mide la tasa instantánea de fallo en \(t\), esto es, la probabilidad de morir en el siguiente intervalo infinitesimal, condicionada a haber sobrevivido hasta \(t\).
Estas dos funciones están íntimamente relacionadas: a partir de \(h(t)\) se recupera
\[
S(t)=\exp\Bigl(-\int_0^t h(u)\,du\Bigr).
\]
Por ejemplo, un riesgo muy alto al inicio de la vida produce una supervivencia que cae bruscamente, mientras que un riesgo bajo al principio y creciente después genera una curva de supervivencia con caída más suave inicial seguida de un declive más marcado en edades avanzadas.
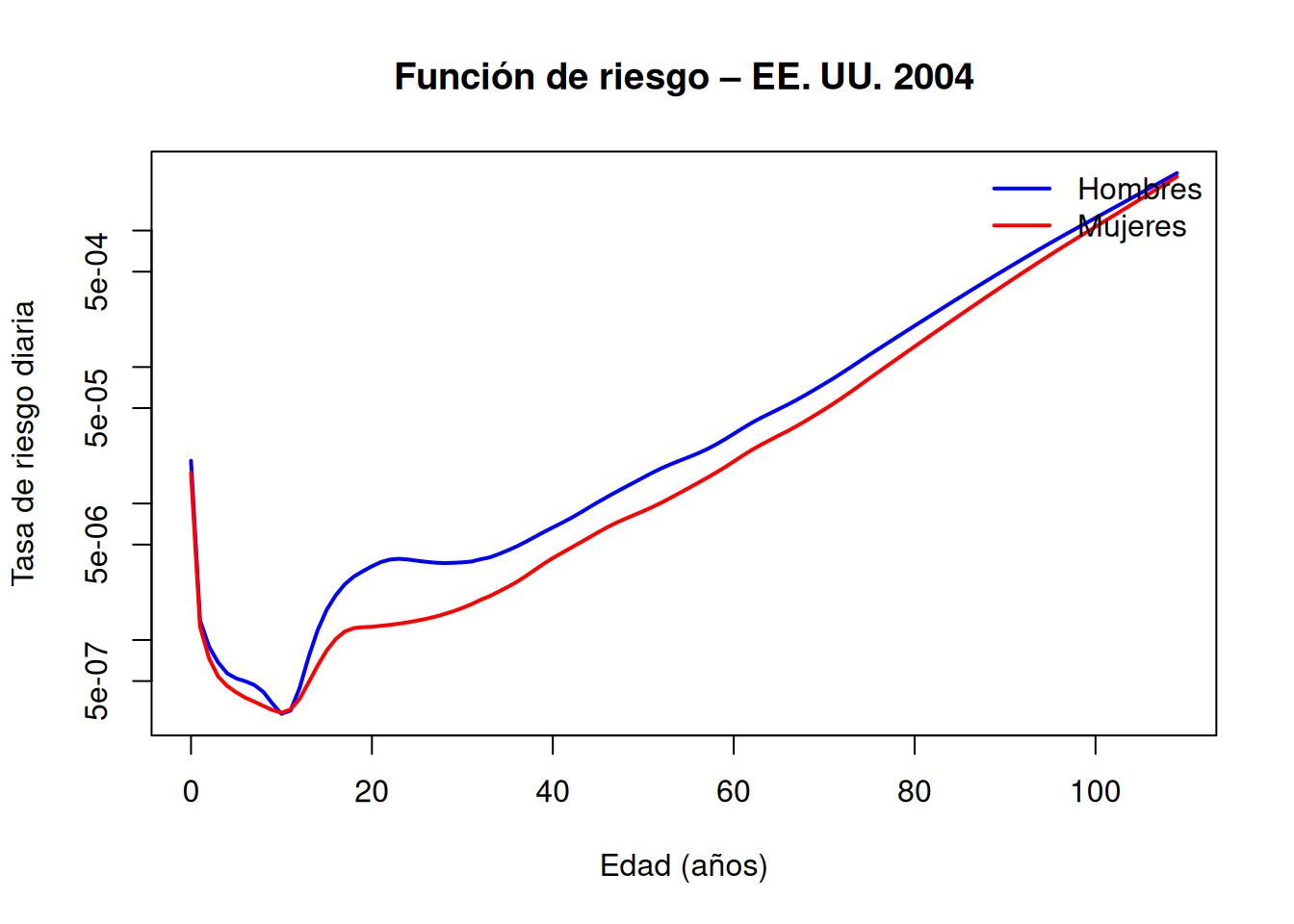
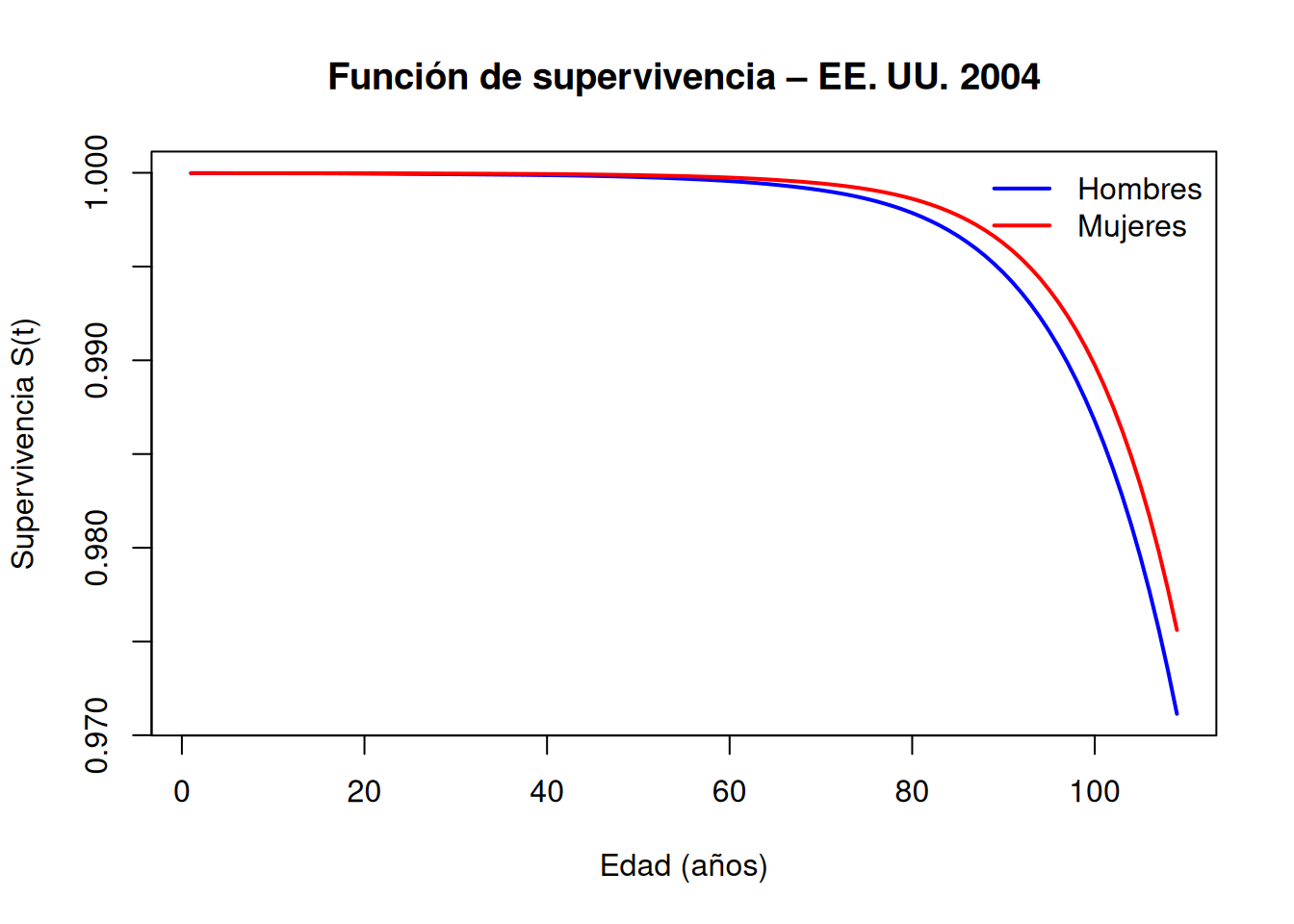
Ejemplo Con los datos demográficos de EE. UU. en 2004 (paquete survival de R), las tasas diarias de mortalidad por edad muestran un riesgo neonatal muy alto que se atenúa tras el primer mes, un ligero repunte en la adolescencia y un aumento sostenido a partir de la mediana edad. Además, los hombres presentan sistemáticamente un \(h(t)\) superior al de las mujeres. Las curvas de supervivencia derivadas de estas funciones de riesgo ilustran cómo la supervivencia global oculta cambios de riesgo muy marcados en etapas tempranas o tardías de la vida:
# 1) Cargar paquete y extraer datoslibrary(survival)# Extraer el vector de “edades” (en días) a partir de los nombres de las filasageDays <-as.numeric(dimnames(survexp.us)[[1]])#ageYears <- ageDays / 365ageYears <- ageDayshazMale <- survexp.us[, "male", "2004"]hazFemale <- survexp.us[, "female", "2004"]# 2) Gráfico de la función de riesgo (hazard) en escala logplot(ageYears, hazMale, type="l", log="y", col="blue", lwd=2,xlab="Edad (años)", ylab="Tasa de riesgo diaria",main="Función de riesgo – EE. UU. 2004")lines(ageYears, hazFemale, col="red", lwd=2)legend("topright", legend=c("Hombres","Mujeres"),col=c("blue","red"), lwd=2, bty="n")
# 3) Cálculo aproximado de la función de supervivencia# S(t) ≈ exp(–∫ h(u) du) por método del trapeciodt <-diff(ageYears)cumhazMale <-cumsum(hazMale[-length(hazMale)] * dt)cumhazFemale <-cumsum(hazFemale[-length(hazFemale)] * dt)survMale <-exp(-cumhazMale)survFemale <-exp(-cumhazFemale)# 4) Gráfico de la función de supervivenciaplot(ageYears[-1], survMale, type="l", col="blue", lwd=2,xlab="Edad (años)", ylab="Supervivencia S(t)",main="Función de supervivencia – EE. UU. 2004")lines(ageYears[-1], survFemale, col="red", lwd=2)legend("topright", legend=c("Hombres","Mujeres"),col=c("blue","red"), lwd=2, bty="n")
11.2 Otras representaciones de la función de sobrevivencia
El análisis de supervivencia puede representarse de varias maneras equivalentes:
Función de distribución acumulada (CDF)\(F(t)=\Pr(T\le t)\,,\quad 0<t<\infty\,,\) también llamada función de riesgo acumulado. Satisface \(F(t)=1-S(t)\).
Función de densidad (PDF)\(f(t)=\frac{d}{dt}F(t)=-\frac{d}{dt}S(t)\,,\) que mide la tasa instantánea de ocurrencia del evento en \(t\).
Relación PDF–hazard–supervivencia\(h(t)=\frac{f(t)}{S(t)}\,,\) donde \(h(t)\) es la función de riesgo instantáneo.
Función de riesgo acumulado (cumulative hazard)\(H(t)=\int_{0}^{t}h(u)\,du\,.\)
Gracias a esta última, la supervivencia se expresa como
Esta relación permite pasar de un hazard dado a la supervivencia correspondiente (y viceversa) y es la clave para construir curvas de supervivencia a partir de riesgos instantáneos.
11.3 Tiempo medio y mediano de supervivencia
El tiempo medio de supervivencia se define como el valor esperado de la variable aleatoria de supervivencia \(T\),
Esta expresión muestra que el área bajo la curva de supervivencia \(S(t)\) es justamente la esperanza de \(T\). El tiempo medio sólo existe si \(S(\infty)=0\) (es decir, si eventualmente todos los sujetos presentan el evento). Cuando existe una fracción de “curados” con \(S(\infty)=c>0\), la integral diverge y el tiempo medio no está definido. En la práctica, para estimar una media finita a partir de una curva de Kaplan–Meier que no llega a cero, a veces se impone un tiempo máximo de seguimiento.
El tiempo mediano de supervivencia es el valor \(t\) tal que
\[
S(t)=\tfrac12\,.
\]
Si \(S(t)\) presenta saltos, se toma el tiempo mediano como el menor \(t\) que satisface \(S(t)\le\tfrac12\). Cuando la curva de supervivencia jamás desciende por debajo de \(0.5\) durante el periodo observado, el tiempo mediano no está definido.
11.4 Distribuciones paramétricas de supervivencia
En análisis de supervivencia a menudo se elige una familia paramétrica para describir la forma de la función de riesgo y supervivencia. A continuación se resumen dos de las más utilizadas.
11.4.1 Distribución exponencial
La distribución exponencial supone un riesgo constante
\[
h(t)=\lambda\,,\quad t>0.
\]
De aquí se obtiene directamente la función de riesgo acumulado
En R disponemos de las funciones dweibull(), pweibull() y rweibull(). Por ejemplo, para trazar la supervivencia y el riesgo para \(\alpha=1.5\) y \(\lambda=0.03\):
donde \(\beta>0\) es forma y \(\lambda>0\) tasa. Su función de varianza \(V(\mu)\propto\mu^2\) la hace adecuada para datos con coeficiente de variación constante. El riesgo resulta