4.1 Introducción a los Modelos Lineales Generalizados
Los capítulos 1 y 2 mostraron cómo la regresión lineal clásica descansa sobre la suposición de varianza constante y errores normales. El capítulo 3 evidenció que dichas hipótesis fallan en muchos conjuntos de datos. Para superar esa limitación se recurre a los modelos lineales generalizados (GLM), que amplían el marco de la regresión mediante dos ideas clave:
El componente aleatorio ya no es necesariamente normal: la distribución de las respuestas puede elegirse dentro de una familia más amplia (binomial, Poisson, gamma, etc.), lo que permite adecuar la varianza al comportamiento empírico del dato.
El componente sistemático sigue siendo lineal en los parámetros, pero su efecto sobre la media \(\mu\) se modula mediante una función de enlace apropiada, por ejemplo \(\log \mu=\eta\) o \(\log\{\mu/(1-\mu)\}=\eta\).
4.2 Los dos componentes de un GLM
En cualquier GLM hay que responder a dos preguntas fundamentales.
1. ¿Qué distribución describe mejor la aleatoriedad?
La elección deriva de la propia naturaleza del dato o de la relación observada entre varianza y media. Proporciones sugieren un modelo binomial; conteos, un modelo Poisson; tiempos de espera positivos, un modelo gamma, y así sucesivamente. Esa selección fija el componente aleatorio y controla, por ejemplo, si la varianza es \(\mu(1-\mu)\), \(\mu\) o \(\phi\mu^{2}\).
2. ¿Cómo se relacionan los predictores con la media \(\mu\)?
La respuesta define el componente sistemático. Partiendo del predictor lineal \(\eta=\beta_{0}+\sum_{j=1}^{p}\beta_{j}x_{j}\), se introduce una función de enlace \(g(\mu)=\eta\) que traduce la escala natural de la respuesta a la escala lineal de \(\eta\). Con ello se conserva la interpretabilidad de los coeficientes y se respetan las restricciones inherentes a la media (por ejemplo, \(0<\mu<1\) en datos binomiales).
Elegida la pareja (distribución, enlace), el modelo resultante mantiene las ventajas de la regresión—estimación por máxima verosimilitud, tests de devianza, intervalos asintóticos—pero se ajusta a datos con varianza no constante o distribuciones no normales.
4.3 El componente aleatorio: modelos de dispersión exponencial
Los modelos lineales generalizados se apoyan en una familia de distribuciones –los modelos de dispersión exponencial (EDM)– que cubre la mayor parte de los tipos de datos habituales. Al incluir continuas como la normal o la gamma y discretas como la Poisson, la binomial o la binomial negativa, los EDM permiten tratar, dentro de un mismo marco teórico, respuestas binarias, proporciones, conteos y variables positivas continuas, con o sin ceros exactos.
donde \(\theta\) es el parámetro canónico, \(\kappa(\theta)\) la función cumulante, \(\phi>0\) el parámetro de dispersión y \(a(y,\phi)\) la constante de normalización. Escribimos \(y\sim\text{EDM}(\mu,\phi)\) cuando la media \(\mu\) y la dispersión \(\phi\) caracterizan la distribución. El soporte \(S\) de \(y\) no depende de \(\theta\) ni de \(\phi\), y que el dominio \(\Theta\) de \(\theta\) es abierto y contiene el cero.
4.3.2 Ejemplos clásicos
Ejemplo La función de densidad para la distribución normal con media \(\mu\) y varianza \(\sigma^{2}\) es
Se identifica \(\theta=\mu\) como parámetro canónico, \(\kappa(\theta)=\mu^{2}/2=\theta^{2}/2\) como función cumulante, \(\phi=\sigma^{2}\) como parámetro de dispersión y \(a(y,\phi)=\left(2\pi\sigma^{2}\right)^{-1/2}\exp\!\{-y^{2}/(2\sigma^{2})\}\) como función de normalización. Por lo tanto, la normal pertenece a la familia EDM.
Ejemplo La función de probabilidad de Poisson suele escribirse
lo que muestra que \(\theta=\log\mu\) es el parámetro canónico, \(\kappa(\theta)=\mu\) la función cumulante y \(\phi=1\) la dispersión. La función de normalización es \(a(y,\phi)=1/y!\). Así, la distribución de Poisson también es un EDM.
4.3.3 Función generadora de momentos
Una propiedad fundamental es que el MGF siempre puede escribirse como
para todos los valores de \(t\) para los cuales existe la esperanza. La CGF se utiliza para derivar los cumulantes de una distribución, como la media (primer cumulante, \(\kappa_{1}\)) y la varianza (segundo cumulante, \(\kappa_{2}\)). El \(r\)-ésimo cumulante, \(\kappa_{r}\), es
Para la distribución normal, \(\kappa(\theta)=\theta^{2}/2\), de modo que \(\mathrm{E}[y]=\mathrm{d}\kappa(\theta)/\mathrm{d}\theta=\theta\). Como en la distribución normal se cumple que \(\theta=\mu\), obtenemos \(\mathrm{E}[y]=\theta=\mu\) (tal como se esperaba). Para la varianza se calcula \(V(\mu)=\mathrm{d}^{2}\kappa(\theta)/\mathrm{d}\theta^{2}=1\), y por lo tanto \(\operatorname{var}[y]=\phi V(\mu)=\sigma^{2}\), también como se esperaba.
Para la distribución de Poisson, se tiene \(\kappa(\theta)=\mu\) y \(\theta=\log \mu\). La media es
como era de esperar. Para la función de varianza, \(V(\mu)=\mathrm{d}\mu/\mathrm{d}\theta=\mu\). Dado que \(\phi=1\) para la distribución de Poisson, resulta \(\operatorname{var}[y]=\mu\) para dicha distribución.
Nota: la función de varianza determina la distribución dentro de la clase EDM.
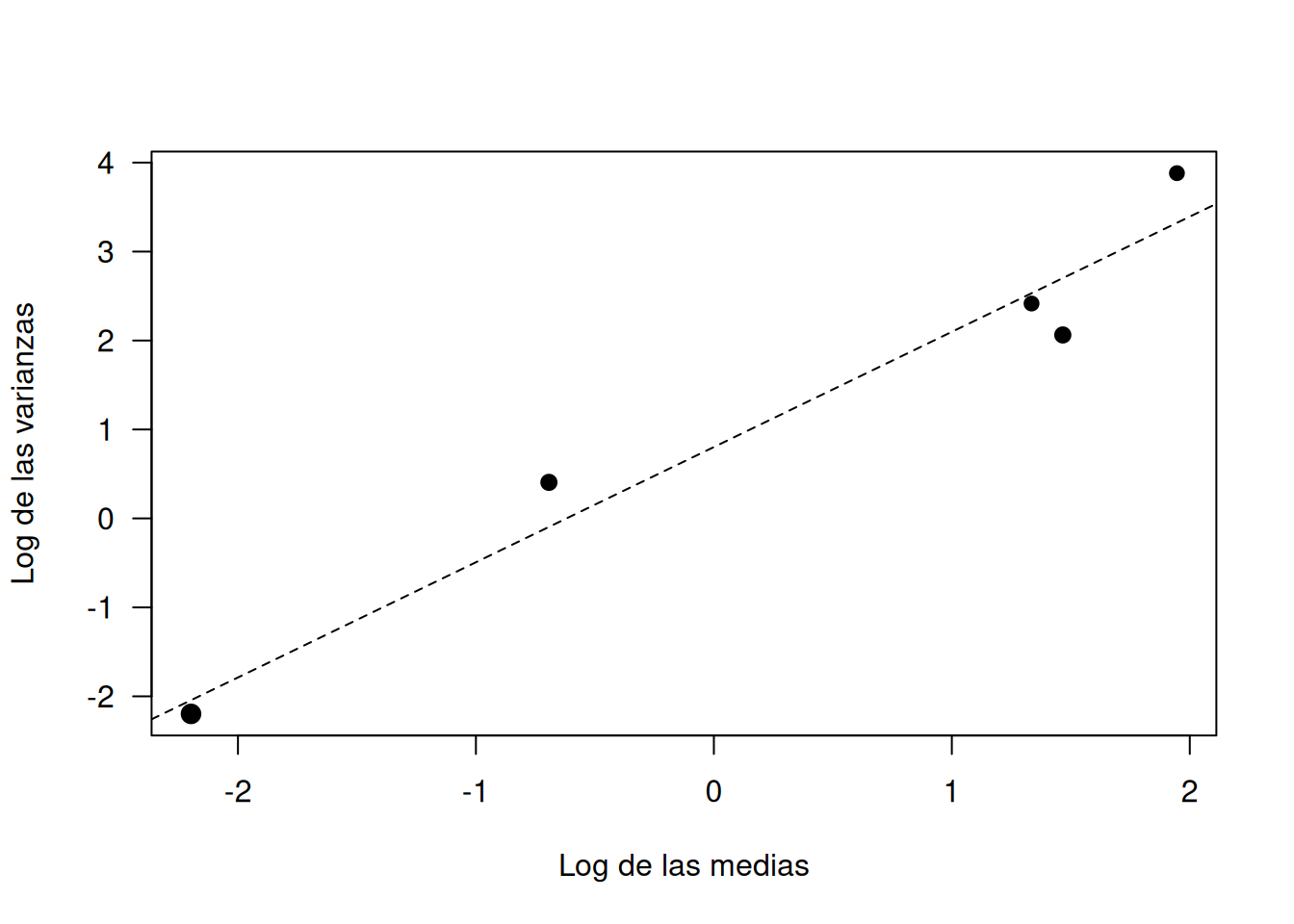
4.3.5 Ejemplo: Inspección empírica de la función de varianza
Para decidir qué distribución de la familia EDM describe mejor los conteos de noisy miners se explora la relación media–varianza. La idea es que, si los datos provienen de una distribución EDM, su varianza debería seguir la forma general \(\operatorname{var}[y]=\phi\,V(\mu)\), donde \(V(\mu)\) caracteriza la distribución (por ejemplo \(V(\mu)=\mu\) en la Poisson).
Se parte de los datos nminer, que registran el número de eucaliptos (\(\text{Eucs}\)) y de noisy miners (\(\text{Minerab}\)). Para obtener estimaciones estables de medias y varianzas se agrupan las observaciones en cinco intervalos aproximadamente iguales de eucaliptos. El siguiente bloque reproduce el cálculo de tamaños, medias y varianzas grupales:
library(GLMsData)data(nminer)# Definimos puntos de corte y asignamos las observaciones a gruposbreaks <-c(-Inf, 4, 11, 15, 19, Inf) +0.5Eucs.cut <-cut(nminer$Eucs, breaks)# Estadísticos por grupomn <-tapply(nminer$Minerab, Eucs.cut, mean) # mediasvr <-tapply(nminer$Minerab, Eucs.cut, var) # varianzassz <-tapply(nminer$Minerab, Eucs.cut, length) # tamañoscbind("Tamaño"= sz, "Media"= mn, "Varianza"= vr)
Con estos resúmenes se construye un gráfico log–log de varianzas vs. medias. Si la relación \(\log(\text{Var}) = a + b\,\log(\text{Media})\) es aproximadamente lineal, la pendiente \(b\) sugiere la forma de \(V(\mu)=\mu^{\,b}\).
plot(log(vr) ~log(mn),pch =19,las =1,cex =0.45*sqrt(sz), # el área refleja el tamaño muestralxlab ="Log de las medias",ylab ="Log de las varianzas")hm.lm <-lm(log(vr) ~log(mn), weights = sz) # ajuste ponderadoabline(hm.lm, lty =2) # recta estimada
El ajuste produce una pendiente \(\hat{b}\approx 1.30\) con intervalo de confianza al 95 % que abarca 1 \((0.82,\;1.77)\). Además, la intersección implica \(\hat{\phi}\approx 1\). En consecuencia, la relación varianza–media es aproximadamente \(\operatorname{var}[y]\simeq\mu\), que coincide con la función de varianza de la distribución Poisson.
4.4 EDM en forma de modelo de dispersión
Al trabajar con distribuciones de la familia EDM resulta útil re-expresar la densidad en función de la media \(\mu\) en lugar del parámetro canónico \(\theta\). Dado que \(\mu\) y \(\theta\) son funciones uno-a-uno, podemos aislar la parte de la densidad que depende de \(\theta\) mediante \[
t(y,\mu)=y\,\theta-\kappa(\theta).
\] Si derivamos respecto a \(\theta\) obtenemos \(\partial t/\partial\theta = y-\mu\) y una segunda derivada \(\partial^{2}t/\partial\theta^{2}=-V(\mu)<0\). Por tanto, \(t(y,\mu)\) alcanza un máximo único en \(\mu=y\).
Ese hecho motiva la devianza unitaria \[
d(y,\mu)=2\{t(y,y)-t(y,\mu)\},
\] una medida de distancia que se anula sólo cuando \(y=\mu\) y crece simétricamente al alejarse de esa igualdad. Con ella, toda EDM adopta la forma de modelo de dispersión \[
\mathcal{P}(y;\mu,\phi)=b(y,\phi)\,\exp\!\Bigl\{-\frac{1}{2\phi}\,d(y,\mu)\Bigr\}, \tag{5.13}
\] donde \(b(y,\phi)=a(y,\phi)\exp\{t(y,y)/\phi\}\) asegura la normalización. Esta parametrización es ventajosa porque:
Expresa la densidad usando la media —cantidad con interpretación directa en regresión— y el parámetro de dispersión \(\phi\).
La devianza unitaria \(d(y,\mu)\) servirá más adelante para definir la devianza del modelo y construir contrastes de bondad de ajuste.
Facilita la derivación de estimadores y de intervalos, pues separa la parte “informativa” \(\exp\{-d(y,\mu)/(2\phi)\}\) de la parte puramente normativa \(b(y,\phi)\).
En práctica, conocer \(d(y,\mu)\) permite comparar observaciones con sus medias modeladas y, por tanto, evaluar la adecuación del modelo GLM sin depender de transformaciones ad hoc.
4.4.1 Ejemplos de devianza unitaria
Para la distribución normal con media \(\mu\) y varianza \(\sigma^{2}\) se obtiene \(t(y,\mu)=y\mu-\mu^{2}/2\) y, al evaluar en \(\mu=y\), \(t(y,y)=y^{2}/2\). Consecuentemente, la devianza unitaria es simplemente \[
d(y,\mu)=(y-\mu)^{2},
\] de modo que la densidad normal clásica ya está en forma de modelo de dispersión.
Este razonamiento parte de que siempre podemos igualar \(\mu\) a \(y\). Sin embargo, cuando \(y\) se halla en el borde del soporte —por ejemplo, \(y=0\) o \(y=1\) en la distribución binomial, donde \(0<\mu<1\)— tal sustitución no se puede realizar. La solución consiste en definir \[
d(y,\mu)=2\Bigl\{\lim_{\varepsilon\to 0} t(y+\varepsilon,y+\varepsilon)-t(y,\mu)\Bigr\},
\] tomando el límite por la derecha si el borde es inferior y por la izquierda si es superior. Con esta versión la devianza unitaria queda bien definida para todas las EDM tratadas en el libro, aunque en la notación cotidiana se sigue utilizando la forma más simple (5.12) con el entendimiento de que (5.14) se aplica cuando hace falta.
En la distribución Poisson, donde \(\mu>0\), se deduce \(t(y,\mu)=y\log\mu-\mu\). Para \(y\neq 0\) la devianza unitaria resulta \[
d(y,\mu)=2\left\{y\log\frac{y}{\mu}-(y-\mu)\right\},
\] mientras que para el caso frontera \(y=0\) se emplea la definición límite y se obtiene \[
d(0,\mu)=2\mu. \tag{5.16}
\] Así, la forma (5.15) se usa de manera rutinaria recordando que, si aparece un recuento cero, se sustituye por su límite dado en (5.16). En la formulación de dispersión la Poisson mantiene \(\phi=1\) y un término normalizador \(b(y)= (y\log y-y)/y!\), confirmando que su varianza se controla únicamente mediante la media.
4.5 La aproximación saddlepoint
La aproximación saddlepoint ofrece una formulación analítica sencilla y sorprendentemente precisa para la densidad de una EDM. A partir de la devianza unitaria y de la función varianza, la densidad exacta \(\mathcal{P}(y;\mu,\phi)\) se sustituye por
Esta expresión guarda la misma forma exponencial de la representación en modelo de dispersión, pero reemplaza el complejo término de normalización \(b(y,\phi)\) por la sencilla fracción \(1/\sqrt{2\pi\phi V(y)}\).
4.5.0.1 Ejemplos ilustrativos
Para la distribución normal \(V(\mu)=1\), así que \(V(y)=1\) y la aproximación reproduce exactamente su densidad; el saddlepoint es, en este caso, la distribución normal misma. En cambio, para la Poisson donde \(V(\mu)=\mu\), se obtiene
La aproximación saddlepoint tiene una consecuencia importante. Si dicha aproximación a la función de probabilidad de una EDM es precisa, entonces la desviancia unitaria \(d(y,\mu)\) sigue una distribución \(\chi_{1}^{2}\).
Para demostrarlo usamos el hecho de que la distribución \(\chi_{1}^{2}\) queda determinada por su función generadora de momentos (MGF). Considere una variable aleatoria \(y\) cuya función de probabilidad sea una EDM. Si la aproximación saddlepoint resulta exacta, la MGF de la desviancia unitaria es
pues el integrando es justamente la densidad (saddlepoint) correspondiente al parámetro \(\phi'\). La MGF anterior identifica una distribución \(\chi_{1}^{2}\), lo que demuestra que
\[
d(y,\mu)\big/\phi \;\sim\; \chi_{1}^{2}
\]
siempre que la aproximación saddlepoint sea adecuada. Este resultado sustenta otros resultados posteriores de teoría y además implica que \(\mathrm{E}\,[d(y,\mu)]=\phi\).
4.6 El componente sistemático
4.6.1 Función de enlace
En un GLM la parte determinista se expresa mediante el predictor lineal \[\eta=\beta_{0}+\sum_{j=1}^{p}\beta_{j}x_{j},\]
al que se conecta la media de la respuesta a través de una función de enlace \(g(\cdot)\), de modo que \(g(\mu)=\eta\). Al ser monótona y diferenciable, esta función garantiza que cada valor real de \(\eta\) corresponde a un único valor admisible de \(\mu\) y, a la vez, hace posible la estimación por métodos de máxima verosimilitud.
Una elección especialmente cómoda es el enlace canónico, aquel que iguala el predictor a su parámetro canónico, \(\eta=\theta=g(\mu)\). Por ejemplo, en la distribución normal se tiene \(\theta=\mu\), por lo que el enlace canónico es la identidad; en la distribución de Poisson, \(\theta=\log\mu\) y el enlace canónico es el logaritmo, lo que asegura \(\mu>0\) para cualquier \(\eta\) real. El uso del enlace canónico suele simplificar las ecuaciones de estimación y proporciona interpretaciones directas en términos del parámetro natural.
4.6.2 Términos offset
Con frecuencia el predictor incluye componentes cuyo coeficiente es conocido de antemano; dichos términos se denominan offsets. Supóngase que se modela el número anual de nacimientos en varias ciudades. El conteo \(y_i\) puede considerarse Poisson, pero la media \(\mu_i\) ha de reflejar la población \(P_i\) de cada ciudad, pues una urbe más poblada naturalmente registra más nacimientos. Al modelar la tasa de nacimientos por habitante, la relación \[\log(\mu_i/P_i)=\eta_i\]
implica que la ecuación para \(\mu_i\) adopta la forma \[\log\mu_i=\log P_i+\eta_i,\]
donde \(\log P_i\) actúa como offset: su valor es fijo, no requiere estimación y cuantifica la exposición al fenómeno (en este caso, el tamaño poblacional).
El concepto se generaliza. En estudios de incidencia de enfermedades, la exposición puede ser el número de persona-años trabajados, incorporándose igualmente como offset. Otro ejemplo procede de los datos de los cerezos: al aproximar cada árbol por un cono o un cilindro se llega al modelo \[\log\mu=\beta_0+2\log g+\log h,\]
siendo \(g\) la circunferencia y \(h\) la altura. El término \(2\log g+\log h\) es nuevamente un offset; todo lo que resta por estimar recae en \(\beta_{0}\), interpretado aquí como un factor de forma que distingue entre las dos geometrías.
En síntesis, los offsets permiten ajustar diferencias de escala o exposición sin inflar el número de parámetros, manteniendo la linealidad del predictor y facilitando una interpretación clara del resto de las covariables.
4.7 Modelos lineales generalizados (definición)
Un modelo lineal generalizado se construye combinando las dos piezas vistas hasta aquí.
Primero se fija el componente aleatorio: cada observación \(y_i\) se supone independiente y perteneciente a una distribución de la familia EDM, \[y_i\sim \operatorname{EDM}\bigl(\mu_i,\ \phi/w_i\bigr),\] donde \(\phi\) es el parámetro de dispersión común y \(w_i\ge 0\) son pesos priori que, salvo necesidad específica, suelen tomarse iguales a 1.
En segundo lugar se establece el componente sistemático: la media \(\mu_i\) se conecta con los predictores mediante una función de enlace \(g(\cdot)\), \[g(\mu_i)=o_i+\beta_{0}+\sum_{j=1}^{p}\beta_{j}x_{ji},\] donde \(o_i\) representa un offset conocido que ajusta la exposición de la observación.
Las dos expresiones se condensan en el esquema formal
Así, especificar un GLM equivale a responder dos preguntas fundamentales: ¿qué distribución EDM describe mejor la variabilidad de los datos? y ¿qué enlace establece una relación adecuada entre la media y los covariables? Para abreviar se escribe \[
\text{GLM(EDM; enlace)}
\]
indicando con claridad las dos elecciones esenciales.
4.7.1 Ejemplo ilustrativo
En la serie de precipitaciones de Quilpie se estudia si la media mensual de lluvia excede un umbral. Cada respuesta es binaria, de forma que el modelo propuesto es
donde \(x_i\) es el índice SOI y \(y_i=1\) si en julio se superan \(10\) mm. Este planteamiento se describe como GLM(binomial; logit), y en R se invoca mediante
glm(y ~ x, family =binomial(link ="logit"), data = datos)
4.8 La devianza total
Tras ver que la devianza unitaria\(d(y,\mu)\) mide cuán lejos está cada observación de su media teórica, es natural sumar esas distancias para evaluar el ajuste global de un modelo. Así se define la devianza total
incorpora la dispersión \(\phi\) y las ponderaciones \(w_i\). Cuando la aproximación saddlepoint resulta precisa ‒y lo es exactamente en modelos normales‒ la devianza escalada se distribuye como \(\chi_n^{2}\) al evaluarla en los valores verdaderos de \(\mu_i\) y \(\phi\). Este hecho provee la base teórica para pruebas de bondad de ajuste que se desarrollarán más adelante; en la práctica, claro está, se reemplazan las medias reales por sus estimaciones.
La devianza aparece de forma inmediata al reescribir la log-verosimilitud de un GLM en la forma de dispersión. Para el modelo
de modo que maximizar la verosimilitud equivale a minimizar la devianza total; la devianza generaliza así la suma de cuadrados residuales de la regresión lineal.
4.8.1 Ejemplo ilustrativo
En un GLM normal \(y_i\sim N(\mu_i,\sigma^{2})\) la devianza es
\[
D(y,\mu)=\sum_{i=1}^{n}(y_i-\mu_i)^{2},
\]
justo la suma de cuadrados residuales clásica. La versión escalada
sigue exactamente una \(\chi_n^{2}\), lo que confirma que la devianza actúa como estadístico de bondad de ajuste y, por extensión, respalda su uso en toda la familia de GLM cuando el número de observaciones es grande.
4.9 Transformaciones de regresión y su relación con los GLM
Al igual que en capítulos anteriores, una forma clásica de afrontar varianzas no constantes en regresiones lineales consiste en transformar la respuesta hasta «estabilizar» su dispersión. Sea \(y^{*}=h(y)\) una transformación diferenciable; un desarrollo de Taylor alrededor de la media \(\mu\) muestra que \(\operatorname{var}[y^{*}]\approx h'(\mu)^{2}\operatorname{var}[y]\). Por tanto, la varianza será aproximadamente constante si \(h'(\mu)\) es proporcional a \(\operatorname{var}[y]^{-1/2}\), es decir, a \(V(\mu)^{-1/2}\) donde \(V(\mu)\) denota la verdadera relación media–varianza del proceso.
Esa observación enlaza directamente con los modelos lineales generalizados. Usar la transformación \(h(y)\) dentro de una regresión lineal equivale, de manera aproximada, a ajustar un GLM cuya familia de distribución viene determinada por \(V(\mu)=1/h'(\mu)^{2}\) y cuyo enlace natural sería \(g(\mu)=h(\mu)\).
Distribuciones EDM y transformaciones que estabilizan la varianza usadas en regresión lineal
Transformación estabilizadora de varianza (Box-Cox \(\lambda\))
GLM aproximado
Función de varianza
Función de enlace
\(y^{*}=\sin^{-1}\!\sqrt{y}\)
Binomial
\(V(\mu)=\mu(1-\mu)\)
\(g(\mu)=\sin^{-1}\!\sqrt{\mu}\)
\(y^{*}=\sqrt{y}\;(\lambda=1/2)\)
Poisson
\(V(\mu)=\mu\)
\(g(\mu)=\sqrt{\mu}\)
\(y^{*}=\log y\;(\lambda=0)\)
Gamma
\(V(\mu)=\mu^{2}\)
\(g(\mu)=\log\mu\)
\(y^{*}=1/\sqrt{y}\;(\lambda=-\tfrac12)\)
Inversa gaussiana
\(V(\mu)=\mu^{3}\)
\(g(\mu)=1/\sqrt{\mu}\)
Según lo anterior, la raíz cuadrada aproxima un GLM de Poisson con enlace \(\sqrt{\mu}\), mientras que el logaritmo conduce a un GLM gamma con enlace log. Así, toda transformación que estabiliza la varianza define implícitamente tanto la función de varianza como la función de enlace de un GLM.
Sin embargo, confiar en una única transformación obliga a aceptar la relación fija entre \(V(\mu)\) y \(g(\mu)\) que dicha transformación impone, lo cual rara vez refleja la complejidad real de los datos. El marco de los GLM ofrece mayor flexibilidad: primero se selecciona la familia EDM según la naturaleza y la dispersión observada (binomial para proporciones, Poisson para conteos, gamma para continuas positivas, etc.); después se elige un enlace que proporcione linealidad en los parámetros. Además, los GLM modelizan la respuesta en su escala original, evitan interpretaciones sobre variables transformadas y generan inferencias probabilísticas coherentes cuando la normalidad no es razonable.