3Más Allá de la Regresión Lineal – El Método de Máxima Verosimilitud
3.1 Introducción y Visión General
El modelo de regresión lineal presentado anteriormente asume que la varianza es constante, y frecuentemente que los errores se distribuyen de forma normal.
Sin embargo, existen muchos tipos de datos para los cuales la aleatoriedad no es constante, lo que hace que el método de mínimos cuadrados no sea apropiado.
En estos casos, se requiere el uso de la estimación de máxima verosimilitud para ajustar el modelo.
3.2 La Necesidad de Modelos de Regresión No Normales
Anteriormente se introdujo el modelo de regresión lineal, que asume que la varianza es constante (homocedasticidad) y, a menudo, que los errores siguen una distribución normal. Sin embargo, existen muchos tipos de datos en los que la variabilidad no es constante, por lo que el método de mínimos cuadrados no es adecuado. En estos casos es preferible usar la estimación de máxima verosimilitud para ajustar el modelo.
3.3 Cuando los Modelos Lineales Son una Mala Elección
El componente aleatorio de los modelos de regresión en capítulos anteriores asume varianza constante y normalidad.
Existen tres situaciones comunes en las que la variación no es constante y, por ello, los modelos lineales no son adecuados:
Proporciones:
La respuesta es una proporción (entre 0 y 1) de un total de conteos.
A medida que la proporción se acerca a 0 o 1, la varianza debe acercarse a 0, siendo menor en los extremos que en valores cercanos a 0.5.
Además, al estar acotada, la respuesta no puede ser modelada con una distribución normal.
Ejemplo: Datos binarios, donde la respuesta es 0 o 1.
Conteos:
La respuesta es un conteo.
A medida que el conteo se acerca a 0, la varianza también se reduce.
Los conteos son discretos y no negativos, por lo que la normalidad es inapropiada.
Se suele usar la distribución de Poisson (o la binomial negativa en caso de sobredispersión).
Datos Continuos Positivos:
La respuesta es continua y estrictamente positiva.
Cerca de 0, la varianza es menor; además, estos datos suelen presentar asimetría positiva (right-skewed).
La normalidad es inadecuada ya que la distribución normal permite valores negativos.
Se pueden usar distribuciones como la gamma o la inversa gaussiana.
En todas estas situaciones, la relación entre \(y\) y las variables explicativas suele ser no lineal, ya que \(y\) está acotado.
3.3.1 Resultados Binarios y Conteos Binomiales
Cuando la respuesta es binaria (por ejemplo, éxito/fallo), no tiene sentido transformar la variable para lograr normalidad, ya que sólo puede tomar dos valores.
En el caso de que se tabulen múltiples resultados binarios para formar una variable binomial, se puede modelar la proporción \(y\) de éxitos de un total de \(m\).
Por ejemplo, se puede utilizar un modelo de la forma: \[
\log \frac{\mu}{1-\mu} = \beta_0 + \beta_1 x,
\] donde \(\mu\) es la probabilidad de éxito y la transformación logit extiende la escala a toda la recta real.
Ejemplo: El estudio de pilotos militares que evalúa si la resistencia al desmayo disminuye con la edad (datos de gforces).
3.3.2 Conteos Sin Restricción: Modelos de Poisson o Binomial Negativa
Cuando la respuesta es un conteo (número de eventos), la varianza no es constante y además los datos son discretos.
Un modelo de regresión lineal normal no es adecuado.
Se puede modelar la respuesta con una distribución de Poisson, usando un modelo de la forma: \[
\begin{cases}
y \sim \operatorname{Pois}(\mu) & \text{(componente aleatoria)} \\
\log \mu = \beta_0 + \beta_1 x & \text{(componente sistemática)}
\end{cases} \tag{4.2}
\]
Ejemplo: El estudio de hábitats de un pájaro agresivo (noisy miner nminer), donde se cuenta el número de pájaros en relación al número de eucaliptos.
3.3.3 Observaciones Continuas Positivas
Cuando la respuesta es continua y positiva (por ejemplo, tiempos de entrega), es común que la varianza aumente con la media.
Una transformación logarítmica puede estabilizar la varianza, pero a menudo transforma la relación lineal en algo no lineal.
En estos casos, el modelo de regresión lineal normal no es capaz de satisfacer ambos objetivos (linealidad y varianza constante).
Es preferible usar un modelo de regresión que ajuste la distribución apropiada para números positivos, como la distribución gamma o la inversa gaussiana.
Un posible modelo es: \[
\begin{cases}
y \sim \operatorname{Gamma}(\mu; \phi) & \text{(componente aleatoria)} \\
\mu = \beta_0 + \beta_1 x & \text{(componente sistemática)}
\end{cases} \tag{4.3}
\] donde \(\phi\) está relacionado con la varianza de la distribución gamma.
Ejemplo: Un estudio de un embotellador de bebidas que analiza el tiempo de servicio de las máquinas expendedoras en función del número de cajas de producto y la distancia recorrida (sdrink).
3.4 La Idea de la Estimación de Máxima Verosimilitud
Anteriormente se desarrolló el principio de los mínimos cuadrados como criterio para estimar los parámetros en el predictor lineal de los modelos de regresión lineal. Este método es adecuado cuando los datos de respuesta se distribuyen aproximadamente de forma normal. Sin embargo, en situaciones en las que los datos no son normales (por ejemplo, modelos basados en distribuciones binomial, Poisson o gamma), se requiere una metodología de estimación más general: la estimación de máxima verosimilitud.
3.4.1 Concepto General
La máxima verosimilitud consiste en elegir los estimadores de los parámetros desconocidos que maximizan la función de verosimilitud, es decir, la función de densidad o probabilidad de los datos observados, considerada como función de los parámetros. Esta metodología incluye los mínimos cuadrados como un caso especial (cuando los errores son normales).
3.4.2 Ejemplo con la Distribución Exponencial
Supongamos que \(y_1,\dots,y_n\) son observaciones independientes de una distribución exponencial con parámetro de escala \(\theta\). La función de densidad de la distribución exponencial es: \[
\mathcal{P}(y;\theta)=\theta\exp(-\theta y).
\]
La función de verosimilitud conjunta para los \(n\) datos es: \[
\mathcal{L}(\theta;y)=\prod_{i=1}^{n}\mathcal{P}(y_i;\theta)=\theta^n\exp\Big(-\theta\sum_{i=1}^{n}y_i\Big)=\theta^n\exp(-n\bar{y}\theta),
\] donde \(\bar{y}\) es la media aritmética de los \(y_i\).
El principio de máxima verosimilitud consiste en elegir el valor \(\hat{\theta}\) que maximice \(\mathcal{L}(\theta;y)\). Es fácil demostrar que en este caso la función se maximiza cuando: \[
\hat{\theta}=\frac{1}{\bar{y}}.
\]
3.4.3 La Función Log-Verosimilitud
En la práctica es más conveniente trabajar con la función logarítmica de la verosimilitud, ya que la transformación logarítmica convierte productos en sumas: \[
\ell(\theta;y)=\log \mathcal{L}(\theta;y)=\sum_{i=1}^{n}\log \mathcal{P}(y_i;\theta).
\] Para el ejemplo exponencial, el log-verosimilitud es: \[
\ell(\theta;y)=n(\log \theta-\bar{y}\theta).
\] Maximizar \(\ell(\theta;y)\) es equivalente a maximizar \(\mathcal{L}(\theta;y)\).
3.4.4 Relación con los Mínimos Cuadrados
Se puede demostrar que los mínimos cuadrados son un caso especial de la máxima verosimilitud. Por ejemplo, considere un modelo de regresión normal: \[
y_i\sim N(\mu_i,\sigma^2),\quad \mu_i=\beta_0+\beta_1 x_{1i}+\cdots+\beta_p x_{pi}.
\] La función de densidad para \(y_i\) es: \[
\mathcal{P}(y_i;\mu_i,\sigma^2)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp\Biggl\{-\frac{(y_i-\mu_i)^2}{2\sigma^2}\Biggr\}.
\] El logaritmo de esta función es: \[
\log \mathcal{P}(y_i;\mu_i,\sigma^2)=-\frac{1}{2}\log(2\pi\sigma^2)-\frac{(y_i-\mu_i)^2}{2\sigma^2}.
\] Así, la log-verosimilitud para los \(n\) datos es: \[
\ell\bigl(\beta_0,\dots,\beta_p,\sigma^2;y\bigr)
=-\frac{n}{2}\log(2\pi\sigma^2)-\frac{1}{2\sigma^2}\sum_{i=1}^{n}(y_i-\mu_i)^2,
\] donde el término \(\sum_{i=1}^{n}(y_i-\mu_i)^2\) es la suma de cuadrados (RSS). Para un valor fijo de \(\sigma^2\), maximizar la log-verosimilitud equivale a minimizar la RSS, lo que demuestra que los mínimos cuadrados son equivalentes a la estimación de máxima verosimilitud cuando se asume normalidad.
3.4.5 Ejemplo : Lluvia en Quilpie y Estimación de Máxima Verosimilitud
En este ejemplo se registra la cantidad total de lluvia de julio (en milímetros) en Quilpie, Australia, junto con el valor del índice de oscilación del sur (SOI) mensual. El SOI es la diferencia estandarizada entre las presiones de aire en Darwin y Tahiti y se ha relacionado con la lluvia en partes de Australia. Algunos agricultores pueden retrasar la siembra hasta que se supere un cierto umbral de lluvia dentro de un periodo (una “ventana de lluvia”).
Para modelar este fenómeno, se define la variable respuesta \(y\) de la siguiente forma: \[
y =
\begin{cases}
1 & \text{si la lluvia total de julio excede 10 mm}, \\
0 & \text{en caso contrario.}
\end{cases}
\]
El parámetro desconocido es la probabilidad de que la lluvia supere los 10 mm, que denotamos por \(\mu\) (ya que \(E[y] = \mu = \Pr(y=1)\)). Por el momento se ignora el efecto del SOI y se considera que todas las observaciones son equivalentes.
La función de probabilidad de \(y\) se define como: \[
\mathcal{P}(y;\mu) = \mu^y (1-\mu)^{1-y},
\] para \(y = 0\) o \(1\). Esta es la distribución Bernoulli con probabilidad \(\mu\). En R, la función dbinom() evalúa esta función de probabilidad; fijando size=1, la distribución binomial se reduce a la distribución Bernoulli.
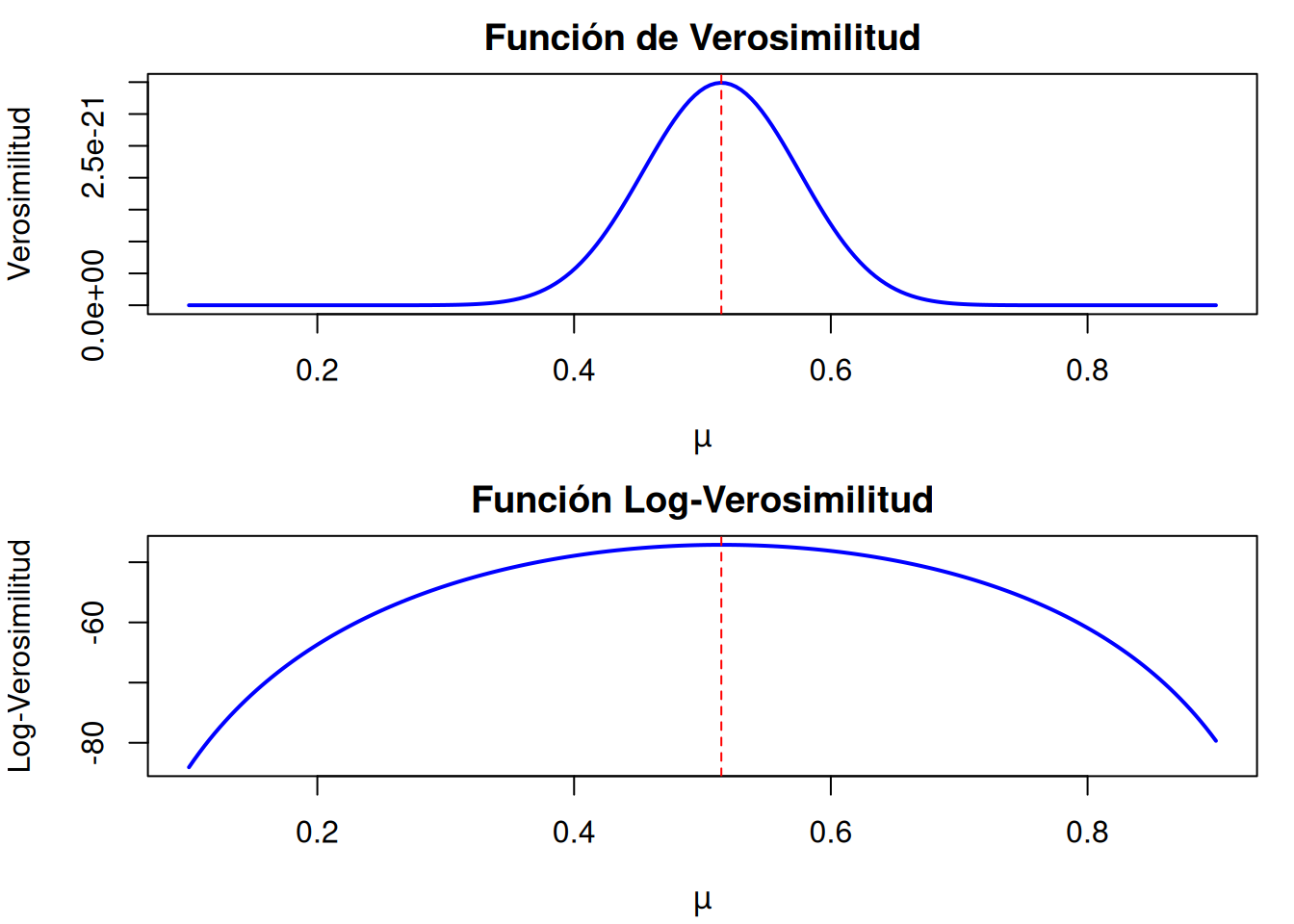
Se evalúa el log-verosimilitud para algunos valores candidatos de \(\mu\), lo que muestra que el estimador de máxima verosimilitud (MLE) de \(\mu\) se encuentra cerca de 0.5. El código empleado es el siguiente:
library(GLMsData)data(quilpie); names(quilpie)
[1] "Year" "Rain" "SOI" "Phase" "Exceed" "y"
mu <-c(0.2, 0.4, 0.5, 0.6, 0.8) # Valores candidatos para mull <-rep(0, 5) # Vector para guardar los log-verosimilitudesfor (i in1:5){ ll[i] <-sum(dbinom(quilpie$y, size=1, prob=mu[i], log=TRUE))}data.frame(Mu = mu, LogLikelihood = ll)
# Generar una secuencia de valores candidatos para mu (por ejemplo, de 0.1 a 0.9)mu_vals <-seq(0.1, 0.9, length.out =200)# Calcular la función de log-verosimilitud para cada valor de mull_vals <-sapply(mu_vals, function(mu) sum(dbinom(quilpie$y, size =1, prob = mu, log =TRUE)))# Convertir el log-verosimilitud a verosimilitud (exponenciando)likelihood_vals <-exp(ll_vals)# Graficar la función de verosimilitud y el log-verosimilitud en paneles separadospar(mfrow =c(2, 1), mar =c(4, 4, 2, 1)) # Configurar dos paneles verticales# Panel superior: Gráfico de la función de verosimilitudplot(mu_vals, likelihood_vals, type ="l", lwd =2, col ="blue",xlab =expression(mu), ylab ="Verosimilitud",main ="Función de Verosimilitud")abline(v =0.5147, lty =2, col ="red") # Línea vertical en el MLE# Panel inferior: Gráfico de la función log-verosimilitudplot(mu_vals, ll_vals, type ="l", lwd =2, col ="blue",xlab =expression(mu), ylab ="Log-Verosimilitud",main ="Función Log-Verosimilitud")abline(v =0.5147, lty =2, col ="red") # Línea vertical en el MLE
# Restablecer la distribución de los gráficos a una sola figura (opcional)par(mfrow =c(1, 1))
La figura anterior muestra el gráfico de la función de verosimilitud (panel superior) y el log-verosimilitud (panel inferior) para un rango mayor de valores de \(\mu\). Visualmente, el MLE de \(\mu\) aparece justo por encima de 0.5, y se señala una línea vertical en \(\hat{\mu} = 0.5147\).
3.5 Máxima Verosimilitud para Estimar un Parámetro
En esta sección se desarrolla un enfoque sistemático para maximizar el log-verosimilitud usando cálculo, y se introduce el concepto de score.
3.5.1 Ecuaciones de Score
Se define la función score como la derivada del log-verosimilitud con respecto al parámetro a estimar, digamos \(\zeta\): \[
U(\zeta)=\frac{d\ell(\zeta;y)}{d\zeta}.
\]
La ecuación que se resuelve para obtener el estimador de máxima verosimilitud (MLE) es: \[
U(\hat{\zeta})=0.
\]
Dado que los log-verosimilitudes que consideramos son unimodales y diferenciables, resolver la ecuación de score garantiza obtener el máximo global.
Además, la función score tiene la propiedad importante de que su esperanza es cero cuando se evalúa en el valor real del parámetro, es decir, \(E[U(\zeta)] = 0\).
3.5.1.1 Modelo Bernoulli
Para un modelo Bernoulli con probabilidad \(\mu\), la función de probabilidad es: \[
\mathcal{P}(y;\mu)=\mu^y (1-\mu)^{1-y},
\] y su log-verosimilitud para una observación es: \[
\log \mathcal{P}(y;\mu)=y\log\mu+(1-y)\log(1-\mu).
\]
La derivada con respecto a \(\mu\) es: \[
\frac{d\log \mathcal{P}(y;\mu)}{d\mu}=\frac{y-\mu}{\mu(1-\mu)}.
\]
Para \(n\) observaciones, la función score es: \[
U(\mu)=\frac{d\ell(\mu;y)}{d\mu}=\sum_{i=1}^n\frac{y_i-\mu}{\mu(1-\mu)}
=\frac{n(\bar{y}-\mu)}{\mu(1-\mu)}.
\]
Al resolver \(U(\hat{\mu})=0\), se obtiene que \(\hat{\mu}=\bar{y}\), es decir, la MLE de \(\mu\) es la media muestral.
3.5.2 Información: Observada y Esperada
Se define la información observada como: \[
\mathcal{J}(\zeta)=-\frac{d^2\ell(\zeta;y)}{d\zeta^2}=-\frac{dU(\zeta)}{d\zeta}.
\]
La información esperada (o Fisher information) es: \[
\mathcal{I}(\zeta)=E[\mathcal{J}(\zeta)].
\]
Esta medida indica cuánta información tienen los datos sobre el parámetro y se relaciona con la precisión del estimador. En el ejemplo Bernoulli, al evaluar en \(\mu=\hat{\mu}\) se obtiene: \[
\mathcal{J}(\hat{\mu})=\frac{n}{\hat{\mu}(1-\hat{\mu})}
\] y, en general, la información esperada es: \[
\mathcal{I}(\mu)=\frac{n}{\mu(1-\mu)}.
\]
3.5.3 Errores Estándar de los Parámetros
Usando una expansión en serie de Taylor, se demuestra que la varianza del MLE se puede aproximar como: \[
\operatorname{var}[\hat{\zeta}] \approx \frac{1}{\mathcal{I}(\zeta)}.
\]
Por lo tanto, el error estándar estimado de \(\hat{\zeta}\) es: \[
\text{SE}(\hat{\zeta}) \approx \frac{1}{\sqrt{\mathcal{I}(\hat{\zeta})}}.
\]
3.5.3.1 Ejemplo
En el ejemplo Bernoulli, usando la información de Fisher calculada previamente:
n <-length(quilpie$y)muhat <-mean(quilpie$y) Info <- n / (muhat * (1- muhat))c(muhat = muhat, FisherInfo = Info)
muhat FisherInfo
0.5147059 272.2354978
El error estándar se calcula como:
1/sqrt(Info)
[1] 0.06060767
Esto indica que el estimador \(\hat{\mu}\) tiene un error estándar aproximado de 0.0606.
3.6 Máxima Verosimilitud para Más de Un Parámetro
En esta sección se extiende la metodología de máxima verosimilitud al caso en que se estiman múltiples parámetros en un modelo de regresión. El proceso involucra la construcción de las ecuaciones score para cada parámetro, el cálculo de la información (observada y esperada), y la obtención de los errores estándar de los estimadores.
3.6.1 Ecuaciones Score
Modelo General:
Se asume que cada observación \(y_i\) sigue una distribución parametrizada por un parámetro de localización (media) \(\mu_i\) y un parámetro de dispersión \(\phi\). La media se define en función de las covariables \(x_{ij}\) y los parámetros de regresión \(\beta_j\) a través del predictor lineal \[
\eta_i=\beta_0+\beta_1x_{i1}+\cdots+\beta_px_{ip}
\] y mediante una función de enlace que relaciona \(\mu_i\) y \(\eta_i\), es decir, \(g(\mu_i)=\eta_i\).
Función Log-Verosimilitud y Funciones Score:
La log-verosimilitud para \(n\) observaciones es \[
\ell(\beta_0,\beta_1,\dots,\beta_p;y) = \sum_{i=1}^{n} \log \mathcal{P}(y_i;\mu_i,\phi).
\] Las funciones score para cada parámetro se definen como: \[
U(\beta_j)=\frac{\partial \ell(\beta_0,\beta_1,\dots,\beta_p;y)}{\partial \beta_j}
= \sum_{i=1}^{n} \frac{\partial \log \mathcal{P}(y_i;\mu_i,\phi)}{\partial \mu_i}\frac{\partial \mu_i}{\partial \beta_j}.
\] Así, hay una ecuación score por cada parámetro desconocido en el modelo, y se resuelven conjuntamente para obtener los estimadores de máxima verosimilitud.
3.6.2 Información: Observada y Esperada
Información Observada:
La segunda derivada negativa de la log-verosimilitud respecto a los parámetros mide la “curvatura” del log-verosimilitud alrededor del máximo y se define para el par de parámetros \((\beta_j, \beta_k)\) como: \[
\mathcal{J}_{jk}(\beta) = -\frac{\partial^2 \ell(\beta;y)}{\partial \beta_j \partial \beta_k}
= -\frac{\partial U(\beta_j)}{\partial \beta_k}.
\]
Información Esperada o Fisher Information:
Se define como \[
\mathcal{I}_{jk}(\beta) = E[\mathcal{J}_{jk}(\beta)].
\] En particular, la cantidad \(\mathcal{I}_{jj}(\beta)\) es una medida del monto de información disponible sobre el parámetro \(\beta_j\) y, de forma general, la varianza de un estimador de máxima verosimilitud se aproxima por: \[
\operatorname{var}[\hat{\beta}_j] \approx \frac{1}{\mathcal{I}_{jj}(\beta)}.
\]
3.6.3 Errores Estándar de los Parámetros
Utilizando la información esperada se puede obtener una aproximación de la precisión de los estimadores. Específicamente, el error estándar (la desviación típica) del estimador de \(\beta_j\) se estima como: \[
\operatorname{se}(\hat{\beta}_j) \approx \frac{1}{\sqrt{\mathcal{I}_{jj}(\hat{\beta})}}.
\]
Este resultado muestra que la precisión del MLE está inversamente relacionada con la cantidad de información disponible; mientras mayor sea \(\mathcal{I}_{jj}\), menor será el error estándar del estimador.
3.7 Máxima Verosimilitud Usando Álgebra Matricial
En esta sección se extiende el método de máxima verosimilitud al contexto de varios parámetros y se lo expresa usando álgebra matricial. Esto facilita el manejo de modelos complejos y permite utilizar métodos iterativos para resolver las ecuaciones score.
3.7.1 Notación
Se asume que las respuestas provienen de una distribución con función de probabilidad \[
\mathcal{P}(\mathbf{y};\boldsymbol{\zeta}),
\] donde \(\boldsymbol{\zeta} = [\zeta_1, \dots, \zeta_q]\) es el vector de parámetros desconocidos. La función de verosimilitud es la función de probabilidad vista como función de los parámetros: \[
\mathcal{L}(\boldsymbol{\zeta};\mathbf{y}) = \mathcal{P}(\mathbf{y};\boldsymbol{\zeta}).
\] La log-verosimilitud se define como: \[
\ell(\boldsymbol{\zeta};\mathbf{y}) = \log \mathcal{L}(\boldsymbol{\zeta};\mathbf{y}).
\] Los valores de los parámetros que maximizan la verosimilitud son los estimadores de máxima verosimilitud (MLE), denotados por \(\hat{\boldsymbol{\zeta}}\).
3.7.2 Ecuaciones Score
La derivada primera de la log-verosimilitud con respecto a \(\boldsymbol{\zeta}\) se conoce como el vector score: \[
U(\boldsymbol{\zeta}) = \frac{\partial \ell(\boldsymbol{\zeta};\mathbf{y})}{\partial \boldsymbol{\zeta}} = \sum_{i=1}^{n} \frac{\partial \log \mathcal{P}(y_i; \boldsymbol{\zeta})}{\partial \boldsymbol{\zeta}}.
\] Cada componente \(U(\zeta_j)\) de este vector es la derivada parcial con respecto a \(\zeta_j\). El MLE se obtiene resolviendo la ecuación de score: \[
U(\hat{\boldsymbol{\zeta}}) = \mathbf{0}.
\] En el caso de modelos de regresión, a menudo el interés se centra en los parámetros de la regresión. Por ejemplo, si el predictor lineal está dado por \[
\boldsymbol{\eta} = \beta_0 + \beta_1 x_{i1} + \cdots + \beta_p x_{ip} = X\boldsymbol{\beta},
\] y se define el enlace mediante \(\mu = g^{-1}(\eta)\), entonces se pueden escribir las ecuaciones score para cada \(\beta_j\) como: \[
U(\beta_j) = \frac{d\ell(\boldsymbol{\beta};\mathbf{y})}{d\mu} \frac{\partial \mu}{\partial \beta_j}.
\]
3.7.3 Información: Observada y Esperada
La información se mide a través de la segunda derivada de la log-verosimilitud. Se define la información observada como: \[
\mathcal{J}(\boldsymbol{\zeta}) = -\frac{\partial^2 \ell(\boldsymbol{\zeta}; \mathbf{y})}{\partial \boldsymbol{\zeta} \partial \boldsymbol{\zeta}^T}.
\] La información esperada (o información de Fisher) es: \[
\mathcal{I}(\boldsymbol{\zeta}) = E[\mathcal{J}(\boldsymbol{\zeta})].
\] En el contexto de modelos de regresión, con el predictor lineal \(\eta = X\boldsymbol{\beta}\), la información se puede expresar en términos de derivadas parciales con respecto a los parámetros y usualmente resulta en una matriz de dimensión \(p' \times p'\). Por ejemplo, la entrada \((j,k)\) se expresa como: \[
\mathcal{J}_{jk}(\boldsymbol{\beta}) = -\frac{\partial^2 \ell(\boldsymbol{\beta};\mathbf{y})}{\partial \beta_j \partial \beta_k}.
\] Las propiedades importantes son:
La esperanza del vector score es cero:\(E[U(\boldsymbol{\zeta})] = \mathbf{0}\).
La varianza del vector score es igual a la información esperada:\[
\operatorname{var}[U(\boldsymbol{\zeta})] = \mathcal{I}(\boldsymbol{\zeta}) = E[U(\boldsymbol{\zeta})U(\boldsymbol{\zeta})^T].
\]
3.7.4 Errores Estándar de los Parámetros
A partir de la matriz de información, se puede aproximar la varianza de cada estimador mediante el inverso de la matriz: \[
\operatorname{var}[\hat{\beta}_j] \approx (\mathcal{I}^{-1}(\boldsymbol{\beta}))_{jj}.
\] Por lo tanto, el error estándar de \(\hat{\beta}_j\) se estima como: \[
\operatorname{se}(\hat{\beta}_j) \approx \frac{1}{\sqrt{(\mathcal{I}^{-1}(\hat{\boldsymbol{\beta}}))_{jj}}}.
\]
3.7.5 Fisher Scoring para calcular MLEs
La estimación de máxima verosimilitud se obtiene al resolver \(U(\hat{\boldsymbol{\zeta}}) = \mathbf{0}\). Una técnica iterativa para hacer esto es el método de Newton-Raphson, que en forma matricial es: \[
\hat{\boldsymbol{\zeta}}^{(r+1)} = \hat{\boldsymbol{\zeta}}^{(r)} + \mathcal{J}(\hat{\boldsymbol{\zeta}}^{(r)})^{-1}U(\hat{\boldsymbol{\zeta}}^{(r)}).
\] Debido a que la matriz de información observada puede ser complicada de calcular, se utiliza en su lugar la matriz de información esperada (Fisher scoring): \[
\hat{\boldsymbol{\zeta}}^{(r+1)} = \hat{\boldsymbol{\zeta}}^{(r)} + \mathcal{I}(\hat{\boldsymbol{\zeta}}^{(r)})^{-1}U(\hat{\boldsymbol{\zeta}}^{(r)}).
\]
Esta es una forma más estable y a menudo más sencilla de implementar la estimación de máxima verosimilitud.
3.8 Propiedades de los estimadores de máxima verosimilitud
El método de máxima verosimilitud no sólo ofrece un camino unificado para estimar parámetros en modelos normales y no‒normales: bajo supuestos regulares —básicamente, que la información aumenta al crecer el tamaño muestral \(n\)— sus estimadores disfrutan de atributos teóricos muy atractivos. A continuación se describen esas propiedades tanto para un único parámetro como para el caso multivariado, manteniendo la notación y las ecuaciones originales.
3.8.1 Motivación general
Supóngase que cada respuesta proviene de una distribución parametrizada por \(\zeta\) (o por el vector \(\boldsymbol{\zeta}\)). El estimador de máxima verosimilitud, denotado \(\hat{\zeta}\), se define como el valor que maximiza la función de verosimilitud (o su logaritmo) y, en consecuencia, coincide con la solución de la ecuación de “score” \(U(\hat\zeta)=0\). A diferencia de métodos basados en momentos, la verosimilitud utiliza la forma completa de la densidad y esto, junto con condiciones de regularidad suaves, confiere a \(\hat{\zeta}\) una serie de propiedades asintóticas que justifican su uso práctico.
3.8.2 Caso unidimensional
Para un único parámetro \(\zeta\) las conclusiones clásicas son cinco.
- invarianza: cualquier transformación biyectiva \(s(\zeta)\) tiene por MLE el valor transformado \(s(\hat\zeta)\).
- insesgamiento asintótico: \(\mathrm{E}[\hat\zeta]=\zeta\) cuando \(n\to\infty\); con muestras pequeñas el sesgo puede no ser despreciable.
- eficiencia asintótica: ningún otro estimador insesgado asintótico posee varianza menor; si existiera, sería estadísticamente equivalente a \(\hat\zeta\).
- consistencia: \(\hat\zeta\rightarrow\zeta\) en probabilidad a medida que crece el tamaño muestral.
- normalidad asintótica: cuando \(\zeta_{0}\) es el valor verdadero,
así que su error estándar se estima mediante \(\sqrt{\mathcal{I}(\zeta_{0})^{-1}}\).
3.8.3 Extensión multivariada
Cuando el parámetro es un vector \(\boldsymbol{\zeta}=(\zeta_{1},\dots,\zeta_{q})\) las cinco propiedades se mantienen reinterpretadas en clave matricial.
La invarianza se refiere a transformaciones biyectivas de \(\boldsymbol{\zeta}\).
El insesgamiento asegura \(\mathrm{E}[\hat{\boldsymbol{\zeta}}]=\boldsymbol{\zeta}\) asintóticamente.
La eficiencia implica que ningún otro estimador vectorial insesgado posee matriz de varianzas–covarianzas más pequeña.
La consistencia equivale a \(\hat{\boldsymbol{\zeta}}\to\boldsymbol{\zeta}\) en probabilidad.
Por último, la normalidad asintótica adopta la forma
lo que sirve de base a pruebas de razón de verosimilitud y a la construcción de regiones de confianza elipsoidales.
3.8.4 Interpretación práctica y buenas prácticas
Estas propiedades explican por qué la máxima verosimilitud domina la inferencia paramétrica moderna: brinda estimadores que, con datos suficientes, son insesgados, eficientes y de distribución conocida, permitiendo construir intervalos o realizar tests sin depender de aproximaciones ad hoc. Sin embargo, la “virtud asintótica” no garantiza un desempeño óptimo con muestras pequeñas; en tales casos puede ser prudente evaluar sesgos, utilizar ajustes (p. ej. bias‐reduction) o recurrir a métodos de remuestreo. Finalmente, la normalidad asintótica depende de que el modelo esté bien especificado; diagnósticos y contrastes de adecuación siguen siendo imprescindibles para que estas propiedades se traduzcan en inferencias fiables.
3.9 Pruebas de hipótesis con grandes muestras
Una vez estimado el modelo mediante máxima verosimilitud surge, de manera natural, la necesidad de contrastar afirmaciones sobre sus parámetros. Esta sección describe cómo, bajo supuestos asintóticos, se construyen tres familias de contrastes equivalentes: Wald, score y razón de verosimilitud. La exposición comienza con un único parámetro y evoluciona hacia modelos multivariados, incluidos los contrastes sobre subconjuntos de parámetros.
3.9.1 Tres miradas a un mismo contraste unidimensional
Sea \(\zeta\) el único parámetro de interés y considérese la hipótesis nula \(H_{0}\!: \zeta=\zeta^{0}\) frente a la alternativa bilateral.
La prueba de Wald mide la distancia entre el estimador y el valor hipotético, escalada por la varianza asintótica de \(\hat\zeta\),
Bajo \(H_{0}\), \(W\xrightarrow{d}\chi^{2}_{1}\). Emplear \(Z=\sqrt{W}\) resulta útil cuando se desea una formulación unilateral, porque \(Z\xrightarrow{d}N(0,1)\).
La prueba de score evita estimar \(\hat\zeta\); se concentra en la pendiente de la log‑verosimilitud evaluada en \(\zeta^{0}\):
Los tres estadísticos comparten, pues, la misma distribución límite y, con muestras grandes, conducen a conclusiones concordantes. Ello se ilustra con los datos de lluvia en Quilpie: al contrastar \(H_{0}\!:\mu=0.5\) los tres valores (0.0588, 0.0588, 0.0588) arrojan \(p\)‑valores próximos a 0.81, indicando que la proporción analizada no difiere del 50 %:
## --- datos -------------------------------------------------------------## Se supone que ya existe el data‑frame `quilpie`## con la variable binaria y (1 = lluvia > 10 mm; 0 = lo contrario)y <- quilpie$y # vector de 0/1n <-length(y) # tamaño muestral## --- estimación de máxima verosimilitud -------------------------------muhat <-mean(y) # MLE de µ en el modelo Bernoullivar_hat <- muhat*(1- muhat)/n # varianza asintótica de mû## --- estadístico de Wald ----------------------------------------------W <- (muhat -0.5)^2/ var_hatpW <-pchisq(W, df =1, lower.tail =FALSE)## --- estadístico de score ---------------------------------------------U_mu0 <- (sum(y)/0.5)-((n-sum(y))/0.5) # U(mu0)I_mu0 <- n / (0.5* (1-0.5)) # I(mu0)S <- U_mu0^2/ I_mu0 # S = U^2/IpS <-pchisq(S, df =1, lower.tail =FALSE)## --- estadístico de razón de verosimilitud ----------------------------logLik_mu0 <-sum(dbinom(y, size =1, prob =0.5, log =TRUE))logLik_muhat <-sum(dbinom(y, size =1, prob = muhat, log =TRUE))L <-2* (logLik_muhat - logLik_mu0)pL <-pchisq(L, df =1, lower.tail =FALSE)## --- resumen ----------------------------------------------------------round(cbind( Estadístico =c(W, S, L),"p‑valor"=c(pW, pS, pL) ),4)
Si \(\boldsymbol{\zeta}\in\mathbb{R}^{q}\), la nula global \(H_{0}\!: \boldsymbol{\zeta}=\boldsymbol{\zeta}^{0}\) se examina mediante extensiones matriciales:
Con los mismos datos de Quilpie, probar \(H_{0}\!:\beta_{0}=\beta_{1}=0\) arroja distintos valores numéricos (11.79, 15.92, 18.37), pero todos conducen a \(p<0.01\), descartando la nula:
Con frecuencia se desea verificar si un subconjunto \(\boldsymbol{\zeta}_{2}\) (dimensión \(q_{2}\)) aporta información adicional una vez fijado el resto \(\boldsymbol{\zeta}_{1}\). Particionando la matriz de información,
el contraste \(H_{0}\!:\boldsymbol{\zeta}_{2}=\boldsymbol{\zeta}^{0}_{2}\) se basa en
\[
W = (\hat{\boldsymbol{\zeta}}_{2}-\boldsymbol{\zeta}^{0}_{2})^{\!\top}
(\mathcal{I}^{22})^{-1}
(\hat{\boldsymbol{\zeta}}_{2}-\boldsymbol{\zeta}^{0}_{2}),
\quad
S = U(\boldsymbol{\zeta}^{*})^{\!\top}\!
\mathcal{I}(\boldsymbol{\zeta}^{*})^{-1}
U(\boldsymbol{\zeta}^{*}),
\quad
L = 2\{\ell(\hat{\boldsymbol{\zeta}})-\ell(\boldsymbol{\zeta}^{*})\},
\]
donde \(\boldsymbol{\zeta}^{*}\) combina los MLE de \(\boldsymbol{\zeta}_{1}\) con el valor fijado \(\boldsymbol{\zeta}^{0}_{2}\). Todos los estadísticos tienden a \(\chi^{2}_{q_{2}}\). En el ejemplo, contrastar \(\beta_{1}=0\) (con \(q_{2}=1\)) produce \(p\)‑valores de orden \(10^{-4}\) con las tres técnicas, confirmando la relevancia de la covariable SOI.
En términos prácticos, \(Z\) es el estadístico que suelen devolver los paquetes de software junto con su error estándar. El contraste de razón de verosimilitud requiere volver a ajustar el modelo con la restricción impuesta, mientras que la prueba score evita ese paso calculando la pendiente en el punto nulo.
3.9.5 Fortalezas y limitaciones de cada enfoque
Los tres métodos son asintóticamente equivalentes, pero difieren en comodidad computacional y estabilidad para muestras pequeñas. El contraste de Wald sólo necesita el vector de estimadores y su matriz de varianzas, por lo que resulta muy simple; sin embargo, su comportamiento puede deteriorarse cuando la estimación está cerca del borde del espacio paramétrico (fenómeno de Hauck–Donner). La prueba de score es atractiva si el ajuste bajo \(H_{0}\) es trivial y, además, suele mantener mejor nivel con n moderado. La razón de verosimilitud, a costa de dos ajustes, es la opción preferida cuando se desea un criterio globalmente robusto y compatible con comparaciones entre modelos anidados. En la práctica conviene contrastar los resultados y, ante discrepancias con muestras pequeñas, favorecer score o razón de verosimilitud.
3.10 Intervalos de confianza
La estimación puntual mediante máxima verosimilitud resulta muy potente; sin embargo, la práctica exige acompañar cada punto con una medida explícita de precisión. En este apartado describimos cómo se construyen regiones o bandas de confianza a partir de los tres grandes estadísticos asintóticos —Wald, puntaje y cociente de verosimilitudes— haciendo hincapié en sus vínculos con la información de Fisher. En todos los casos se parte de la aproximación cuadrática de la log‑verosimilitud cuando el tamaño muestral \(n\) es grande, suposición bajo la cual los estadísticos convergen a distribuciones \(\chi^{2}\).
3.10.1 Regiones conjuntas para varios parámetros
Supóngase que \(\boldsymbol{\zeta}\) contiene \(q\) parámetros desconocidos. Una región de confianza conjunta al nivel \(100(1-\alpha)\%\) se obtiene hallando todos los valores de \(\boldsymbol{\zeta}\) que satisfacen, respectivamente,
La primera expresión corresponde al criterio de Wald, la segunda al de puntaje y la tercera al cociente de verosimilitudes. Hallar la envolvente exacta de estos conjuntos rara vez es trivial, pues implica resolver ecuaciones no lineales en dimensión \(q\); por ello, en la práctica se suelen recurrir a cortes bidimensionales o aproximaciones elípticas.
3.10.2 Intervalos para un único parámetro
Cuando el interés recae en un componente \(\zeta_{j}\), las expresiones anteriores se reducen a funciones unidimensionales y es posible localizar numéricamente los dos valores frontera que satisfacen el umbral \(\chi^{2}_{1,\,1-\alpha}\). La figura 4.9 del Dunn ilustra la geometría: los límites Wald se obtienen desplazándose una distancia fija a ambos lados de \(\hat{\zeta}_{j}\), mientras que los límites puntaje y verosimilitud se definen allí donde la pendiente del log‑likelihood o la caída respecto al máximo alcanzan la cota crítica.
Para el estadístico de Wald, la forma cerrada es particularmente cómoda:
donde \(z_{1-\alpha/2}\) es el cuantil estándar normal y \(\operatorname{var}[\hat{\zeta}_{j}]\) se obtiene como la entrada \((j,j)\) de \(\mathcal I(\hat{\boldsymbol{\zeta}})^{-1}\). Nótese la simetría inherente, una característica que no comparten las bandas basadas en puntaje o en el cociente de verosimilitudes, ya que la log‑verosimilitud rara vez es perfectamente cuadrática en muestras reales.
En el ejemplo de Quilpie (sección 4.11), el parámetro de interés es la pendiente \(\beta_{1}\). Los tres métodos arrojan límites muy similares: el intervalo Wald va de \(0.0624\) a \(0.2305\), el de puntaje de \(0.0655\) a \(0.2289\) y el de verosimilitud de \(0.0719\) a \(0.2425\). Las pequeñas discrepancias obedecen a la ligera asimetría de la superficie de verosimilitud, pero todos los intervalos excluyen el cero, reforzando la significación detectada previamente por los contrastes.
3.10.3 Comparación de modelos no anidados: AIC y BIC
Los contrastes de razón de verosimilitudes funcionan cuando un modelo está contenido en otro, pero fallan si ambos modelos son no anidados. En ese contexto la práctica estándar consiste en comparar AIC y BIC, dos criterios que parten de la log‑verosimilitud máxima pero añaden un castigo por complejidad.
Sea \(\ell(\hat{\zeta}_{1},\ldots,\hat{\zeta}_{p};y)\) la log‑verosimilitud evaluada en los MLE de un modelo cualquiera. Entonces
La primera expresión aplica un penalizador constante \(k=2\); la segunda emplea \(k=\log n\), de modo que el castigo crece con el tamaño muestral. En ambos casos cuanto más negativo sea el valor resultante, mejor se considera el equilibrio entre ajuste y parsimonia.
3.10.3.1 Ejemplo Quilpie
En la base de lluvias de Quilpie se han ajustado dos modelos binomiales para la probabilidad de superar 10 mm en julio:
Modelo 1: logit \((\mu)=\beta_{0}+\beta_{1}\,\text{SOI}\).
La log‑verosimilitud máxima es \(-39.9503\) y hay dos parámetros libres (\(p=2\)). Se obtiene AIC = 79.9 y BIC = 84.3.
Modelo 2: logit \((\mu)=\beta_{0}+\sum_{k=2}^{5}\beta_{k}\,\text{Fase}_{k}\),
donde la SOI se reemplaza por sus cinco fases categóricas (cuatro dummies más intercepto, \(p=5\)). La log‑verosimilitud asciende a \(-31.8995\), produciendo AIC = 75.8 y BIC = 86.9.
Las conclusiones difieren:
El AIC favorece el segundo modelo (fase), pues gana verosimilitud más de lo que pierde por los parámetros extra.
El BIC, con penalización mayor, opta por el modelo simple con SOI continua.