En aplicaciones biomédicas las técnicas no paramétricas (p. ej. estimador KM) y semiparamétricas (p. ej. modelo de riesgos proporcionales de Cox) suelen ser las más empleadas por su flexibilidad para ajustarse a formas arbitrarias de la función de riesgo. Sin embargo, los modelos paramétricos siguen siendo útiles cuando los datos de supervivencia se ajustan aproximadamente a una familia conocida, ya que:
Tienen un número fijo y pequeño de parámetros desconocidos, lo que facilita la estimación e inferencia mediante la teoría de la verosimilitud estándar.
Permiten tratar de modo más directo patrones complejos de censura y truncamiento.
Su validez depende, eso sí, de la adecuación del modelo a los datos.
Anteriormente se introdujeron varias familias paramétricas (exponencial, Weibull, gamma, …). En este capítulo se hace hincapié en la distribución exponencial y la Weibull, las más utilizadas en práctica, y se comentan brevemente otros modelos.
15.2 La distribución exponencial
La distribución exponencial es el caso más simple y se caracteriza por tener una tasa de riesgo constante:
\[
h(t)=\lambda,
\]
lo que le otorga la propiedad de pérdidad de memoria: el riesgo instantáneo es igual en cualquier punto del tiempo al riesgo inicial.
Función de densidad: \(f(t;\lambda)=\lambda\,e^{-\lambda t}.\)
Función de supervivencia: \(S(t;\lambda)=e^{-\lambda t}.\)
Para construir la verosimilitud con datos censurados a la derecha, basta multiplicar
la densidad \(f(t_i;\lambda)\) para cada observación con evento (\(\delta_i=1\)),
la supervivencia \(S(t_i;\lambda)\) para cada observación censurada (\(\delta_i=0\)).
Por su sencillez, la exponencial es muy útil en cálculos de potencia y tamaño de muestra. No obstante, al carecer de flexibilidad en la forma de \(h(t)\) (siempre constante), a menudo se prefiere la Weibull —que añade un parámetro de forma— para modelar supervivencias reales.
Nota: cuando \(T\sim\mathrm{Exp}(\lambda)\), entonces \(T^\alpha\sim\mathrm{Weibull}(\alpha,\lambda)\), lo que muestra que la exponencial es un caso particular de la Weibull.
15.3 El modelo Weibull
15.3.1 Diagnóstico de ajuste Weibull en una sola muestra
La distribución Weibull, con parámetros de forma \(\alpha\) y escala \(\lambda\), tiene \[
h(t)=\alpha\,\lambda^{\alpha}\,t^{\alpha-1},
\qquad
S(t)=\exp\bigl[-(\lambda t)^{\alpha}\bigr].
\]
Usando en su lugar \[
\sigma=\frac1\alpha,
\quad
\mu=-\log\lambda,
\]
se reescriben \[
h(t)=\frac1\sigma\,e^{-\mu/\sigma}\,t^{1/\sigma-1},
\qquad
S(t)=\exp\bigl[-e^{-\mu/\sigma}\,t^{1/\sigma}\bigr].
\]
Si aplicamos la transformación complemento‐log‐log \[
g(u)=\log\bigl[-\log(u)\bigr],
\]
a \(S_i=S(t_i)\) obtenemos la relación lineal \[
\log\bigl[-\log S_i\bigr]
=\alpha\log\lambda+\alpha\log t_i
=-\frac\mu\sigma+\frac1\sigma\log t_i.
\]
Por tanto, para valorar si los datos siguen una Weibull, se procede así:
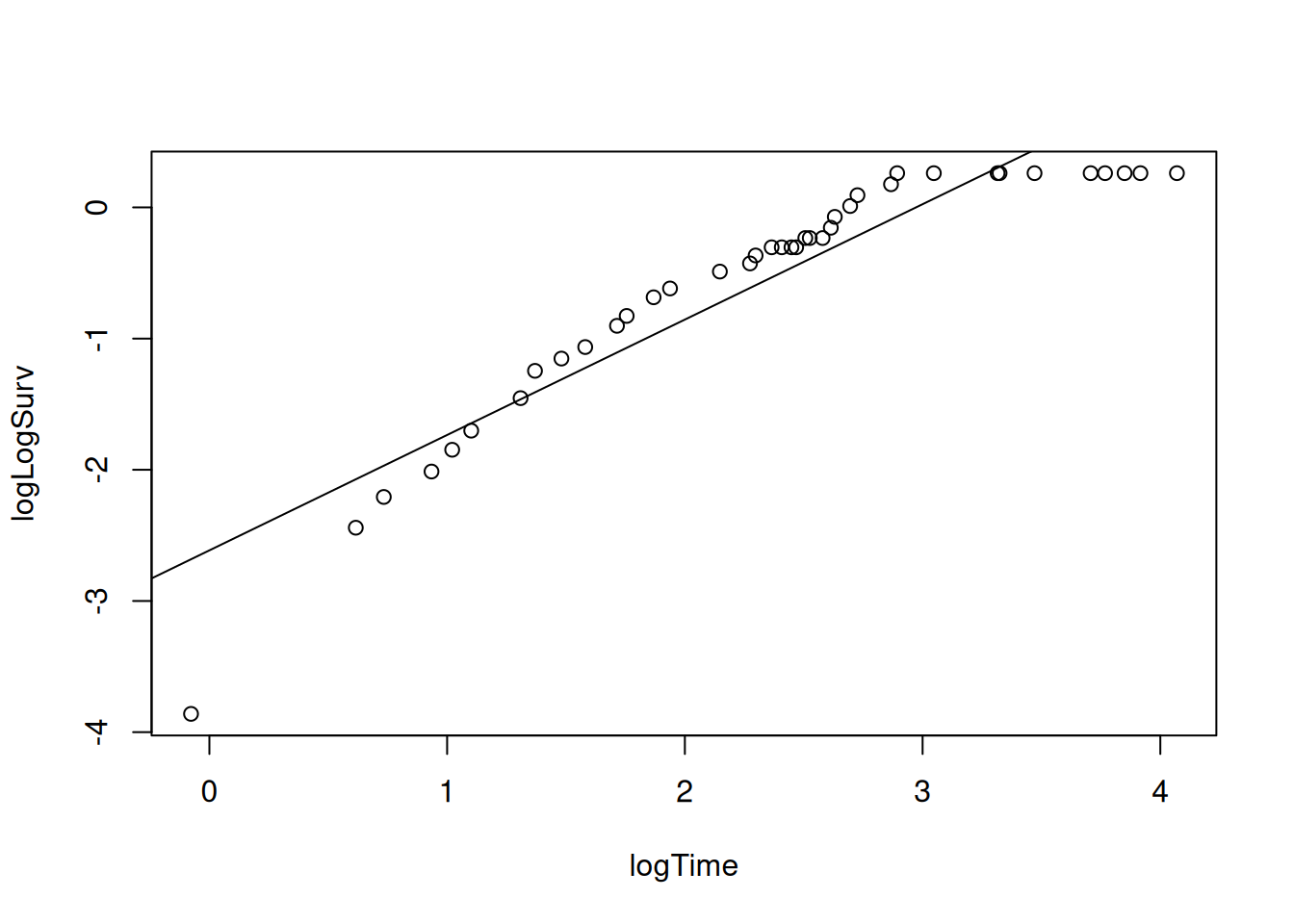
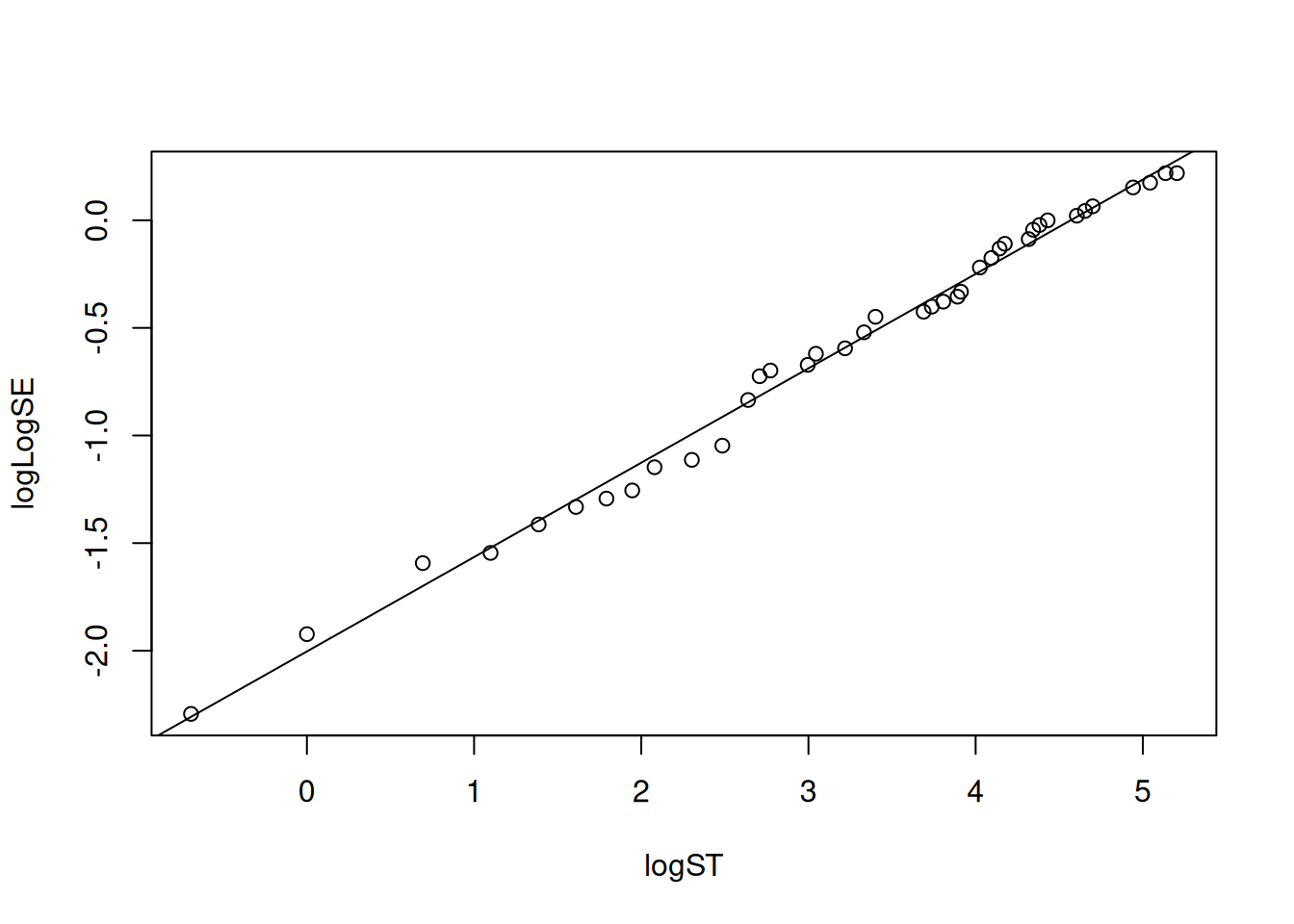
Calcular la estimación de Kaplan–Meier \(\hat S(t_i)\).
Aquí los puntos caen muy cerca de la línea, indicando un buen ajuste Weibull.
De la pendiente \(m=0.4385\) y la ordenada \(b=-2.0032\) obtenemos \(\sigma=\frac1m=2.280,\qquad \mu=-\frac b m=4.568.\)
15.3.2 Estimación por Máxima Verosimilitud de Parámetros Weibull
Sea una muestra de tamaño \(n\) con tiempos \(t_i\) y indicadores \(\delta_i\) (1=evento, 0=censura). La función de verosimilitud para el modelo Weibull, con tasa de eventos \(d=\sum\delta_i\), es
Para facilitar la optimización, reparametrizamos en términos de \[
\sigma=\frac1\alpha,
\quad
\mu=-\log\lambda,
\]
y codificamos la log‐verosimilitud en R como:
Call:
survreg(formula = Surv(ttr, relapse) ~ 1, dist = "weibull")
Value Std. Error z p
(Intercept) 4.6563 0.2170 21.46 < 2e-16
Log(scale) 0.7135 0.0919 7.76 8.3e-15
Scale= 2.04
Weibull distribution
Loglik(model)= -466.1 Loglik(intercept only)= -466.1
Number of Newton-Raphson Iterations: 5
n= 125
El intercepto \(\hat\mu=4.656\) coincide con la optimización manual.
El parámetro de escala \(\hat\sigma=\exp(0.713)=2.04\) es cercano a \(2.041\).
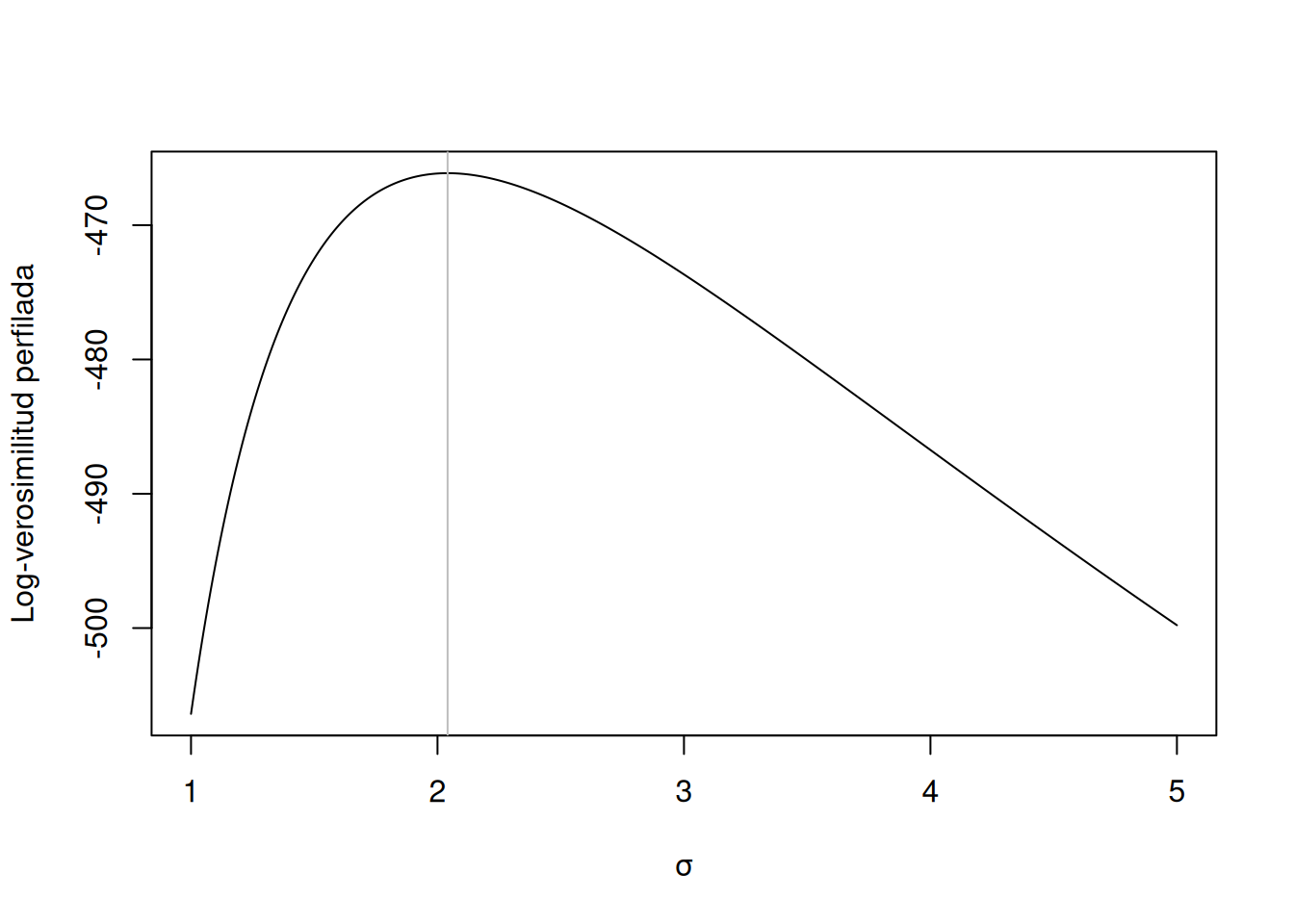
15.3.3 Verosimilitud de perfil Weibull
Se aprovecha la propiedad de que, para un valor fijo de \(\alpha\): \[T^*=T^\alpha\sim\mathrm{Exp}(\lambda^\alpha)\] de modo que el MLE de \(\lambda\) es
Este gráfico muestra el máximo en \(\hat\sigma\), confirmando los valores obtenidos por optimización.
15.3.4 Ajuste Weibull por dos puntos
Podemos ajustar una Weibull que pase exactamente por dos puntos \((t_{1},s_{1})\) y \((t_{2},s_{2})\) del estimador de Kaplan–Meier resolviendo el sistema lineal que surge de la transformación \[y_i=\log\bigl[-\log(s_i)\bigr]=\alpha\log\lambda+\alpha\log(t_i),\quad i=1,2.\] De ahí se obtiene la solución cerrada
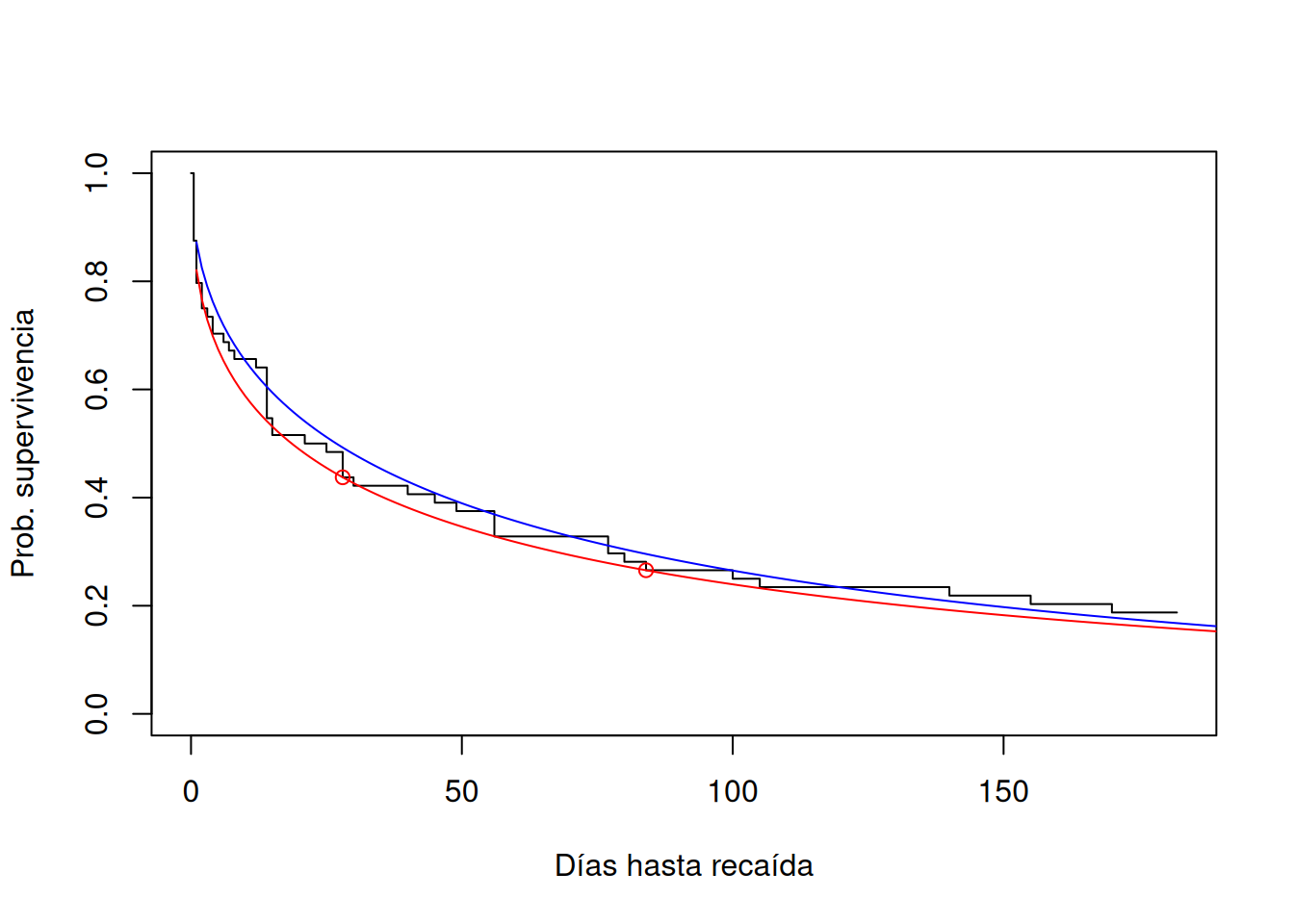
# 4) Comparación gráficaplot(result.surv, conf.int=FALSE,xlab="Días hasta recaída",ylab="Prob. supervivencia")lines(s.mle.vals ~ t.vals, col="blue") # Weibull MLElines(s.vals ~ t.vals, col="red") # Weibull por dos puntospoints(t.vec, s.vec, col="red") # puntos de ajuste
En la figura anterior se ve que la curva roja (Weibull por dos puntos) y la azul (MLE) son bastante similares, y ambas aproximan bien al escalón de Kaplan–Meier.
15.3.5 Modelo Weibull AFT
En el modelo Accelerated Failure Time (AFT) se asume que el tiempo de supervivencia bajo tratamiento, \(T_{1}\), es un múltiplo del que habría tenido bajo control, \(T_{0}\):
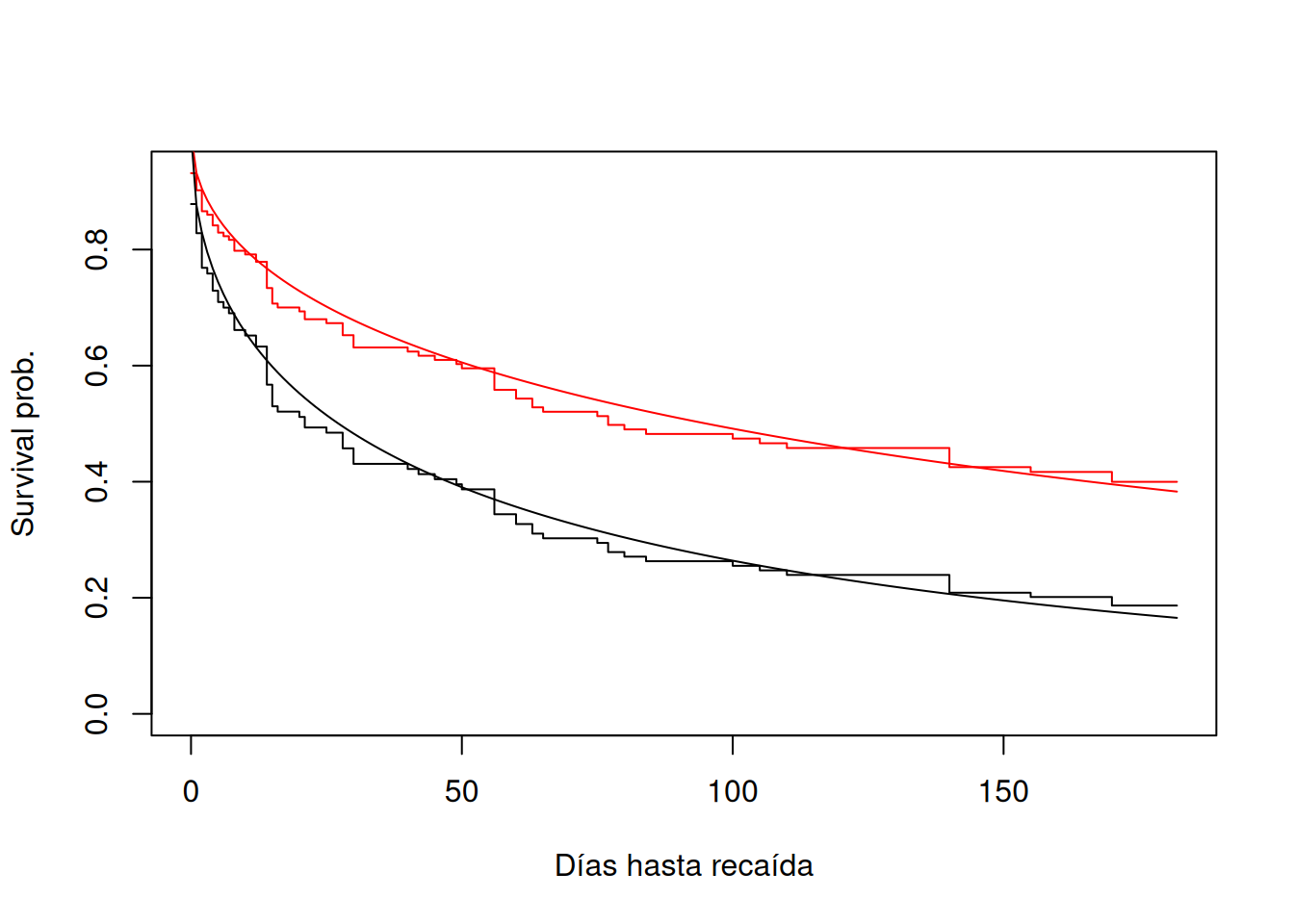
En la Figura resultante se visualizan en step las curvas de Cox y en líneas suaves las estimaciones Weibull, mostrando su buena concordancia.
15.3.6 Enfoque de regresión para el modelo Weibull
En el enfoque de regresión AFT Weibull, en lugar de trabajar directamente con funciones de riesgo, modelamos el log-tiempo de supervivencia como un modelo de localización-escala:
\[
\log(t)=\mu+\gamma\,z+\sigma\,\epsilon^{*},
\]
donde:
\(z\) es el indicador de grupo (0=control, 1=tratamiento),
\(\mu\) y \(\gamma\) son parámetros de intercepto y efecto del grupo,
\(\sigma\) es el parámetro de escala (relacionado con la forma de la Weibull, \(\alpha=1/\sigma\)),
\(\epsilon^{*}=\log\varepsilon\) con \(\varepsilon\sim\text{Exp}(1)\), de modo que \(\epsilon^{*}\) sigue una distribución valor extremo.
Bajo este modelo:
La supervivencia de grupo control cumple \(T_{0}\sim\mathrm{Weibull}(\lambda=e^{-\mu},\alpha=1/\sigma)\).
El efecto de tratamiento acelera (o retrasa) los tiempos en un factor \(e^{\gamma}\), equivalente al hazard ratio \(e^{-\gamma/\sigma}\) en el modelo de riesgos proporcionales.
Esta formulación sugiere además que, si en lugar de \(\epsilon^{*}=\log\varepsilon\) (valor extremo) se elige otro error:
\(\epsilon\sim N(0,1)\) → modelo log-normal,
\(\epsilon\) con c.d.f. logística → modelo log-logístico,
se obtienen otras familias paramétricas de supervivencia.
15.3.7 Ajuste Weibull AFT con varias covariables
En los modelos Weibull AFT con varias covariables, se ajustan estadísticos de supervivencia de la misma forma que en Cox, pero usando survreg(..., dist="weibull"). Por ejemplo, en los datos pharmacoSmoking:
# Cox proporcional de referenciamodelAll2.coxph <-coxph(Surv(ttr, relapse) ~ grp + age + employment)summary(modelAll2.coxph)
A continuación, el ajuste Weibull AFT con las mismas covariables:
model.pharm.weib <-survreg(Surv(ttr, relapse) ~ grp + age + employment,dist="weibull")summary(model.pharm.weib)
Call:
survreg(formula = Surv(ttr, relapse) ~ grp + age + employment,
dist = "weibull")
Value Std. Error z p
(Intercept) 2.4024 0.9653 2.49 0.0128
grppatchOnly -1.1902 0.4133 -2.88 0.0040
age 0.0697 0.0203 3.43 0.0006
employmentother -1.3890 0.5029 -2.76 0.0057
employmentpt -1.3143 0.6132 -2.14 0.0321
Log(scale) 0.6313 0.0900 7.02 2.3e-12
Scale= 1.88
Weibull distribution
Loglik(model)= -454.1 Loglik(intercept only)= -466.1
Chisq= 23.96 on 4 degrees of freedom, p= 8.2e-05
Number of Newton-Raphson Iterations: 5
n= 125
Diferencias clave respecto a Cox:
Intercepto y Log(scale) definen la Weibull basal (líneas (Intercept) y Log(scale)).
Los coeficientes grppatchOnly, age, … son parámetros AFT (\(\gamma_j\)): un valor negativo indica acortamiento de tiempos; el factor de aceleración es \(e^{\gamma_j}\).
Bajo Weibull la correspondencia con riesgos proporcionales es
predictor beta_PH_weibull beta_PH_cox
grppatchOnly grppatchOnly 0.63301278 0.60788405
age age -0.03708786 -0.03528934
employmentother employmentother 0.73878031 0.70347664
employmentpt employmentpt 0.69903157 0.65369019
Vemos que los \(\beta_j\) convertidos del AFT Weibull coinciden muy bien (diferencias < 7 %) con los del modelo de Cox.
15.3.8 Selección de Modelos y Análisis de Residuos
En el contexto de un modelo Weibull con múltiples covariables, podemos reutilizar las herramientas de selección de modelo y diagnóstico por residuos vistas para Cox. Por ejemplo, ajustamos un modelo inicial con todas las covariables y aplicamos eliminación para atrás usando AIC:
La selección final coincide con el modelo de la sección anterior, conservando sólo grp, age y employment.
Para el análisis de residuos de devianza, usamos:
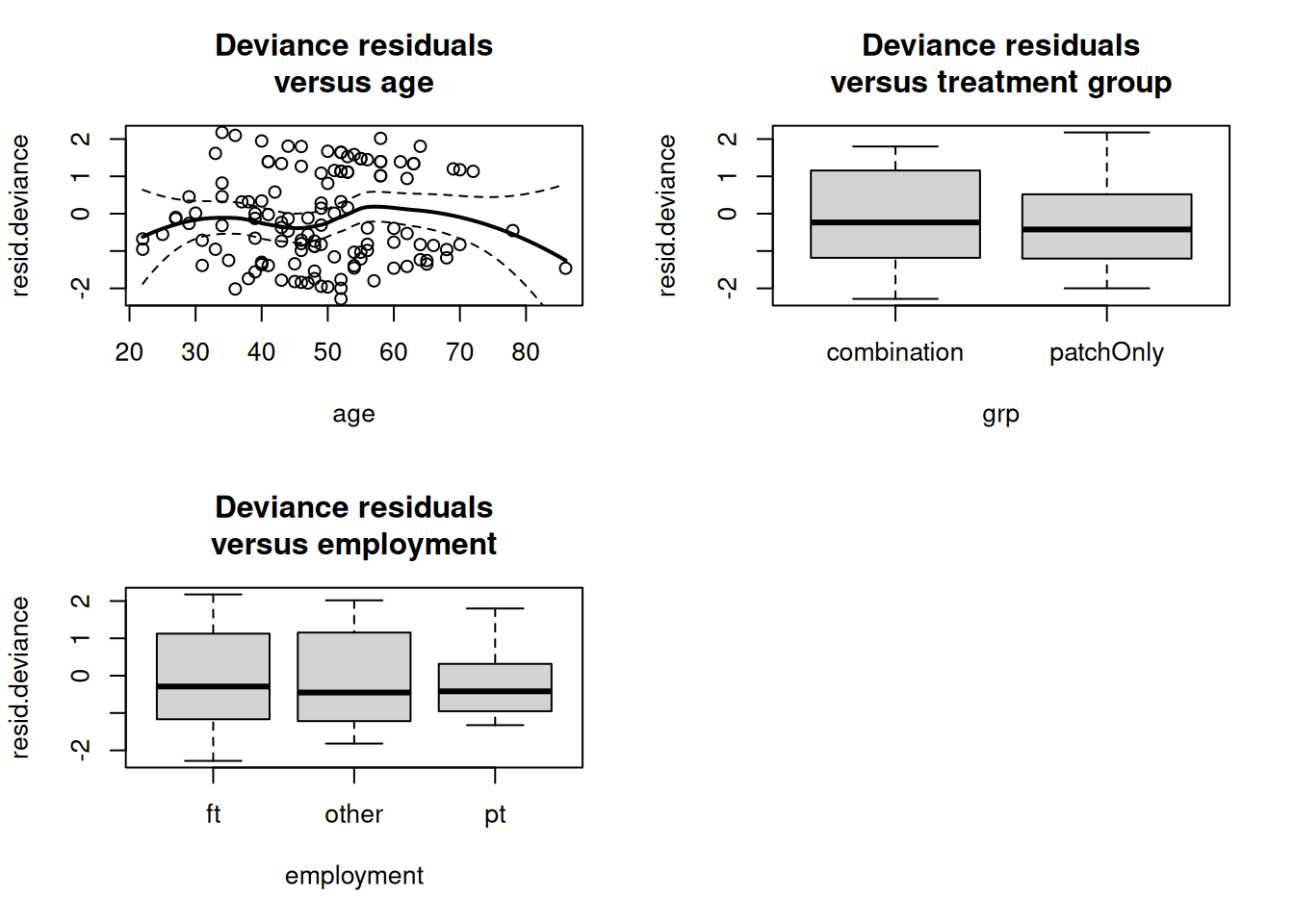
smoothSEcurve <-function(yy, xx) {# use after a call to "plot"# fit a lowess curve and 95% confidence interval curve# make list of x valuesxx.list <-min(xx) + ((0:100)/100)*(max(xx) -min(xx))# Then fit loess function through the points (xx, yy)# at the listed valuesyy.xx <-predict(loess(yy ~ xx), se=T,newdata=data.frame(xx=xx.list))lines(yy.xx$fit ~ xx.list, lwd=2)lines(yy.xx$fit -qt(0.975, yy.xx$df)*yy.xx$se.fit ~ xx.list, lty=2)lines(yy.xx$fit +qt(0.975, yy.xx$df)*yy.xx$se.fit ~ xx.list, lty=2)}resid.deviance <-residuals(model.pharm.weib, type="deviance")par(mfrow=c(2,2))plot(resid.deviance ~ age, data=pharmacoSmoking)smoothSEcurve(resid.deviance, age)title("Deviance residuals\nversus age")plot(resid.deviance ~ grp, data=pharmacoSmoking)title("Deviance residuals\nversus treatment group")plot(resid.deviance ~ employment, data=pharmacoSmoking)title("Deviance residuals\nversus employment")
En la figura anterior, los residuos de desviancia en función de grp y employment están centrados alrededor de cero, y para age el patrón es consistente con un efecto lineal dado el ancho de los intervalos de confianza al 95 %.
Para identificar observaciones influyentes en el coeficiente de age, calculamos los dfbeta:
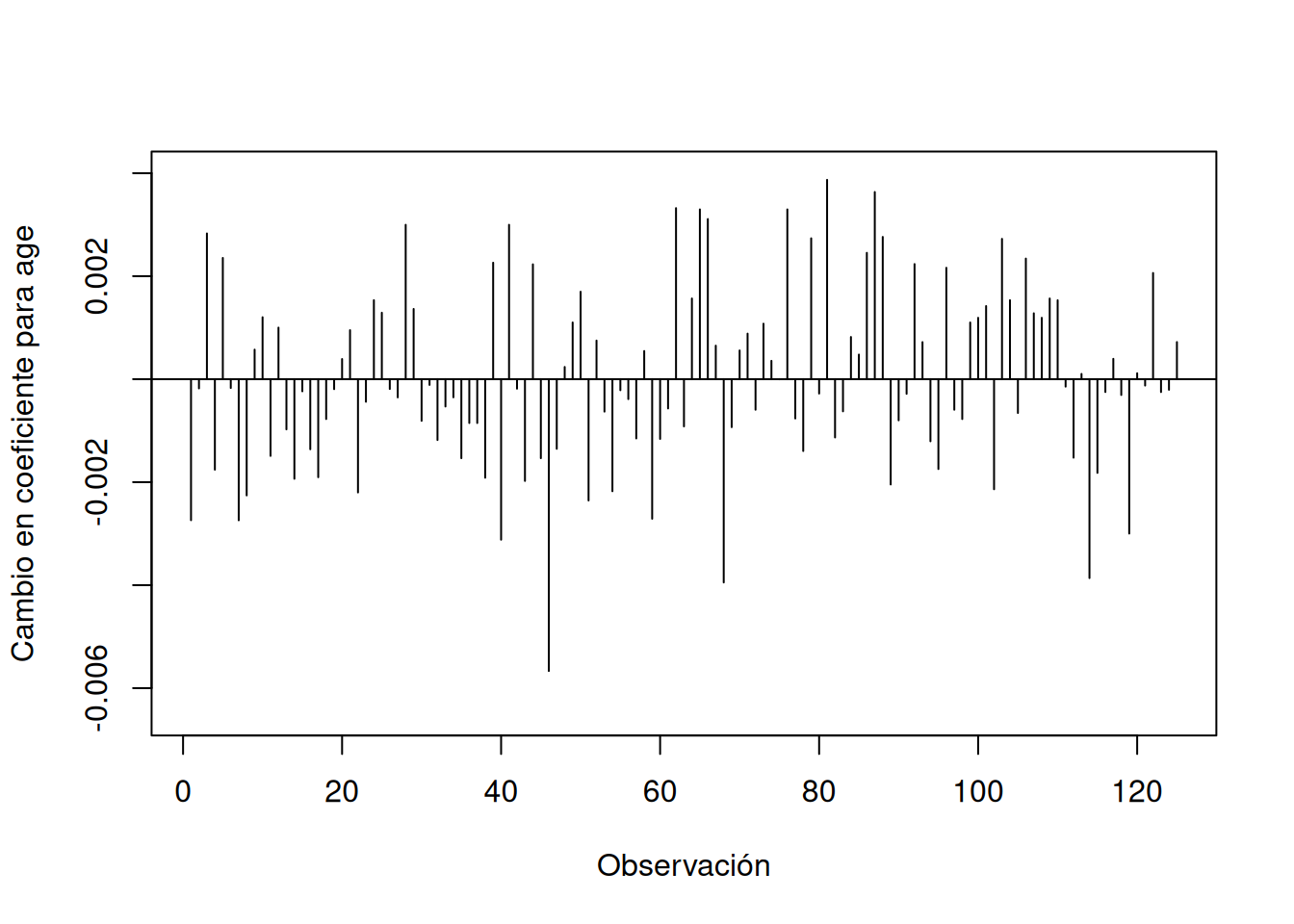
resid.dfbeta <-residuals(model.pharm.weib, type="dfbeta")n.obs <-length(pharmacoSmoking$ttr)index.obs <-1:n.obsplot(resid.dfbeta[, 3] ~ index.obs, type="h",xlab="Observación", ylab="Cambio en coeficiente para age",ylim=c(-0.0065, 0.004))abline(h=0)
En la figura anterior aparecen nuevamente los pacientes 46 y 68 (y además el 114) como los que más alteran la estimación de \(\beta_{\text{age}}\), al igual que en el modelo de Cox.
15.4 Otros modelos paramétricos
En esta sección se muestran dos extensiones del modelo de tiempo acelerado (AFT) usando distribuciones distintas para \(\varepsilon\):
15.4.1 Log-normal
Si \(\varepsilon\sim N(0,1)\) entonces \(T\sim\mathrm{Log\text{-}Normal}\) y ajustamos en R con
model.pharm.lognormal <-survreg(Surv(ttr, relapse) ~ grp + age + employment,dist="lognormal")summary(model.pharm.lognormal)
Call:
survreg(formula = Surv(ttr, relapse) ~ grp + age + employment,
dist = "lognormal")
Value Std. Error z p
(Intercept) 1.6579 1.0084 1.64 0.1002
grppatchOnly -1.2623 0.4523 -2.79 0.0053
age 0.0648 0.0203 3.20 0.0014
employmentother -1.1711 0.5316 -2.20 0.0276
employmentpt -0.9543 0.7198 -1.33 0.1849
Log(scale) 0.8754 0.0796 10.99 <2e-16
Scale= 2.4
Log Normal distribution
Loglik(model)= -451.5 Loglik(intercept only)= -461.7
Chisq= 20.4 on 4 degrees of freedom, p= 0.00042
Number of Newton-Raphson Iterations: 3
n= 125
Aquí los coeficientes son en la escala AFT: un efecto negativo significa menor tiempo esperado.
15.4.2 Log-logístico
Si \(\varepsilon\sim\mathrm{Logistic}(0,1)\,,\quad S(u)=\frac1{1+e^u},\) entonces \(T\sim\mathrm{Log\text{-}Logistic}\) y ajustamos con
model.pharm.loglogistic <-survreg(Surv(ttr, relapse) ~ grp + age + employment,dist="loglogistic")summary(model.pharm.loglogistic)
Call:
survreg(formula = Surv(ttr, relapse) ~ grp + age + employment,
dist = "loglogistic")
Value Std. Error z p
(Intercept) 1.9150 0.9708 1.97 0.0485
grppatchOnly -1.3260 0.4588 -2.89 0.0038
age 0.0617 0.0196 3.15 0.0017
employmentother -1.2605 0.5392 -2.34 0.0194
employmentpt -1.0991 0.7050 -1.56 0.1190
Log(scale) 0.3565 0.0884 4.03 5.5e-05
Scale= 1.43
Log logistic distribution
Loglik(model)= -453.4 Loglik(intercept only)= -463.6
Chisq= 20.47 on 4 degrees of freedom, p= 4e-04
Number of Newton-Raphson Iterations: 4
n= 125
En este caso la proporción de odds de supervivencia cumple