Cushny, A. R. and Peebles, A. R. (1905) “The action of optical isomers: II hyoscines.” The Journal of Physiology 32, 501–510.
7.1.1 Datos
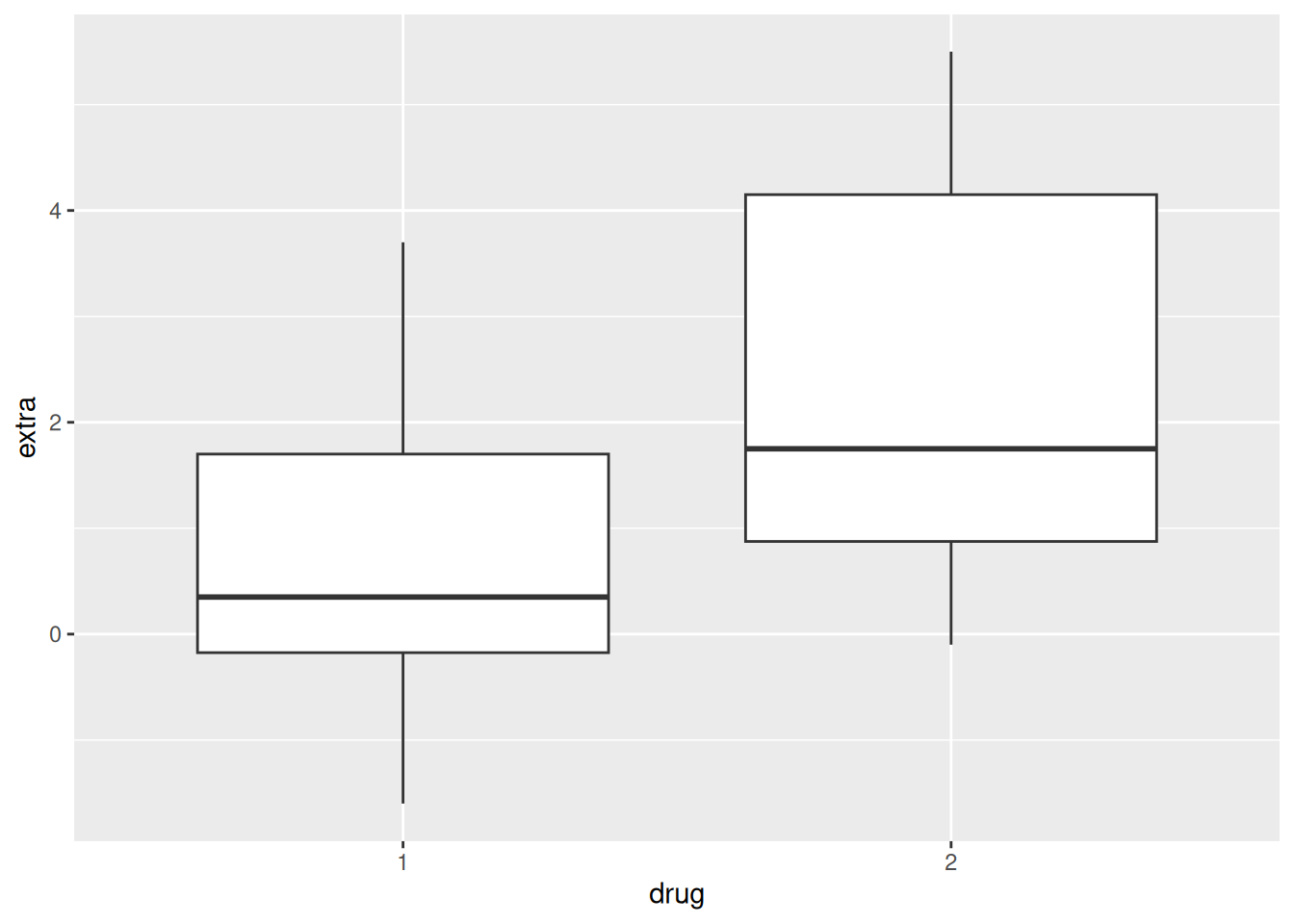
Cargamos y exploramos los datos. (extra = horas adicionales de sueño con el medicamento; group se renombra a drug porque se refiere al tipo de medicación).
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(ggformula)
Loading required package: scales
Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
Loading required package: ggridges
New to ggformula? Try the tutorials:
learnr::run_tutorial("introduction", package = "ggformula")
learnr::run_tutorial("refining", package = "ggformula")
response drug min Q1 median Q3 max mean sd n missing
1 extra 1 -1.6 -0.175 0.35 1.70 3.7 0.75 1.789010 10 0
2 extra 2 -0.1 0.875 1.75 4.15 5.5 2.33 2.002249 10 0
Pregunta de investigación: ¿Cómo afectan dos medicamentos distintos al tiempo de sueño, comparando a los mismos sujetos sin medicación y luego con el medicamento?
7.1.2 Modelo
La forma más simple para comparar medias consiste en suponer que cada grupo proviene de una distribución normal con media desconocida y desviación estándar común. Más adelante veremos cómo permitir desviaciones estándar diferentes por grupo.
Para dos grupos, definimos tres parámetros: las medias \(\mu_1\) y \(\mu_2\), y la desviación estándar compartida \(\sigma\). Además, necesitamos distribuciones previas para esos parámetros. Una elección habitual es asignar a cada media una normal previa y a \(\sigma\) una distribución uniforme (aunque luego discutiremos alternativas más informativas).
La normal previa para \(\mu_g\) con media 0 y desviación estándar 3 significa que, a priori, estamos 95% seguros de que el efecto del medicamento está entre –6 y +6 horas de sueño adicional, y resulta muy improbable un cambio mayor a 9 horas.
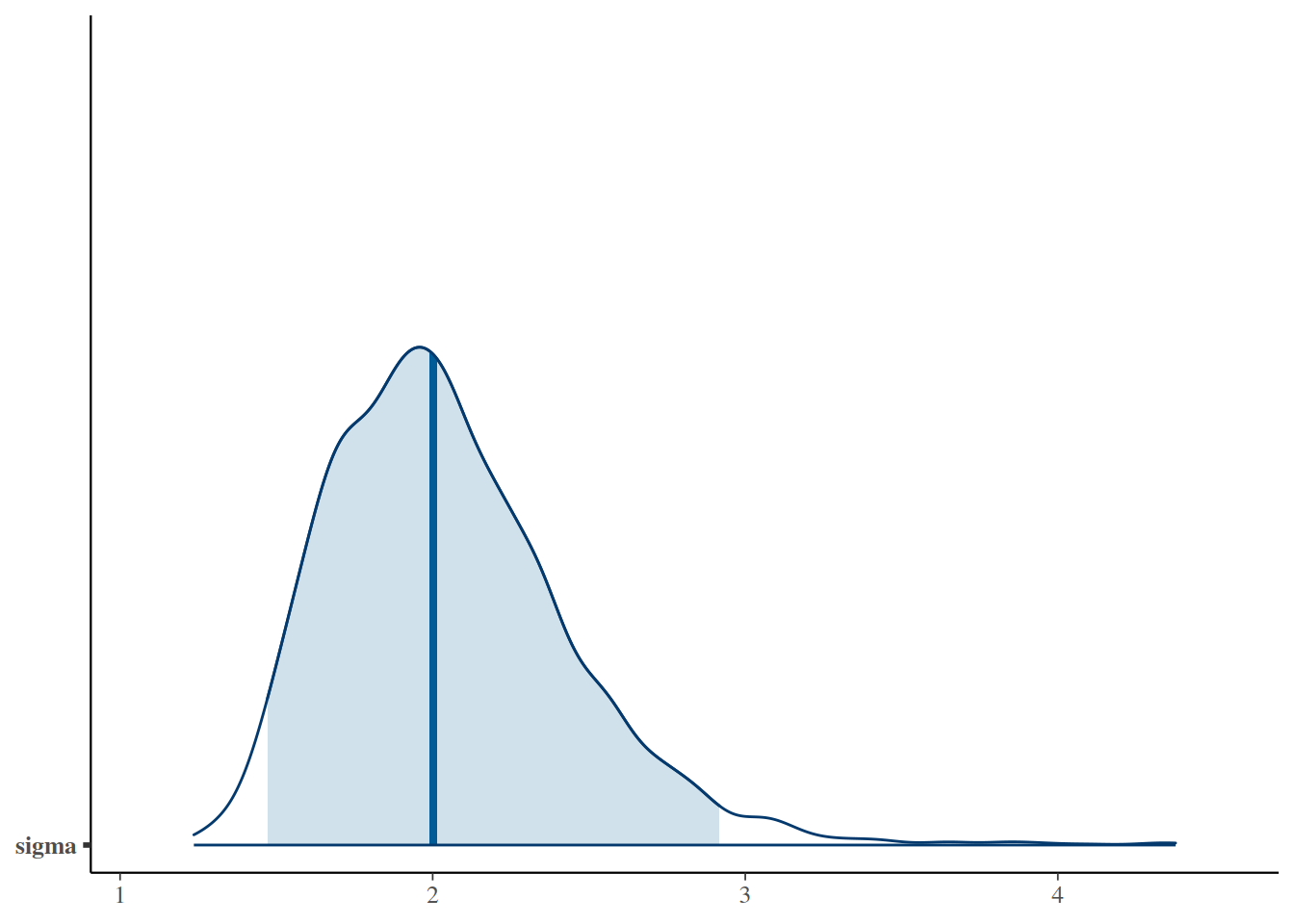
Para \(\sigma\) usamos Uniform\((0.002, 2000)\), una previa no restrictiva que cubre desde varianzas muy pequeñas hasta extremadamente grandes.
A continuación, se muestra la implementación en JAGS usando la librería R2jags.
library(R2jags)
Loading required package: rjags
Loading required package: coda
Linked to JAGS 4.3.2
Loaded modules: basemod,bugs
Attaching package: 'R2jags'
The following object is masked from 'package:coda':
traceplot
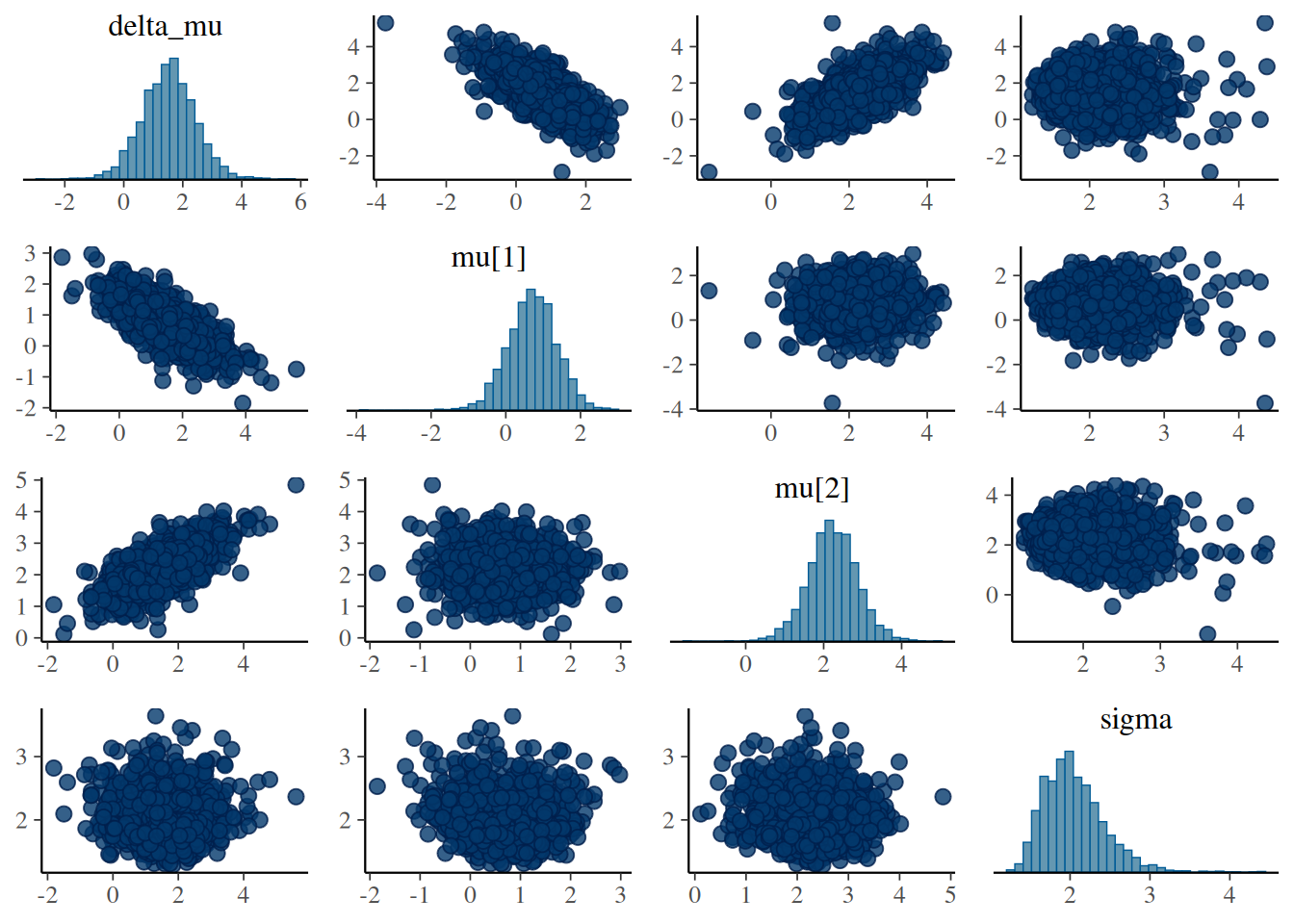
# Gráficos de pares para mu[1], mu[2], sigmamcmc_pairs(sleep_mcmc)
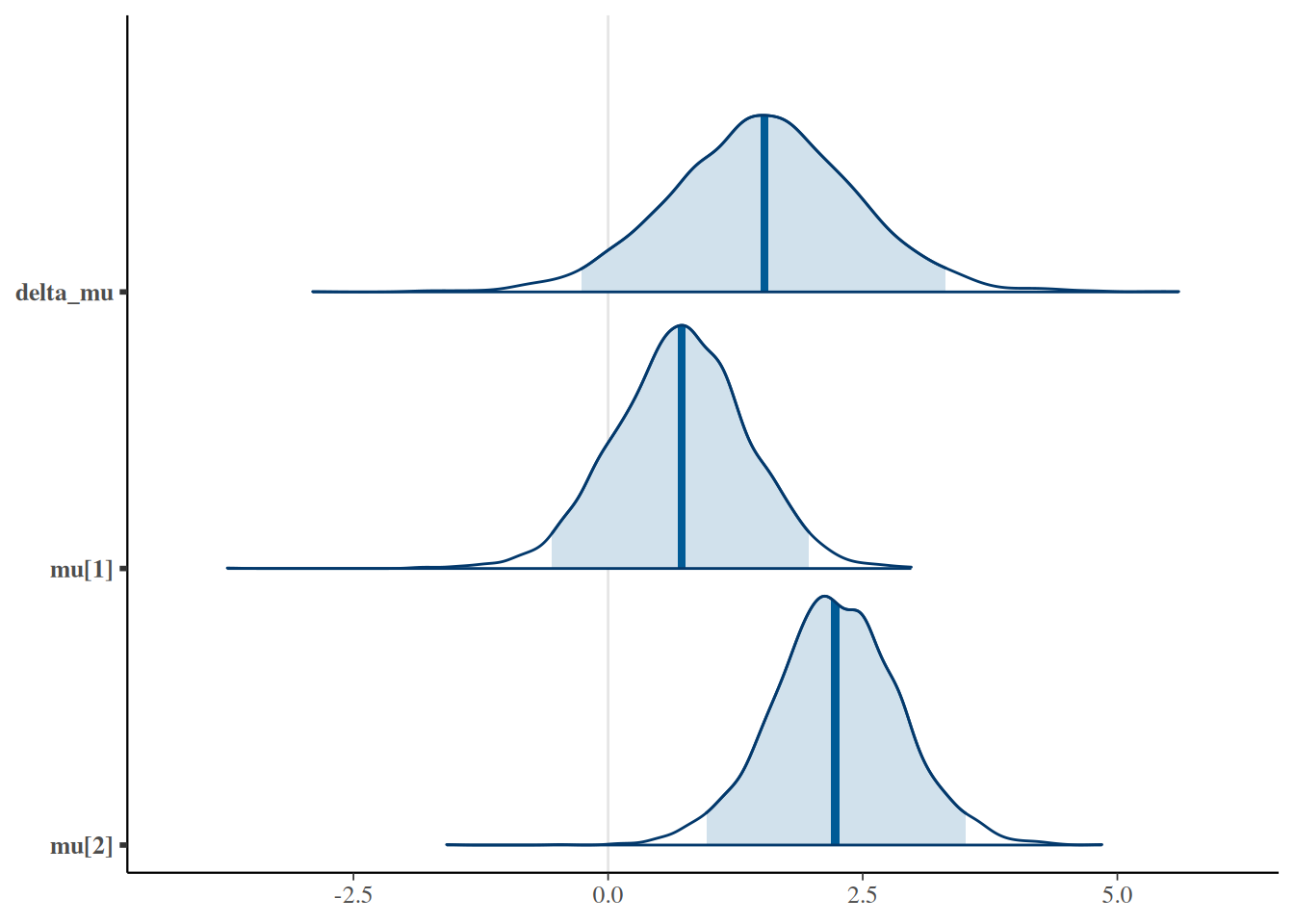
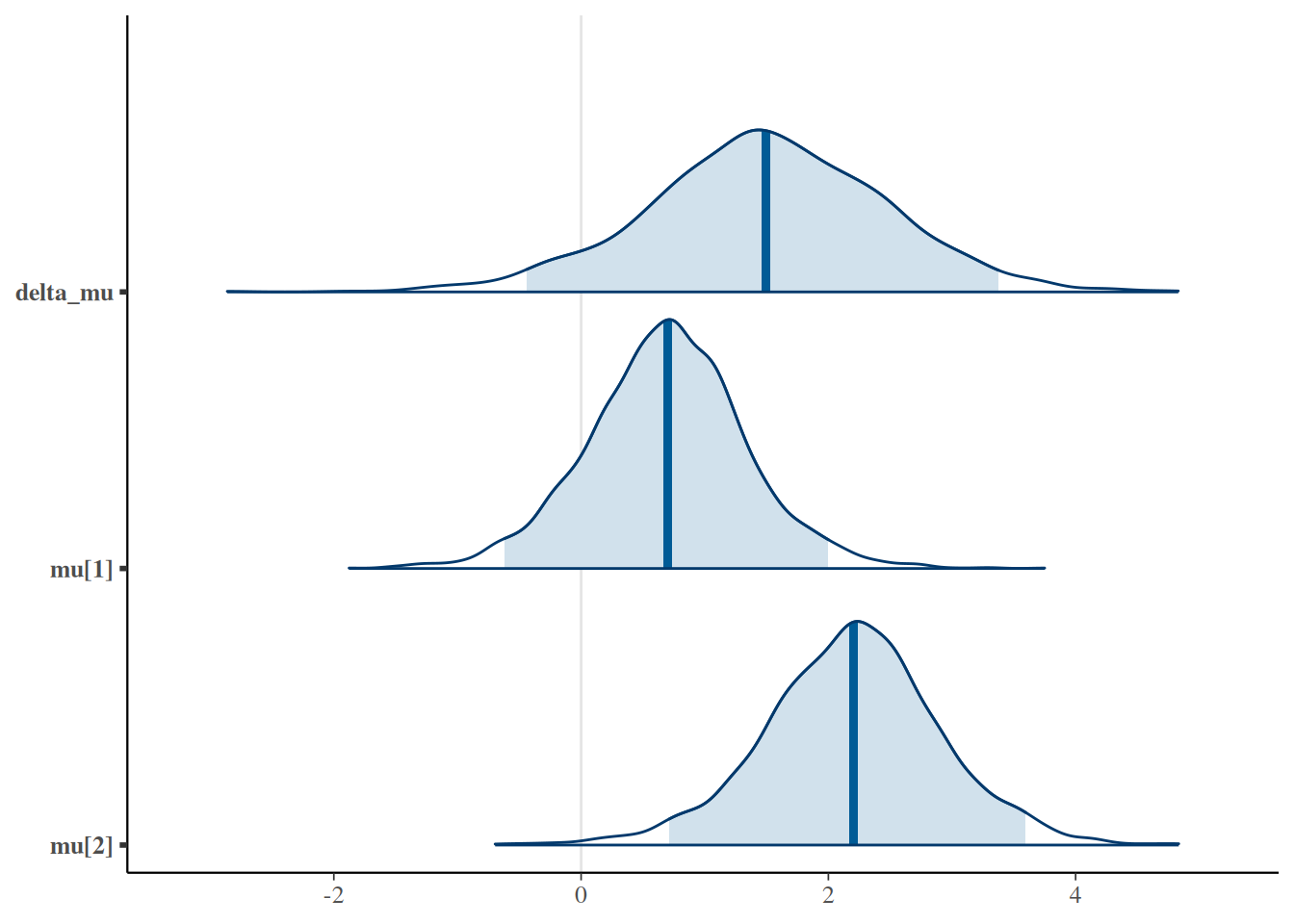
Para cuantificar la probabilidad posterior de que el tiempo medio de sueño con la segunda droga supere al de la primera, calculamos:
library(mosaic)
Registered S3 method overwritten by 'mosaic':
method from
fortify.SpatialPolygonsDataFrame ggplot2
The 'mosaic' package masks several functions from core packages in order to add
additional features. The original behavior of these functions should not be affected by this.
Attaching package: 'mosaic'
The following object is masked from 'package:Matrix':
mean
The following object is masked from 'package:scales':
rescale
The following objects are masked from 'package:dplyr':
count, do, tally
The following object is masked from 'package:purrr':
cross
The following object is masked from 'package:ggplot2':
stat
The following objects are masked from 'package:stats':
binom.test, cor, cor.test, cov, fivenum, IQR, median, prop.test,
quantile, sd, t.test, var
The following objects are masked from 'package:base':
max, mean, min, prod, range, sample, sum
prop( ~(delta_mu >0), data =posterior(sleep_jags) )
prop_TRUE
0.952
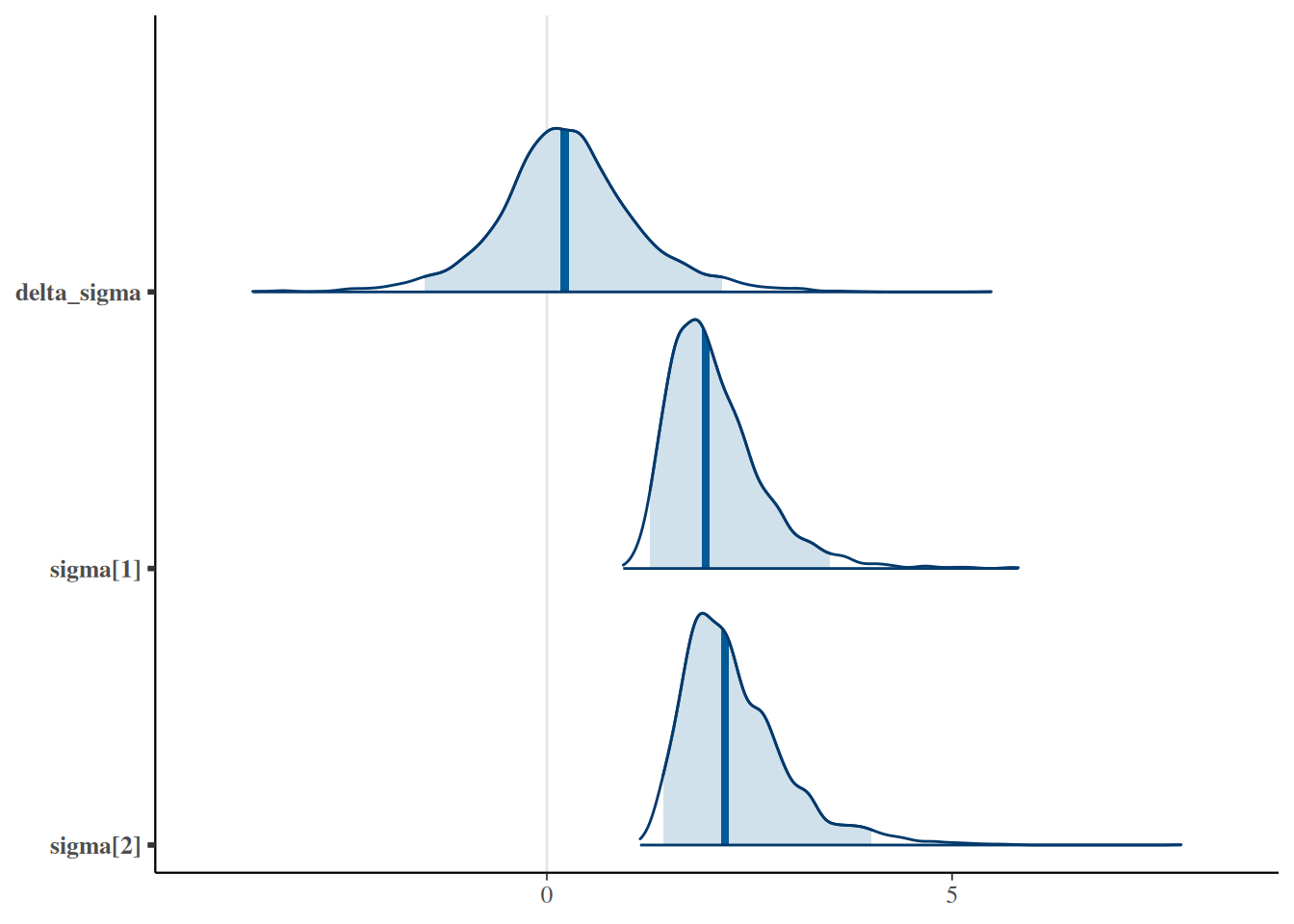
7.1.3 Desviaciones estándar diferentes por grupo
Si en lugar de una \(\sigma\) común queremos una \(\sigma\) distinta para cada medicamento, el modelo cambia ligeramente:
Welch Two Sample t-test
data: extra by drug
t = -1.8608, df = 17.776, p-value = 0.07939
alternative hypothesis: true difference in means between group 1 and group 2 is not equal to 0
95 percent confidence interval:
-3.3654832 0.2054832
sample estimates:
mean in group 1 mean in group 2
0.75 2.33
prop( ~(delta_mu <0), data =posterior(sleep_jags2) )
prop_TRUE
0.06533333
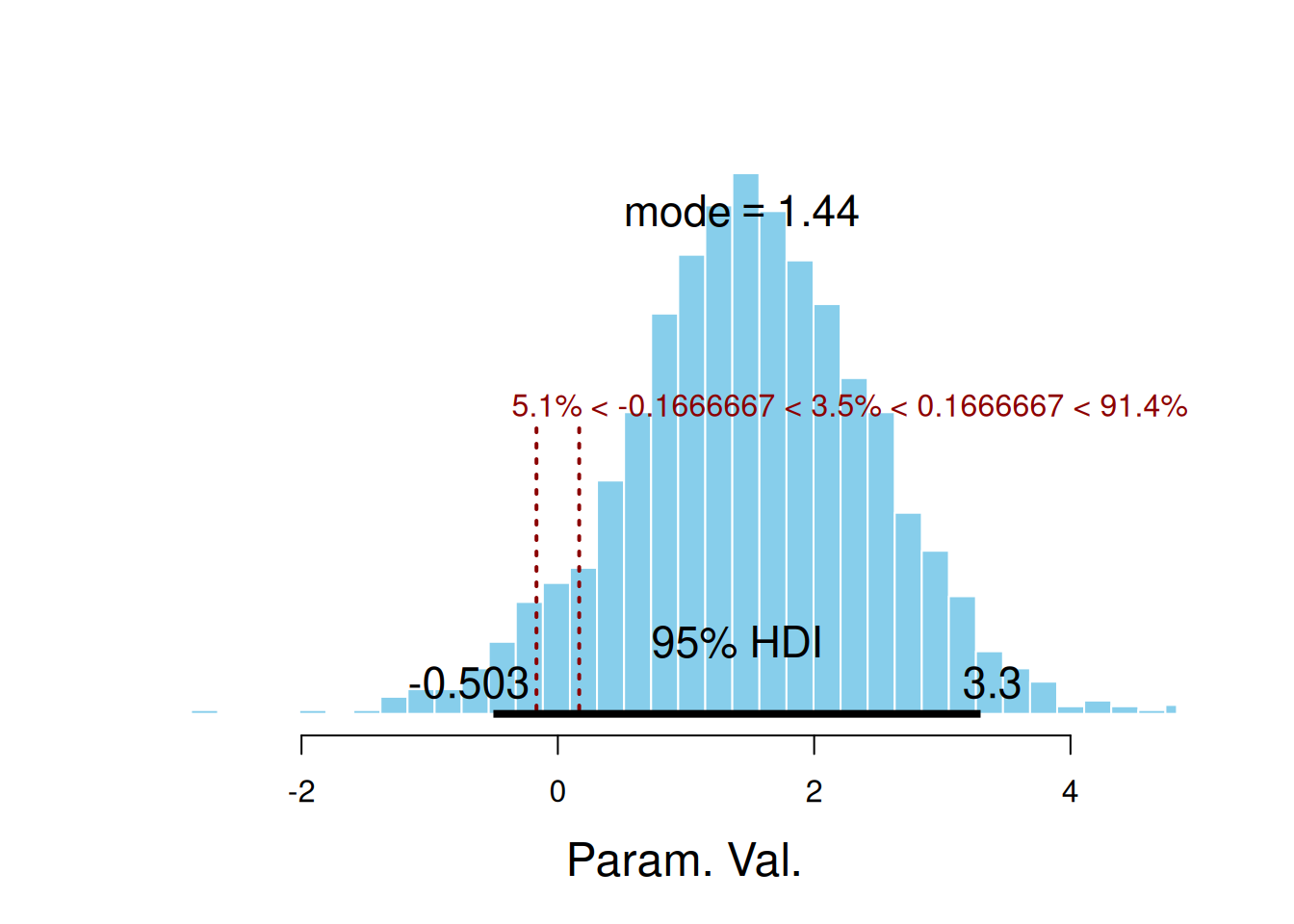
7.1.4 ROPE (Región de Equivalencia Práctica)
Para saber si una diferencia pequeña carece de relevancia práctica, definimos una región de equivalencia práctica (ROPE). Por ejemplo, si no nos importan diferencias menores a 10 minutos (1/6 horas), la ROPE para \(\delta_\mu\) sería \((-1/6,1/6)\). Podemos verificar si el 95% HDI queda completamente fuera de esa ROPE:
$posterior
ESS mean median mode
var1 3000 1.498507 1.491914 1.436025
$hdi
prob lo hi
1 0.95 -0.5027985 3.29843
$ROPE
lo hi P(< ROPE) P(in ROPE) P(> ROPE)
1 -0.1666667 0.1666667 0.05066667 0.03533333 0.914
7.1.5 Comparaciones pareadas
Los datos originales incluyen otra variable: ID, porque las mismas diez personas fueron evaluadas con cada medicamento. Si queremos comparar directamente ambos medicamentos por sujeto, podemos usar las diferencias individuales:
Entonces, para modelar la diferencia \(\delta_i\) de cada sujeto \(i\), podemos usar una distribución \(t\) robusta:
sleep_model4 <-function() {for (i in1:Nsubj) { delta[i] ~dt(mu, 1/ sigma^2, nu) } mu ~dnorm(0, 2) sigma ~dunif(0.002, 2000) nuMinusOne ~dexp(1/29) nu <- nuMinusOne +1 tau <-1/ sigma^2}sleep_jags4 <-jags(model = sleep_model4,parameters.to.save =c("mu", "sigma", "nu"),data =list(delta = sleep_wide$delta,Nsubj =nrow(sleep_wide) ),n.iter =5000,DIC =FALSE)
Compiling model graph
Resolving undeclared variables
Allocating nodes
Graph information:
Observed stochastic nodes: 10
Unobserved stochastic nodes: 3
Total graph size: 24
Initializing model
summary(sleep_jags4)
fit using jags
3 chains, each with 5000 iterations (first 2500 discarded), n.thin = 2
n.sims = 3750 iterations saved
mu.vect sd.vect 2.5% 25% 50% 75% 97.5% Rhat n.eff
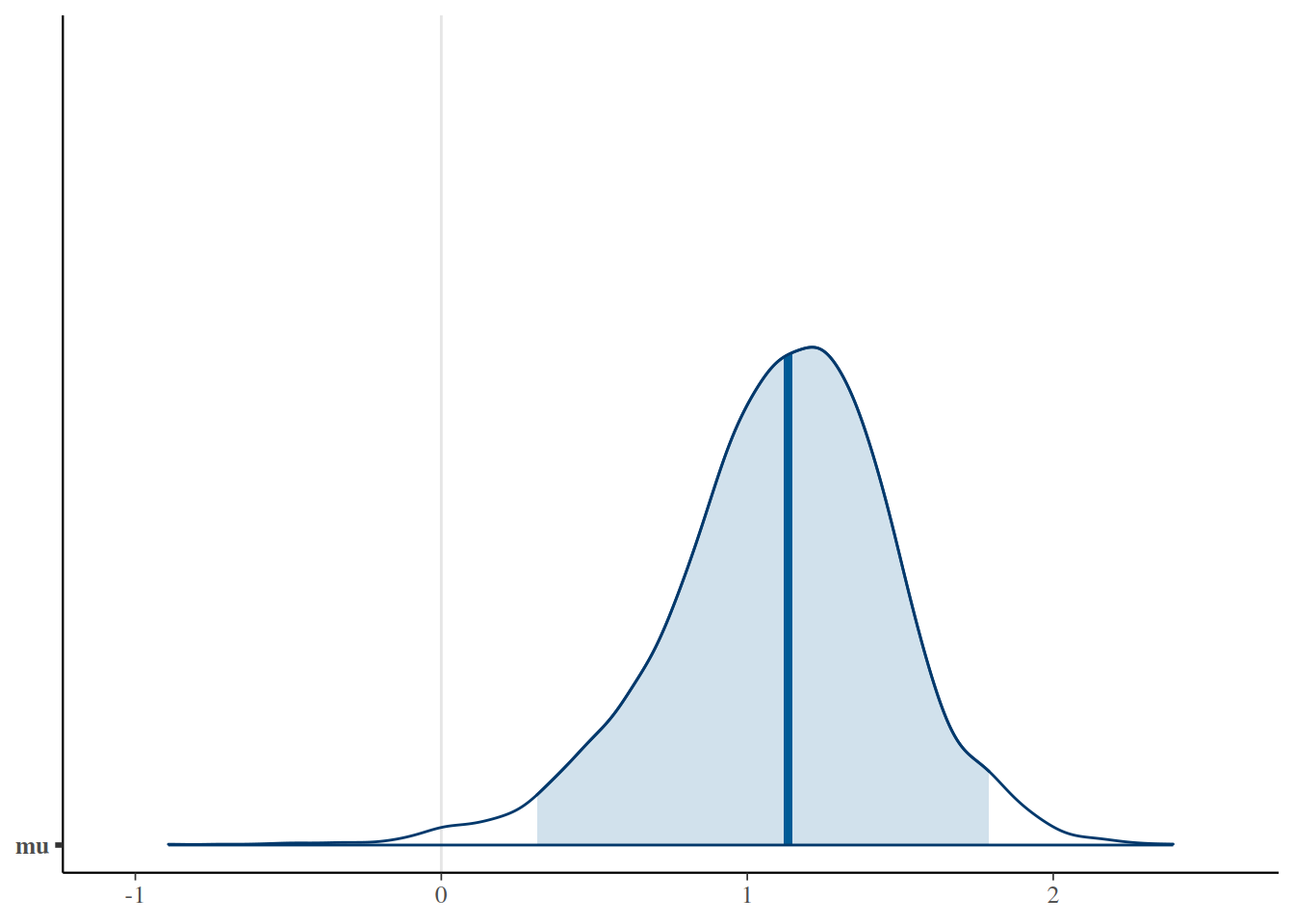
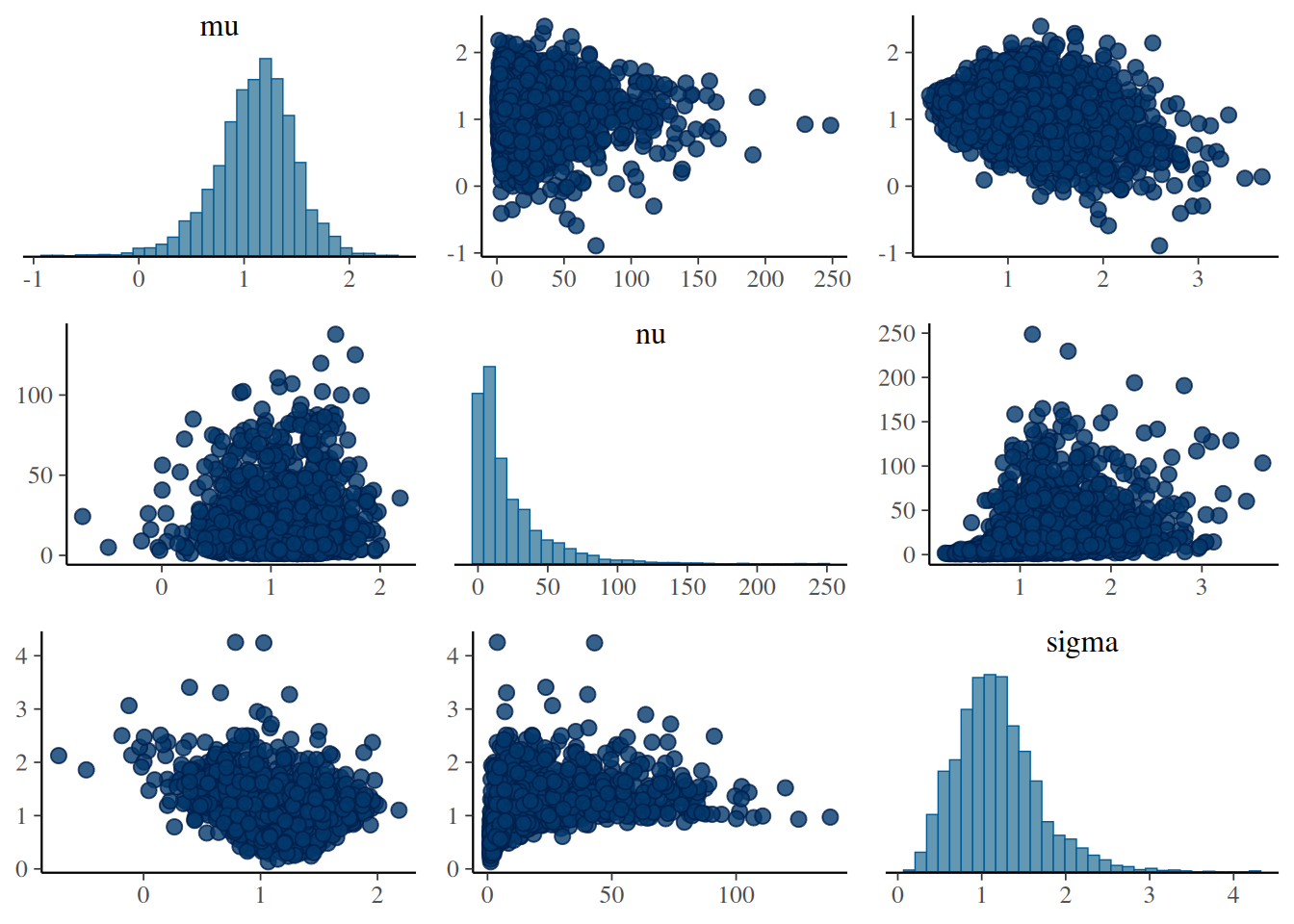
mu 1.108 0.371 0.312 0.896 1.133 1.353 1.790 1.001 3500
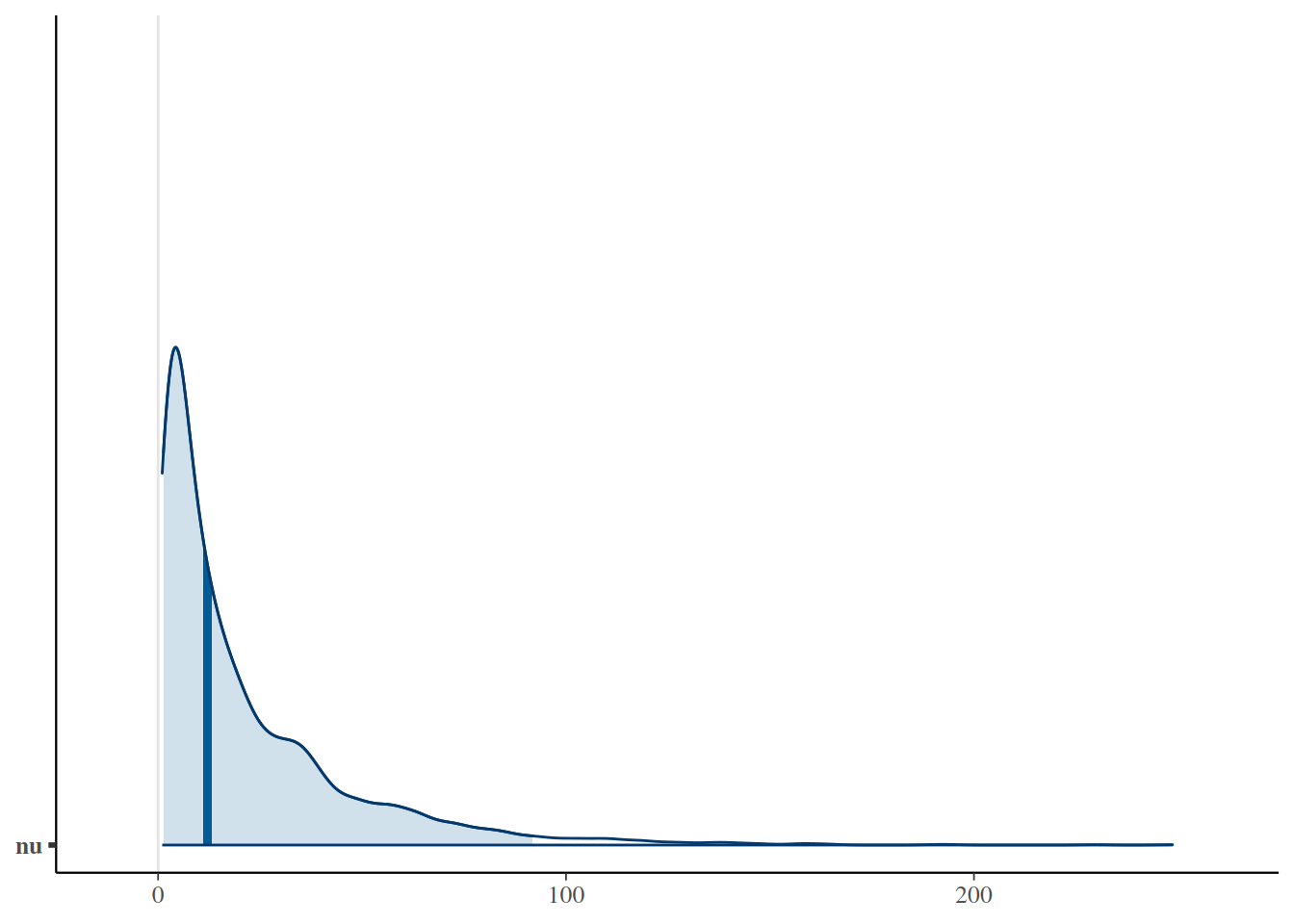
nu 21.579 25.362 1.299 4.406 12.008 29.780 91.843 1.006 400
sigma 1.183 0.493 0.407 0.851 1.129 1.446 2.363 1.002 1200
sleep_mcmc4 <-as.mcmc(sleep_jags4)mcmc_areas(sleep_mcmc4, prob =0.95, pars ="mu")
mcmc_areas(sleep_mcmc4, prob =0.95, pars ="nu")
mcmc_pairs(sleep_mcmc4)
prop( ~(mu >0), data =posterior(sleep_jags4) )
prop_TRUE
0.9933333
hdi(sleep_jags4, pars =c("mu"))
par lo hi prob chain
1 mu 0.4359805 1.832829 0.95 1
2 mu 0.3154208 1.777718 0.95 2
3 mu 0.3856669 1.912459 0.95 3
hdi(sleep_jags4)
par lo hi prob chain
1 mu 0.4359805 1.832829 0.95 1
2 mu 0.3154208 1.777718 0.95 2
3 mu 0.3856669 1.912459 0.95 3
4 nu 1.0043826 69.264565 0.95 1
5 nu 1.0013740 65.134106 0.95 2
6 nu 1.0200925 86.187685 0.95 3
7 sigma 0.2894731 2.089948 0.95 1
8 sigma 0.3436961 2.109135 0.95 2
9 sigma 0.3120321 2.245814 0.95 3
7.2 Regresión Lineal Simple
Cargamos Stan:
library(rstan)
Loading required package: StanHeaders
rstan version 2.32.7 (Stan version 2.32.2)
For execution on a local, multicore CPU with excess RAM we recommend calling
options(mc.cores = parallel::detectCores()).
To avoid recompilation of unchanged Stan programs, we recommend calling
rstan_options(auto_write = TRUE)
For within-chain threading using `reduce_sum()` or `map_rect()` Stan functions,
change `threads_per_chain` option:
rstan_options(threads_per_chain = 1)
Attaching package: 'rstan'
The following object is masked from 'package:R2jags':
traceplot
The following object is masked from 'package:coda':
traceplot
The following object is masked from 'package:tidyr':
extract
7.2.1 Ejemplo: Datos de Galton
Para ilustrar regresión, utilizaremos un conjunto de datos histórico: las alturas recopiladas por Francis Galton, que incluyeron la altura de adultos y la de sus padres.
library(mosaicData)head(Galton)
Para simplificar, nos quedamos solo con las mujeres y, de cada familia, tomamos un único registro:
El modelo lineal simple asume que cada observación \(y_i\) se distribuye según una normal (o t-Student) cuya media depende linealmente de \(x_i\). Es decir:
Permitir que la desviación estándar dependa de \(x_i\).
Usar una relación funcional distinta (regresión no lineal).
7.2.2.2 Previas
Debemos asignar previas a los cuatro parámetros: \(\beta_0\), \(\beta_1\), \(\sigma\) y \(\nu\).
\(\nu\) (grados de libertad): Una Gamma trasladada centrada alrededor de 30 es una elección genérica que permite flexibilidad para alejarse de la normalidad si hace falta.
\(\beta_1\) (pendiente): El estimador MLE de \(\beta_1\) es
\(\sigma\) mide la variabilidad de \(y_i\) alrededor de \(\mu_i\), para un \(x_i\) fijo. Una previa uniforme (muy poco informativa) sobre un rango amplio de \(\sigma\) garantiza cobertura sin forzar demasiado.
7.2.2.2.1 Implementación en JAGS
galton_model <-function() {for (i in1:length(y)) { y[i] ~dt(mu[i], 1/sigma^2, nu) mu[i] <- beta0 + beta1 * x[i] } sigma ~dunif(6/100, 6*100) nuMinusOne ~dexp(1/29) nu <- nuMinusOne +1# Previas para beta0 y beta1: beta0 ~dnorm(0, 1/100^2) # "100" es orden de magnitud de las alturas beta1 ~dnorm(0, 1/4^2) # esperamos pendiente en torno a 1}
Observamos que la convergencia no es óptima, debido a la fuerte correlación entre \(\beta_0\) y \(\beta_1\), que genera una “cresta” estrecha en la distribución conjunta y ralentiza al muestreador de Gibbs.
7.2.2.3 Posibles soluciones
Reparametrizar el modelo, para reducir la correlación posterior entre parámetros.
Usar un algoritmo más eficiente (por ejemplo, Hamiltonian Monte Carlo en Stan).
de modo que \(\beta_1 = \alpha_1\) y \(\beta_0 = \alpha_0 - \alpha_1,\overline{x}\). Con esta parametrización, \(\alpha_0\) es la media predicha cuando \(x=\overline{x}\), y \(\alpha_1\) sigue siendo la pendiente. La ventaja es que \(\alpha_0\) y \(\alpha_1\) suelen aparecer menos correlacionados en la posterior.
Si nuestro interés principal es la pendiente (generalmente más relevante que el intercepto), podemos resumir \(\beta_1\) con su HDI:
hdi(posterior(galtonC_jags), pars ="beta1")mcmc_areas(as.mcmc(galtonC_jags), pars ="beta1", prob =0.95)
Galton observó que \(\beta_1 < 1\), lo que refleja el fenómeno de “regresión hacia la media”: hijos de padres muy altos tienden a ser algo más bajos, y niños de padres bajos, algo más altos.
7.3.1.2 Predicción
Supongamos que la “altura media parental” es \(x=70\). Cada muestra posterior define una t-Student( \(\beta_0 + \beta_1x\), \(\sigma\), \(\nu\) ). La distribución predictiva de la altura de una hija para \(x=70\) se obtiene así:
En promedio, esperamos alturas de alrededor de 66–67 pulgadas.
Podemos trazar todas las líneas de regresión de cada muestra posterior y superponer el 95% HDI en \(x=70\):
PosteriorSample <-posterior(galtonC_jags) %>%sample_n(2000)gf_abline(intercept =~beta0, slope =~beta1,data = PosteriorSample, alpha =0.01, color ="steelblue") %>%gf_point(height ~ midparent, data = GaltonW, inherit =FALSE, alpha =0.5) %>%gf_errorbar(lo + hi ~70, data = Galton_hdi,color ="skyblue", width =0.2, size =1.2, inherit =FALSE)
Sin embargo, ese HDI solo describe la media (\(\beta_0 + \beta_1\cdot 70\)), no la dispersión individual alrededor de dicha media. Para simular alturas individuales agregamos ruido t-Student con \(\sigma\) y \(\nu\):
7.3.1.3 Verificación predictiva posterior con bayesplot
Para evaluar si el modelo reproduce bien los datos, necesitamos:
\(y_{\text{obs}}\): vector de observaciones reales (GaltonW$height).
\(y_{\text{rep}}\): matriz con simulaciones de \(y\) para cada muestra posterior. Cada fila corresponde a una muestra posterior y cada columna a un individuo.
Podemos generar esas simulaciones con CalvinBayes::posterior_calc():
Con bayesplot trazamos intervalos predictivos en función de \(x\):
ppc_intervals(GaltonW$height, y_avg, x = GaltonW$midparent)ppc_intervals(GaltonW$height, y_ind, x = GaltonW$midparent)
Si queremos personalizar, extraemos los datos con ppc_ribbon_data() y luego usamos ggformula:
plot_data <-ppc_ribbon_data(GaltonW$height, y_ind, x = GaltonW$midparent)# Banda central y cintas de predicción:plot_data %>%gf_ribbon(ll + hh ~ x, fill ="steelblue") %>%gf_ribbon(l + h ~ x, fill ="steelblue") %>%gf_line(m ~ x, color ="steelblue") %>%gf_point(y_obs ~ x, alpha =0.5)
7.4 Ajuste de modelos con Stan
Al centrar la variable explicativa, JAGS suele converger aceptablemente. No obstante, podemos usar Stan, que maneja la correlación posterior de manera más eficiente y no requiere reparametrización.
El modelo Stan se define en el archivo galton.stan. Para compilarlo:
El parámetro \(\beta_2\) cuantifica la diferencia en alturas promedio entre hombres y mujeres cuyos padres tienen la misma altura media. El 95% HDI de \(\beta_2\) se obtiene con:
¿Gastar más en educación resulta en puntajes SAT más altos? La prueba SAT es un examen estandarizado utilizado para la admisión a universidades en los Estados Unidos, que evalúa habilidades en lectura crítica, matemáticas y escritura. Datos de 1999 pueden usarse para explorar esta pregunta. Entre otras cosas, los datos incluyen el puntaje SAT promedio total (en una escala de 400 a 1600) y la cantidad de dinero gastado en educación (en miles de dólares por estudiante) en cada estado de Estados Unidos.
Como primer intento, podríamos ajustar un modelo lineal (sat vs expend). Usando centrado, el núcleo del modelo se ve así:
for (i in 1:length(y)) {
y[i] ~ dt(mu[i], 1/sigma^2, nu)
mu[i] <- alpha0 + alpha1 * (x[i] - mean(x))
}
alpha1 mide cuánto mejora el rendimiento en el SAT por cada $1000 gastados en educación en un estado. Para ajustar el modelo, necesitamos priors para nuestros cuatro parámetros:
Entonces, ¿cómo llenamos los signos de interrogación para este conjunto de datos?
sigma: {Unif}(?,?)
Esto cuantifica la cantidad de variación de un estado a otro entre estados que tienen el mismo gasto por estudiante. La escala del SAT varía de 400 a 1600. Los promedios estatales no estarán cerca de los extremos de esta escala. Una ventana de 6 órdenes de magnitud alrededor de 1 da {Unif}(0.001, 1000), ambos extremos de los cuales están bastante lejos de lo que creemos razonable.
alpha0: {Norm}(?, ?)
alpha0 mide el puntaje SAT promedio para los estados que gastan una cantidad promedio. Dado que los SAT promedio están alrededor de 1000, algo como {Norm}(1000, 100) parece razonable.
alpha1: {Norm}(0, ?)
Este es el más complicado. La pendiente de una línea de regresión no puede ser mucho más que \(\frac{SD_y}{SD_x}\), por lo que podemos estimar esa relación o calcularla a partir de nuestros datos para guiar nuestra elección de prior.
sat_jags <-jags(model = sat_model,data =list(y = SAT$sat,x = SAT$expend,alpha0mean =1000, # SAT scores are roughly 500 + 500alpha0sd =100, # broad prior on scale of 400 - 1600alpha1sd =4*sd(SAT$sat) /sd(SAT$expend),sigma_lo =0.001, # 3 o.m. less than 1sigma_hi =1000# 3 o.m. greater than 1 ),parameters.to.save =c("nu", "log10nu", "alpha0", "beta0", "alpha1", "sigma"),n.iter =4000,n.burnin =1000,n.chains =3 )
Esto parece extraño: ¿Realmente podemos aumentar los puntajes SAT reduciendo la financiación a las escuelas? Quizás deberíamos observar los datos en bruto con nuestro modelo superpuesto.
gf_point(sat ~ expend, data = SAT) %>%gf_abline(slope =~ alpha1, intercept =~ beta0, data =posterior(sat_jags) %>%sample_n(2000),alpha =0.01, color ="steelblue")
Hay mucha dispersión, y la tendencia negativa está fuertemente influenciada por los 4 estados que gastan más (y tienen puntajes SAT relativamente bajos). Para solventar este problema vamos a incluir más covariables.
Tenemos algunos datos adicionales sobre cada estado. Vamos a ajustar un modelo con dos predictores: expend y frac.
El paquete brms proporciona una forma simplificada de describir modelos lineales generalizados y ajustarlos con Stan. La función brm() convierte una descripción concisa del modelo en código Stan, lo compila y lo ejecuta. Aquí hay un modelo lineal con sat como respuesta, y expend, frac, y una interacción como predictores.
Stan maneja mejor los parámetros correlacionados que JAGS.
sat3_stanmcmc_combo(as.mcmc.list(sat3_stan))
Podemos usar stancode() para extraer el código Stan utilizado para ajustar el modelo.
stancode(sat3_brm)
Podemos usar standata() para mostrar los datos que brm() pasa a Stan.
standata(sat3_brm) %>%lapply(head) # trunca la salida para ahorrar espacio
Supongamos que queremos construir un modelo que tenga el mismo prior y verosimilitud que nuestro modelo JAGS. Aquí están algunos valores que necesitaremos.
Para usar una distribución t para la respuesta, usamos family = student(). Para establecer los priors, es útil saber cuáles serán los nombres de los parámetros y cuáles serían los priors predeterminados si no hacemos nada. (Si no se lista ningún prior, se usará un prior plano impropio.)
get_prior( sat ~ expend * frac, data = SAT,family =student() # distribución para la variable de respuesta)
Podemos comunicar los priors a brm() de la siguiente manera:
sat3a_brm <-brm( sat ~ expend * frac, data = SAT,family =student(),prior =c(set_prior("normal(0,220)", coef ="expend"),set_prior("normal(0,11)", coef ="frac"),set_prior("normal(0,1.5)", coef ="expend:frac"),set_prior("normal(1000, 100)", class ="Intercept"),set_prior("exponential(1/30.0)", class ="nu"),set_prior("uniform(0.001,1000)", class ="sigma") ) )sat3a_stan <-stanfit(sat3a_brm)