12Estimación No-Paramétrica de la curva de sobrevivencia
12.1 Estimación no paramétrica de la función de sobrevivencia
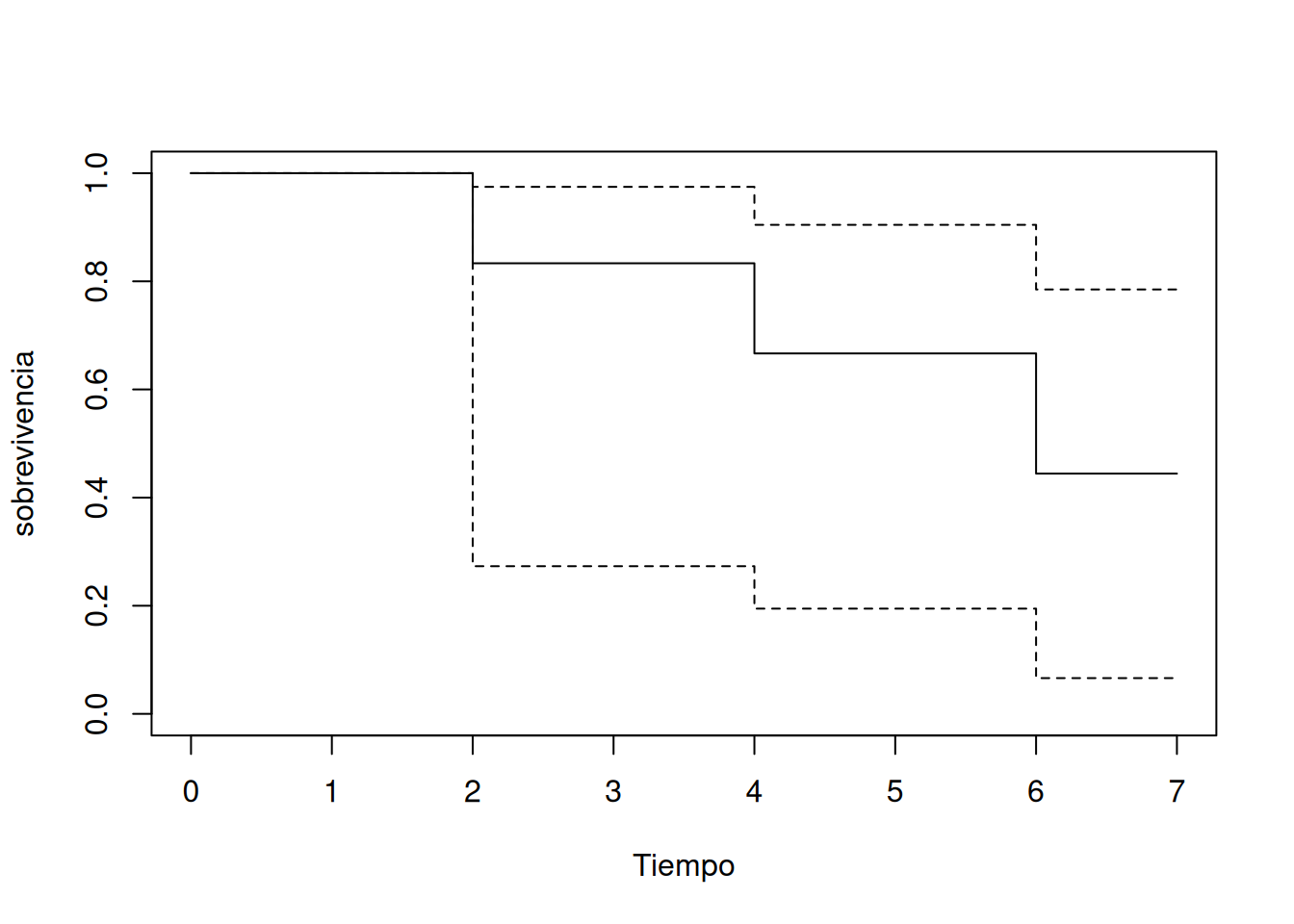
En muchos estudios de sobrevivencia resulta difícil elegir una familia paramétrica que describa adecuadamente la forma de la distribución de tiempos hasta el evento. Por ello, en aplicaciones médicas y biológicas suele preferirse un estimador no paramétrico, con la flexibilidad necesaria para adaptarse a datos reales. El estimador más utilizado es el product–limit o Kaplan–Meier, definido como
donde en cada tiempo de fallo \(t_i\) hay \(n_i\) sujetos en riesgo y \(d_i\) eventos observados. Al multiplicar los factores condicionales \(1 - d_i/n_i\) se obtiene una función escalonada, continua por la derecha, que da la probabilidad de sobrevivencia en cada punto. Por ejemplo, con los siguientes datos:
Paciente
Tiempo Sobrevivencia
Status
1
7
0
2
6
1
3
6
0
4
5
0
5
2
1
6
4
1
resulta la siguiente construcción:
\(t_i\)
\(n_i\)
\(d_i\)
\(q_i=d_i/n_i\)
\(1-q_i\)
\(\hat S(t_i)\)
2
6
1
0.167
0.833
0.833
4
5
1
0.200
0.800
0.667
6
3
1
0.333
0.667
0.444
La mediana de sobrevivencia es el menor \(t\) tal que \(\hat S(t)\le0.5\), en este caso \(t=6\).
12.1.1 Varianza e intervalos de confianza
Aplicando el método delta se obtiene primero la varianza de \(\log\hat S(t)\):
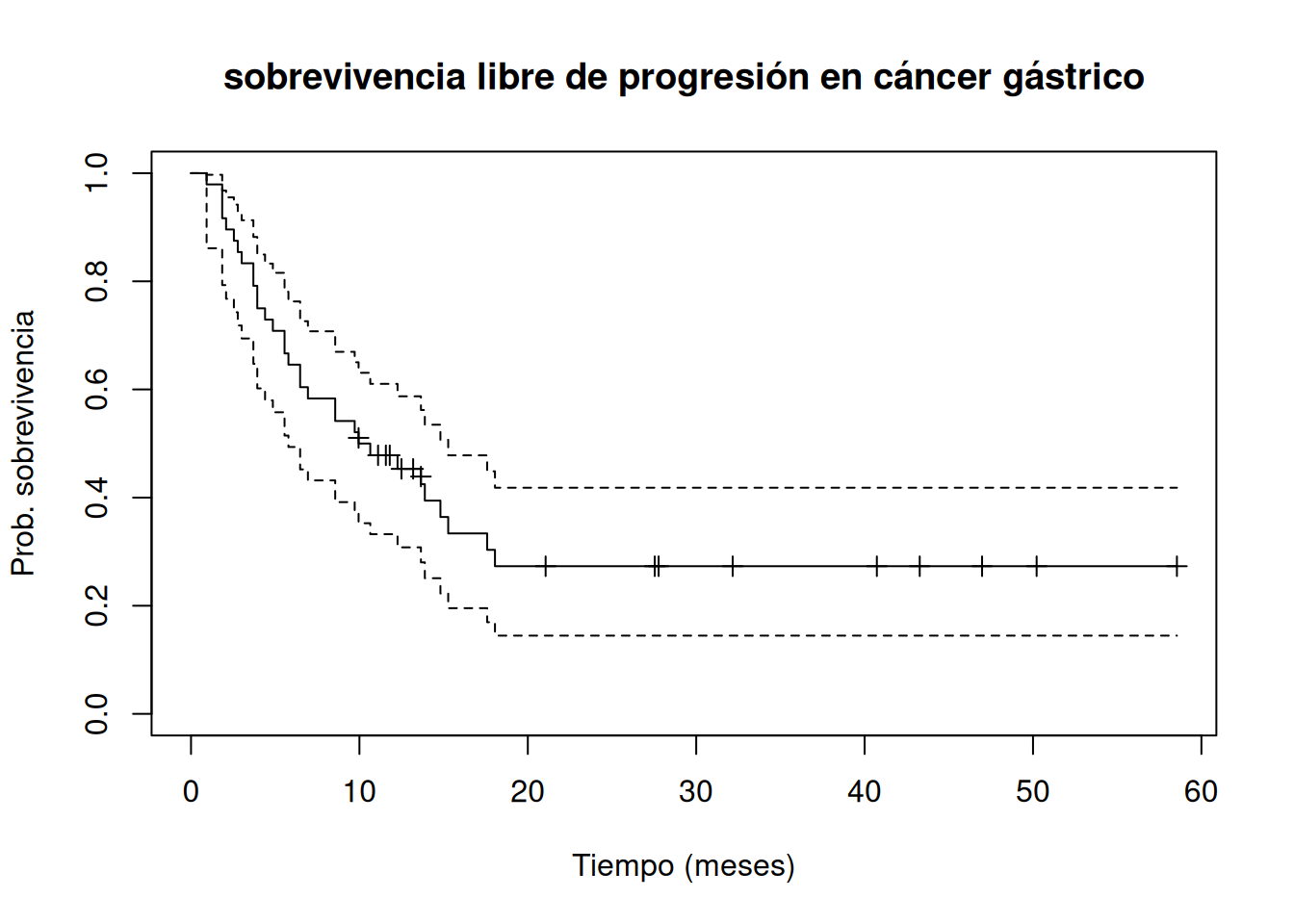
Este procedimiento ilustra cómo obtener y visualizar curvas de sobrevivencia no paramétricas con sus intervalos de confianza sin asumir una forma funcional específica de la distribución de tiempos.
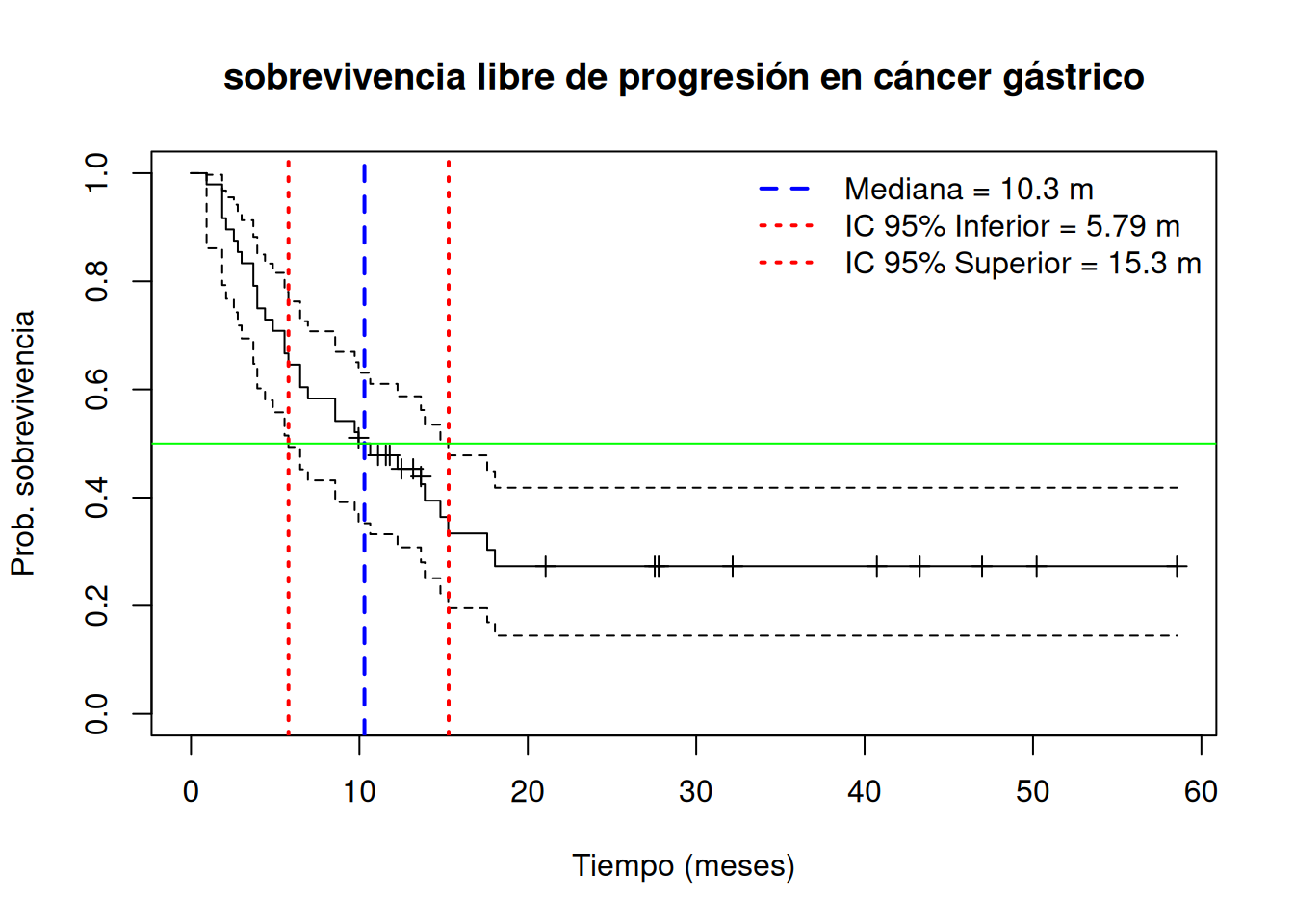
12.2 Cálculo de la mediana de sobrevivencia e intervalo de confianza
es decir, el menor tiempo \(t\) en que la función de sobrevivencia estimada cae por debajo de 0.5. Para obtener un intervalo de confianza de nivel \(1-\alpha\) se emplea la transformación log-log complementario
dando los límites inferior y superior del intervalo.
En la práctica, la función survfit() de R ya calcula y muestra la mediana con su intervalo de confianza al nivel deseado. Por ejemplo, en el análisis de sobrevivencia libre de progresión en cáncer gástrico:
La Figura 3.4 del Moore ilustra cómo la línea vertical en \(t=10.3\) meses marca la mediana, y las líneas en \(5.79\) y \(15.27\) meses muestran los límites del intervalo de confianza intersectando la curva de sobrevivencia y sus bandas de confianza.
El tiempo de seguimiento mediano es una medida de la “profundidad” del seguimiento en un ensayo clínico: indica cuánto tiempo, en promedio, han sido observados los pacientes. Sin embargo, su cálculo no es trivial.
Una forma sencilla consiste en tomar la mediana de todos los tiempos de seguimiento (independientemente de si están censurados o no). El problema es que un estudio con muchas muertes tempranas, pero con un seguimiento prolongado en los supervivientes, puede parecer que tiene un seguimiento breve.
Una alternativa más informativa es el seguimiento potencial, que invierte el papel de eventos y censuras. En este método (conocido como Kaplan–Meier inverso), tratamos las muertes como observaciones censuradas (su “verdadero” tiempo hubiera sido mayor) y las censuras como eventos. Calculamos entonces el estimador de Kaplan–Meier con este nuevo indicador de censura, y extraemos su mediana:
# Invertir el indicador de eventodelta.followup <-1- delta# Kaplan–Meier inverso para el seguimiento potencialkm.rev <-survfit(Surv(timeM, delta.followup) ~1)# Mediana de los tiempos (simple) vs. potencialmed_simple <-median(timeM)med_potencial <-27.8c("Mediana simple"= med_simple,"Mediana potencial (KM inverso)"= med_potencial)
En el ejemplo de los pacientes con cáncer gástrico tratados con Xelox, la mediana simple de seguimiento es de aproximadamente 9.95 meses, mientras que la mediana potencial (Kaplan–Meier inverso) alcanza 27.8 meses, reflejando mejor el largo periodo de observación activo en el estudio.
12.4 Estimación suavizada de la función de riesgo y de sobrevivencia
Al estimar la función de riesgo no paramétrica, el estimador puntual en cada tiempo de fallo \(t_{(i)}\) se define como
\[
\frac{d_i}{n_i}\,,
\]
pero su trazo “a saltos” tiende a ser muy inestable. Una forma más informativa es aplicar un suavizado kernel, centrando en cada \(t_{(i)}\) un kernel \(K(u)\) escalado por un ancho de banda \(b\). El estimador suavizado viene dado por
donde típicamente se elige el kernel de Epanechnikov
\[
K(u)=\tfrac34\,(1 - u^2)\quad\text{para }|u|\le1,\;0\text{ en otro caso.}
\]
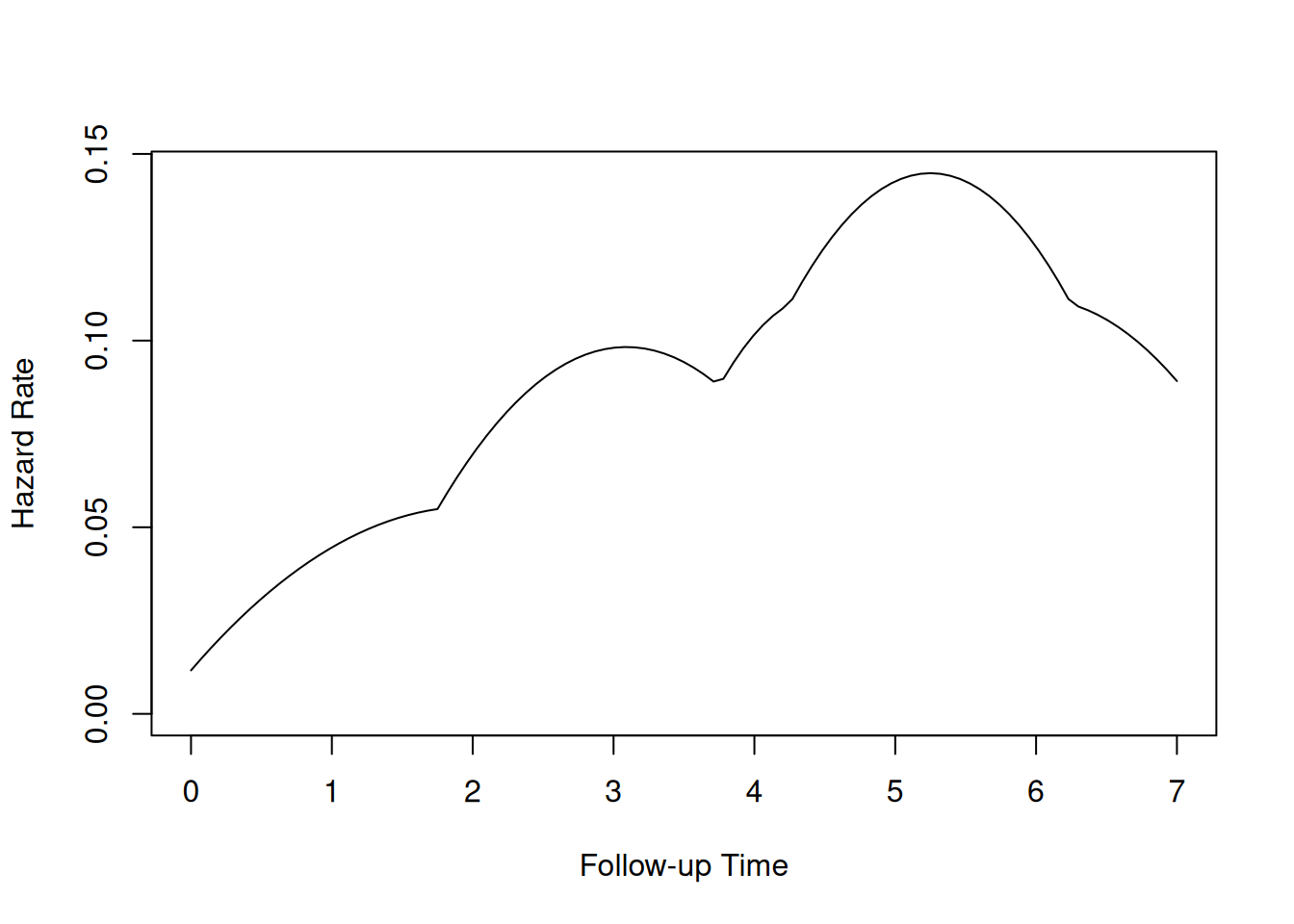
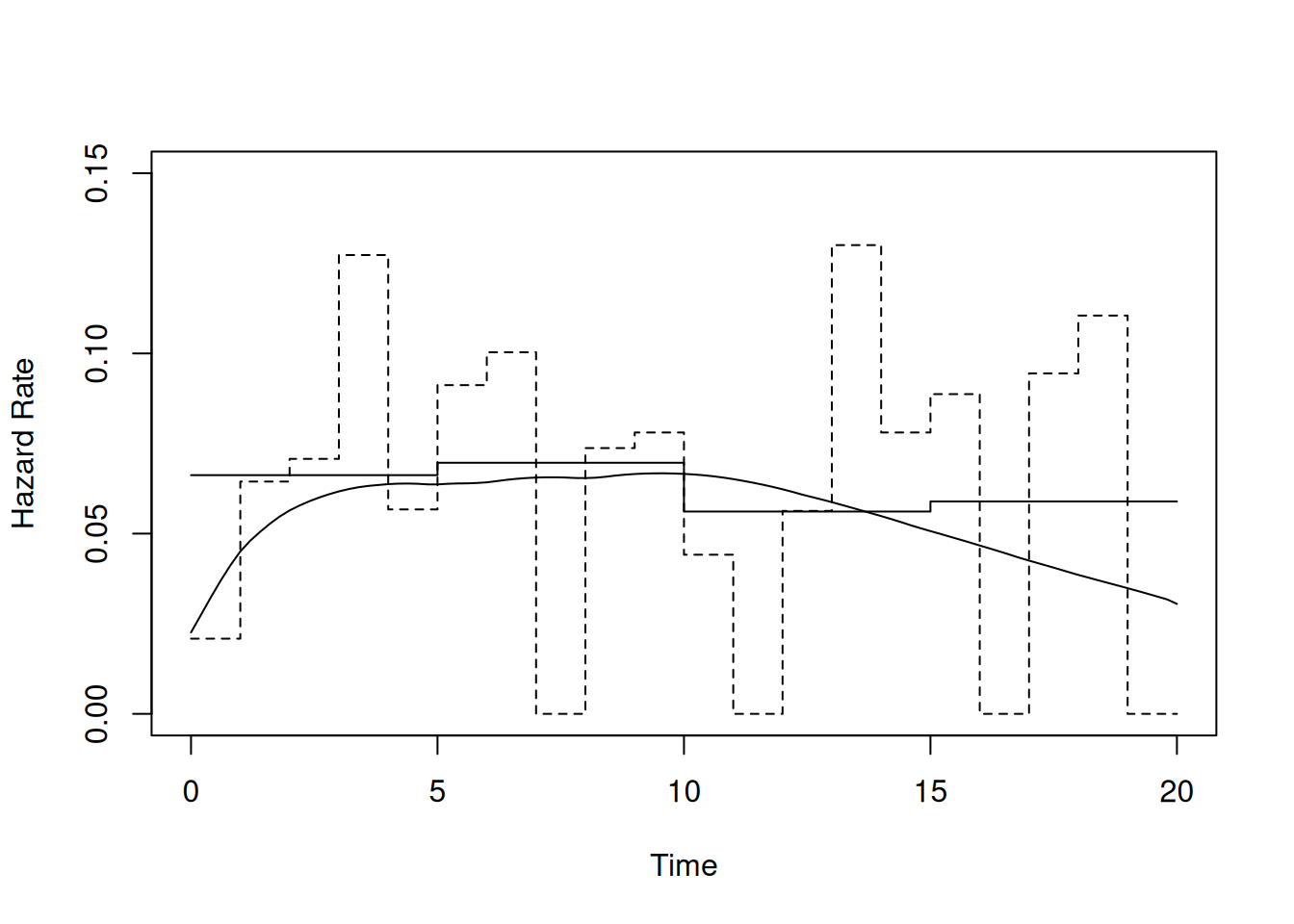
Un mayor \(b\) produce un suavizado más intenso. La Fig. 3.5 ilustra cómo, para los fallos en \(t=2,4,6\), la suma de estos kernels ajustados da una curva azul más lisa que los saltos grises de los estimadores puntuales.
En R, el paquete muhaz facilita este cálculo; por ejemplo, con los datos de la Tabla 1.1:
library(muhaz)# vectores de tiempos y censurast.vec <-c(7,6,6,5,2,4)cens.vec <-c(0,1,0,0,1,1)# estimador suavizado global (sin corrección de frontera)res.haz <-muhaz(t.vec, cens.vec,max.time =8,bw.grid =2.25,bw.method ="global",b.cor ="none")
Warning in muhaz(t.vec, cens.vec, max.time = 8, bw.grid = 2.25, bw.method = "global", : maximum time > maximum Survival Time
plot(res.haz)
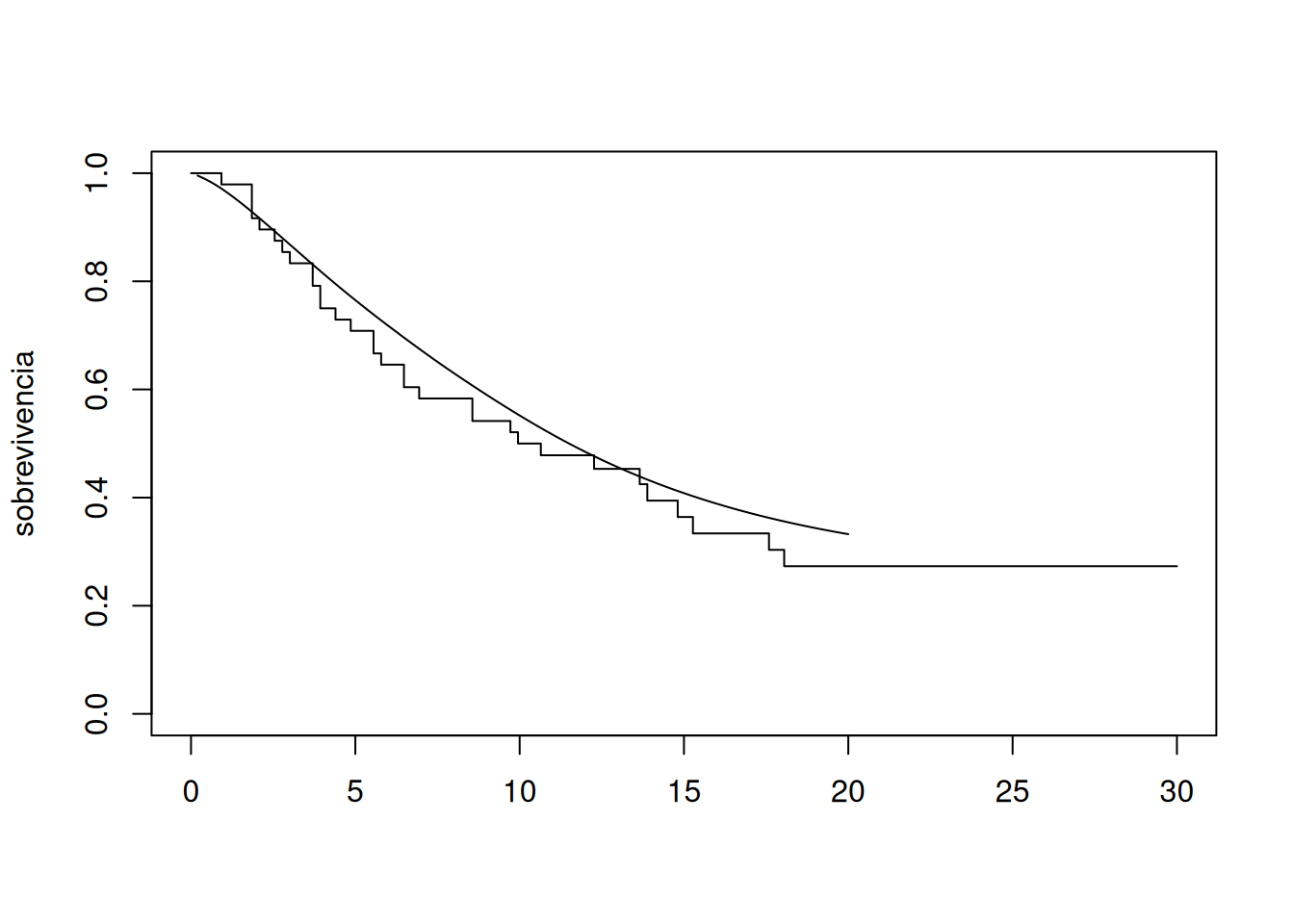
Para visualizar al mismo tiempo un estimador a saltos por intervalos fijos y el suavizado sobre datos de sobrevivencia (por ejemplo “gastricXelox”), puede emplearse también la función pehaz y luego superponer el suavizado con banda ancha y corrección de frontera izquierda:
Por último, dada la función de riesgo suavizada \(\hat h(u)\) en una grilla times, el estimador suavizado de sobrevivencia se obtiene numéricamente por
Esta figura muestra que la curva suavizada sigue de cerca a los “escalones” de Kaplan–Meier, aportando una visión continua de la evolución del riesgo y de la sobrevivencia.
12.5 Truncamiento por la izquierda
En algunos estudios interesa medir el tiempo desde un origen anterior al momento de entrada al estudio —por ejemplo, desde la fecha de diagnóstico de la enfermedad— pero solo observamos a quienes sobreviven hasta inscribirse en el ensayo. A este sesgo se le llama truncamiento por la izquierda: los sujetos con sobrevivencias muy cortas (que morirían antes de entrar) no llegan a registrarse y, por tanto, no aparecen en los datos.
Para corregir este sesgo hay que condicionar el análisis a que cada individuo haya sobrevivido al menos hasta su tiempo de truncamiento. La idea es la misma del estimador de Kaplan–Meier, pero ahora cada sujeto “entra” en el conjunto en riesgo en su tiempo de truncamiento\(L_i\), y “sale” en su tiempo de evento o censura \(T_i\). El estimador producto–límite se construye igual, salvo que en el recuento de sujetos en riesgo a cada instante sólo participan los que ya han entrado antes de ese instante, y aún no han tenido evento ni censura.
En R esto se especifica usando la función Surv(L_i, T_i, status, type="counting") dentro de survfit(). Por ejemplo, para los datos de la tabla inicial de esta sección se define el vector de tiempos de entrada tm.enter (–Diagnosis) y de salida tm.exit (SurvtimeDiag), y se obtiene tanto el estimador de Kaplan–Meier adaptado como el estimador de Nelson–Altschuler–Aalen (Fleming–Harrington).
A continuación se comparan ambos estimadores para los tiempos desde diagnóstico: las curvas resultantes coinciden en cuanto al primer descenso, pero el estimador Aalen no cae precipitadamente a cero cuando el conjunto en riesgo se vacía.
En muchas cohortes de supervivencia sucede que solo se observa a los individuos que sobreviven hasta el momento de su inclusión en el estudio. Este fenómeno, llamado truncamiento por la izquierda, introduce un sesgo porque quienes fallecen antes de poder inscribirse quedan fuera del análisis. Para ilustrar esto consideremos los datos de Channing House, una residencia de ancianos en Palo Alto (California), con 96 hombres y 361 mujeres. En este conjunto de datos:
entry es la edad (en meses) al ingreso a la residencia,
exit es la edad al fallecer, abandonar o al final del seguimiento,
cens vale 1 si el sujeto murió y 0 si fue censurado.
Para corregir el sesgo de truncamiento por la izquierda, entry se usa como tiempo de truncamiento (el sujeto solo entra en riesgo a partir de esa edad). A continuación se muestra cómo preparar los datos y estimar la supervivencia de los hombres usando primero el estimador de Kaplan–Meier (KM) y luego el estimador Nelson–Altschuler–Aalen (NAA):
library(survival)# Cargar y transformar las edades de meses a añoshead(ChanningHouse)
sex entry exit time cens
1 Male 782 909 127 1
2 Male 1020 1128 108 1
3 Male 856 969 113 1
4 Male 915 957 42 1
5 Male 863 983 120 1
6 Male 906 1012 106 1
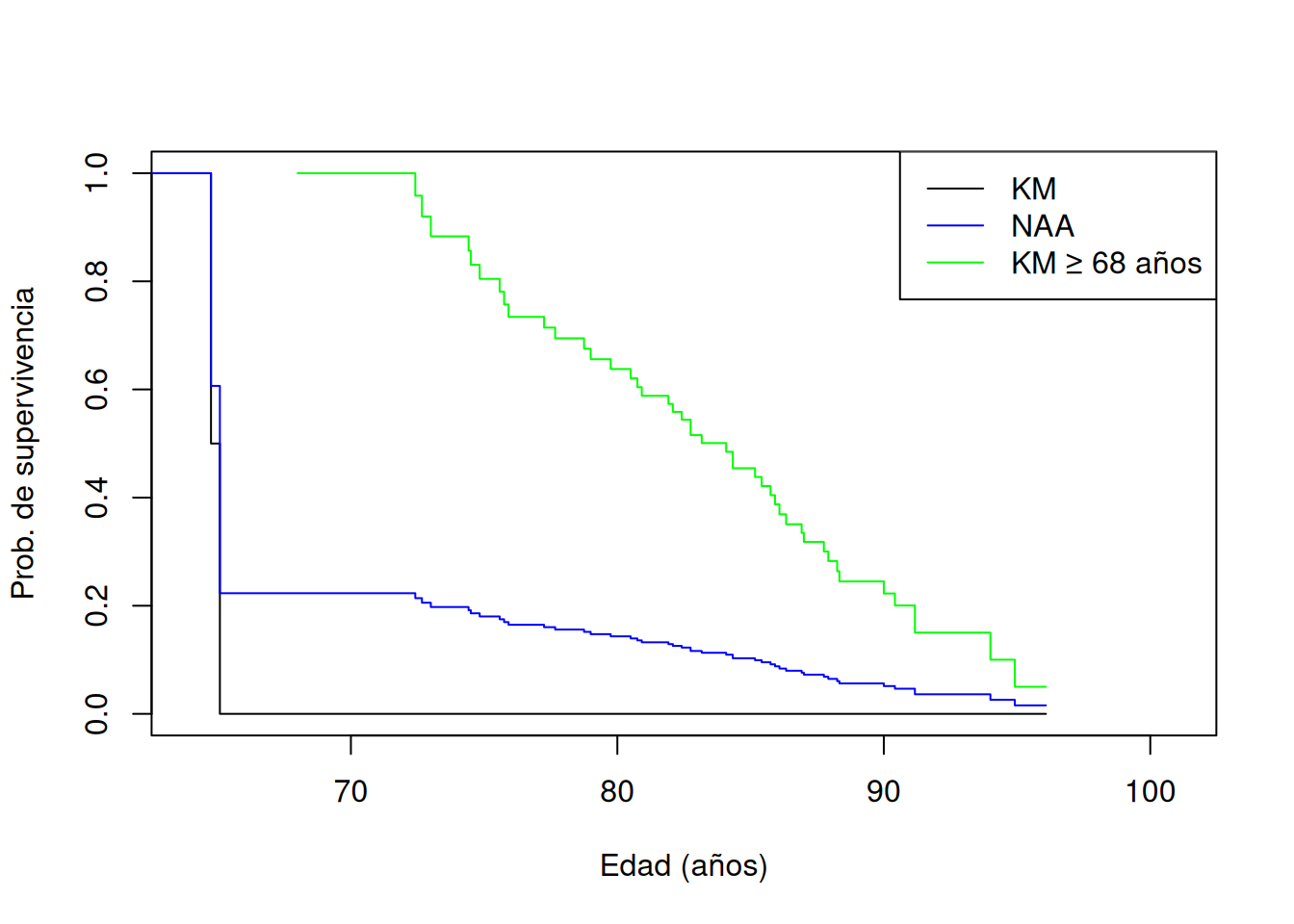
ChanningHouse <-within(ChanningHouse, { entryYears <- entry/12 exitYears <- exit/12})ChanningMales <-subset(ChanningHouse, sex =="Male")# Estimador Kaplan–Meier con left truncationresult.km <-survfit(Surv(entryYears, exitYears, cens, type="counting") ~1,data = ChanningMales)plot(result.km, xlim=c(64,101),ylim=c(0,1),xlab="Edad (años)", ylab="Prob. de supervivencia",conf.int=FALSE)# Estimador Nelson–Altschuler–Aalen (Fleming–Harrington)result.naa <-survfit(Surv(entryYears, exitYears, cens, type="counting") ~1,type="fleming-harrington", data = ChanningMales)lines(result.naa, col="blue", conf.int=FALSE)result.km.68<-survfit(Surv(entryYears, exitYears, cens, type="counting") ~1,start.time=68, data = ChanningMales)lines(result.km.68, col="green", conf.int=FALSE)legend("topright",legend=c("KM","NAA","KM ≥ 68 años"),col=c("black","blue","green"), lty=1)
El curva negra (KM) cae a cero alrededor de los 65 años porque, en esas edades tempranas, el tamaño del conjunto en riesgo se reduce a cero y el producto acumulado lo fuerza a cero. En cambio, la curva azul (NAA), al basarse en la exponentiación de una suma acumulada de riesgos, evita caer prematuramente a cero, aunque también desciende bruscamente cuando el riesgo es pequeño.
Para obtener una estimación más estable, podemos condicionar a aquellos hombres que hayan vivido al menos hasta los 68 años, especificando start.time=68.
La curva verde muestra la supervivencia condicional a haber alcanzado los 68 años y es mucho más razonable, ya que el conjunto en riesgo a partir de esa edad es suficientemente grande. De este modo, seleccionar un punto de truncamiento realista permite obtener estimaciones válidas con truncamiento por la izquierda.
12.6 Comparación de dos grupos de supervivencia
Cuando se comparan dos grupos de supervivencia, el objetivo es probar la hipótesis nula
\[
H_{0}:\ S_{1}(t)=S_{0}(t)
\]
contra alguna alternativa que refleje una mayor supervivencia en el grupo experimental respecto al control. En lugar de asumir un modelo paramétrico (por ejemplo, distribución exponencial o Weibull), se recurre a pruebas no paramétricas que usen las diferencias observadas en cada instante de fallo. Una forma práctica de plantear la alternativa es mediante la alternativa de Lehmann,
equivalente a asumir riesgos proporcionales\(h_{1}(t)=\psi h_{0}(t)\), para cuyo caso, bajo \(H_{A}\) con \(\psi<1\), la supervivencia del grupo 1 excede uniformemente a la del grupo 0.
12.6.1 Construcción de la prueba de log-rank
Para cada tiempo de fallo distinto \(t_{i}\) se construye una tabla de contingencia 2×2 que agrupa los “números en riesgo” y los “números de fallos” en controles (\(0\)) y tratamientos (\(1\)):
Control (\(0\))
Tratamiento (\(1\))
Total
Fallo (\(D\))
\(d_{0i}\)
\(d_{1i}\)
\(d_{i}=d_{0i}+d_{1i}\)
No falla
\(n_{0i}-d_{0i}\)
\(n_{1i}-d_{1i}\)
\(n_{i}-d_{i}\)
Total
\(n_{0i}\)
\(n_{1i}\)
\(n_{i}=n_{0i}+n_{1i}\)
Suponiendo independencia entre grupos y condicionando a que los márgenes \(d_{i},n_{i},n_{0i},n_{1i}\) estén fijos, el número de fallos en el grupo de control \(d_{0i}\) sigue una distribución hipergeométrica
Se comparan dos grupos (control C, tratamiento T), con seis sujetos:
Paciente
Survtime
Censor
Grupo
1
6
1
C
2
7+
0
C
3
10
1
T
4
15
1
C
5
19+
0
T
6
25
1
T
Los cuatro tiempos de falla son \(t=6,10,15,25\). Para cada uno, se calcula \(n_{0i},n_{1i},d_{0i},d_{1i}\) y luego \(e_{0i},v_{0i}\). El resultado acumulado es
donde \(\hat{S}(t_{i})\) es un estimador combinado de la supervivencia en \(t_{i}\). Cuando \(\rho=0\), \(w_{i}=1\) y se recupera el log-rank clásico. Si \(\rho=1\), se obtiene la modificación de Prentice (o Peto-Peto) que enfatiza las diferencias tempranas.
12.6.2.1 Ejemplo
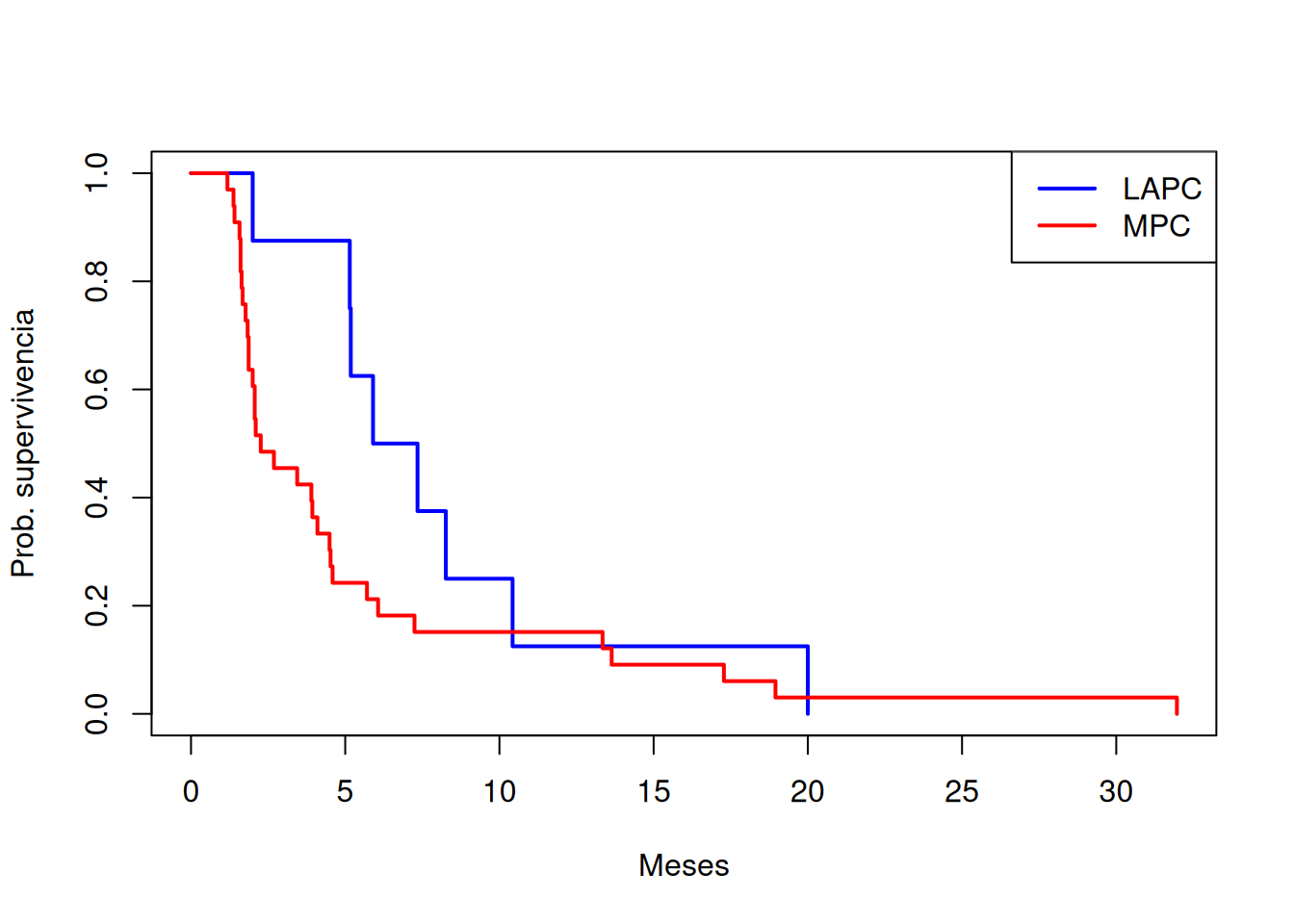
Se compara la supervivencia libre de progresión (PFS) en cáncer pancreático según etapa: “LAPC” (localmente avanzado) vs. “MPC” (metastásico). Con los datos del paquete asaur:
Como en la figura, el grupo MPC muestra una ventaja inicial en PFS, pero las curvas convergen tras los 10 meses. La prueba con \(\rho=1\) capta esa diferencia temprana, a diferencia del log-rank clásico.
12.7 Pruebas estratificadas
Cuando comparamos dos tratamientos en presencia de un covariable categórica de confusión (por ejemplo, centro de tratamiento, grupo etario o sexo), podemos ajustar sin recurrir inmediatamente a un modelo de riesgos proporcionales completo. Si la covariable tiene un número moderado de niveles \(G\), basta con realizar una prueba log-rank estratificada. En este enfoque, para cada estrato \(g=1,\dots,G\) se calcula el estadístico no estratificado
donde \(d_{0i}\) y \(e_{0i}\) son, respectivamente, los fallos observados y esperados (bajo la hipótesis de igualdad de curvas) en el grupo control, dentro del estrato, en el instante \(t_i\). El estadístico global se construye entonces como
que, bajo la hipótesis nula de iguales funciones de riesgo en cada estrato (\(h_{0j}(t)=h_{1j}(t)\) para todo \(j=1,\dots,G\)), se compara con una \(\chi^{2}\) de 1 grado de libertad.
12.7.1 Ejemplo: fármaco versus placebo, estratificado por edad
En el conjunto de datos pharmacoSmoking (paquete asaur) se compara el tiempo hasta la recaída en dos grupos de tratamiento: “combination” versus “patchOnly”. La prueba log-rank sin ajustar da:
Call:
survdiff(formula = Surv(ttr, relapse) ~ grp + strata(ageGroup2),
data = pharmacoSmoking)
N Observed Expected (O-E)^2/E (O-E)^2/V
grp=combination 61 37 49.1 2.99 7.03
grp=patchOnly 64 52 39.9 3.68 7.03
Chisq= 7 on 1 degrees of freedom, p= 0.008
El valor de \(\chi^{2}\) cambia poco respecto al no estratificado, por lo que la edad no era un confusor relevante en este caso.
12.7.2 Ejemplo: Sesgo por genotipo
Se simula un ensayo clínico donde, además del tratamiento (control vs. experimental), existe un covariable de genotipo (“mutant” vs. “wt”) que confunde la comparación. Se asume que los tiempos de supervivencia siguen una distribución exponencial sin censura:
Tasa de fallo (hazard) de un paciente “mutant” en control: \(\lambda_{\text{mutant},0} = 0.03.\)
El tratamiento reduce el hazard en un factor 0.55, de modo que \(\lambda_{\text{mutant},1} = 0.03 \times 0.55.\)
Los “wild type” (wt) tienen un hazard 20 % del de los “mutant”, y el factor de tratamiento es el mismo: \(\lambda_{\text{wt},0} = 0.03 \times 0.2,\qquad \lambda_{\text{wt},1} = 0.03 \times 0.2 \times 0.55.\)
En R, se generan muestras exponenciales con estos parámetros, con tamaños desiguales para producir la confusión:
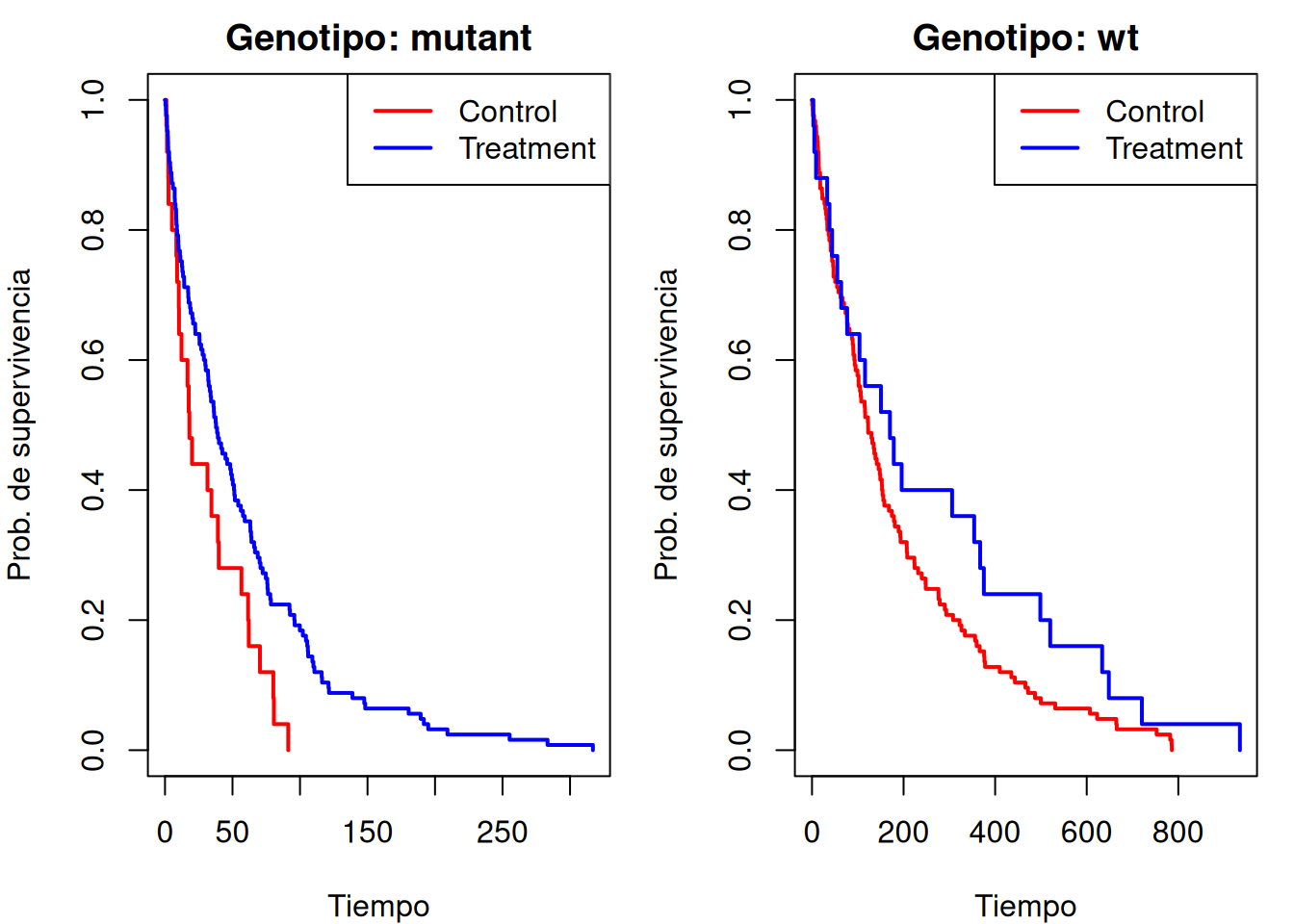
El test indica erróneamente que el tratamiento empeora la supervivencia. Sin embargo, si graficamos las curvas de Kaplan–Meier por separado para cada genotipo, vemos que en ambos (“mutant” y “wt”) el tratamiento sí mejora la supervivencia.
# Ajuste de Kaplan–Meier por cada genotipofit.mutant <-survfit(Surv(ttAll[genotype=="mutant"], status[genotype=="mutant"]) ~ trt[genotype=="mutant"])fit.wt <-survfit(Surv(ttAll[genotype=="wt"], status[genotype=="wt"]) ~ trt[genotype=="wt"])# Gráficos en paneles: mutuantes (izquierda) y wild-type (derecha)par(mfrow =c(1, 2), mar =c(4, 4, 2, 1))# Panel 1: genotipo “mutant”plot(fit.mutant, col =c("red", "blue"), lwd =2,xlab ="Tiempo", ylab ="Prob. de supervivencia",main ="Genotipo: mutant")legend("topright", legend =c("Control", "Treatment"),col =c("red", "blue"), lwd =2)# Panel 2: genotipo “wt”plot(fit.wt, col =c("red", "blue"), lwd =2,xlab ="Tiempo", ylab ="Prob. de supervivencia",main ="Genotipo: wt")legend("topright", legend =c("Control", "Treatment"),col =c("red", "blue"), lwd =2)
Para ajustar la confusión, realizamos un test log-rank estratificado por genotipo:
survdiff(Surv(ttAll, status) ~ trt +strata(genotype))
Call:
survdiff(formula = Surv(ttAll, status) ~ trt + strata(genotype))
N Observed Expected (O-E)^2/E (O-E)^2/V
trt=control 150 150 133 2.17 7.57
trt=treatment 150 150 167 1.73 7.57
Chisq= 7.6 on 1 degrees of freedom, p= 0.006
Ahora queda claro—tanto por la prueba como por la gráfica—que el tratamiento experimental mejora la supervivencia cuando se controla el genotipo.