En muchos problemas la variable respuesta es continua y estrictamente positiva; por ejemplo, biomasa de follaje o diámetros arbóreos. Estas variables suelen presentar asimetría a la derecha, ya que el límite en cero comprime la cola izquierda, y muestran además una varianza que crece con la media: cuando \(\mu\to0\) la varianza tiende a cero, y para valores grandes de \(\mu\) la varianza aumenta.
Para capturar este comportamiento creciente de la varianza, los modelos lineales generalizados (GLM) emplean funciones de varianza de la forma \(V(\mu)=\mu^p\). En particular:
\(V(\mu)=\mu^2\) conduce a la distribución gamma, adecuada cuando el coeficiente de variación es constante.
\(V(\mu)=\mu^3\) conduce a la distribución inversa gaussiana, útil cuando la cola derecha es aún más pesada.
En R, estos modelos se ajustan con
family =Gamma(link=…) # para GLM gamma family =inverse.gaussian(link=…) # para GLM inverso-gaussiano
10.1.1 Ejemplo: Biomasa de follaje en Tilia cordata
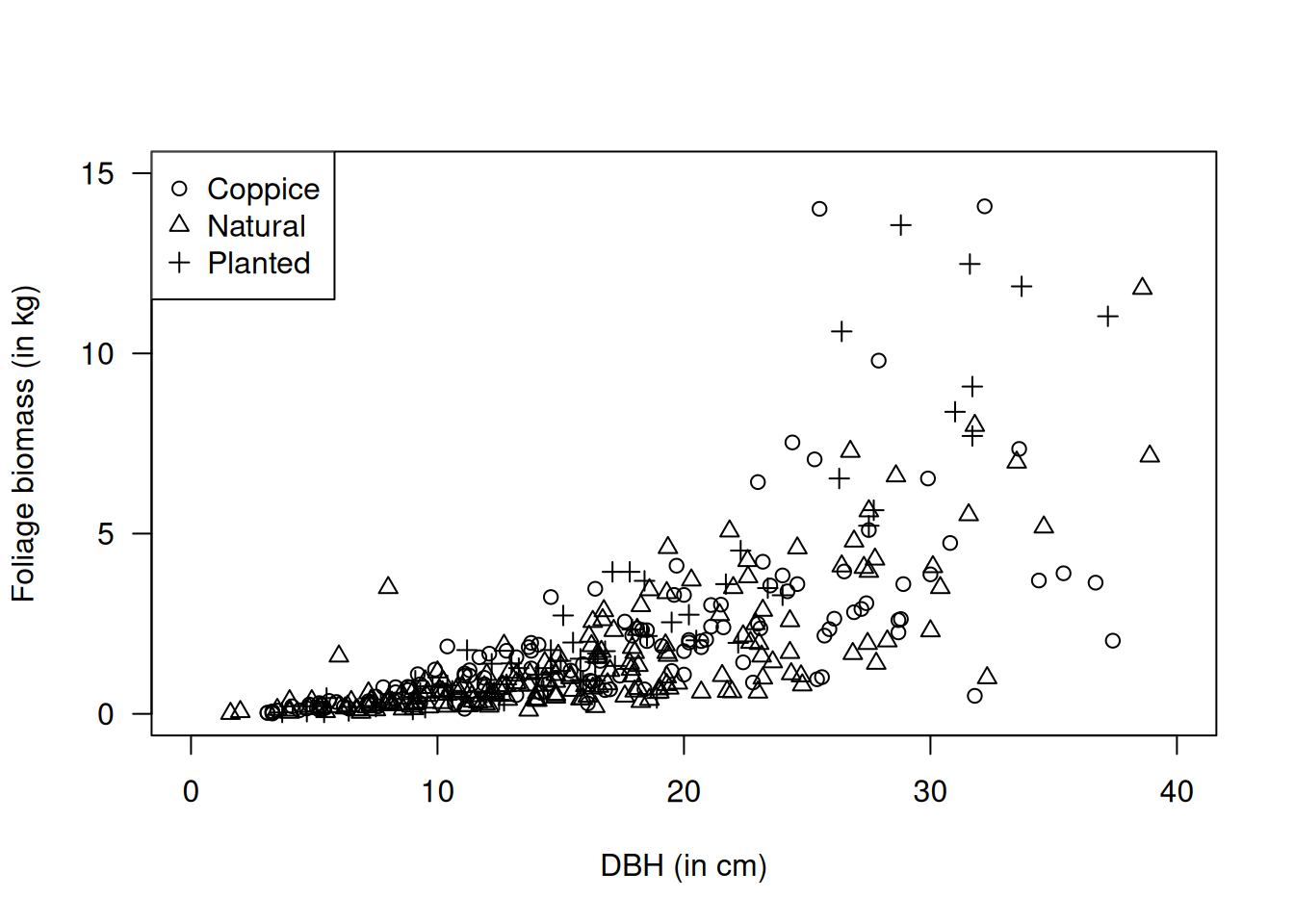
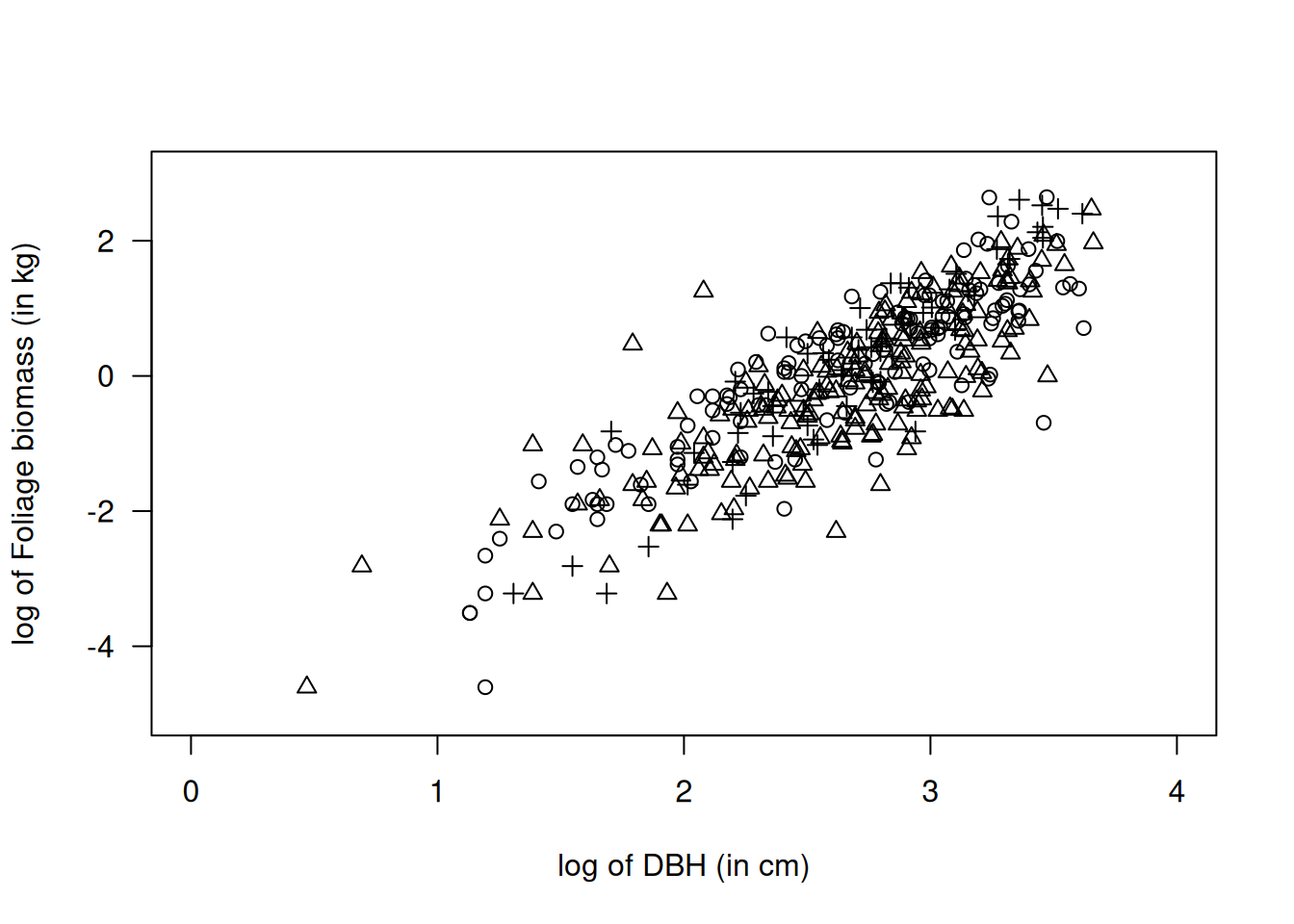
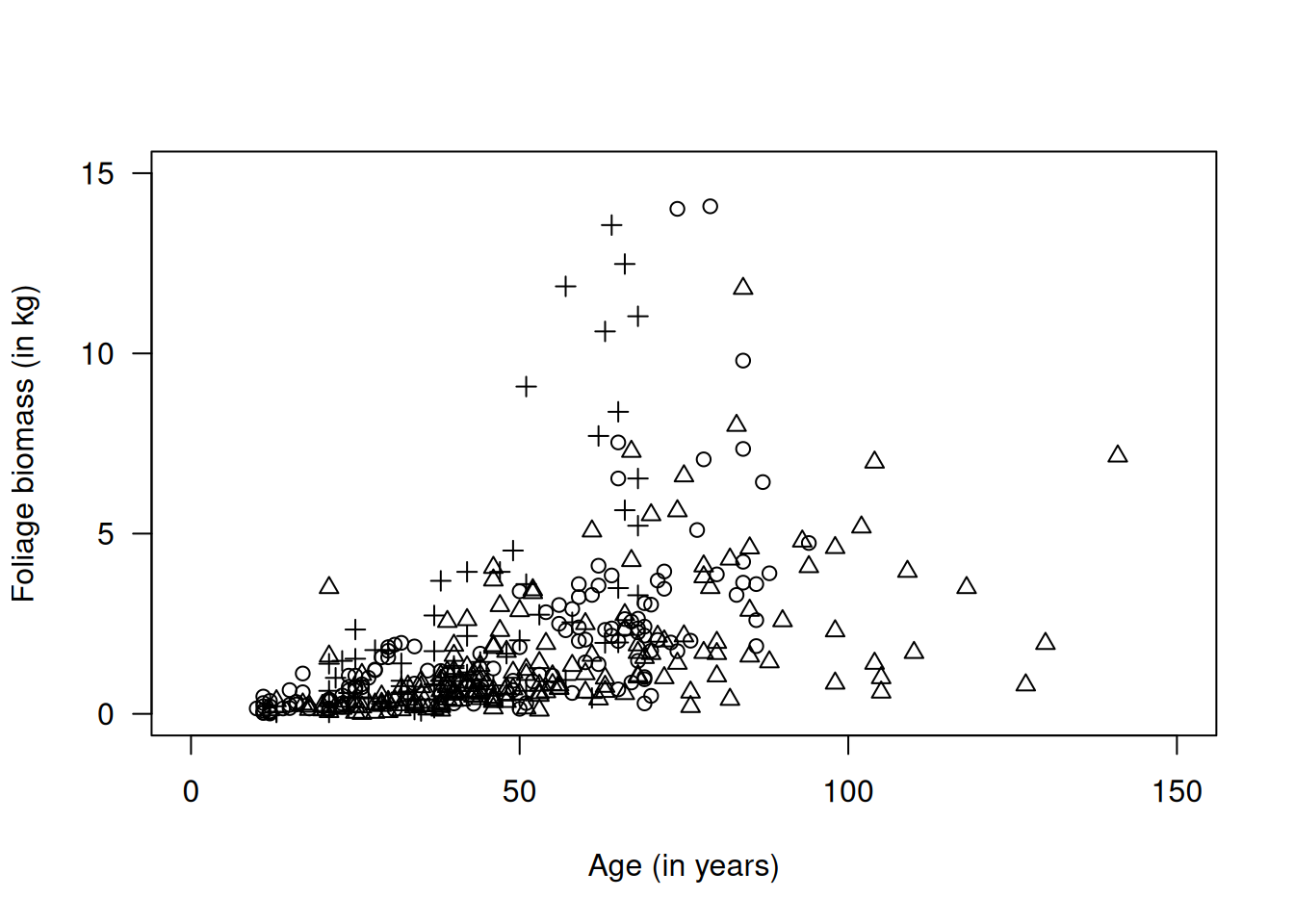
Un estudio sobre robles pequeños obtuvo una muestra de biomasa de follaje (\(y\)), el diámetro a la altura del pecho (DBH, \(d\)), la edad y el origen de cada árbol (coppice, natural, plantado). Biológicamente, la biomasa del follaje está relacionada con el área de la copa, aproximadamente proporcional a \(\pi d^2\). Por tanto, una transformación logarítmica sugiere el modelo
con una distribución de error gamma o inverso gaussiana para reflejar el aumento de varianza con la media.
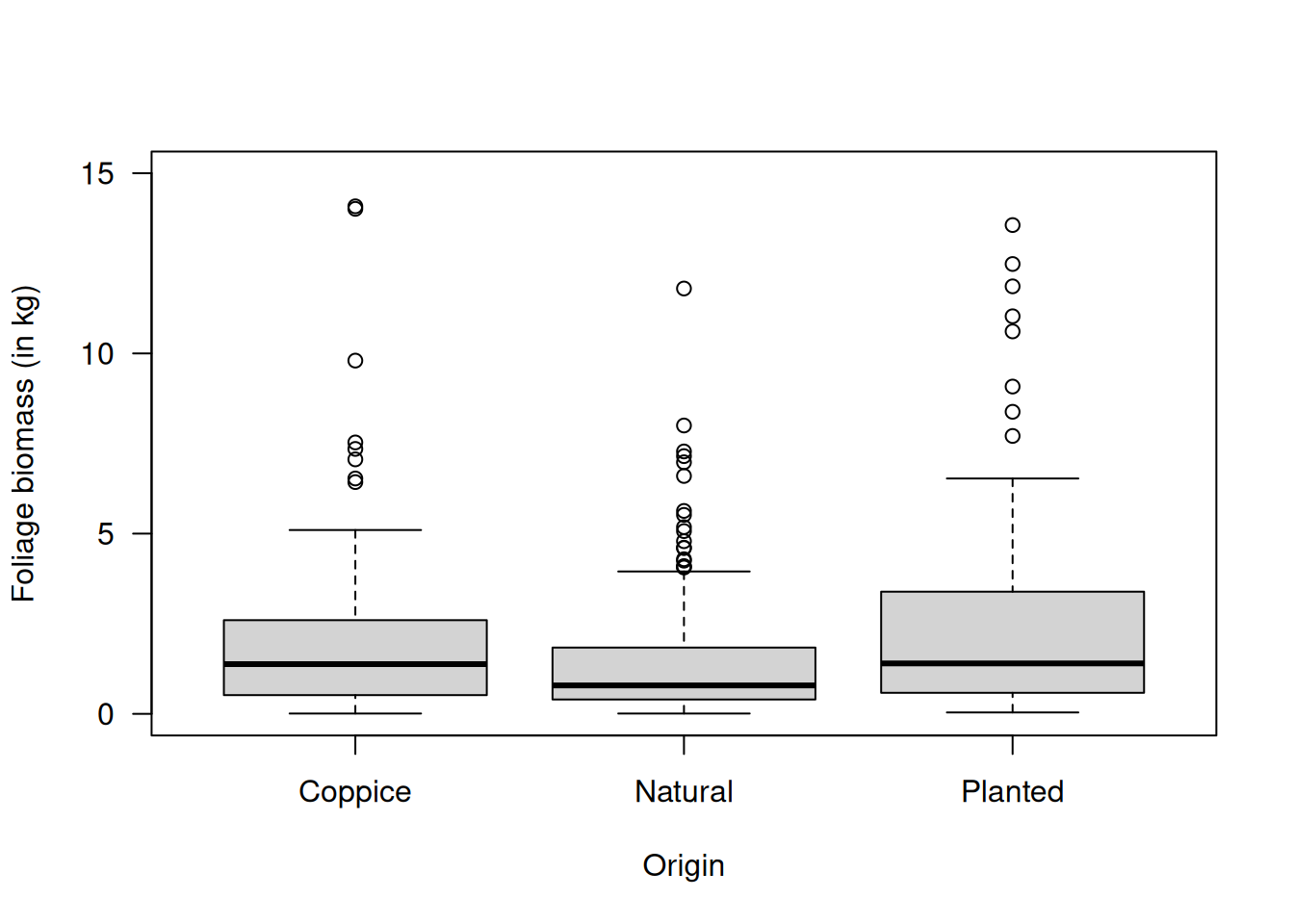
Al graficar \(\log(y)\) contra \(\log(d)\) y contra la edad, se observa una relación lineal en la escala log–log junto con heterocedasticidad creciente. El efecto del factor Origin es menos evidente, aunque podría incluirse como covariable categórica. Estos hallazgos apoyan el uso de un GLM gamma (o inverso-gaussiano si la cola derecha es muy pesada), que garantiza respuestas positivas y una varianza proporcional a \(\mu^2\) (o \(\mu^3\)) acorde con la dispersión observada.
# Plot Foliage against Originplot( Foliage ~ Origin, data=lime, ylim=c(0, 15),las=1, ylab="Foliage biomass (in kg)")
10.2 La distribución Gamma
La distribución Gamma es una opción habitual para modelar variables continuas positivas con asimetría a la derecha y varianza creciente con la media. Su función de densidad, en la parametrización habitual, es
con \(\mathrm{E}[y]=\alpha\beta\) y \(\operatorname{Var}[y]=\alpha\beta^2\). Para usarla en un GLM se reparametriza en términos de la media \(\mu\) y un parámetro de dispersión \(\phi>0\) mediante
y, por la aproximación saddlepoint, la suma ponderada de estas devianzas unitarias sigue \(\chi^2_{n-p'}\) aproximadamente, lo cual se puede asumir si \(y> 0\), \(\mu>0\) y \(\phi\) es pequeño. El enlace canónico es el recíproco \(\eta=1/\mu\), aunque en la práctica suele usarse el enlace log para garantizar \(\mu>0\) y lograr interpretaciones multiplicativas de los coeficientes.
Ejemplo
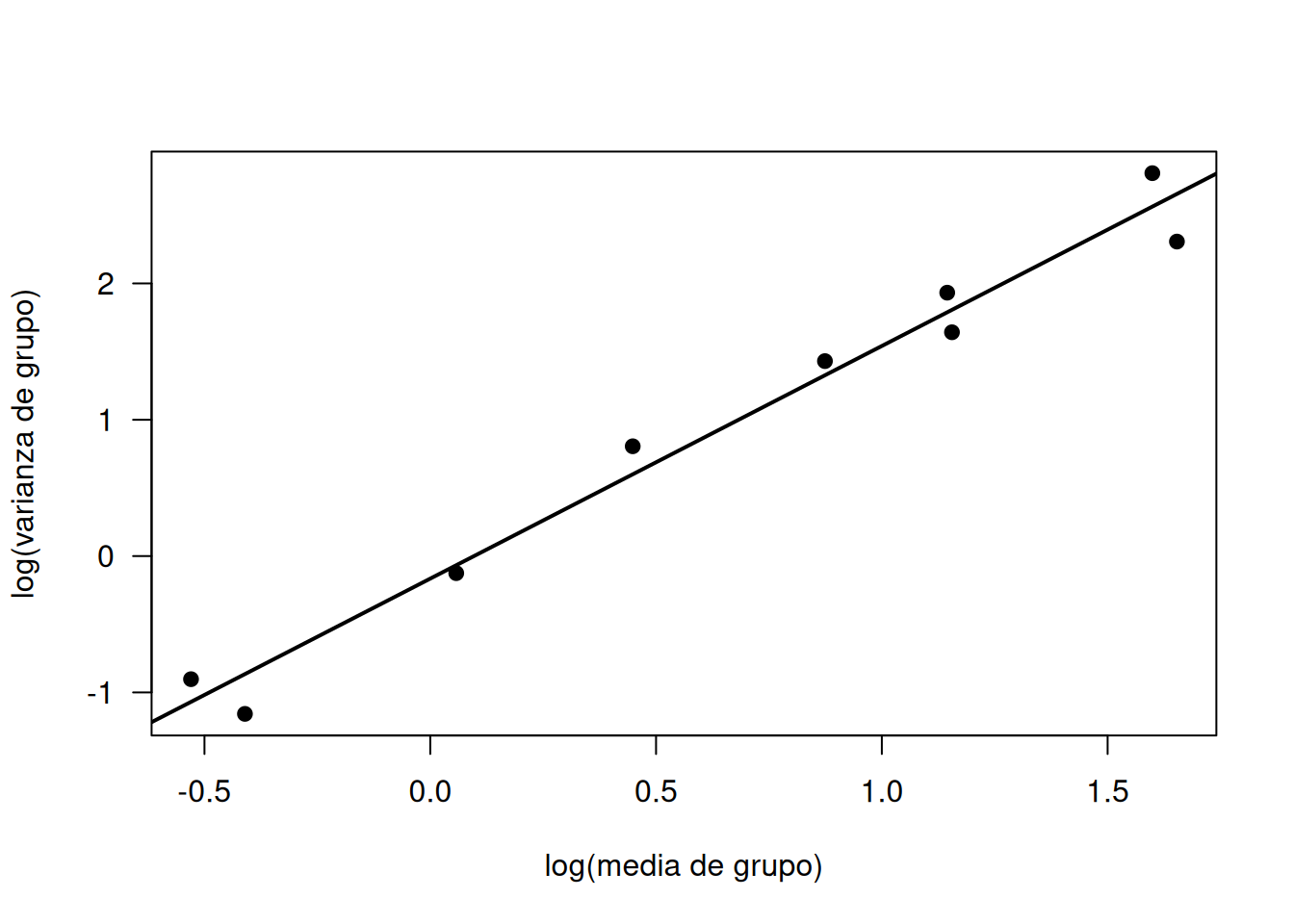
Para comprobar que \(V(\mu)\approx\mu^2\), se agrupan las observaciones de biomasa de follaje por edad y origen, y se calculan medias y varianzas de cada grupo. Luego se grafica \(\log(\text{varianza})\) frente a \(\log(\text{media})\) y se ajusta una recta:
library(GLMsData); data(lime)# Definir grupos de edadlime$AgeGrp <-cut(lime$Age, breaks=4)# Calcular medias y varianzas por grupo y origenvr <-with(lime, tapply(Foliage, list(AgeGrp, Origin), var))mn <-with(lime, tapply(Foliage, list(AgeGrp, Origin), mean))# Gráfico log(varianza) vs. log(media)plot(log(vr) ~log(mn), las=1, pch=19,xlab="log(media de grupo)", ylab="log(varianza de grupo)")# Ajuste de regresión lineal en escala log-logmf.lm <-lm(c(log(vr)) ~c(log(mn)))abline(coef(mf.lm), lwd=2)
El coeficiente de la pendiente resulta cercano a 1.7, muy próximo a 2, lo que confirma que
respaldando así el uso de un GLM Gamma para modelar la biomasa de follaje.
10.3 La distribución gaussiana inversa
La distribución gaussiana inversa es otra opción para modelar datos continuos positivos con asimetría más marcada que la Gamma. Su función de densidad, en la parametrización de GLM con media \(\mu>0\) y dispersión \(\phi>0\), es
lo que traduce una varianza que crece aún más rápido con la media. El enlace canónico es \(\eta=\mu^{-2}\), aunque en la práctica suele emplearse el enlace logarítmico u otros que garanticen \(\mu>0\) y faciliten la interpretación (por ejemplo, efectos multiplicativos).
10.3.2 Devianza unitaria y ajuste
La devianza unitaria queda dada por
\[
d(y,\mu)=\frac{(y-\mu)^2}{y\,\mu^2}\,,
\]
y la suma ponderada de estas devianzas, \(D(y,\hat\mu)=\sum w_i,d(y_i,\hat\mu_i)\), sigue exactamente una \(\chi^2_{n-p'}\) porque para la inversa gaussiana la aproximación saddlepoint es exacta. Por tanto, los tests de ajuste y las comparaciones análogas a \(F\)-tests (cuando \(\phi\) es estimada) mantienen su validez sin aproximaciones adicionales.
10.4 Funciones de enlace
En los GLM basados en distribuciones Gamma e inversa gaussiana, es esencial elegir un enlace que garantice \(\mu>0\) y aporte interpretabilidad. R admite para ambas familias los enlaces “log” (\(\eta=\log\mu\)), “identity” (\(\eta=\mu\)) e “inverse” (\(\eta=1/\mu\)), así como el enlace canónico “1/mu^2” para la inversa gaussiana.
En el ejemplo anterior, se procede así:
Enlace logarítmico (el habitual), que permite ajustar sin problemas:
Enlaces inverso e identidad, que provocan errores de convergencia incluso suministrando valores iniciales desde el modelo logarítmico:
lime.inv <-update(lime.log, family =Gamma(link="inverse"),mustart =fitted(lime.log))# Error: no valid set of coefficients has been foundlime.id <-update(lime.log, family =Gamma(link="identity"),mustart =fitted(lime.log))# Error: no valid set of coefficients has been found
Estos fallos indican que esos enlaces no son adecuados dada la forma de los datos.
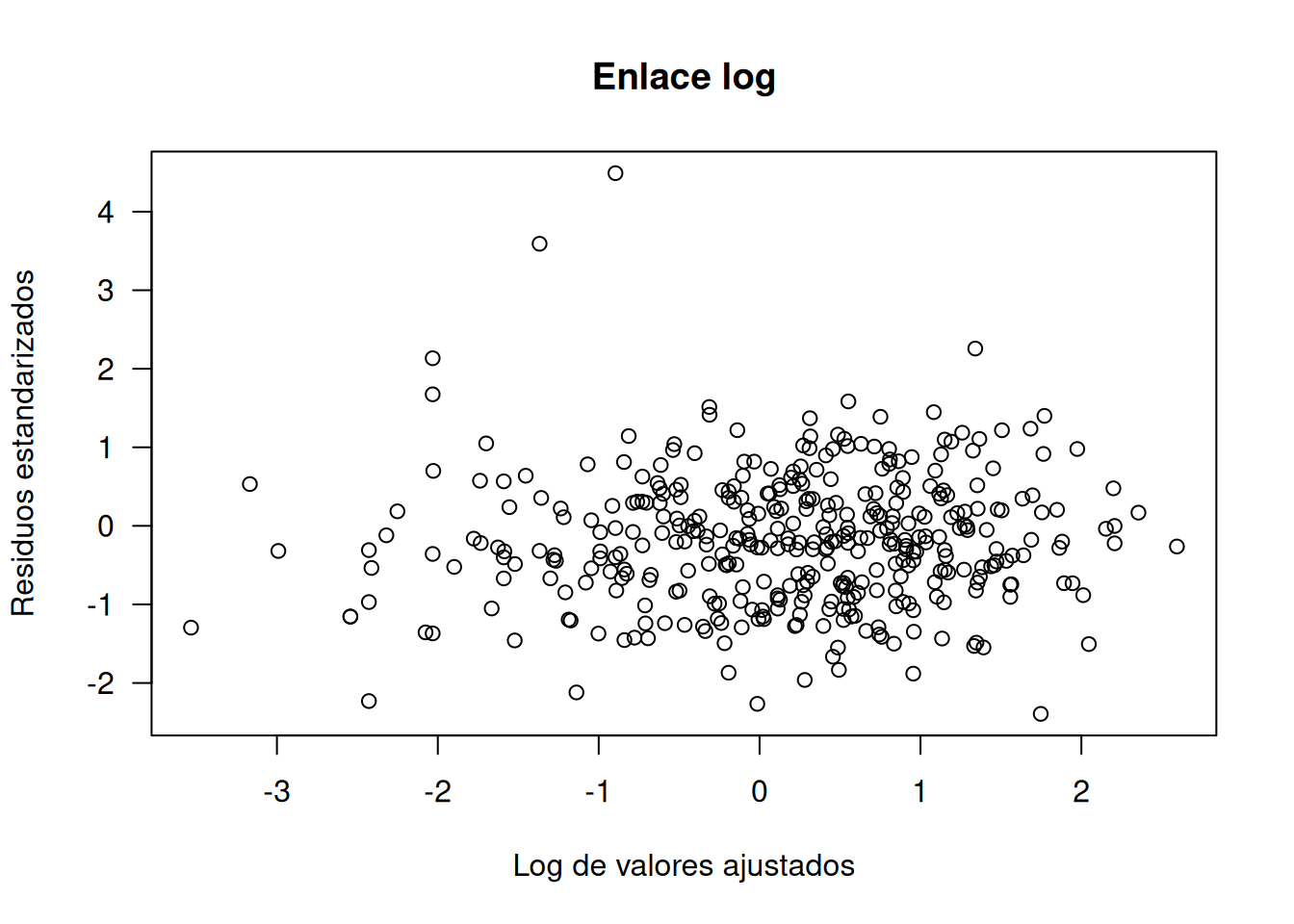
Diagnósticos del modelo log-link, utilizando residuos estandarizados, de trabajo, cuantílicos y distancia de Cook:
library(statmod)# Residuos estandarizados vs. log(valores ajustados)plot(rstandard(lime.log) ~log(fitted(lime.log)),main="Enlace log", las=1,xlab="Log de valores ajustados",ylab="Residuos estandarizados")
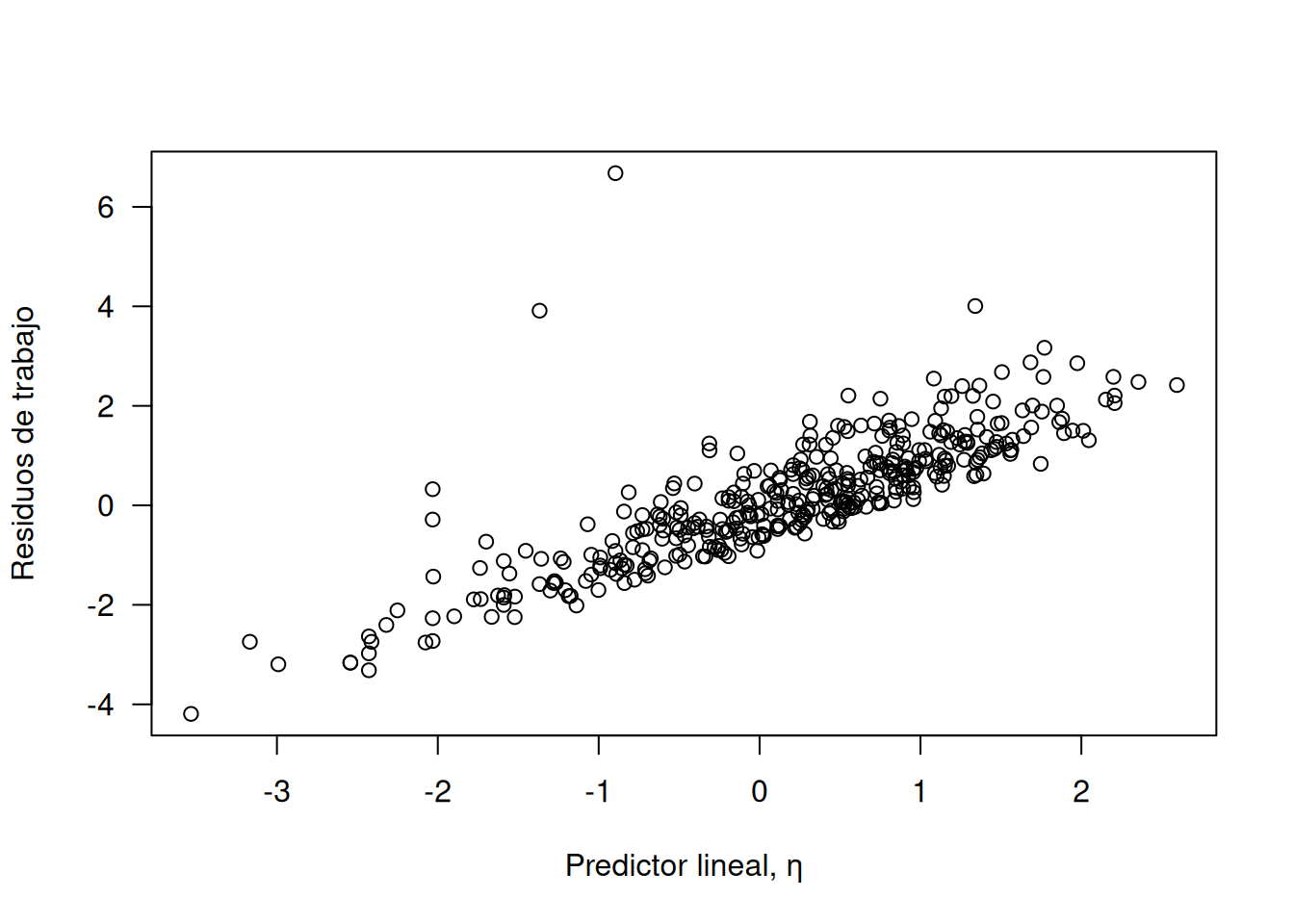
# Residuos de trabajo + predictor lineal vs. predictor linealeta.log <- lime.log$linear.predictorplot(resid(lime.log, type="working") + eta.log ~ eta.log,las=1, ylab="Residuos de trabajo",xlab="Predictor lineal, η")
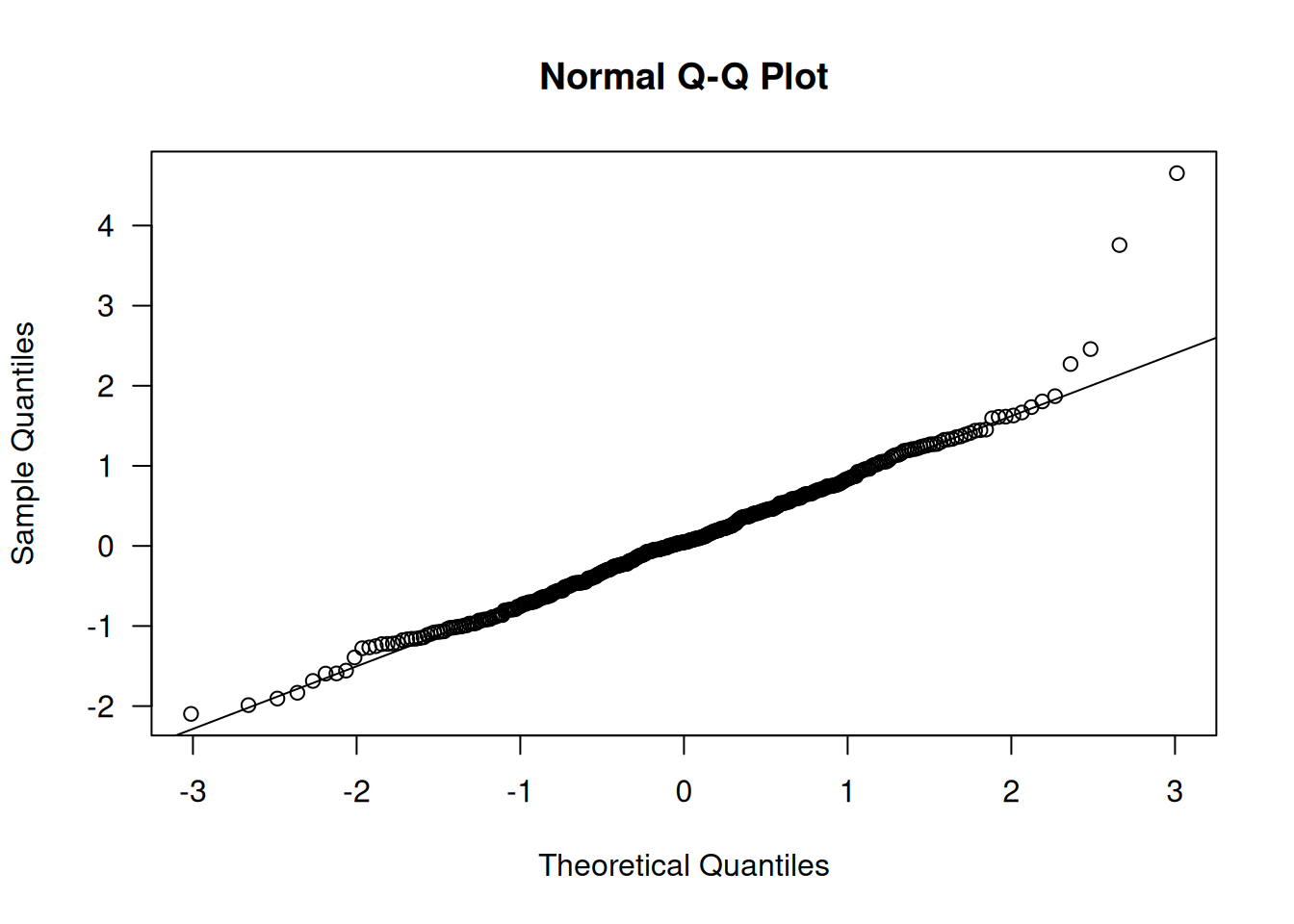
# Q–Q de residuos cuantílicosqqnorm(qr1 <-qresid(lime.log), las=1); qqline(qr1)
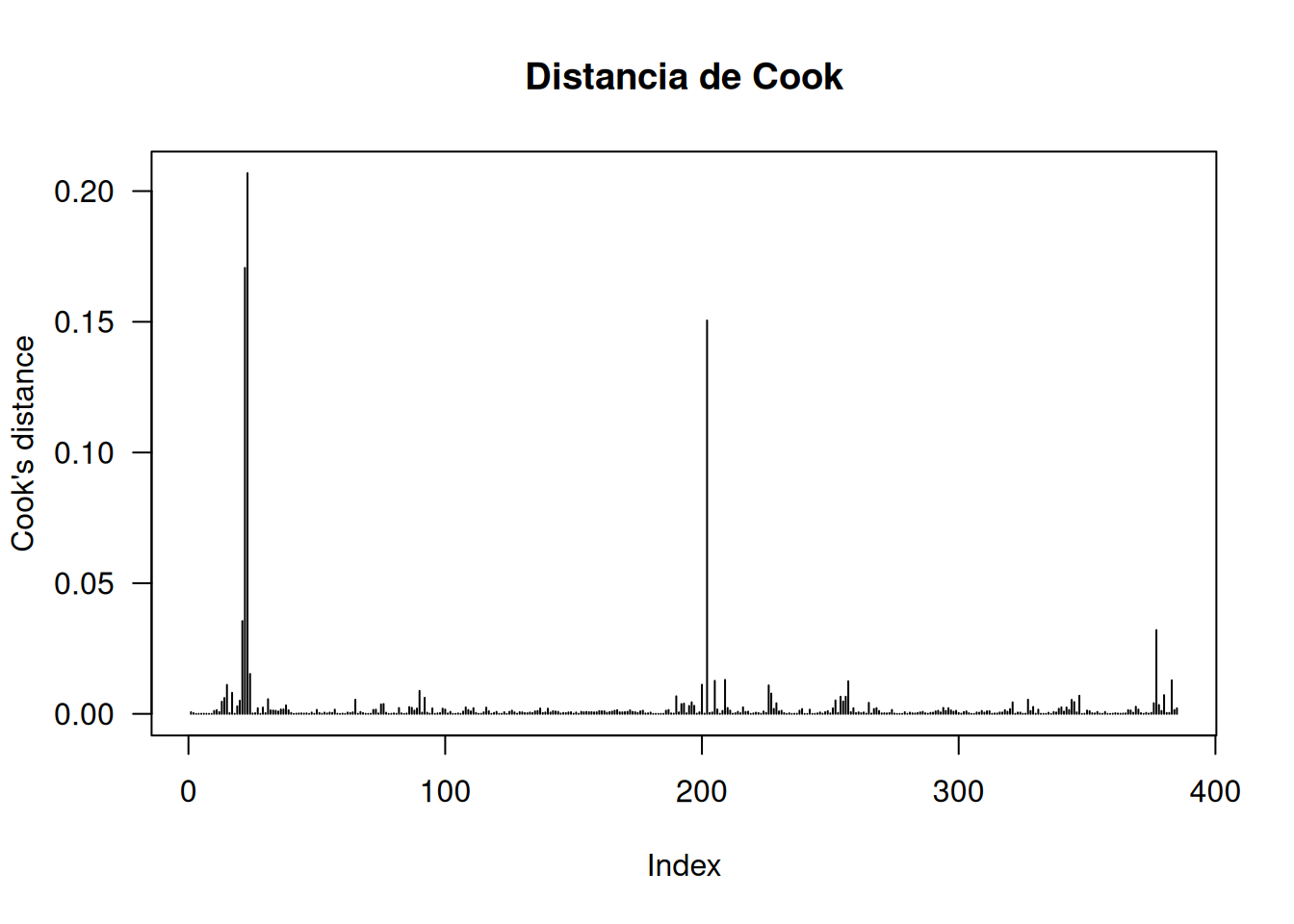
# Distancia de Cookplot(cooks.distance(lime.log), type="h",main="Distancia de Cook",ylab="Cook's distance", las=1)
Aunque aparecen algunos residuos elevados y valores de Cook relativamente altos, ninguna observación resulta influyente según los umbrales estándar. Por tanto, el enlace log se muestra adecuado para este conjunto de datos.
Nota:
No existe un punto de corte universal para la distancia de Cook. Como criterios exploratorios, se suelen revisar observaciones con \(D_i>4/n\) o \(D_i>4/(n-k-1)\). Valores mayores que 1 suelen considerarse evidencia más fuerte de influencia. En todos los casos, estas reglas deben usarse como herramientas diagnósticas y no como criterios automáticos para eliminar observaciones.
10.5 Estimación del parámetro de dispersión
10.5.1 Caso Gamma
En los GLM con Gamma, el parámetro de dispersión \(\phi\) no tiene una estimación de máxima verosimilitud en forma cerrada: debe resolverse numéricamente la ecuación
que arroja valores de \(F\) y \(P<2\times10^{-16}\) para los efectos de Origin, \(\log(\mathrm{DBH})\) y su interacción, tanto usando la estimación de Pearson como la de media de devianza.
En todos los casos, las conclusiones sobre qué términos incluir en el modelo son prácticamente idénticas, confirmando la solidez del procedimiento frente a la elección del estimador de \(\phi\).
10.5.2 Caso Gaussiana Inversa
En los GLM con distribución gaussiana inversa, el estimador de máxima verosimilitud de la dispersión tiene la forma cerrada
siendo \(D(y,\hat\mu)\) la devianza residual y \(n\) el número de observaciones. Como este estimador está sesgado a la baja, se suele preferir el estimador de devianza media
que coincide casi exactamente con el estimador de perfil modificado y resulta prácticamente insesgado cuando los datos tienen buena precisión. De manera análoga al caso Gamma, el estimador de Pearson