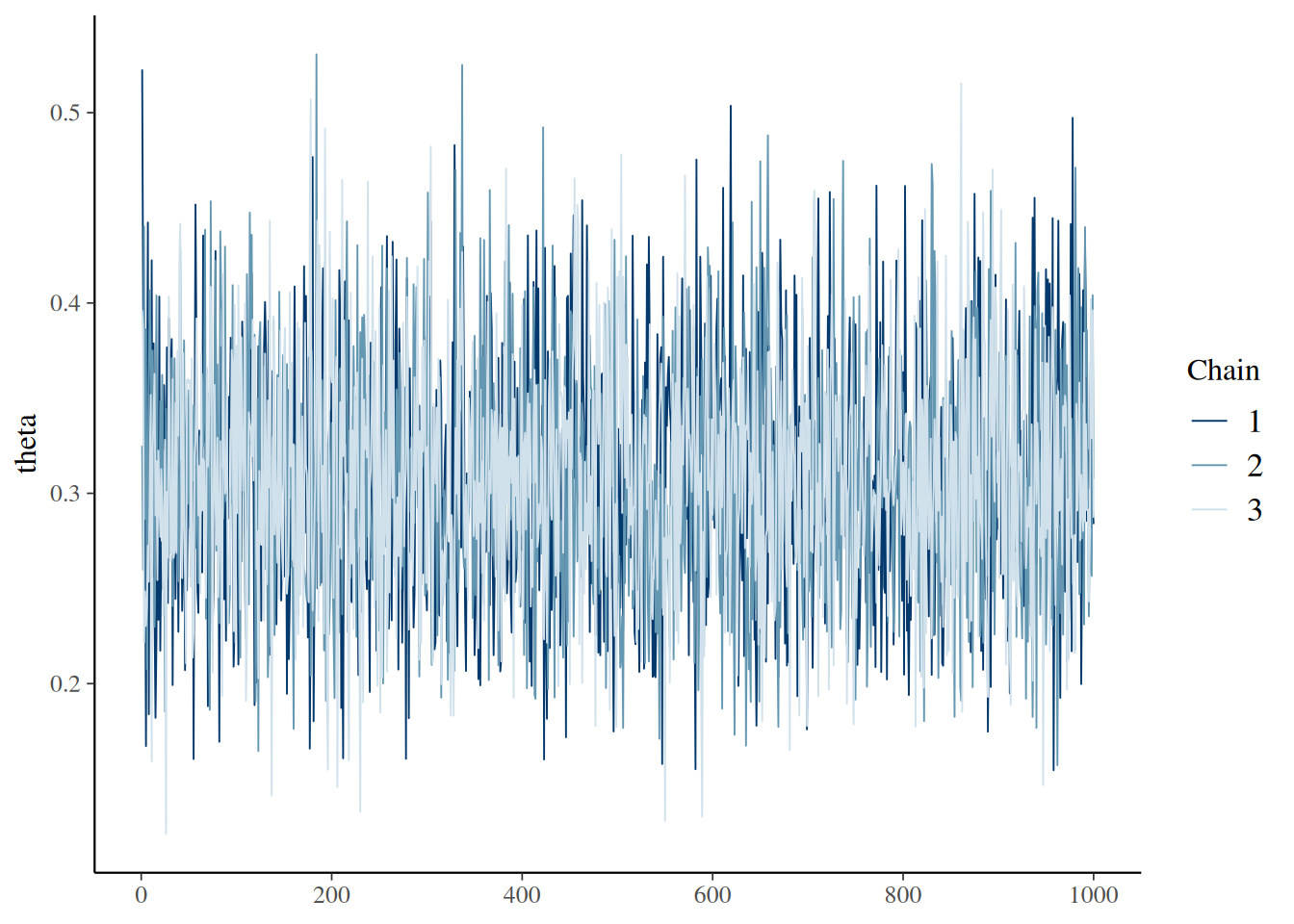
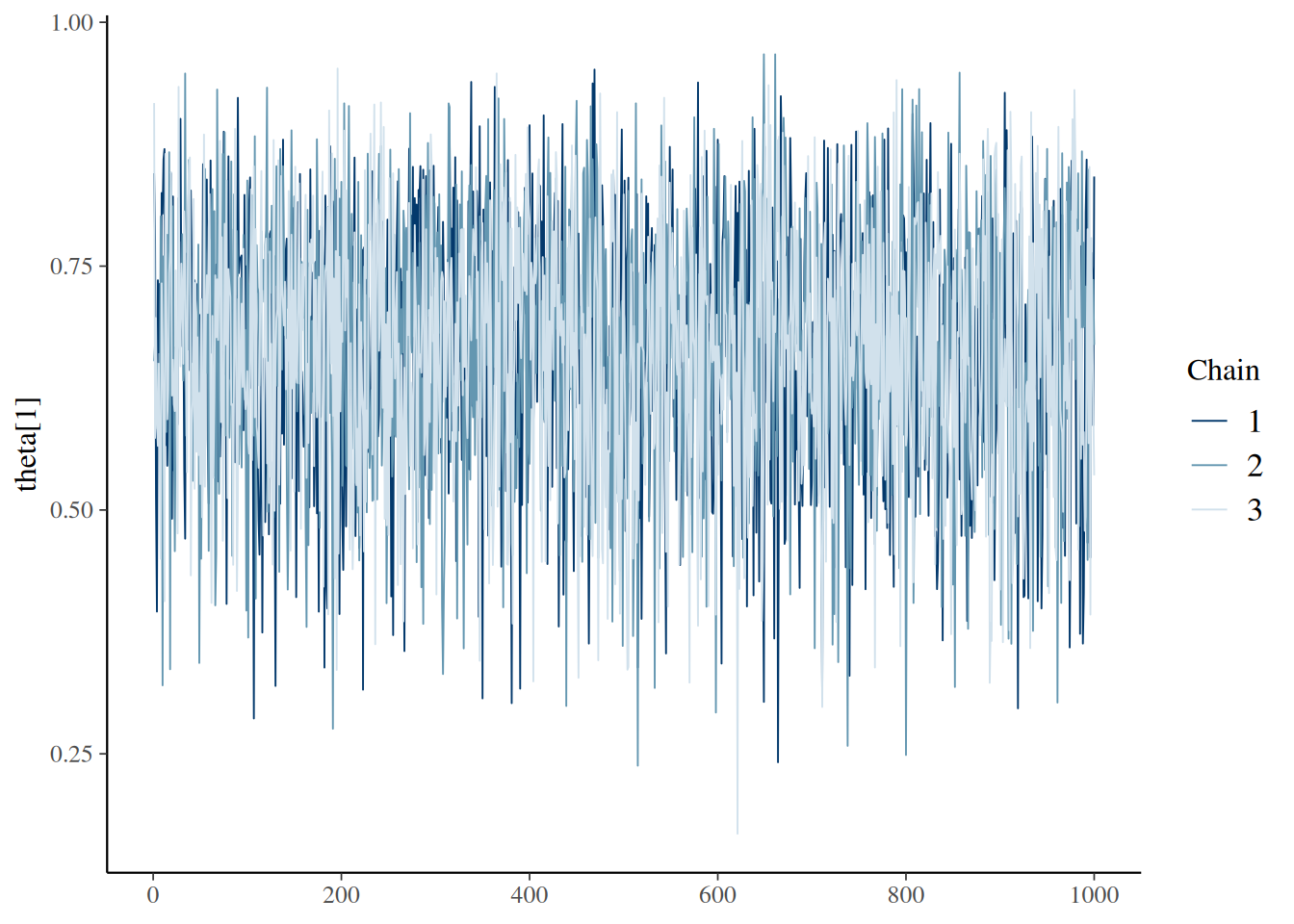
mcmc_trace(as.mcmc(bern_jags4), pars="theta")
6.2 Sesgos de dos monedas: Reginald vs. Tony
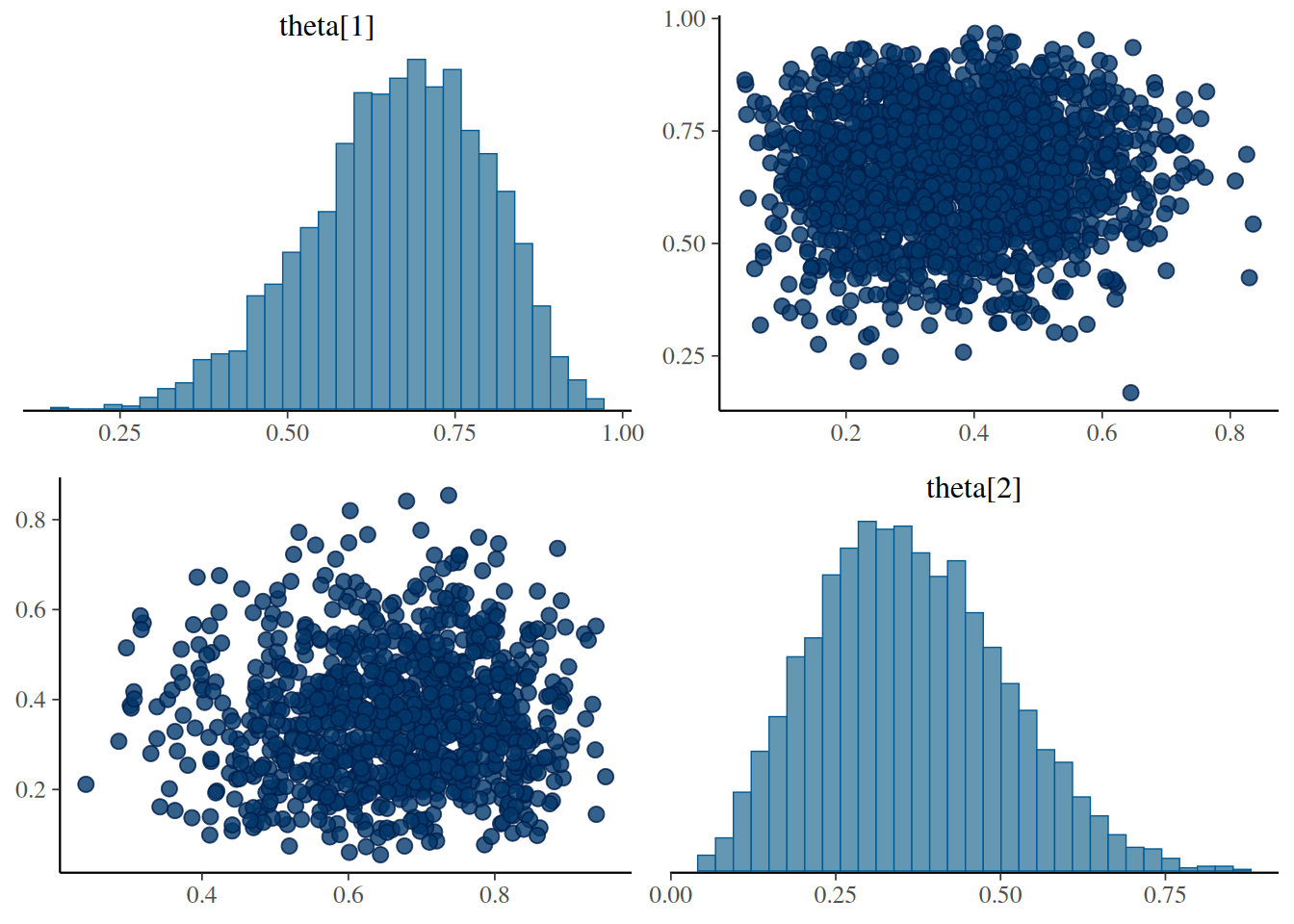
En este ejemplo estimamos los sesgos \(\theta_{1}\) y \(\theta_{2}\) de las monedas de Reginald y Tony, y analizamos su diferencia \(\theta_{1}-\theta_{2}\) para evaluar, por ejemplo, la hipótesis \(H_{0}:\theta_{1}>\theta_{2}\).
6.2.1 Carga y resumen de datos
Partimos del conjunto z6N8z2N7 que contiene en cada fila un lanzamiento:
library(mosaic)
Registered S3 method overwritten by 'mosaic':
method from
fortify.SpatialPolygonsDataFrame ggplot2
The 'mosaic' package masks several functions from core packages in order to add
additional features. The original behavior of these functions should not be affected by this.
Attaching package: 'mosaic'
The following objects are masked from 'package:dplyr':
count, do, tally
The following object is masked from 'package:Matrix':
mean
The following object is masked from 'package:ggplot2':
stat
The following objects are masked from 'package:stats':
binom.test, cor, cor.test, cov, fivenum, IQR, median, prop.test,
quantile, sd, t.test, var
The following objects are masked from 'package:base':
max, mean, min, prod, range, sample, sum
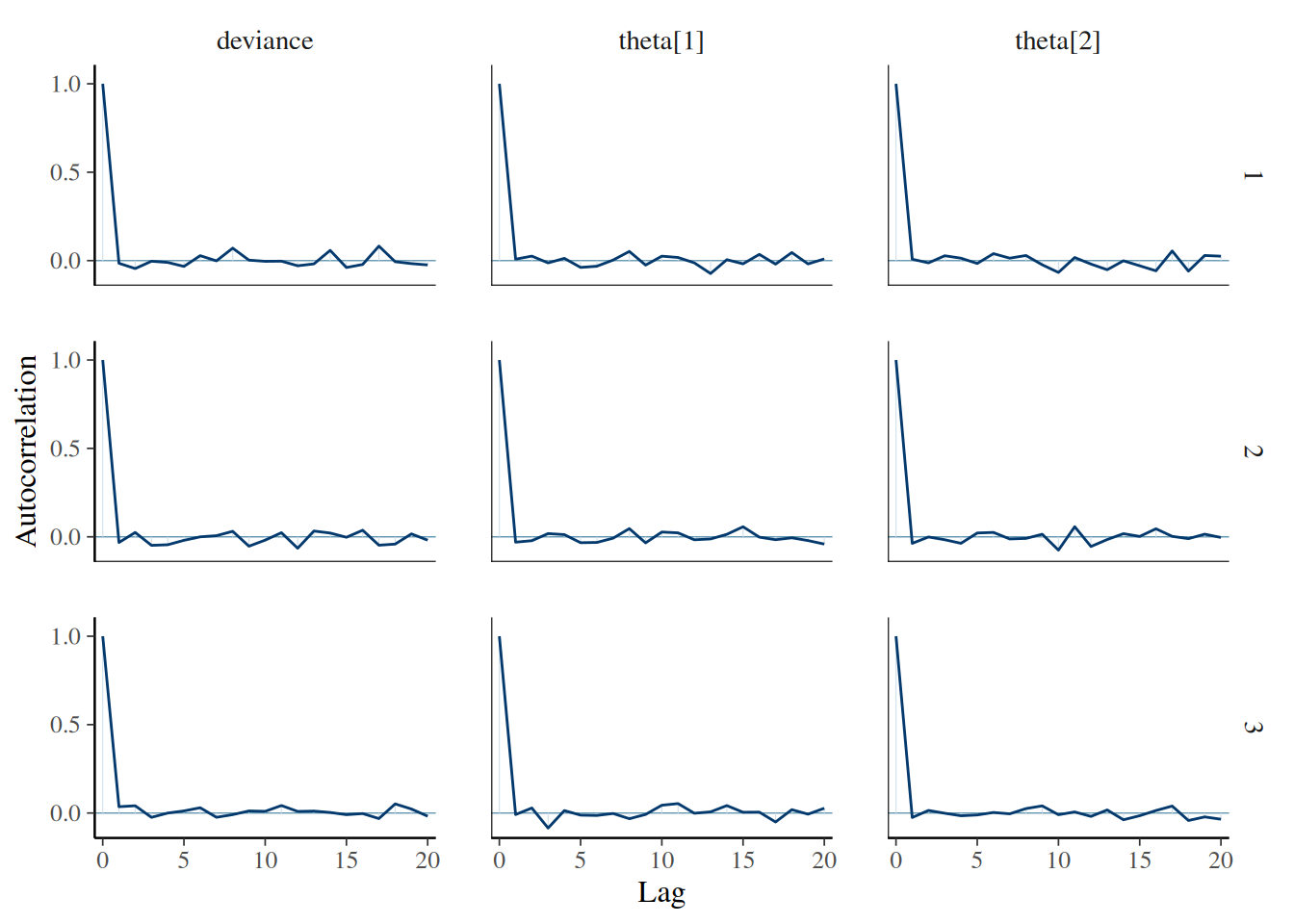
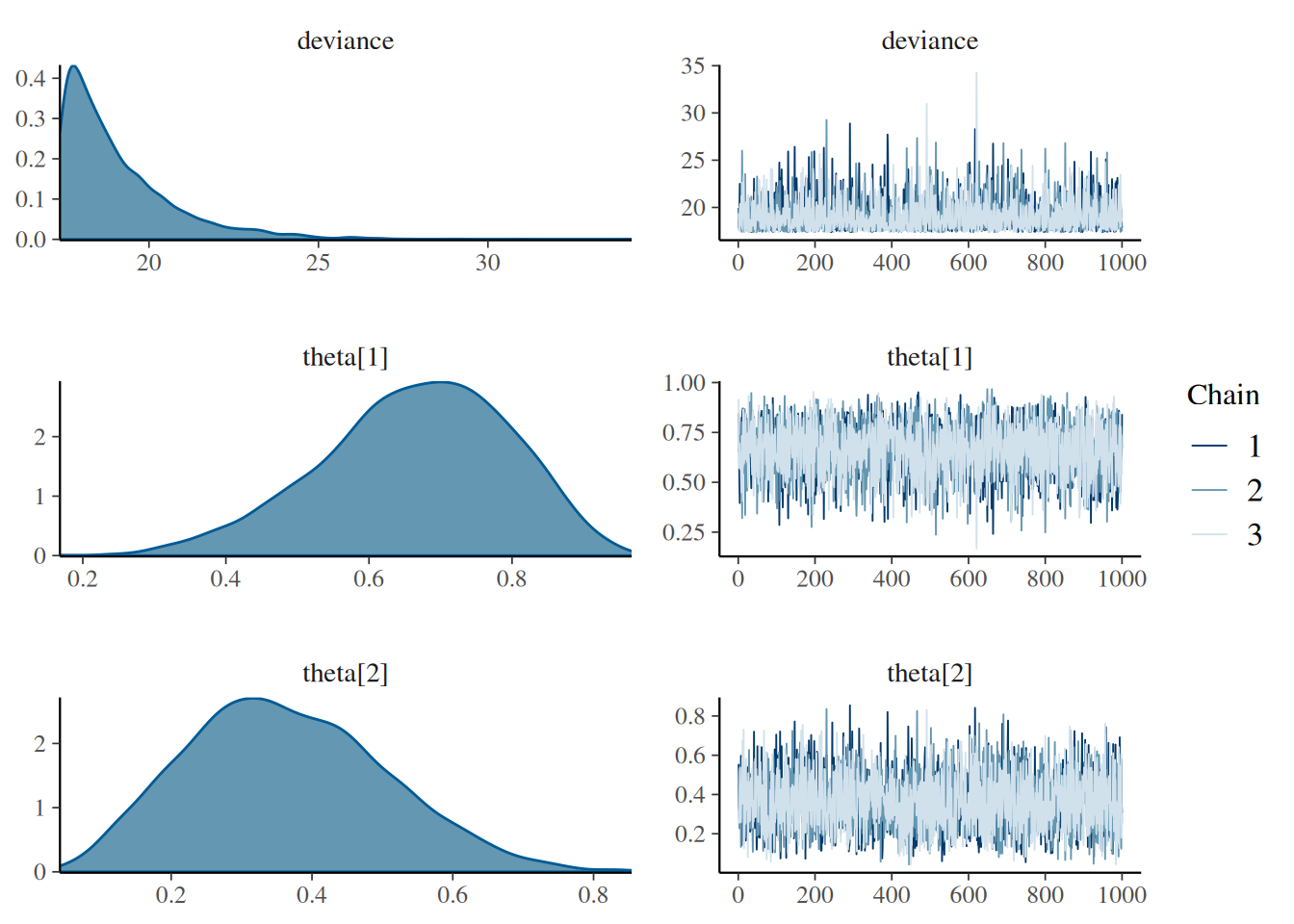
# Estadístico de Gelman–Rubingelman_res <-gelman.diag(bern2_mcmc, autoburnin=FALSE)print(gelman_res)
Potential scale reduction factors:
Point est. Upper C.I.
deviance 1 1
theta[1] 1 1
theta[2] 1 1
Multivariate psrf
1
Los diagnósticos indican buena mezcla y ESS adecuado.
6.2.5 Inferencia sobre la diferencia
Extraemos la muestra posterior y calculamos la diferencia:
# 1. Convierte el objeto jags a un objeto mcmc de codabern2_mcmc <-as.mcmc(bern2_jags)# 2. Junta las cadenas en una sola matriz de drawspost_mat <-as.matrix(bern2_mcmc)# post_mat tendrá dos columnas: "theta[1]" y "theta[2]"# 3. Calcula la diferenciadif <- post_mat[,"theta[1]"] - post_mat[,"theta[2]"]# 4. Estadísticos de interésmean(dif)
[1] 0.3011272
quantile(dif, c(0.025, 0.975))
2.5% 97.5%
-0.09405656 0.65172258
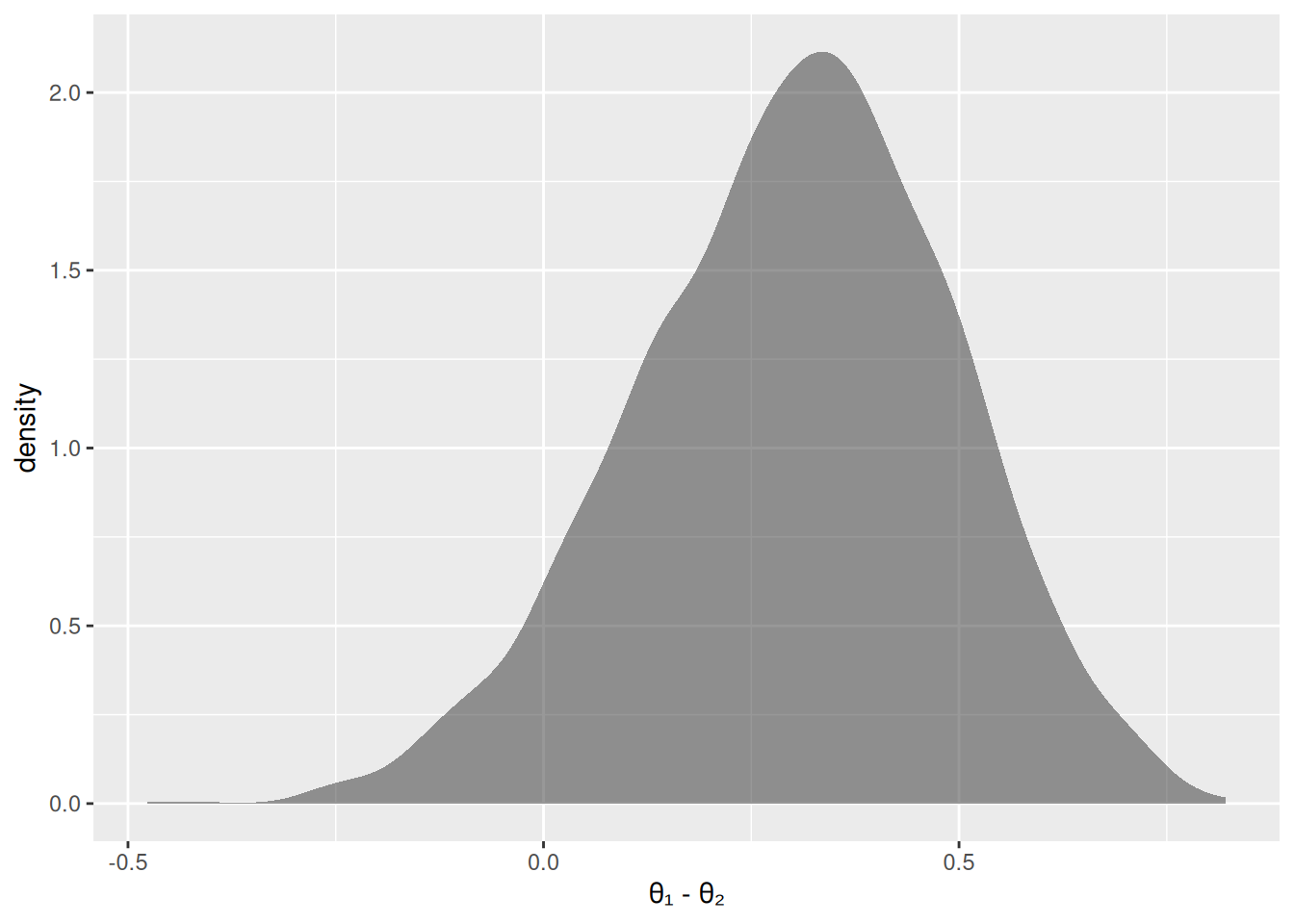
# 5. Densidad de la diferencialibrary(ggformula)gf_density(~ dif, xlab="θ₁ - θ₂",main="Distribución posterior de la diferencia")
Para estimar \(P(H_{0}:\theta_{1}>\theta_{2})\):
mean(dif >0)
[1] 0.9346667
Así, la probabilidad de \(H_0\) es 0.93 y la de \(H_1:\theta_{1}<\theta_{2}\) es 0.067, lo que sugiere que es muy plausible que Reginald tenga mayor sesgo que Tony.
6.3 Distribuciones disponibles en JAGS
JAGS ofrece de forma nativa una amplia colección de distribuciones frecuentes, como dbeta, dgamma, dnorm, dbern, dbinomial, entre otras (ver manual de usuario de JAGS para la lista completa). Estas facilitan la especificación de modelos sin tener que definir cada función de densidad desde cero.
6.3.1 Extensión mediante el “ones trick” y el “zeros trick”
Cuando se requiere una distribución no incluida en JAGS, puede emplearse el Bernoulli ones trick. La idea es usar que
\[
\mathrm{dbern}(1\mid \theta)=\theta,
\]
es decir, si queremos evaluar una función de densidad arbitraria \(pdf\bigl(y[i],|,\text{parámetros}\bigr)\), la definimos como
spy[i] <- pdf(y[i], parámetros) / C
y luego forzamos a JAGS a “evaluar” ese valor con
ones[i] ~ dbern(spy[i])
Aquí, ones[i] es un vector de unos definido en el bloque data y \(C\) es una constante grande que asegura que \(0\le \text{spy}[i]\le1\). Dado que sólo importan las razones de densidades en MCMC, el factor de escala \(1/C\) no altera los resultados.
Análogamente, el Poisson zeros trick utiliza el hecho de que
\[
\mathrm{dpois}(0\mid \lambda)=e^{-\lambda},
\]
de modo que, definiendo
theta[i] <- pdf(y[i], parámetros) + K
0 ~ dpois(-log(theta[i]))
con \(K\) suficientemente grande para mantener positivo el argumento de la Poisson, obtenemos la misma contribución al logaritmo de la densidad.
6.3.2 Extensión a nuevas distribuciones
Para evitar estos trucos, es posible extender JAGS con distribuciones propias mediante la creación de módulos en C++ (vía runjags o la guía de Wabersich & Vandekerckhove), lo que permite declarar directamente en el modelo:
y[i] ~ dMiDistrib( parámetros )
sin recurrir a aproximaciones via dbern o dpois. Esta vía requiere programar la función de densidad y su derivada en un módulo compilado, pero ofrece máxima flexibilidad para modelos a medida.
6.4 Introducción a la modelación jerárquica
Para recordar el escenario básico, consideremos primero el modelo no jerárquico para el sesgo de una moneda. Sea \(y_{i}\) el resultado de cada lanzamiento (0/1) que sigue una distribución de Bernoulli con parámetro \(\theta\):
\[
y_{i} \sim \operatorname{dbern}(\theta).
\]
El parámetro \(\theta\) tiene como priori una distribución beta con parámetros \((a,b)\):
\[
\theta \sim \operatorname{dbeta}(a,b).
\]
Estos parámetros \((a,b)\) pueden reexpresarse en términos de la moda\(\omega\) y la concentración\(\kappa\) de la beta. En concreto,
\(\omega = \displaystyle\frac{a - 1}{a + b - 2}\) es la moda,
\(\kappa = a + b\) es la concentración total,
y, recíprocamente,
\[
a \;=\;\omega\,(\kappa - 2) + 1,\qquad
b \;=\;(1-\omega)\,(\kappa - 2) + 1.
\]
Con esa reparametrización, la priori en \(\theta\) queda como
Aquí, \(\omega\) indica la ubicación típica de \(\theta\) (p. ej., si \(\omega=0.25\), entonces \(\theta\) tenderá a situarse alrededor de 0.25), mientras que \(\kappa\) gobierna cuán concentrados están los valores de \(\theta\) alrededor de \(\omega\). Cuanto mayor es \(\kappa\), más cerca de \(\omega\) quedarán las muestras de \(\theta\). Por simplicidad, en este ejemplo tomamos \(\kappa\) como un valor fijo y lo llamamos \(K\).
6.4.1 Extensión a modelo jerárquico: estimar la moda \(\omega\)
Para introducir la jerarquía, ya no consideramos \(\omega\) como conocimiento previo fijo, sino como un parámetro a inferir. La idea es suponer que una “casa” (mint) fabrica monedas cuyo sesgo \(\theta\) se distribuye alrededor de un valor típico \(\omega\), con dispersión controlada por \(K\). Si \(K\) es grande, la casa produce monedas muy homogéneas (todas con \(\theta\approx\omega\)); si \(K\) es pequeño, las monedas saldrán más dispersas. Así, cuando extraemos una moneda al azar, los datos de sus lanzamientos nos informan ambas cosas:
El sesgo particular de esa moneda, \(\theta\) (cercano a la proporción de caras observadas).
La moda subyacente de la casa, \(\omega\), que refleja el sesgo más probable de las monedas en general.
Para ese segundo nivel, asignamos a \(\omega\) una priori que también sea beta, con parámetros \((A_\omega,B_\omega)\):
De ese modo, creemos a priori que \(\omega\) queda cerca de \(\displaystyle\frac{A_\omega - 1}{A_\omega + B_\omega - 2}\), con la concentración (certeza) dada por \(A_\omega + B_\omega\).
6.4.2 Estructura jerárquica y regla de Bayes conjunta
La jerarquía de dependencias queda así resumida:
Primero, \(\omega\) se elige según \(\operatorname{dbeta}(A_\omega,B_\omega)\).
Luego, dado \(\omega\), el sesgo de la moneda \(\theta\) se extrae de \(\theta \sim \operatorname{dbeta}\bigl(\omega(\!K-2\!) +1,\;(1-\omega)(\!K-2\!) +1\bigr).\)
Finalmente, cada observación \(y_i\) (0 = cruz, 1 = cara) viene de \(y_i \sim \operatorname{dbern}(\theta).\)
En notación de probabilidad conjunta, la distribución a posteriori de \((\theta,\omega)\), tras observar los datos \(\gamma={y_i}\), es
Aquí, \(p(\gamma\mid\theta)\) es la verosimilitud binomial/Bernoulli según los datos de la moneda,
\(p(\theta\mid\omega)\) es la beta definida mediante modo \(\omega\) y concentración \(K\),
\(p(\omega)\) es la beta \((A_\omega,B_\omega)\).
6.4.3 Ejemplo de Modelación Jerárquica (sección 9.2.4, Kruschke)
Contexto: El Toque Terapéutico (TT) es una práctica de enfermería que se dice trata condiciones médicas manipulando un “campo de energía humano” con las manos de los practicantes (ver explicación). Rosa et al. (1998) evaluaron la afirmación de que los practicantes de “toque terapéutico” pueden percibir el “campo energético” de un paciente, incluso sin contacto visual. Para ello, cada practicante extendía ambas manos tras una pantalla que le impedía ver al experimentador. En cada uno de 10 ensayos, un asistente (un niño de 9 años) lanzaba una moneda y colocaba su mano unos centímetros por encima de una de las manos del practicante, según el resultado. El practicante debía adivinar cuál de sus manos estaba siendo “energéticamente” detectada. Cada intento se calificaba como acierto o error. Participaron 21 practicantes; siete de ellos fueron evaluados de nuevo un año después, siendo considerados por los autores como sujetos independientes, para un total nominal de 28 sujetos. La capacidad de los practicantes para identificar correctamente la posición de la mano del investigador se comparó con una tasa de éxito del 50% esperada por casualidad.
Pregunta de Investigación: ¿Las tasas de acierto para los practicantes será mayor al 50%?
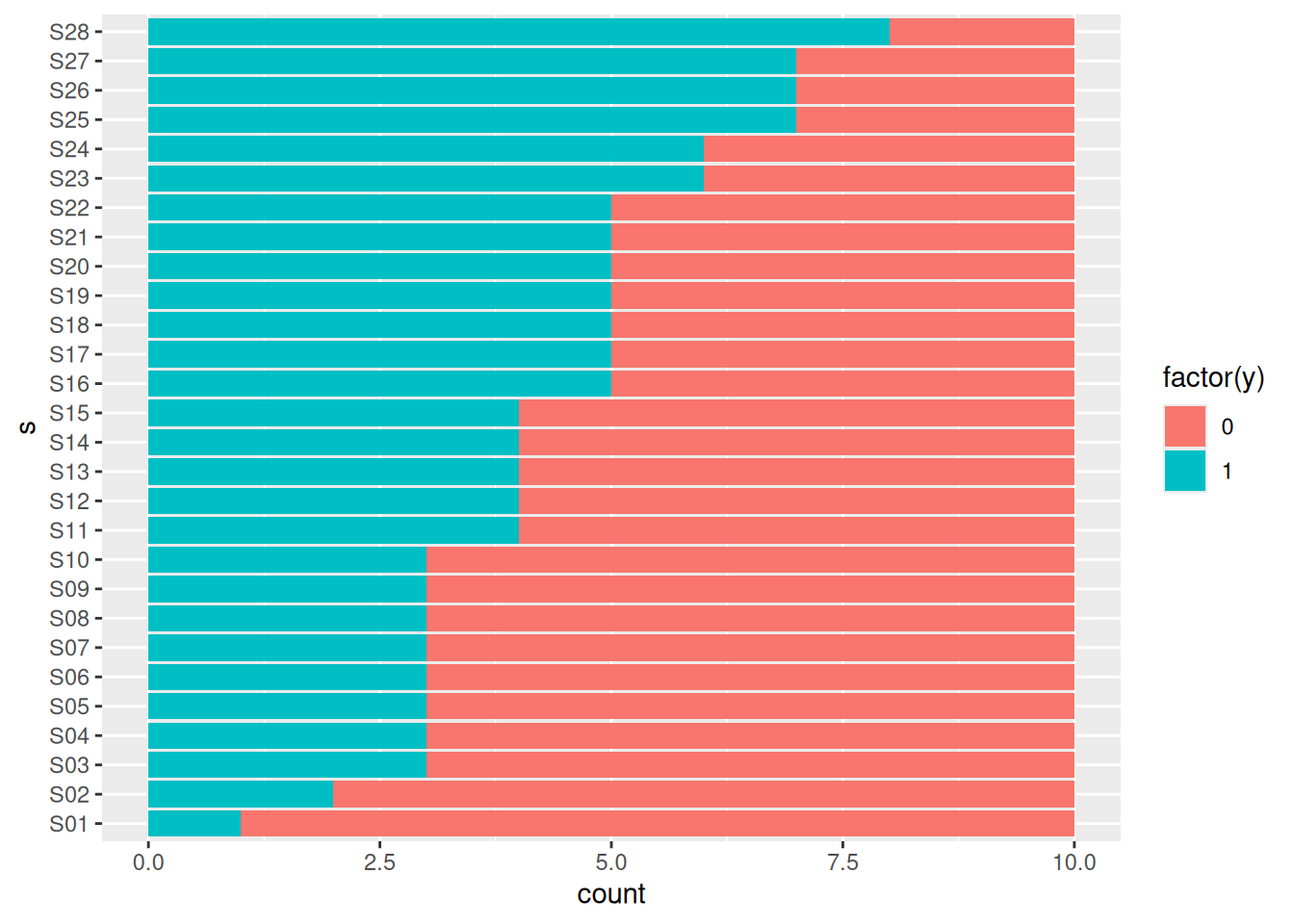
Las tasas de acierto empíricas para cada individuo se pueden visualizar de la siguiente forma:
gf_bar(s ~ ., data = TherapeuticTouch, fill =~factor(y))
de donde es interesante observar la diferencia entre tasas de acierto entre individuos (que en este caso está ordenado del que tiene menos al que tiene más acierto). Es por esto que un modelo con tasa de acierto variable por individuos tendría sentido.
En este caso usamos un modelo jerárquico que tendría la forma:
donde esta última escogencia se hiperparámetros se basa en la aplicación de la siguiente función, que está en el paquete de github CalvinBayes (https://github.com/CalvinData/CalvinBayes). Nota: este paquete permite hacer los mismos gráficos de diagnósticos con el objeto obtenido en R2jags:
library(CalvinBayes)
Attaching package: 'CalvinBayes'
The following objects are masked _by_ '.GlobalEnv':
DbdaAcfPlot, DbdaDensPlot, diagMCMC, diagStanFit, HDIofGrid,
HDIofICDF, HDIofMCMC, plotPost, summarizePost, TherapeuticTouch,
z6N8z2N7
The following object is masked from 'package:bayesplot':
rhat
The following object is masked from 'package:datasets':
HairEyeColor
gamma_params(mean =1, sd =10)
# A tibble: 1 × 6
shape rate scale mode mean sd
<dbl> <dbl> <dbl> <lgl> <dbl> <dbl>
1 0.01 0.01 100 NA 1 10
que garantiza una v.a. Gamma con media 1 y desviación estándar 10 (previas no-informativas).
Ajustamos el modelo con un número de mayor de cadenas, con mayor tamaño de muestra posterior y con thinning. Noten que ejecutamos el modelo paralelizando el proceso (1 core por cadena)
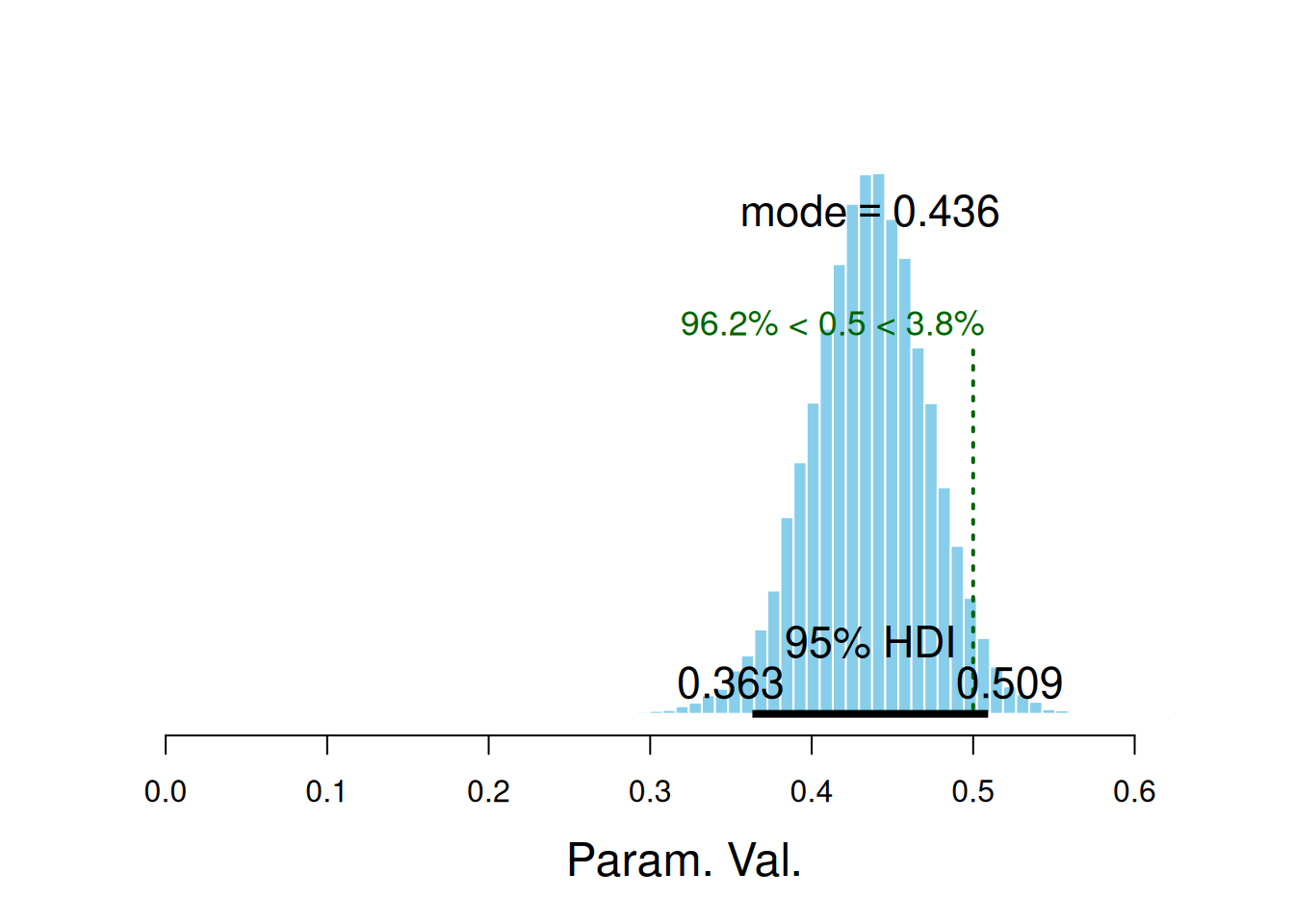
$posterior
ESS mean median mode
var1 12352.91 0.4355177 0.436148 0.4362388
$hdi
prob lo hi
1 0.95 0.3632788 0.5092646
$comparison
value P(< comp. val.) P(> comp. val.)
1 0.5 0.962 0.038
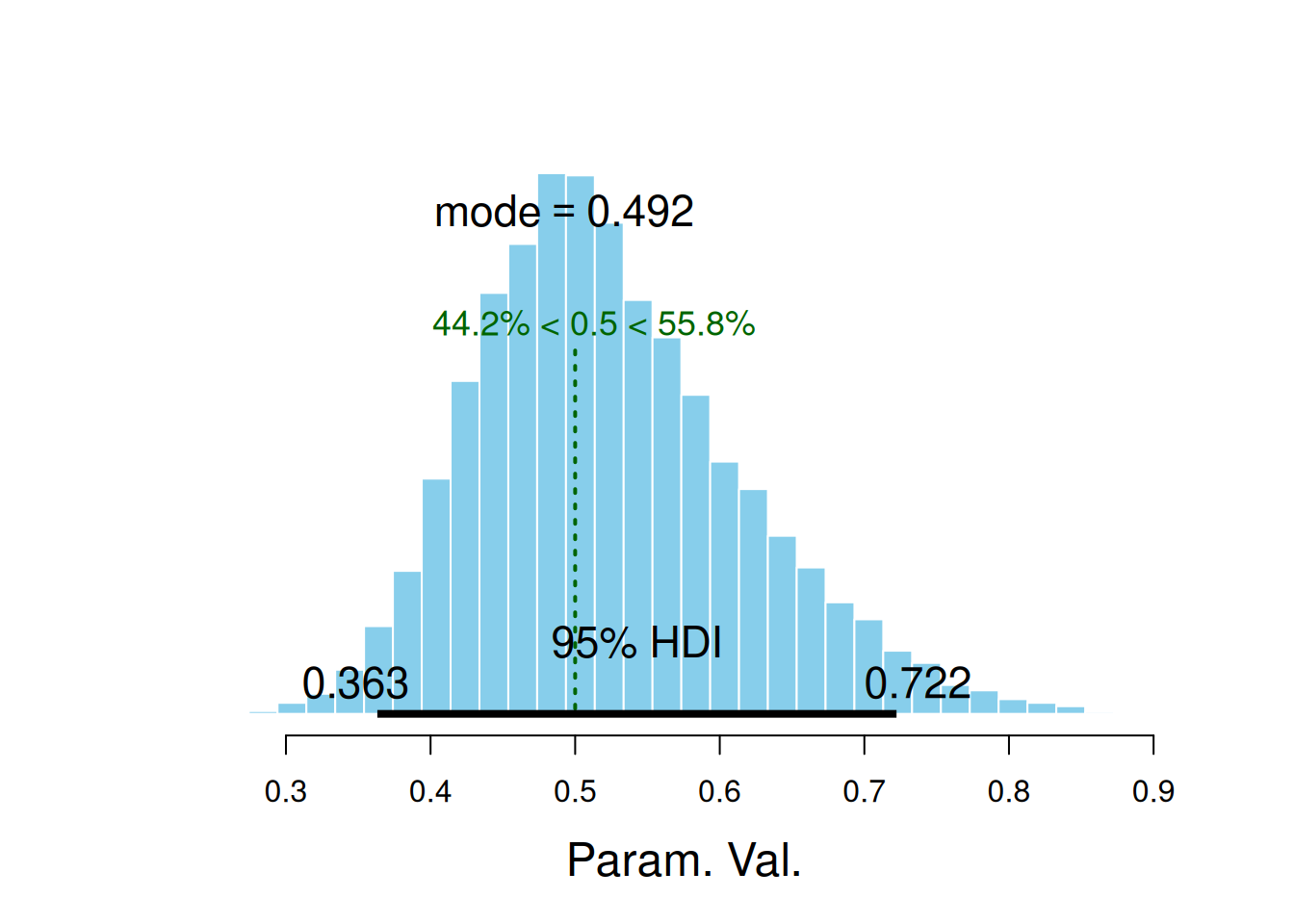
De donde se concluye que el 96% de la población de practicantes no tienen una tasa de acierto general mayor al 50%. Este análisis se puede realizar para la tasa de acierto del sujeto #28:
$posterior
ESS mean median mode
var1 7157.362 0.52434 0.5128259 0.4924208
$hdi
prob lo hi
1 0.95 0.363208 0.7222406
$comparison
value P(< comp. val.) P(> comp. val.)
1 0.5 0.44185 0.55815
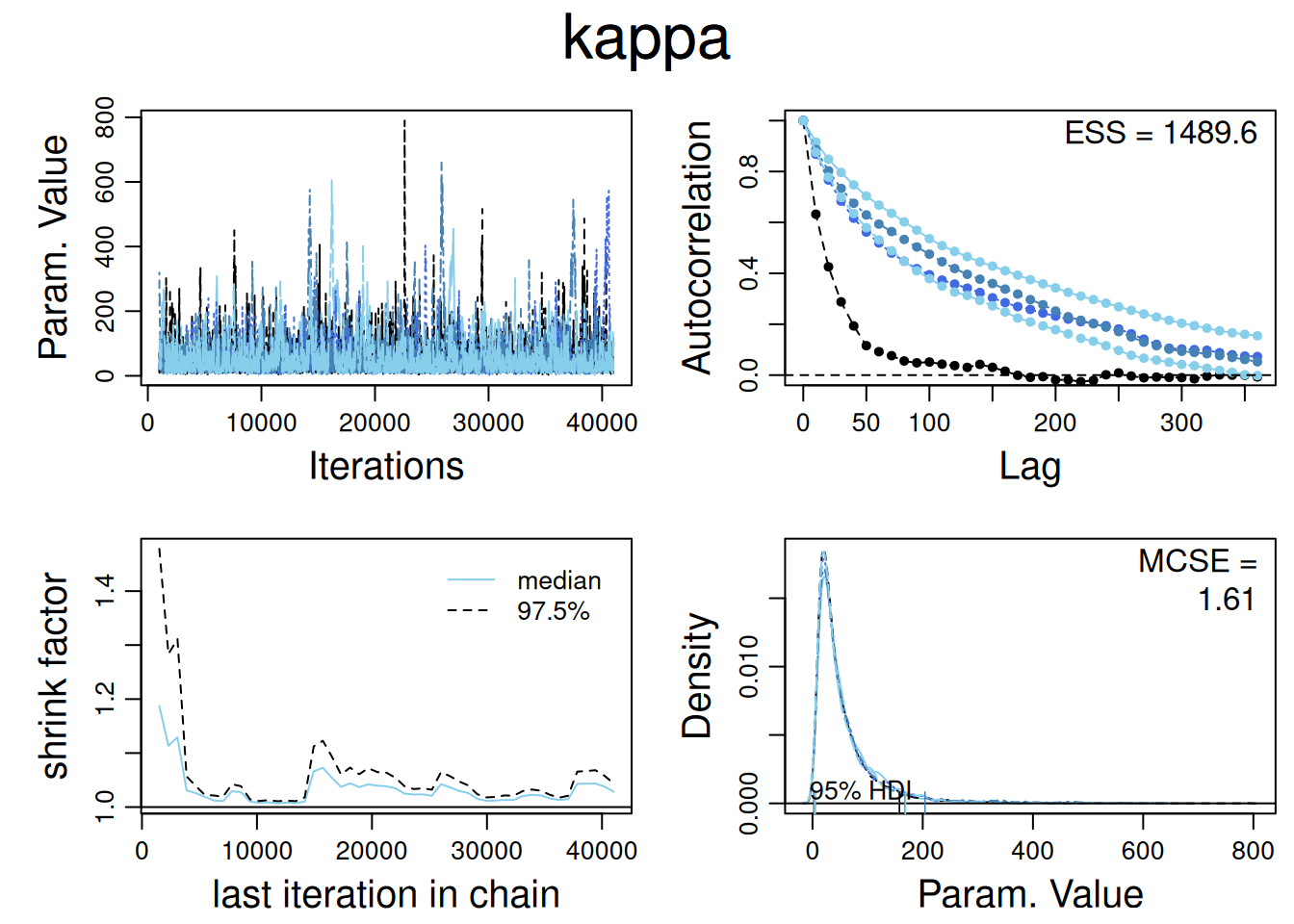
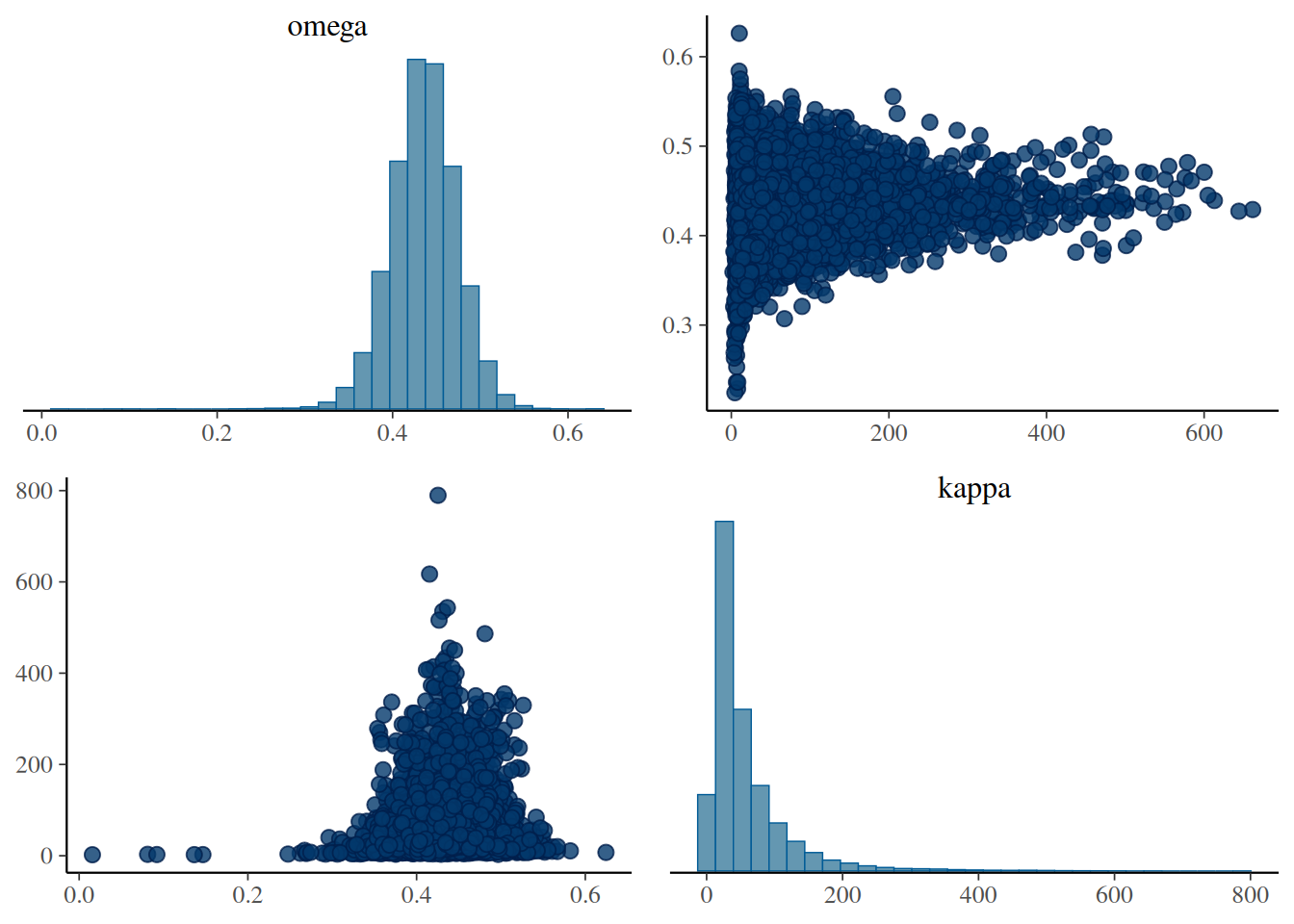
Diagnósticos del parámetro de precisión de la tasa de acierto individual:
diag_mcmc(touch_mcmc, par ="kappa")
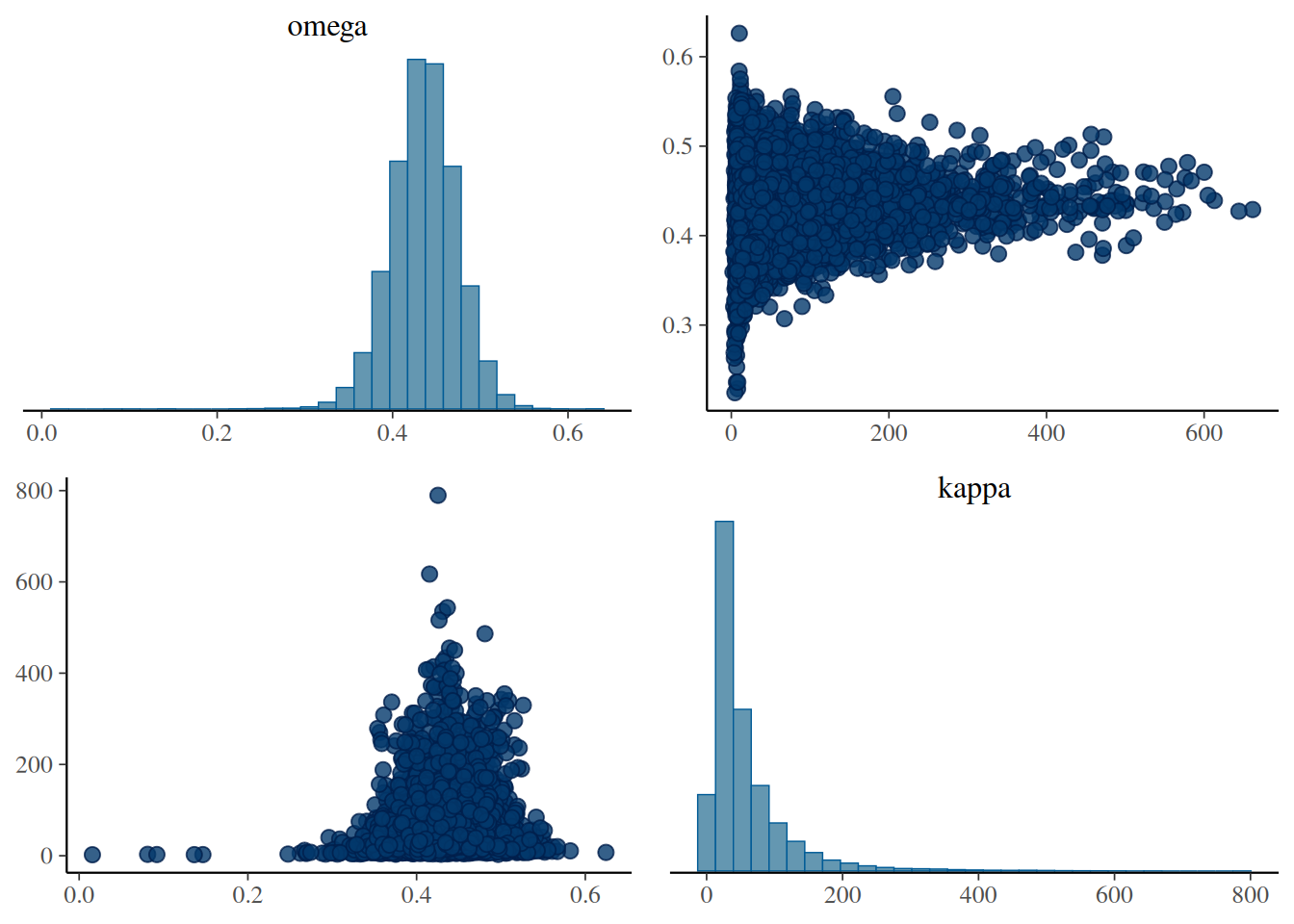
Gráfico de dispersión entre las muestras posteriores de \(K\) y \(\omega\):
mcmc_pairs(touch_mcmc, pars =c("omega", "kappa"))
Muestreo a partir de la previa:
TouchData_pre <-list(Ntotal =0,Nsubj =length(unique(TherapeuticTouch$s)),# must convert subjects to sequence 1:Nsubjs =as.numeric(factor(TherapeuticTouch$s)))touch_jags_pre <-jags.parallel(data = TouchData_pre,model = touch_model,parameters.to.save =c("theta", "kappa", "omega"),n.burnin =1000,n.iter =41000,n.chains =5,n.thin =10,jags.seed =54321,DIC = F )
Diagnósticos:
diag_mcmc(touch_mcmc, par ="theta[1]")
mcmc_pairs(touch_mcmc, pars =c("omega", "kappa"))
6.5 Introducción a STAN
Carga de librería:
library(rstan)rstan_options(auto_write =TRUE)
Para ilustrar el uso de STAN, se va a ajustar un modelo Bernoulli a datos sintéticos. El modelo está definido en el archivo moneda.stan en el repositorio de estas notas.
TRANSLATING MODEL '' FROM Stan CODE TO C++ CODE NOW.
modelo_moneda
S4 class stanmodel 'anon_model' coded as follows:
//
// This Stan program defines a simple model, with a
// vector of values 'y' modeled as normally distributed
// with mean 'mu' and standard deviation 'sigma'.
//
// Learn more about model development with Stan at:
//
// http://mc-stan.org/users/interfaces/rstan.html
// https://github.com/stan-dev/rstan/wiki/RStan-Getting-Started
//
// The input data is a vector 'y' of length 'N'.
data {
int<lower=0> N; // N is a non-negative integer
int y[N]; // y is a length-N vector of integers
}
// The parameters accepted by the model. Our model
// accepts two parameters 'mu' and 'sigma'.
parameters {
real<lower=0,upper=1> theta; // theta is between 0 and 1
}
// The model to be estimated. We model the output
// 'y' to be normally distributed with mean 'mu'
// and standard deviation 'sigma'.
model {
theta ~ beta (1,1);
y ~ bernoulli(theta);
}
Ajuste del modelo en condiciones similares a las que JAGS trabaja por default:
simple_stanfit <-sampling( modelo_moneda, data =list(N =50,y =c(rep(1, 15), rep(0, 35)) ),chains =3, # default is 4iter =1000, # default is 2000warmup =200# default is half of iter )
Inference for Stan model: anon_model.
3 chains, each with iter=1000; warmup=200; thin=1;
post-warmup draws per chain=800, total post-warmup draws=2400.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
theta 0.31 0.00 0.07 0.19 0.26 0.31 0.35 0.44 742 1
lp__ -32.64 0.03 0.80 -34.90 -32.79 -32.34 -32.16 -32.10 949 1
Samples were drawn using NUTS(diag_e) at Tue Jun 24 22:33:10 2025.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
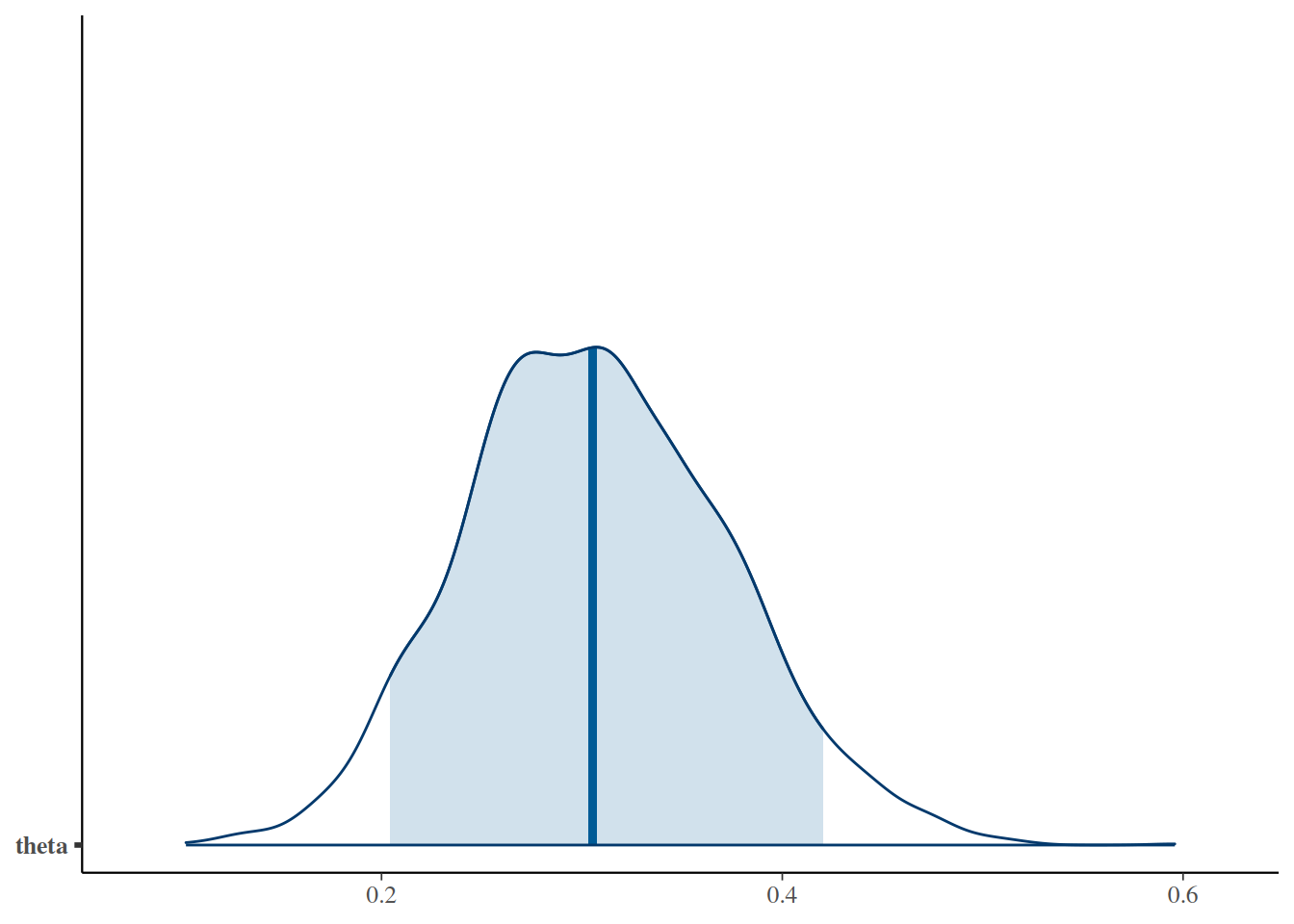
Algunos diagnósticos:
gf_dens(~theta, data =posterior(simple_stanfit))
simple_mcmc <-as.matrix(simple_stanfit)mcmc_areas(as.mcmc.list(simple_stanfit), prob =0.9, pars ="theta")