A continuación veremos los conceptos fundamentales de los modelos de regresión lineal, que se utilizan para explicar una variable respuesta \(y\) a partir de \(p\) variables explicativas \(x_1, x_2, \ldots, x_p\).
1.1.1 Componentes del Modelo
Los modelos de regresión lineal se dividen en dos componentes principales:
1.1.1.1 Componente Aleatorio
Suposición de Varianzas: Se asume que cada observación \(y_i\) tiene una varianza constante \(\sigma^2\) o bien una varianza proporcional a un peso conocido \(w_i\):
En este modelo, los parámetros \(\beta_0, \beta_1, \dots, \beta_p\) y la varianza \(\sigma^2\) se estiman a partir de los datos.
1.1.3 Tipos de Modelos de Regresión
Regresión Lineal Ordinaria: Se usa cuando todos los pesos \(w_i\) son 1.
Regresión Lineal Ponderada: Se aplica cuando los \(w_i\) varían, permitiendo ponderar las observaciones según su fiabilidad.
Regresión Lineal Simple: Modelo con una sola variable explicativa (\(p = 1\)).
Regresión Lineal Múltiple: Modelo con más de una variable explicativa (\(p > 1\)).
1.1.4 Supuestos del Modelo
Para que el modelo sea válido se requieren los siguientes supuestos:
Idoneidad: El mismo modelo se aplica a todas las observaciones.
Linealidad: La relación entre la media \(\mu\) y cada variable explicativa es lineal.
Varianza Constante: La varianza, \(\sigma^2\), es constante (parte desconocida de la varianza).
Independencia: Las observaciones \(y\) son independientes entre sí.
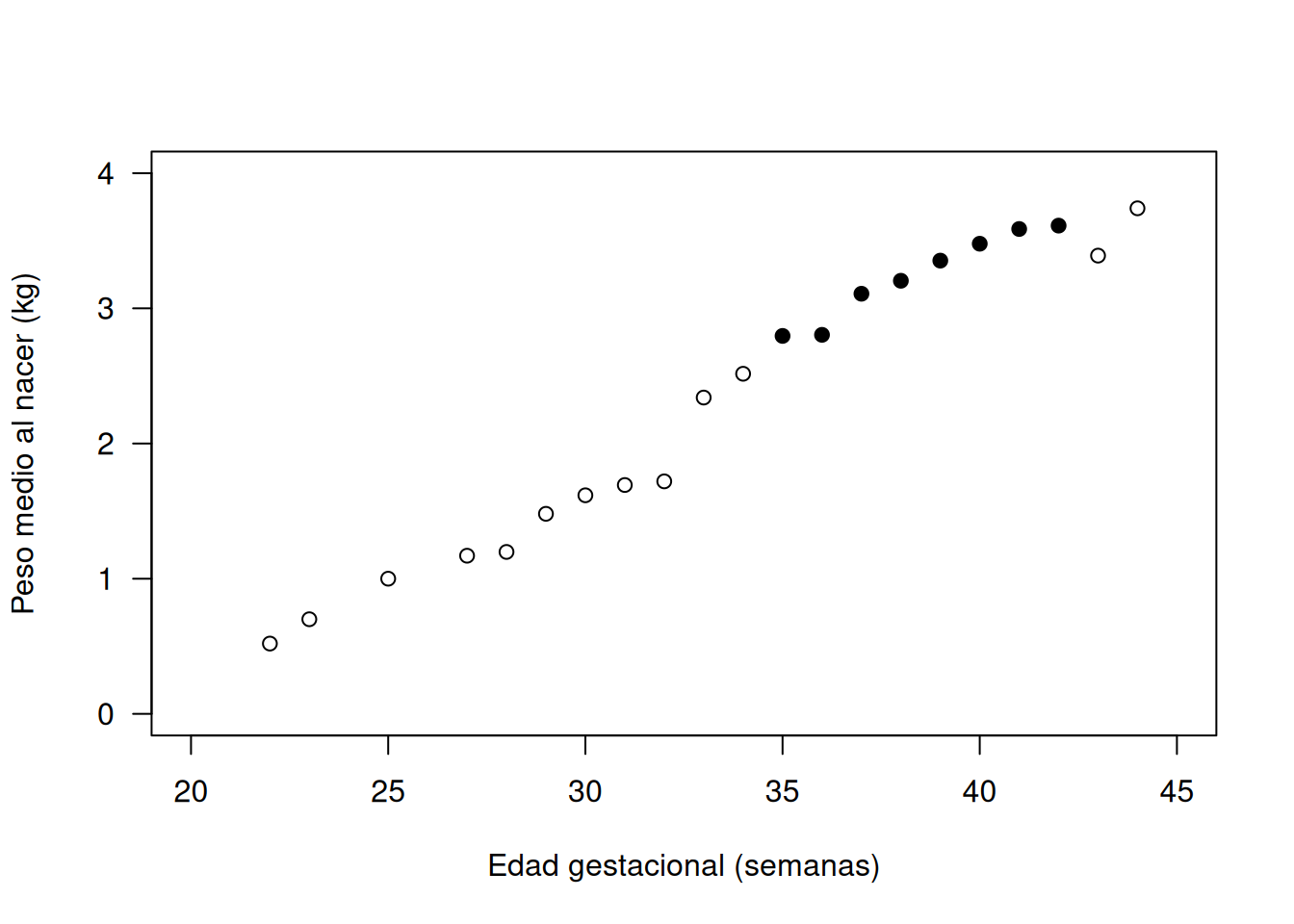
1.1.5 Ejemplo Práctico: Peso al Nacer vs. Edad Gestacional
1.1.5.1 Contexto del Ejemplo
En este ejemplo se analizan datos de 1513 bebés nacidos en el hospital St George’s de Londres entre 1982 y 1984. Los datos incluyen:
Edad Gestacional (\(x_i\)): Medida en semanas.
Número de Nacimientos (\(m_i\)): Número de bebés observados a cada edad.
Peso Medio (\(y_i\)): Promedio del peso al nacer.
Desviación Estándar (SD): Indica la variabilidad del peso; en algunos casos es NA cuando solo hay un nacimiento.
library(GLMsData)data(gestation)str(gestation)
'data.frame': 21 obs. of 4 variables:
$ Age : int 22 23 25 27 28 29 30 31 32 33 ...
$ Births: int 1 1 1 1 6 1 3 6 7 7 ...
$ Weight: num 0.52 0.7 1 1.17 1.2 ...
$ SD : num NA NA NA NA 0.121 NA 0.589 0.319 0.438 0.313 ...
summary(gestation)
Age Births Weight SD
Min. :22.00 Min. : 1.00 Min. :0.520 Min. :0.1210
1st Qu.:29.00 1st Qu.: 1.00 1st Qu.:1.480 1st Qu.:0.3575
Median :34.00 Median : 7.00 Median :2.516 Median :0.4270
Mean :33.76 Mean : 72.05 Mean :2.335 Mean :0.4057
3rd Qu.:39.00 3rd Qu.: 53.00 3rd Qu.:3.353 3rd Qu.:0.4440
Max. :44.00 Max. :401.00 Max. :3.740 Max. :0.5890
NA's :6
1.1.5.2 Consideraciones del Modelo
Dado que el peso medio se calcula a partir de \(m_i\) observaciones, se espera que la varianza de \(y_i\) sea:
Para utilizar el modelo en la práctica, es necesario estimar el intercepto \(\beta_0\), la pendiente \(\beta_1\) y la varianza \(\sigma^2\). Para cualquier combinación de estos parámetros, las desviaciones entre los datos observados \(y_i\) y el modelo \(\mu_i\) se definen como:
La idea es escoger la línea ajustada (es decir, las estimaciones de \(\beta_0\) y \(\beta_1\)) de manera que se minimice la suma de los cuadrados de estas desviaciones. Esta suma se expresa como:
Los pesos no negativos \(w_i\) pueden utilizarse para ponderar las observaciones según su precisión (por ejemplo, medias calculadas con muestras de mayor tamaño se estiman con mayor precisión y se les asigna un peso mayor). En general, valores más pequeños de \(S\) indican que la línea ajustada se aproxima mejor a los datos observados.
Ejemplo Consideremos los datos de gestación. Se prueban algunos valores para \(\beta_0\) y \(\beta_1\) y se calcula el valor correspondiente de \(S\):
y <- gestation$Weightx <- gestation$Agewts <- gestation$Birthsbeta0.A <--0.9; beta1.A <-0.1# Valores iniciales para beta0 y beta1mu.A <- beta0.A + beta1.A * xSA <-sum(wts * (y - mu.A)^2)SA
[1] 186.1106
Se observa que con \(\beta_0 = -0.9\) y \(\beta_1 = 0.1\) se obtiene \(S = 186.1\). Si se prueban otros valores:
Con \(\beta_0 = -3\) y \(\beta_1 = 0.15\) se obtiene \(S = 343.4\), lo que indica que los primeros valores son preferibles. El mínimo de \(S\) se alcanza con las estimaciones de mínimos cuadrados \(\hat{\beta}_0\) y \(\hat{\beta}_1\).
1.2.2 Estimación de los Coeficientes
Las estimaciones de mínimos cuadrados de \(\beta_0\) y \(\beta_1\) se obtienen minimizando \(S(\beta_0, \beta_1)\) mediante cálculo. Las derivadas parciales de \(S\) respecto a \(\beta_0\) y \(\beta_1\) son:
La media estimada es \(\hat{\mu}_g = 1.934\) kg, con un error estándar de \(0.08812\) kg.
1.3 Regresión Múltiple
En este apartado se extiende el modelo de regresión al caso en que se tienen \(p\) variables explicativas y, por tanto, \(p'=p+1\) coeficientes de regresión \(\beta_j\) a estimar (para \(j = 0, 1, \ldots, p\), incluyendo el intercepto).
1.3.1 Estimación de los Coeficientes
Al igual que en la regresión lineal simple, definimos la suma de los cuadrados de las desviaciones entre las observaciones \(y_i\) y las medias del modelo:
\[
S = \sum_{i=1}^{n} w_i \Bigl(y_i - \mu_i\Bigr)^2.
\]
Para cualquier conjunto dado de coeficientes \(\beta_j\), \(S\) mide qué tan cerca están las medias del modelo \(\mu_i\) de los valores observados \(y_i\). Los estimadores de mínimos cuadrados de los coeficientes se definen como aquellos valores que minimizan \(S\), y se denotan como \(\hat{\beta}_0, \hat{\beta}_1, \ldots, \hat{\beta}_p\).
Utilizando cálculo, se demuestra que el mínimo de \(S\) se alcanza cuando
La solución de este sistema de \(p+1\) ecuaciones simultáneas se suele resolver mediante algoritmos matriciales; sin embargo, los estimadores pueden interpretarse de la siguiente manera:
para \(j = 0, \ldots, p\). Aquí, \(x_{ij}^*\) representa los valores de la \(j\)-ésima variable explicativa ajustados para las demás variables (es decir, es la parte de \(x_j\) que no puede ser explicada mediante una regresión sobre las otras variables).
Nótese que la varianza \(\sigma^2\) no aparece en las ecuaciones de mínimos cuadrados, lo que significa que no es necesaria para estimar los coeficientes \(\beta_j\).
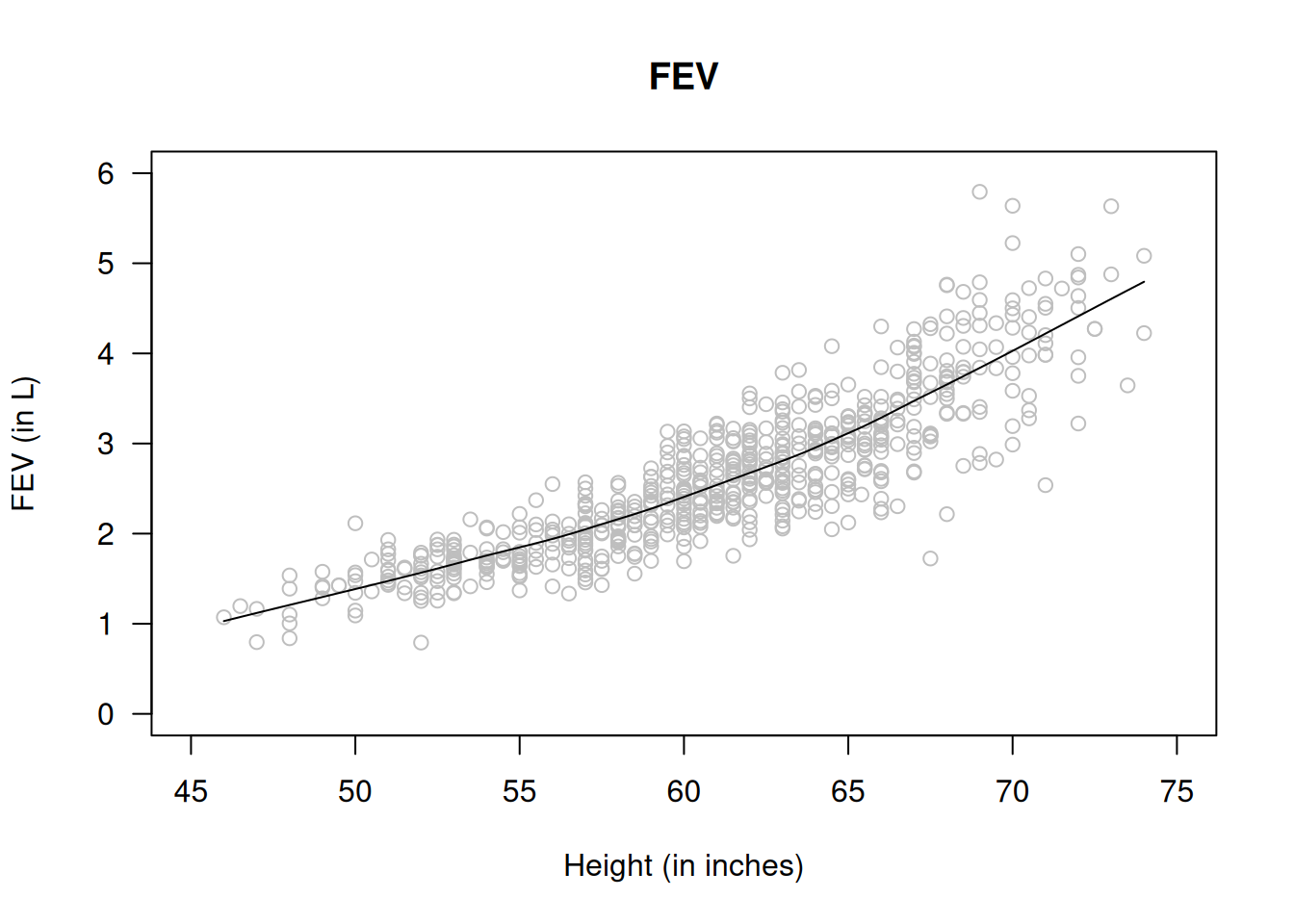
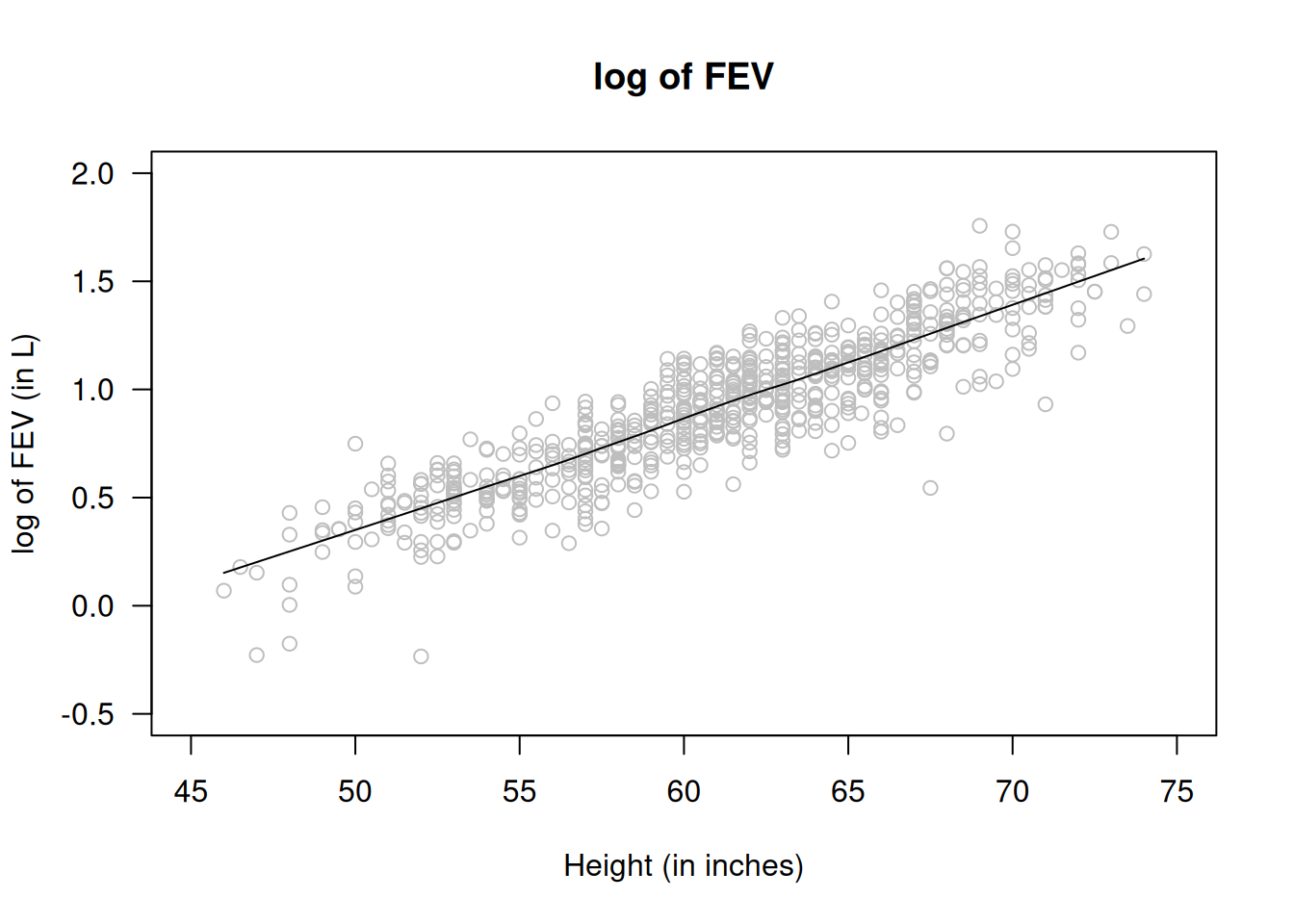
Ejemplo 2.7: Para el conjunto de datos de capacidad pulmonar (lungcap), se observa que la relación entre FEV y la altura no es lineal. Sin embargo, al graficar el logaritmo de FEV frente a la altura se aprecia una relación aproximadamente lineal. Por ello, se puede ajustar un modelo lineal para \(y = \log(\mathrm{FEV})\).
data("lungcap")scatter.smooth( lungcap$Ht, lungcap$FEV, las=1, col="grey",ylim=c(0, 6), xlim=c(45, 75), # Use similar scales for comparisonsmain="FEV", xlab="Height (in inches)", ylab="FEV (in L)" )
scatter.smooth( lungcap$Ht, log(lungcap$FEV), las=1, col="grey",ylim=c(-0.5, 2), xlim=c(45, 75), # Use similar scales for comparisonsmain="log of FEV", xlab="Height (in inches)", ylab="log of FEV (in L)")
Los grados de libertad residuales se obtienen como el número de observaciones menos el número de coeficientes estimados, es decir, \(n - p'\). Así, un estimador insesgado de \(\sigma^2\) se consigue dividiendo RSS por \(n - p'\):
la cual mide la información que aporta la variable explicativa ajustada \(x_j^*\) para estimar el coeficiente \(\beta_j\). La varianza del estimador \(\hat{\beta}_j\) es
1.4 Formulación Matricial de Modelos de Regresión Lineal
La formulación matricial permite expresar y resolver modelos de regresión lineal de forma compacta y eficiente, utilizando herramientas del álgebra matricial.
1.4.1 Notación Matricial
Sea \(\mathbf{y}\) el vector de respuestas de tamaño \(n \times 1\).
Sea \(X\) la matriz del modelo (o matriz de diseño) de tamaño \(n \times p'\) que se escribe como \[X = [\mathbf{x}_0, \mathbf{x}_1, \ldots, \mathbf{x}_p],\] donde \(\mathbf{x}_j\) es el vector de tamaño \(n \times 1\) correspondiente a la variable \(x_j\). Por conveniencia, \(\mathbf{x}_0\) es el vector de unos (el término constante).
El modelo de regresión lineal en notación matricial se expresa como:
donde \(E[\mathbf{y}] = \boldsymbol{\mu}\) y \(W^{-1}\) es una matriz simétrica y definida positiva de tamaño \(n \times n\). En el caso especial en que cada observación tenga el mismo peso, \(W^{-1}\) es la matriz identidad \(I_n\).
Ejemplo Para los datos de gestación con \(n = 21\) y \(p' = 2\), se tiene:
1.4.2 Estimación de los Coeficientes con Notación Matricial
La suma ponderada de los cuadrados de las desviaciones se expresa como
\[
S = (\mathbf{y} - \boldsymbol{\mu})^T\,W\,(\mathbf{y} - \boldsymbol{\mu}),
\]
donde \(\boldsymbol{\mu} = X\,\boldsymbol{\beta}\). Al diferenciar \(S\) con respecto a \(\boldsymbol{\beta}\) y igualar a cero se obtiene la ecuación normal:
Aunque la fórmula matricial de \(\hat{\boldsymbol{\beta}}\) es equivalente a las expresiones escalares vistas anteriormente, en la práctica se utilizan algoritmos numéricos eficientes (como la descomposición QR) para evitar calcular la inversa explícitamente.
Ejemplo Para ajustar el modelo a los datos de lungcap en R (sin ponderar, es decir, \(W^{-1} = I_n\)):
lungcap$Smoke <-factor(lungcap$Smoke, levels =c(0, 1),labels =c("Non-smoker", "Smoker"))Xmat <-model.matrix(~ Age + Ht +factor(Gender) +factor(Smoke), data = lungcap)head(Xmat)
Una vez obtenido \(\hat{\boldsymbol{\beta}}\), los valores ajustados son \(\hat{\boldsymbol{\mu}} = X\,\hat{\boldsymbol{\beta}}\). La varianza se estima a partir de la suma residual de cuadrados (RSS):
Los elementos diagonales de esta matriz son las varianzas de los coeficientes, y sus raíces cuadradas son los errores estándar.
Ejemplo Para el modelo de lungcap, se puede calcular:
var.matrix <- s2 * inv.XtXvar.betaj <-diag(var.matrix) # diag() extrae los elementos diagonalessqrt(var.betaj)
(Intercept) Age Ht factor(Gender)M
0.078638583 0.003348451 0.001678968 0.011718565
factor(Smoke)Smoker
0.020910198
La salida mostrará los errores estándar de cada coeficiente, por ejemplo, \(\operatorname{se}(\hat{\beta}_0) = 0.07864\), \(\operatorname{se}(\hat{\beta}_1) = 0.003348\), etc.
1.4.5 Estimación de la Varianza de los Valores Ajustados
Para un vector de valores de las variables explicativas, \(\mathbf{x}_g\), la mejor estimación de la media es
Ejemplo Para estimar la media de \(\log(\mathrm{FEV})\) en el modelo de lungcap para un caso específico (por ejemplo, para una mujer de 18 años, 66 pulgadas de altura, que fuma), se procede así:
El resultado proporciona la estimación de \(\log(\mathrm{FEV})\) y su error estándar.
1.5 Ajuste de Modelos de Regresión Lineal en R
En esta sección veremos cómo ajustar modelos de regresión lineal de forma práctica en R, utilizando la función lm(). Esto evita tener que realizar los cálculos explícitos que se demostraron en secciones anteriores.
1.5.1 Uso Básico de lm()
La función lm() permite especificar la fórmula del modelo indicando la variable respuesta a la izquierda del símbolo ~ y las variables explicativas a la derecha. Por ejemplo, para ajustar el modelo lineal a los datos de peso al nacer del data frame gestation, en el que además se usan pesos (número de nacimientos, Births), se hace lo siguiente:
gest.wtd <-lm(Weight ~ Age, data = gestation, weights = Births) # Se especifican los pesossummary(gest.wtd)
Call:
lm(formula = Weight ~ Age, data = gestation, weights = Births)
Weighted Residuals:
Min 1Q Median 3Q Max
-1.62979 -0.60893 -0.30063 -0.08845 1.03880
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.678389 0.371172 -7.216 7.49e-07 ***
Age 0.153759 0.009493 16.197 1.42e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.7753 on 19 degrees of freedom
Multiple R-squared: 0.9325, Adjusted R-squared: 0.9289
F-statistic: 262.3 on 1 and 19 DF, p-value: 1.416e-12
En este ejemplo, el primer argumento de lm() es la fórmula Weight ~ Age (se lee “Weight es modelado por Age”). El argumento data = gestation indica el data frame donde se encuentran las variables, y weights = Births especifica los pesos previos.
1.5.2 Ajuste Sin Usar Pesos
Para comparar, se puede ajustar el modelo sin utilizar pesos:
gest.ord <-lm(Weight ~ Age, data = gestation)coef(gest.ord)
(Intercept) Age
-3.049879 0.159483
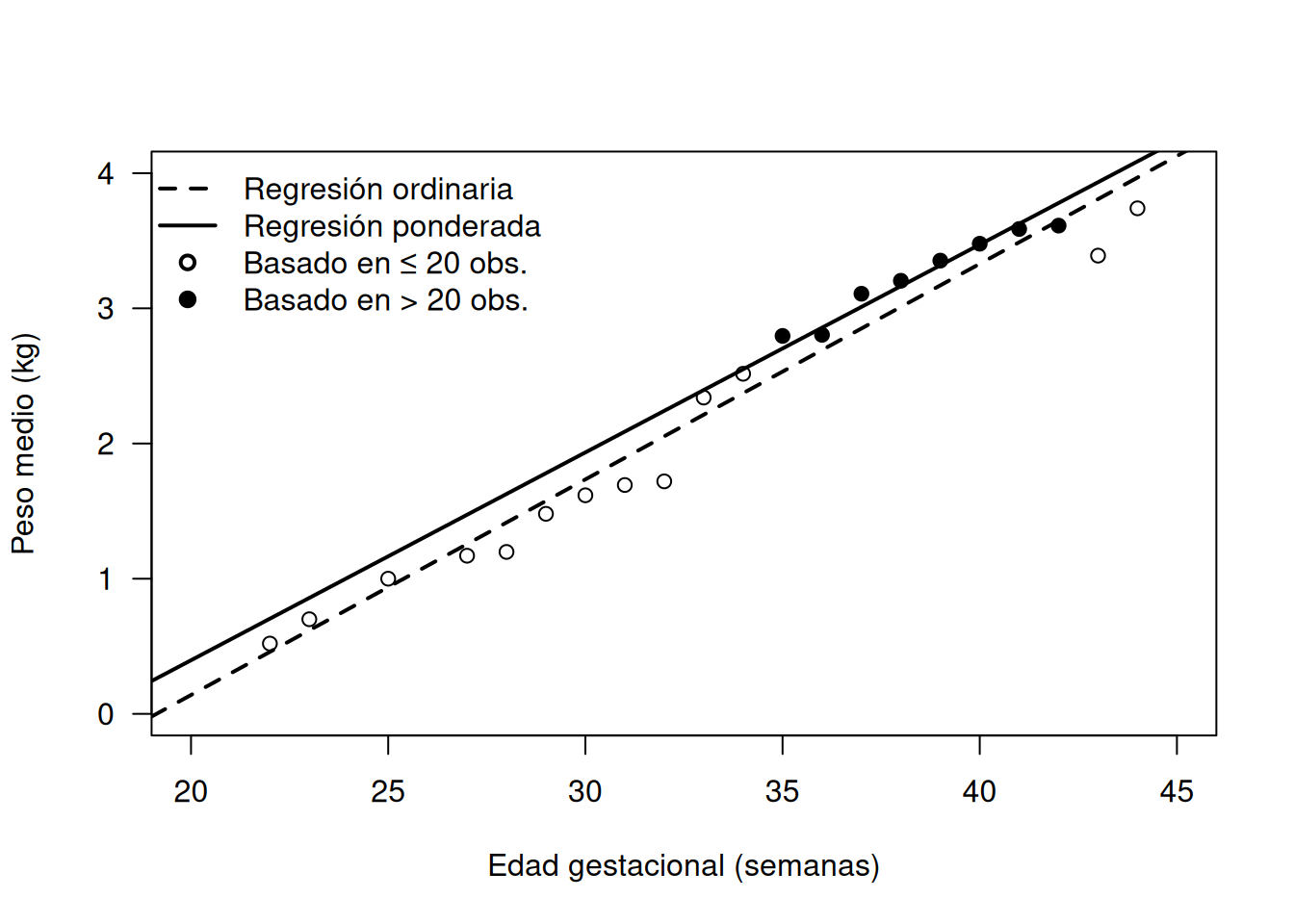
La diferencia entre el ajuste ponderado y el ajuste ordinario se puede visualizar en un gráfico.
1.5.3 Comparación Gráfica de Modelos
El siguiente código muestra cómo graficar los datos de gestation y dibujar las rectas de regresión para el modelo ordinario y el modelo ponderado:
plot(Weight ~ Age, data = gestation, type ="n", las =1, xlim =c(20, 45), ylim =c(0, 4),xlab ="Edad gestacional (semanas)", ylab ="Peso medio (kg)")points(Weight[Births <20] ~ Age[Births <20], pch =1, data = gestation)points(Weight[Births >=20] ~ Age[Births >=20], pch =19, data = gestation)abline(coef(gest.ord), lty =2, lwd =2)abline(coef(gest.wtd), lty =1, lwd =2)legend("topleft", lwd =c(2,2), bty ="n",lty =c(2, 1, NA, NA), pch =c(NA, NA, 1, 19),legend =c("Regresión ordinaria", "Regresión ponderada","Basado en ≤ 20 obs.", "Basado en > 20 obs."))
En este gráfico se utilizan:
Círculos vacíos para observaciones con menos de 20 nacimientos.
Círculos llenos para observaciones con 20 o más nacimientos.
La línea discontinua (lty = 2) muestra la regresión ordinaria, y la línea sólida (lty = 1) la regresión ponderada.
1.5.4 Ajuste de Modelos con Varias Variables
También es posible ajustar modelos con múltiples variables explicativas. Por ejemplo, para ajustar el modelo lineal múltiple a los datos de capacidad pulmonar (lungcap), usando log(FEV) como respuesta y Age, Ht, Gender y Smoke como variables explicativas, se procede de la siguiente manera:
# Se asume que Smoke ya ha sido declarado como factor previamentelm(log(FEV) ~ Age + Ht + Gender + Smoke, data = lungcap)
Call:
lm(formula = log(FEV) ~ Age + Ht + Gender + Smoke, data = lungcap)
Coefficients:
(Intercept) Age Ht GenderM SmokeSmoker
-1.94400 0.02339 0.04280 0.02932 -0.04607
La salida indica que el componente sistemático del modelo es:
La función summary(LC.m1) proporciona un resumen completo del modelo, incluyendo:
Estimaciones de los parámetros y sus errores estándar.
Estadísticos t y valores p.
R-cuadrado y otros indicadores de ajuste.
Para obtener únicamente los coeficientes, se utiliza:
coef(LC.m1)
(Intercept) Age Ht GenderM SmokeSmoker
-1.94399818 0.02338721 0.04279579 0.02931936 -0.04606754
Y para extraer la estimación de \(\sigma\) se usa:
summary(LC.m1)$sigma
[1] 0.1454686
Esta información corresponde, por ejemplo, a la línea de salida que muestra el error residual y los grados de libertad.
1.6 Interpretación de los Coeficientes de Regresión
Después de ajustar un modelo, es muy importante interpretar sus coeficientes para determinar si el modelo tiene sentido físico y para entender la historia que nos cuenta.
1.6.1 Ejemplo: Datos de Gestación
Para los datos de gestación, la componente sistemática del modelo ajustado es
\[
\hat{\mu} = -2.678 + 0.1538\,x
\]
donde \(\mu=E[y]\), siendo \(y\) el peso medio al nacer (en kg) y \(x\) la edad gestacional en semanas. Este modelo indica que, en promedio, el peso medio al nacer aumenta en aproximadamente \(0.1538\) kg por cada semana adicional de gestación. La componente aleatoria sugiere que la variación de los pesos alrededor de \(\mu\) es casi constante, con \(s^2 = 0.6010\).
1.6.2 Ejemplo: Datos de Capacidad Pulmonar
Para el modelo ajustado a los datos de capacidad pulmonar, la variable respuesta es \(\log(\mathrm{FEV})\), de forma que la componente sistemática es
Los coeficientes de regresión deben interpretarse en términos de su impacto sobre \(\mu = E[\log(\mathrm{FEV})]\), y no directamente sobre \(E[\mathrm{FEV}]\). Sin embargo, dado que
\[
E[\log y] \approx \log E[y] = \log \mu
\]
esta ecuación puede reescribirse aproximadamente como
Con esta formulación, se pueden interpretar directamente los efectos de las variables explicativas sobre \(E[\mathrm{FEV}]\). Por ejemplo, un aumento de una pulgada en la altura (\(x_{2}\)) se asocia, manteniendo constantes las demás variables, con un incremento en la media de FEV por un factor de \(\exp(0.04280) = 1.044\).
En el caso de variables cualitativas, los coeficientes indican cuánto varía \(\mu\) en comparación con el nivel de referencia (tras ajustar por el efecto de las otras variables). Así, el coeficiente para Smoke indica que, para los fumadores (Smoke = 1) frente a los no fumadores (Smoke = 0), \(\mu\) cambia por un factor de \(\exp(-0.04607) = 0.9550\). Es decir, FEV se reduce aproximadamente en un 4.5% para los fumadores, manteniendo constantes las demás variables.
La componente aleatoria del modelo indica que la variación de \(\log(\mathrm{FEV})\) alrededor de \(\mu = E[\log(\mathrm{FEV})]\) es aproximadamente constante, con \(s^2 = 0.02116\).
1.6.3 Consideraciones sobre Covariables Correlacionadas
La interpretación de los efectos de covariables correlacionadas es sutil. Por ejemplo, en los datos de capacidad pulmonar, la altura y la edad están positivamente correlacionadas. En los jóvenes, la altura suele aumentar con la edad, por lo que el efecto de aumentar la edad manteniendo la altura fija no equivale al aumento global en FEV que se observaría cuando ambas variables aumentan de forma natural. El coeficiente de cada covariable en el modelo lineal refleja solo el efecto neto, eliminando cualquier cambio concomitante en las demás covariables que normalmente ocurriría si todas variaran de manera no controlada.
Finalmente, es importante recordar que los datos son observacionales, por lo que no se puede inferir una relación causal.
1.7 Inferencia en Modelos de Regresión Lineal: Pruebas t
En esta sección se explica cómo realizar inferencias estadísticas en modelos de regresión lineal utilizando el enfoque de pruebas t. Para ello se asume que los errores del modelo siguen una distribución normal, lo que permite derivar la distribución de los estimadores y construir tests e intervalos de confianza.
1.7.1 Modelos de Regresión Lineal Normales
Hasta ahora se había asumido que las respuestas son independientes y tienen varianza constante, sin especificar una distribución. Sin embargo, para llevar a cabo inferencias formales se asume que:
Este modelo se conoce como modelo de regresión lineal normal.
1.7.2 Distribución de \(\hat{\beta}_j\)
Bajo el modelo normal, las estimaciones de los coeficientes, \(\hat{\beta}_j\), son combinaciones lineales de los \(y_i\) y por ello siguen una distribución normal:
\[
Z = \frac{\hat{\beta}_j - \beta_j}{\operatorname{se}(\hat{\beta}_j)},
\]
donde \(\operatorname{se}(\hat{\beta}_j) = \sqrt{\operatorname{var}[\hat{\beta}_j]}\), si \(\sigma^2\) es conocido \(Z\) sigue una distribución normal estándar. Cuando \(\sigma^2\) es desconocido, se estima por \(s^2\) y se usa la distribución t con \(n-p'\) grados de libertad:
\[
T = \frac{\hat{\beta}_j - \beta_j}{\operatorname{se}(\hat{\beta}_j)}.
\]
1.7.3 Pruebas de Hipótesis para \(\beta_j\)
Para evaluar la significancia de un coeficiente se formula la hipótesis nula
\[
H_0:\; \beta_j = \beta_j^0,
\]
usualmente con \(\beta_j^0 = 0\), contra alternativas unilaterales o bilaterales. El estadístico de prueba es
\[
T = \frac{\hat{\beta}_j - \beta_j^0}{\operatorname{se}(\hat{\beta}_j)}.
\]
Si \(H_0\) es cierta, \(T\) sigue una distribución t con \(n-p'\) grados de libertad. Cada test t determina si, en el contexto del modelo, hay evidencia de que el coeficiente difiere de \(\beta_j^0\).
Ejemplo En el modelo ajustado para los datos de capacidad pulmonar, para el coeficiente de la variable Smoke se obtiene un t-valor de aproximadamente -2.203 y un valor-p de 0.02794. Esto indica evidencia de que la variable Smoke es estadísticamente significativa en presencia de Age, Ht y Gender.
1.7.4 Intervalos de Confianza para \(\beta_j\)
Además de las pruebas de hipótesis, es común estimar el tamaño del efecto mediante intervalos de confianza. Un intervalo de confianza del \(100(1-\alpha)\%\) para \(\beta_j\) se construye como
donde \(t^*_{\alpha/2,\, n-p'}\) es el valor crítico de la distribución t con \(n-p'\) grados de libertad. En R se pueden obtener estos intervalos con la función confint(). Por ejemplo, para el modelo de capacidad pulmonar se obtiene:
donde \(\operatorname{se}(\hat{\mu}_g) = \sqrt{\operatorname{var}[\hat{\mu}_g]}\). En R, la función predict() con el argumento se.fit=TRUE permite obtener estos intervalos.
Ejemplo Para estimar \(E[\log(\mathrm{FEV})]\) para mujeres fumadoras de 18 años y 66 pulgadas de altura, se procede de la siguiente manera:
new.df <-data.frame(Age =18, Ht =66, Gender ="F", Smoke ="Smoker")out <-predict(LC.m1, newdata = new.df, se.fit =TRUE)tstar <-qt(df = LC.m1$df, p =0.975) # Valor crítico para un IC del 95%ci.lo <- out$fit - tstar * out$se.fitci.hi <- out$fit + tstar * out$se.fitCIinfo <-cbind(Lower = ci.lo, Estimate = out$fit, Upper = ci.hi)CIinfo
Lower Estimate Upper
1 1.209268 1.255426 1.301584
La predicción es \(\hat{\mu} = 1.255\), con un intervalo de confianza del 95% de 1.209 a 1.302 para \(\log(\mathrm{FEV})\). Exponenciando estos valores se obtiene un intervalo aproximado para \(E[\mathrm{FEV}]\).
1.8 Análisis de Varianza en Modelos de Regresión
El análisis de varianza (ANOVA) en regresión se utiliza para descomponer la variabilidad total en el conjunto de datos en dos componentes: la parte explicada por el modelo (sistemática) y la parte no explicada (residual).
1.8.1 Descomposición de la Variabilidad
Para cada observación \(y_i\) ajustada mediante mínimos cuadrados se obtiene un valor ajustado
\(\mathrm{SST} = \sum_{i=1}^{n} w_i \left( y_i - \bar{y}_w \right)^2\) es la suma total de cuadrados.
\(\mathrm{SSREG} = \sum_{i=1}^{n} w_i \left( \hat{\mu}_i - \bar{y}_w \right)^2\) es la suma de cuadrados de la regresión.
\(\mathrm{RSS} = \sum_{i=1}^{n} w_i \left( y_i - \hat{\mu}_i \right)^2\) es la suma de cuadrados residuales.
El término cruzado \(\left(\hat{\mu}_i - \bar{y}_w\right)\left(y_i - \hat{\mu}_i\right)\) se cancela al sumar.
1.8.2 Prueba de Significancia del Modelo
La pregunta central es determinar si las variables explicativas son útiles para predecir la respuesta. Esto se evalúa comparando la variación explicada por el modelo (SSREG) con la variación residual (RSS).
Bajo el modelo de regresión normal, se tiene que:
\(\mathrm{RSS} / \sigma^2\) sigue una distribución chi-cuadrado con \(n-p'\) grados de libertad.
Bajo la hipótesis nula de que \(\beta_j = 0\) para \(j=1,\ldots,p\), se puede demostrar que \(\mathrm{SSREG} / \sigma^2\) tiene una distribución chi-cuadrado con \(p'-1\) grados de libertad.
que sigue una distribución \(F\) con \((p'-1, n-p')\) grados de libertad. Un valor grande de \(F\) indica que la variación explicada es significativamente mayor que la residual.
y representa la proporción de la variabilidad total que es explicada por el modelo. Dado que agregar variables no puede aumentar \(\mathrm{RSS}\), \(R^2\) tiende a aumentar con el número de variables. Por ello se usa el \(R^2\) ajustado:
La salida también muestra el estadístico \(F\) y sus grados de libertad:
summary(LC.m1)$fstatistic
value numdf dendf
694.5804 4.0000 649.0000
Estos resultados se resumen en la tabla ANOVA, en la que se observa que la parte sistemática explica una porción significativa de la variación total.
1.9 Comparación de Modelos Anidados
En muchas ocasiones se desea comparar dos modelos de regresión lineal que están anidados, es decir, uno de ellos es un caso especial del otro al fijar algunos coeficientes a cero. Esto permite evaluar si las variables adicionales en el modelo más complejo aportan información significativa.
1.9.1 Análisis de Varianza para Comparar Modelos Anidados
El Modelo A está anidado en el Modelo B, ya que se puede obtener restringiendo el Modelo B a \(\beta_2 = \beta_3 = 0\). La hipótesis nula a evaluar es:
\[
H_0: \beta_2 = \beta_3 = 0,
\]
lo que implica que Model A es suficiente. La comparación se realiza mediante el análisis de varianza (ANOVA), evaluando la reducción en la suma de cuadrados de los residuos (RSS) al pasar de un modelo más simple a uno más complejo. En R, el procedimiento es el siguiente:
LC.A <-lm(log(FEV) ~ Age + Smoke, data = lungcap)LC.B <-lm(log(FEV) ~ Age + Ht + Gender + Smoke, data = lungcap)RSS.A <-sum(resid(LC.A)^2) # RSS del Modelo ARSS.B <-sum(resid(LC.B)^2) # RSS del Modelo Bc(ModelA = RSS.A, ModelB = RSS.B)
ModelA ModelB
28.91982 13.73356
La diferencia entre RSS es el SS (suma de cuadrados) asociado a los parámetros adicionales:
El valor-p casi cero indica que Model B mejora significativamente la explicación de la variación en \(y\), por lo que las variables adicionales son importantes. La función anova() de R resume estos resultados:
anova(LC.A, LC.B)
Analysis of Variance Table
Model 1: log(FEV) ~ Age + Smoke
Model 2: log(FEV) ~ Age + Ht + Gender + Smoke
Res.Df RSS Df Sum of Sq F Pr(>F)
1 651 28.920
2 649 13.734 2 15.186 358.82 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
1.9.2 Análisis de Varianza Secuencial
En ocasiones se comparan una serie de modelos anidados secuencialmente. Por ejemplo, para los datos de lungcap se pueden ajustar los siguientes modelos:
Cada diferencia se asocia a un cambio de 1 grado de libertad. Comparando estos incrementos de SS con el error cuadrático medio (MSE) se realizan pruebas \(F\).
1.9.3 Regresiones Paralelas e Independientes
A veces se desea comparar regresiones separadas para distintos subgrupos. Por ejemplo, en los datos de lungcap se puede analizar la relación entre \(y = \log(\mathrm{FEV})\) y la altura (\(x_2\)) diferenciando fumadores y no fumadores.
Modelo ingenuo (sin covariables):
\[
\hat{\mu} = 0.9154
\]
Modelo con altura:
\[
\hat{\mu} = -2.271 + 0.05212\,x_2
\]
Modelo con altura y smoking (con líneas paralelas):
En este último caso, se permiten que tanto las pendientes como los interceptos difieran entre fumadores y no fumadores. La prueba estadística de la interacción (a través de un test \(t\) o \(F\)) evalúa si las diferencias en las pendientes son significativas.
1.9.4 El Principio de Marginalidad
El principio de marginalidad establece que, si se incluye un término de interacción o un término de orden superior en un modelo, deben incluirse también los términos de orden inferior correspondientes, incluso si no son estadísticamente significativos. Esto es necesario para mantener la interpretación correcta del modelo. Por ejemplo:
Si se incluye \(x^2\), también debe incluirse \(x\).
Si se incluye una interacción entre dos variables, se deben incluir también los efectos principales de cada variable.
Este principio evita restricciones artificiales en el modelo.
1.10 Elegir entre Modelos no Anidados: AIC y BIC
Cuando se desea comparar modelos de regresión que no están anidados, los métodos tradicionales de prueba de hipótesis no son aplicables. En estos casos se utilizan criterios de información que equilibran la precisión y la parsimonia del modelo.
1.10.1 Precisión y Parsimonia
Precisión: Se mide a través de la suma de cuadrados residuales (RSS). Agregar variables explicativas siempre reduce el RSS, lo que mejora la precisión.
Parsimonia: Se refiere a la simplicidad del modelo. Agregar muchas variables puede llevar a un modelo complejo que, aunque preciso, puede ser difícil de interpretar.
Un buen modelo debe balancear ambas consideraciones.
1.10.2 Criterio de Información de Akaike (AIC)
El AIC equilibra la precisión (medida por el RSS) y la complejidad (número de parámetros estimados). Para un modelo de regresión lineal normal, cuando \(\sigma^2\) es desconocido, se define como:
\[
\mathrm{AIC} = n \log(\mathrm{RSS} / n) + 2 p'
\]
donde \(p'\) es el número total de parámetros estimados (incluyendo el intercepto). Modelos con valores de AIC más bajos (más cercanos a \(-\infty\)) se consideran mejores.
1.10.3 Criterio de Información Bayesiano (BIC)
El BIC penaliza la complejidad del modelo de forma más severa que el AIC. Se define como:
\[
\mathrm{BIC} = n \log(\mathrm{RSS} / n) + p' \log n
\]
Debido a que para muestras grandes \(\log n > 2\), el BIC tiende a favorecer modelos más parsimoniosos.
1.10.4 Enfoques y Propósitos
AIC: Se orienta hacia la predicción. Permite incluir variables que puedan mejorar la predicción, incluso si la evidencia de su importancia no es muy fuerte.
BIC: Busca un equilibrio entre interpretación y predicción. Requiere evidencia más fuerte para incluir variables, lo que resulta en modelos más simples.
Ninguno de estos criterios produce pruebas formales ni valores-\(p\), sino que se utilizan para comparar modelos entre sí.
1.10.5 Cálculo en R
En R, la función extractAIC() se usa para obtener el AIC de un modelo. Por defecto, esta función devuelve el AIC; para obtener el BIC se especifica el parámetro de penalización \(k = \log(\text{nobs(fit)})\), donde nobs() extrae el número de observaciones.
Ejemplo
Consideremos nuevamente los datos de capacidad pulmonar (lungcap). Supongamos que el investigador quiere que el modelo incluya la variable de estado de fumador (\(x_{4}\)) y debe elegir entre usar edad (\(x_{1}\)) o altura (\(x_{2}\)). Se consideran los siguientes dos modelos:
Estos modelos no están anidados, por lo que se utilizan los criterios AIC y BIC para compararlos.
LC.A <-lm(log(FEV) ~ Age + Smoke, data = lungcap)extractAIC(LC.A)
[1] 3.000 -2033.551
LC.B <-lm(log(FEV) ~ Ht + Smoke, data = lungcap)extractAIC(LC.B)
[1] 3.000 -2470.728
El primer valor indica los grados de libertad equivalentes (número de parámetros estimados) y el segundo el valor del AIC. Como el AIC de LC.B es menor (más cercano a \(-\infty\)), se prefiere el modelo que utiliza altura (Ht).
Para extraer el BIC:
k <-log(length(lungcap$FEV))extractAIC(LC.A, k = k)
[1] 3.000 -2020.102
extractAIC(LC.B, k = k)
[1] 3.000 -2457.278
Nuevamente, el BIC es menor para el Modelo B, sugiriendo que la combinación de Ht y Smoke es más adecuada que la combinación de Age y Smoke. Esto es razonable, ya que Ht mide directamente una característica física.
1.11 Herramientas para la Selección de Modelos
Cuando existen muchas variables explicativas candidatas, seleccionar el conjunto óptimo para un modelo puede resultar tedioso y complejo. Afortunadamente, R dispone de funciones que ayudan a evaluar de forma sistemática el impacto de agregar o eliminar variables, así como métodos automatizados que facilitan la búsqueda del modelo óptimo.
1.11.1 Agregar y Eliminar Variables
Las funciones add1() y drop1() exploran el efecto de incorporar o eliminar una variable a la vez en el modelo actual:
drop1(): Evalúa el impacto de eliminar cada término individualmente del modelo actual. Por ejemplo, en un modelo que incluye las variables Age, Ht, Gender y Smoke para los datos de capacidad pulmonar:
drop1(lm(log(FEV) ~ Age + Ht + Gender + Smoke, data = lungcap), test ="F")
Single term deletions
Model:
log(FEV) ~ Age + Ht + Gender + Smoke
Df Sum of Sq RSS AIC F value Pr(>F)
<none> 13.734 -2516.6
Age 1 1.0323 14.766 -2471.2 48.7831 7.096e-12 ***
Ht 1 13.7485 27.482 -2064.9 649.7062 < 2.2e-16 ***
Gender 1 0.1325 13.866 -2512.3 6.2598 0.01260 *
Smoke 1 0.1027 13.836 -2513.7 4.8537 0.02794 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
La salida muestra el AIC del modelo completo y los AIC resultantes al eliminar cada variable, junto con las pruebas F correspondientes. En este ejemplo, se observa que el AIC es el menor (más cercano a \(-\infty\)) cuando no se elimina ninguna variable, lo que sugiere que el modelo actual es adecuado.
add1(): Examina el efecto de agregar variables al modelo, partiendo de un modelo mínimo. Por ejemplo, si se inicia con un modelo que solo incluye Smoke:
LC.full <-lm(log(FEV) ~ Age + Ht + Gender + Smoke, data = lungcap)add1(lm(log(FEV) ~ Smoke, data = lungcap), LC.full, test ="F")
Single term additions
Model:
log(FEV) ~ Smoke
Df Sum of Sq RSS AIC F value Pr(>F)
<none> 68.192 -1474.5
Age 1 39.273 28.920 -2033.5 884.045 < 2.2e-16 ***
Ht 1 53.371 14.821 -2470.7 2344.240 < 2.2e-16 ***
Gender 1 2.582 65.611 -1497.8 25.616 5.426e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
La salida indica qué variable adicional reduce el AIC (se acerca más a \(-\infty\)). En este caso, la adición de Ht parece mejorar el modelo, por lo que se sugiere incluir dicha variable.
1.11.2 Métodos Automatizados para la Selección de Modelos
Cuando hay muchas variables, el número de posibles modelos puede crecer exponencialmente (por ejemplo, con 10 variables se tienen \(2^{10} = 1024\) modelos posibles). Para automatizar este proceso se utilizan tres métodos comunes:
Regresión hacia adelante (Forward Regression): Se parte de un modelo mínimo (usualmente solo el intercepto) e se añaden variables de una en una, seleccionando la que mayor mejora aporte al modelo según el AIC (o BIC).
Eliminación hacia atrás (Backward Elimination): Se comienza con un modelo completo y se eliminan las variables una a una, removiendo aquella cuya eliminación mejore más el criterio de selección.
Regresión paso a paso (Stepwise Regression): Combina ambas estrategias, agregando y eliminando variables en cada paso, siempre eligiendo la modificación que lleve al AIC más bajo.
La función step() de R implementa estos métodos. Por ejemplo, para realizar una regresión hacia adelante se define un modelo mínimo y un modelo máximo (que incluya todas las interacciones de dos vías):
min.model <-lm(log(FEV) ~ Age + Ht + Gender + Smoke, data = lungcap)max.model <-lm(log(FEV) ~ (Smoke + Age + Ht + Gender)^2, data = lungcap)auto.forward <-step(min.model, direction ="forward", scope =list(lower = min.model, upper = max.model))
En algunos casos los tres métodos pueden producir el mismo modelo final; sin embargo, en general pueden diferir.
1.11.3 Objeciones a los Procedimientos Stepwise
A pesar de su conveniencia, los métodos automatizados (como los stepwise) tienen varias objeciones:
Falta de fundamentación teórica: Estos métodos no se basan en una comprensión profunda de los datos y pueden probar hipótesis que no son de interés real.
Problemas de múltiples pruebas: La automatización puede llevar a errores estándar subestimados, valores-\(p\) demasiado pequeños, intervalos de confianza estrechos y, en general, a una sobreestimación de la significancia del modelo.
Sobreajuste: Los modelos seleccionados automáticamente a menudo no se ajustan bien a nuevos conjuntos de datos.
Debido a estas razones, muchos autores recomiendan complementar los métodos automatizados con conocimiento teórico y análisis adicionales.