En numerosos estudios el resultado de interés es una proporción \(y\) sobre un total \(m\): por ejemplo, la proporción de individuos que contraen una enfermedad o la proporción de votos a favor de un candidato. En tales casos resulta natural asumir que cada grupo de tamaño \(m\) sigue una distribución binomial, donde cada elemento es independiente y tiene dos posibles resultados.
La función de probabilidad de la distribución binomial, en forma EDM, es
con \(y\in\{0,1/m,2/m,\dots,1\}\), proporción esperada \(0<\mu<1\), tamaño de grupo \(m\) conocido y \(\phi=1\). En el GLM se toman los pesos previos \(w_i=m_i\).
y, por la aproximación de saddlepoint, sigue aproximadamente una \(\chi^2_{n-p'}\) si \(\min\{m_i y_i\}\ge3\) y \(\min\{m_i(1-y_i)\}\ge3\).
Un GLM binomial se denota GLM(binomial; link) y en R se especifica con family=binomial(). Hay tres formas equivalentes de codificar la respuesta en glm():
Proporciones \(y_i\) con pesos weights=m_i.
Array de dos columnas (éxitos, fracasos) sin indicar pesos explícitos.
Vector factor o lógico de longitud \(\sum m_i\), útil para datos Bernoulli.
Para diagnóstico se recomiendan residuos cuantil, pues su aproximación normal es exacta bajo el modelo correcto.
8.1.1 Ejemplo: desgaste de turbinas
Un experimento midió, para distintos tiempos de operación \(x_i\), la proporción \(y_i\) de ruedas con fisuras sobre un total de \(m_i\) turbinas. Un modelo adecuado es un GLM binomial con logit:
library(GLMsData); data(turbines)# Especificación con proporciones y pesostur.m1 <-glm(Fissures/Turbines ~ Hours,family=binomial,weights=Turbines,data=turbines)# Especificación con cbind(éxitos, fracasos)tur.m2 <-glm(cbind(Fissures, Turbines-Fissures) ~ Hours,family=binomial,data=turbines)coef(tur.m1); coef(tur.m2)
(Intercept) Hours
-3.9235965551 0.0009992372
(Intercept) Hours
-3.9235965551 0.0009992372
Ambos ajustes coinciden.
Para el caso de la tercera representación, podemos cambiar la estructura de datos original a:
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
Al modelar proporciones con GLM binomial es necesario elegir una función de enlace que garantice \(0<\mu<1\). Entre las más usadas se encuentran:
Logit (enlace canónico): \[
\eta = \log\frac{\mu}{1-\mu} = \operatorname{logit}(\mu)
\] Es el enlace por defecto en R (link="logit"), y da lugar a la regresión logística.
Probit: \[
\eta = \Phi^{-1}(\mu)\,,
\] donde \(\Phi\) es la CDF normal estándar (link="probit" en R).
Log-log Complementario: \[
\eta = \log\bigl(-\log(1-\mu)\bigr)\,,
\] asimétrico y útil cuando la ocurrencia es rara (link="cloglog").
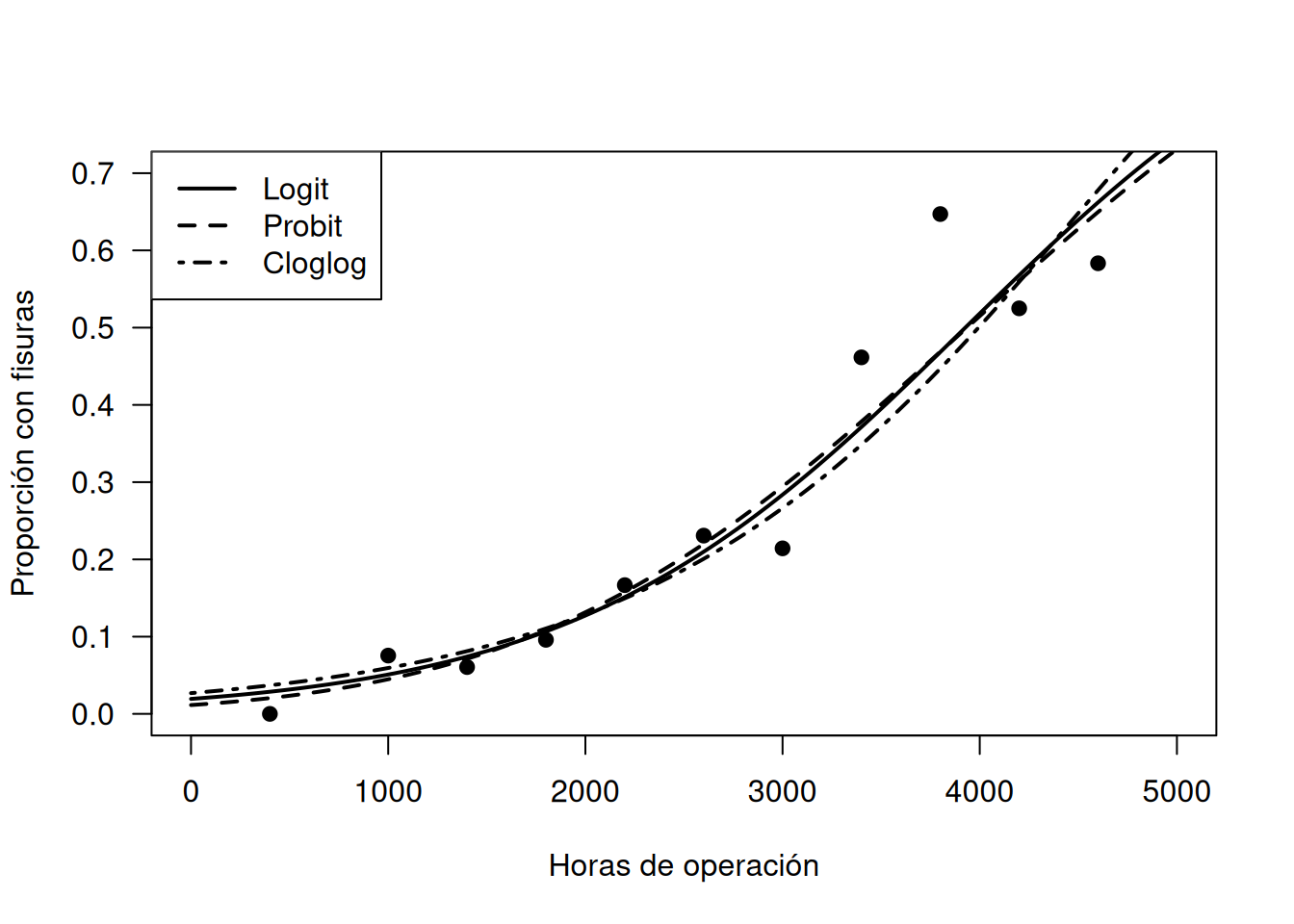
En la práctica logit y probit producen curvas muy similares, ambas simétricas en \(\mu=0.5\), mientras que el enlace cloglog crece más rápido al acercarse a \(\mu=1\).
Para ilustrar, en los datos de turbinas (Ejemplo 9.1) comparamos los tres enlaces:
Las devianzas residuales son similares para logit y probit, algo mayores para cloglog, y las predicciones se obtienen con predict(..., type="response"). Aun con coeficientes distintos, las curvas ajustadas suelen ser muy parecidas.
8.3 Distribuciones de tolerancia y el enlace probit
Una forma intuitiva de entender las funciones de enlace es mediante un modelo de umbral o “tolerancia”. Supongamos que cada turbina \(i\) tiene un nivel de tolerancia \(t_i\), que varía entre máquinas según una distribución continua, y que la turbina desarrolla fisuras si \(t_i\) cae por debajo de un umbral fijo \(T\). Planteamos entonces
De manera análoga, si la distribución de tolerancia fuera:
Logística, surgiría el enlace logit.
Valor extremo (Gumbel), el cloglog.
Cauchy, el cauchit.
Función de enlace
Distribución de tolerancia
Logit
Logistic
\(\mathcal{F}(y)=\exp (y) /\{1+\exp (y)\}\)
Probit
Normal
\(\mathcal{F}(y)=\Phi(y)\)
Complementary log-log
Extreme value
\(\mathcal{F}(y)=1-\exp \{-\exp (y)\}\)
Cauchit
Cauchy
\(\mathcal{F}(y)=\{\arctan (y)+0.5\} / \pi\)
8.4 Cuotas (Odds), razones de cuotas (Odds Ratio) y el enlace logit
Al emplear el enlace logit en un GLM binomial, modelamos directamente el logaritmo de los odds, razones de probabilidad o cuotas, lo cual resulta particularmente intuitivo en aplicaciones de proporciones. Si un evento tiene probabilidad \(\mu\) de ocurrir, sus odds se definen como
\[
\frac{\mu}{1-\mu}\,,
\]
que es la razón entre la probabilidad de éxito y la de fracaso. Por ejemplo, si la probabilidad de que una turbina desarrolle fisuras es 0.6, las odds son \(0.6/(1-0.6)=1.5\), lo que significa que el suceso es 1.5 veces más probable que el no suceso.
De aquí se deduce que, al incrementar \(x\) en una unidad, el log-odds crece en \(\beta_{1}\), y las odds se multiplican por \(\exp(\beta_{1})\). Esta última cantidad, \(\exp(\beta_{1})\), se conoce como odds ratio o razón de cuotas, y mide cuántas veces más probables son las cuotas cuando \(x\) aumenta en una unidad.
En el ejemplo de las turbinas, el ajuste
coef(tr.logit)
(Intercept) Hours
-3.9235965551 0.0009992372
implica que un aumento de 1000 h en el tiempo de funcionamiento multiplica las cuotas de fisura por
Cuando \(x\) es una variable indicadora (0/1), la razón de cuotas \(\exp(\beta_{1})\) compara las cuotas de éxito entre los dos niveles de la variable, facilitando la interpretación de efectos de factores. Por estas razones, el enlace logit es a menudo la elección preferida en regresión binomial.
8.4.1 Ejemplo: Regresión logística con dos factores
En este estudio se evalúa cómo dos factores categóricos —tipo de semilla (“OA73” vs. “OA75”) y tipo de extracto (“Bean” vs. “Cucumber”)— influyen en la proporción de semillas que germinan. Cada observación consiste en el número de semillas germinadas \(Germ_i\) de un total de \(Total_i\) semillas sembradas. Dado que la respuesta es una proporción, resulta natural emplear un GLM binomial con función de enlace logit y ponderar por los tamaños de muestra.
El intercepto corresponde al log-odds de germinación para semillas OA73 con extracto Bean. El coeficiente de Extract=Cucumber es altamente significativo (\(p<10^{-12}\)), mientras que Seeds=OA75 resulta marginalmente no significativo al 5 % (\(p\approx0.08\)).
Para interpretar en términos de odds ratios, calculamos:
Las odds de germinación con Cucumber son 2.90 veces las de Bean.
Las odds para semillas OA75 son 1.31 veces las de OA73, lo cual es un aumento del 31 %, pero con evidencia estadística más débil.
8.5 Dosis efectiva mediana (ED50)
En los experimentos dosis-respuesta con un modelo binomial, se estudia cómo la dosis \(d\) de un compuesto afecta la proporción \(y\) de organismos que sobrevive o sucumbe. Un parámetro de gran interés es la dosis efectiva mediana, o ED50, definida como aquella dosis para la cual \(\mu=0.5\).
donde \(g()\) es la función de enlace empleada (por ejemplo, logit, probit o log-log complementaria).
En R, la función dose.p() del paquete MASS calcula directamente \(\widehat{\mathrm{ED}}(\rho)\) y su error estándar a partir del objeto glm. Por defecto \(\rho=0.5\), de modo que devuelve la ED50.
library(MASS)
Attaching package: 'MASS'
The following object is masked from 'package:dplyr':
select
# Supongamos que ya tenemos ajustados tr.logit, tr.probit y tr.cllED50s <-cbind(Logit =dose.p(tr.logit),Probit =dose.p(tr.probit),"C-log-log"=dose.p(tr.cll))ED50s
Logit Probit C-log-log
p = 0.5: 3926.592 3935.197 3993.575
Estos valores indican que, según el modelo logístico, alrededor de 3927 h de funcionamiento producirían fisuras en el 50 % de los turbinas. Las estimaciones con otros enlaces son muy similares, tal como era de esperar.
8.6 Sobredispersión
En un modelo binomial clásico se tiene \(\text{Var}[y]=\mu(1-\mu)/m\), pero con frecuencia los datos muestran una variabilidad superior a \(\mu(1-\mu)/m\), fenómeno conocido como sobredispersión. Esto provoca que los errores estándar del GLM queden subestimados y que las pruebas de hipótesis sobre los coeficientes aparezcan artificialmente significativas, llevando a modelos excesivamente complejos.
La sobredispersión se detecta mediante pruebas de ajuste: si la devianza residual o el estadístico de Pearson exceden con creces sus grados de libertad residuales, y no hay variables omitidas ni valores atípicos que lo expliquen, la interpretación más plausible es que existe sobredispersión.
Dos mecanismos principales generan sobredispersión:
Variabilidad extra en las probabilidades
Cuando las probabilidades de éxito \(p_i\) varían entre grupos, surge una sobredispersión que puede modelarse jerárquicamente. Supongamos que, condicionada a \(p_i\), la proporción observada satisface
donde el factor de dispersión\(\phi_i>1\) depende de \((m_i,\alpha,\beta)\). De esta manera, la sobredispersión se incorpora naturalmente al permitir variabilidad extra en las probabilidades de éxito entre grupos.
Correlación positiva entre ensayos. Si los \(m_i\) ensayos de Bernoulli están correlacionados con coeficiente \(\rho>0\), resulta igualmente
Para acomodar esta sobredispersión se recurre al modelo cuasi-binomial, que conserva la función de varianza \(V(\mu)=\mu(1-\mu)\) pero estima un factor de dispersión \(\phi>1\) (por defecto con el estimador de Pearson). La estimación de los coeficientes es idéntica al modelo binomial, pero los errores estándar se multiplican por \(\sqrt{\phi}\), y las pruebas de hipótesis pasan a basarse en distribuciones \(F\). En R se ajusta con
glm(..., family=quasibinomial(), weights=...)
y el AIC queda indefinido.
Ejemplo En los datos de turbinas (conjunto turbines), cada rueda parece operar de forma independiente, por lo que cabe esperar que los ensayos de Bernoulli lo sean también. Tras ajustar el modelo logístico
Como ni la devianza residual ni la suma de residuos al cuadrado de Pearson superan apreciablemente los 10 grados de libertad, no hay indicio de sobredispersión. Aunque existen un par de observaciones con valores muy pequeños de \(m_i y_i\), son insuficientes para alterar esta conclusión.
Ejemplo
En un experimento de germinación de semillas (datos germ), se evaluó la proporción de semillas que germinan según dos tipos de semilla (Seeds) y dos tipos de extracto de raíz (Extract), disponiendo además del tamaño de muestra por combinación. Ajustando el modelo binomial con interacción:
se obtuvo una devianza residual de 33.28 con 17 grados de libertad, y un estadístico de Pearson de 31.65, ambos muy superiores a los grados de libertad, lo que indica sobredispersión a pesar de haber incluido la interacción:
c( deviance(gm.m1), df.residual(gm.m1) )
[1] 33.27779 17.00000
sum( resid(gm.m1, type="pearson")^2 )
[1] 31.65114
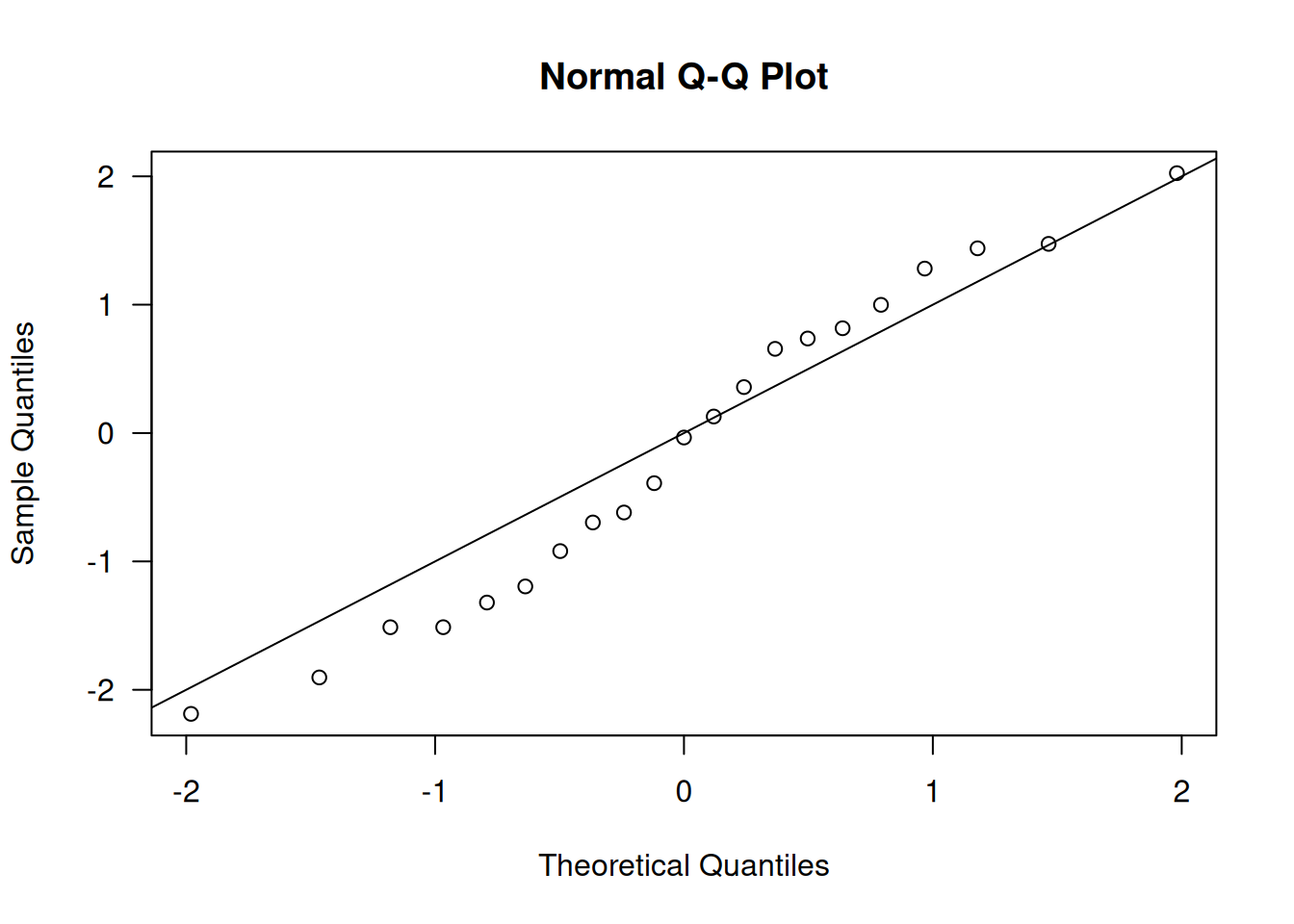
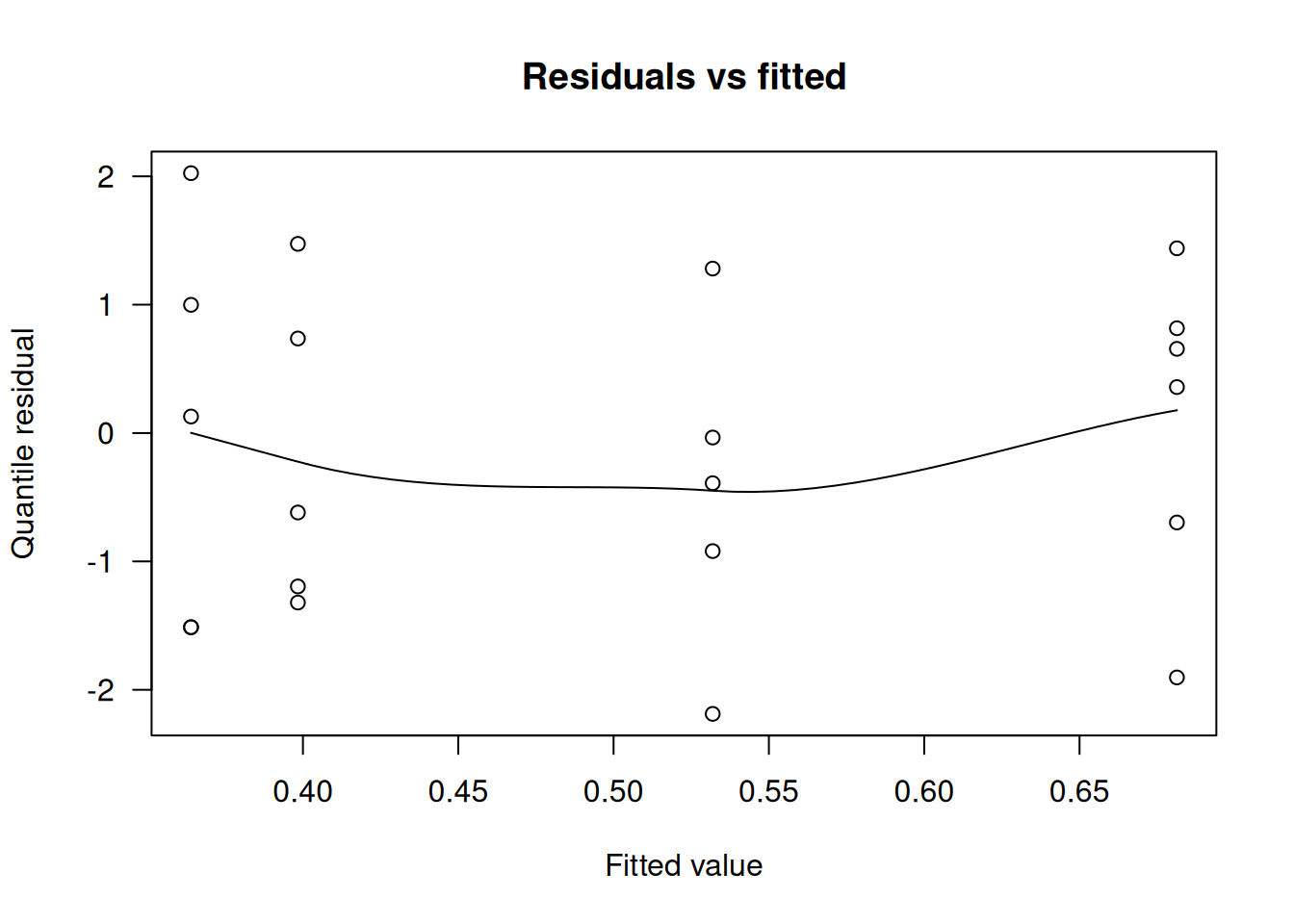
Al inspeccionar los residuales cuantil (qresid(gm.m1)) no se detectaron valores extremos ni ausencias de independencia; la aproximación \(\chi^2\) resultó razonable:
Los contrastes \(F\) mostraron que únicamente Extract sigue siendo significativo (\(P<0.0001\)), mientras que la interacción y el efecto de Seeds dejan de serlo. Los coeficientes del modelo siguen iguales, pero los errores estándar se multiplican por \(\sqrt{\hat\phi}=1.3645\), ensanchando los intervalos de confianza y haciendo más realista la inferencia:
Las pruebas Wald se basan en la aproximación normal de los estimadores y en la razón coeficiente/error estándar. Sin embargo, cuando en un modelo binomial las probabilidades ajustadas \(\hat\mu_i\) tienden a 0 o a 1, el predictor lineal
\[
\hat\eta = g(\hat\mu)=\beta_0 + \beta_1 x
\]
debe ser divergente a \(\pm\infty\) para satisfacer
En ese caso los coeficientes y sus errores estándar crecen sin acotación, y el estadístico de Wald (\(\hat\beta_j/\mathrm{se}(\hat\beta_j)\)) tiende a cero aun cuando el efecto sea real. Este fenómeno, conocido como efecto Hauck–Donner, hace que las pruebas Wald sean completamente engañosas.
En cambio, las pruebas de razón de verosimilitud y de score son invariantes a reparametrizaciones y no sufren este problema de parámetros infinitos.
Ejemplo (Efecto Hauck–Donner)
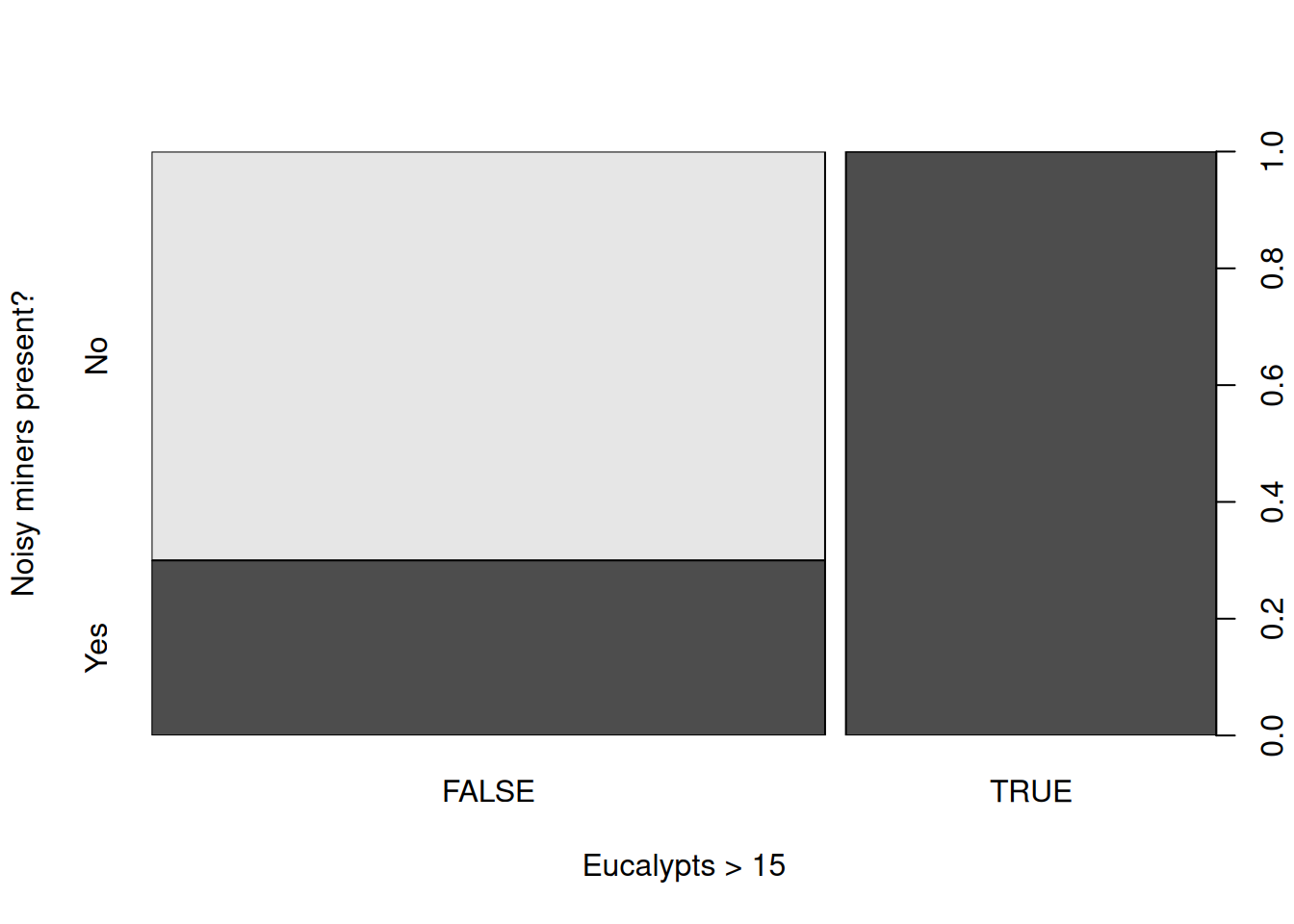
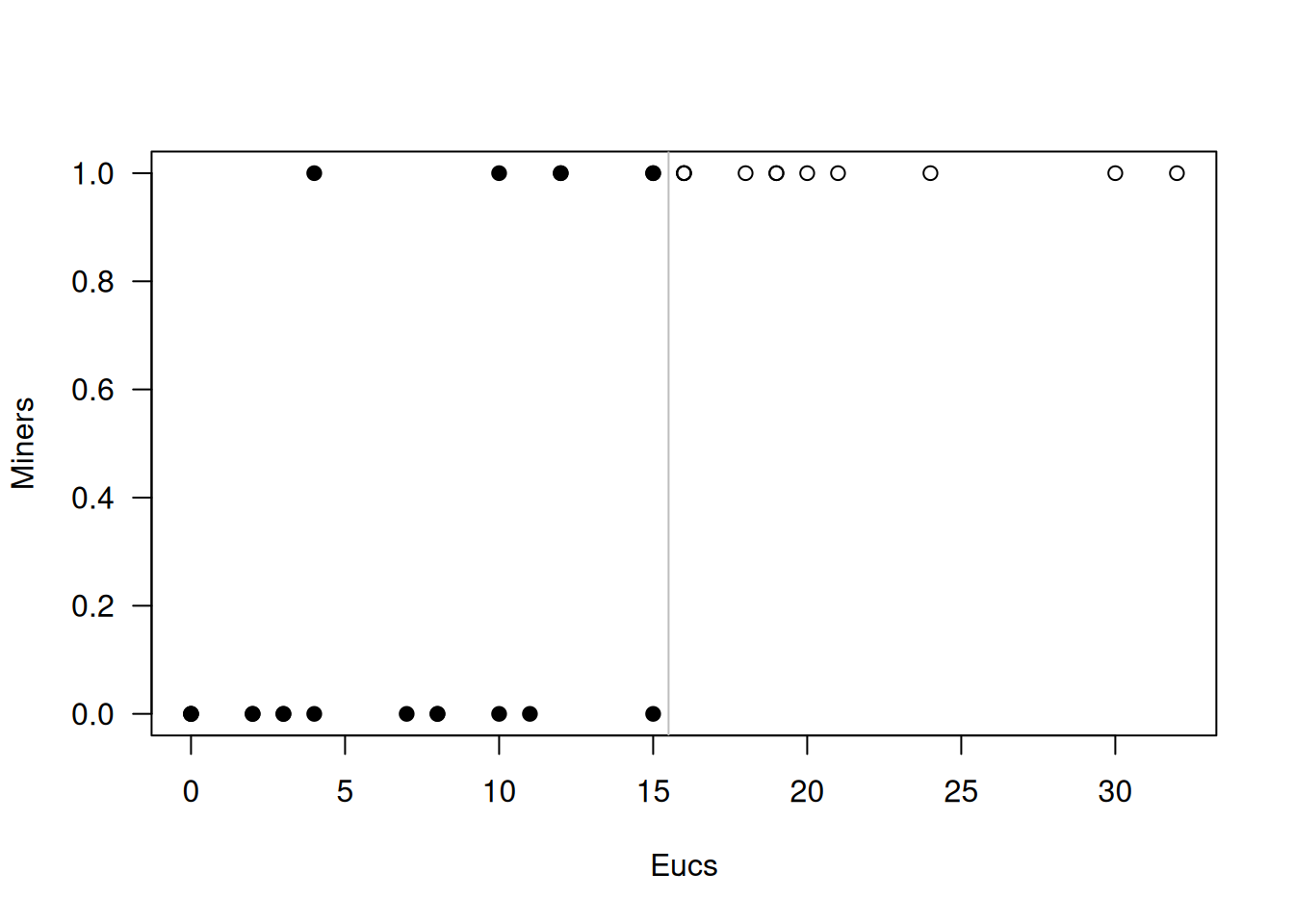
En el conjunto de datos de presencia de noisy miners (nminer), se ajusta un modelo logístico que predice la presencia (Miners) según si el número de eucaliptos excede 15 (Eucs15):
Aunque al inspeccionar el test Wald el coeficiente de Eucs15 no es significativo (\(P\approx0.995\)), la prueba de razón de verosimilitud indica un efecto altamente significativo (\(P\approx10^{-5}\)), y la prueba de score arroja \(P\approx1.8\times10^{-4}\):
Gráficamente, en los parches con más de 15 eucaliptos siempre aparece el ave (\(\hat\mu=1\)), lo que obliga al parámetro a diverger y hace que la prueba Wald colapse. En estas situaciones, conviene descartar los Wald tests y usar en su lugar la razón de verosimilitud o el test de score, que sí ofrecen inferencias fiables:
Cuando todos los tamaños de grupo son \(m_i=1\), cada respuesta \(y_i\) es necesariamente 0 o 1. En ese caso, tanto la devianza residual como el estadístico de Pearson quedan determinados únicamente por los valores ajustados \(\hat\mu_i\), y no se puede conceptalizar la devianza residual ni las pruebas de bondad de ajuste. Esto implica que no existe un concepto interpretable de “desajuste” en sentido clásico y, por tanto, las pruebas de bondad de ajuste basadas en devianza o en Pearson carecen de significado para datos binarios puros.
En lugar de estas pruebas, debe recurrirse a comparaciones de modelos mediante pruebas de razón de verosimilitud o tests de score, asegurándose de que el número de parámetros \(p'\) sea mucho menor que el número de observaciones \(n\) para que las aproximaciones asintóticas sean fiables.
Ejemplo En el ejemplo de los noisy miners (nminer), la devianza residual ajustada resulta menor que los grados de libertad residuales. Aunque pudiera parecer indicativo de subdispersion, esta comparación no tiene sentido, pues dicho valor depende únicamente de cuán cercanas estén las \(\hat\mu_i\) a 0 o a 1 y no de la variabilidad de los datos.
8.9 Ejercicios
Conjunto de datos: SAheart, paquete: bestglm.
Conjunto de datos: UCBAdmissions, paquete: datasets.