15Múltiples salidas de supervivencia y datos agrupados
Hasta ahora se ha considerado el caso más simple de datos de supervivencia: cada individuo tiene un único tiempo de supervivencia, un único tipo de evento final y las observaciones son independientes. Sin embargo, en muchas aplicaciones estas condiciones no se cumplen.
Existen al menos dos situaciones importantes:
Datos agrupados o correlacionados: los tiempos de supervivencia pueden no ser independientes si los individuos pertenecen al mismo grupo, por ejemplo familias, escuelas, pueblos, hospitales o unidades experimentales.
Eventos recurrentes: el evento de interés puede ocurrir más de una vez por individuo, por ejemplo convulsiones, recaídas, hospitalizaciones o infecciones.
En estas notas nos concentraremos en la primera situación: tiempos de supervivencia agrupados y modelos que permiten manejar la dependencia dentro de grupos.
15.1 Tiempos de supervivencia agrupados
Supongamos que los datos están organizados en grupos o conglomerados. Por ejemplo, en estudios familiares, varias personas pertenecen a la misma familia. En estudios clínicos, puede haber dos observaciones por paciente, como un ojo tratado y un ojo no tratado. En estudios multicéntricos, los pacientes pueden estar agrupados por hospital.
La dificultad principal es que los modelos estándar de Cox asumen independencia entre observaciones. Si esta suposición se viola, los estimadores puntuales pueden seguir siendo razonables en ciertos modelos marginales, pero los errores estándar pueden estar mal calculados.
Hay dos enfoques frecuentes:
Modelos marginales con errores estándar robustos por conglomerado.
Modelos con fragilidad, donde se introduce un efecto aleatorio para cada grupo.
Ejemplo: estudio Ashkenazi y cáncer de mama
Struewing et al. estudiaron el efecto de mutaciones del gen BRCA sobre el riesgo de cáncer de mama en una población judía Ashkenazi.
El conjunto de datos original incluía mujeres de ascendencia Ashkenazi. A cada mujer se le determinó si era portadora de una mutación BRCA. Además, se recolectó información sobre sus familiares femeninas de primer grado: edad al diagnóstico de cáncer de mama, si lo tuvieron, o edad actual si nunca fueron diagnosticadas.
Para el ejemplo se construyó un subconjunto con 1960 familias, cada una con dos familiares femeninas. Si una familia tenía tres o más familiares, se seleccionaron dos al azar. El conjunto de datos ashkenazi está disponible en el paquete asaur.
Las variables principales son:
famID: identificador de familia;
brcancer: indicador de cáncer de mama, con 1 si la familiar tuvo cáncer y 0 si fue censurada;
age: edad de inicio del cáncer o edad al momento de entrevista;
mutant: indicador de si la sujeto era portadora de mutación BRCA.
La variable mutant es común a las dos familiares de una misma familia, porque se refiere al estado mutacional de la sujeto.
La preocupación estadística es que las familiares de una misma familia comparten factores genéticos y ambientales. Por tanto, puede no ser adecuado tratarlas como observaciones independientes.
Ejemplo: retinopatía diabética
El Diabetic Retinopathy Study fue un ensayo clínico aleatorizado para evaluar el efecto de la fotocoagulación láser sobre el tiempo hasta la ceguera.
En cada paciente:
un ojo fue asignado aleatoriamente al tratamiento láser;
el otro ojo quedó como control;
el evento fue la aparición de ceguera;
si un ojo no presentó ceguera, se consideró censurado.
También interesaba evaluar si el tipo de diabetes, de inicio temprano o adulto, afectaba el tiempo hasta la ceguera y modificaba el efecto del tratamiento.
Los datos están en el paquete timereg.
library(timereg)library(survival)library(coxme)
Loading required package: bdsmatrix
Attaching package: 'bdsmatrix'
The following object is masked from 'package:base':
backsolve
Cada paciente contribuye con dos observaciones, una por ojo. Por tanto, las observaciones de los dos ojos de un mismo paciente no son independientes.
15.1.1 Modelos marginales para supervivencia agrupada
En el enfoque marginal se mantiene la estructura usual del modelo de riesgos proporcionales de Cox:
\[
h_i(t)=h_0(t)\exp(z_i\beta),
\]
pero se reconoce que las observaciones dentro de un mismo grupo pueden estar correlacionadas.
La idea es:
ajustar un modelo de Cox ignorando inicialmente la estructura de agrupamiento;
corregir los errores estándar usando un estimador robusto por conglomerado.
Supongamos primero que hay una sola covariable y que el estimador del coeficiente es \(\hat\beta\). Denotemos por \(\hat V\) la varianza estimada bajo el modelo de Cox estándar, que asume independencia. Entonces el error estándar usual es:
\[
\operatorname{se}(\hat\beta)=\sqrt{\hat V}.
\]
Para corregir la varianza por agrupamiento, se definen residuos tipo score.
Para el sujeto \(j\) en el grupo \(i\), un residuo score puede escribirse esquemáticamente como
El primer término coincide con el residuo de Schoenfeld en los tiempos de falla. El segundo término incorpora la contribución acumulada del riesgo esperado.
Si hay \(G\) grupos y el grupo \(i\) contiene \(n_i\) observaciones, se define
\[
C
=
\sum_{i=1}^{G}
\sum_{j=1}^{n_i}
\sum_{m=1}^{n_i}
s_{ij}s_{im}.
\]
Entonces una varianza ajustada por conglomerados puede escribirse como
Si hay \(q\) covariables, \(\hat{\boldsymbol\beta}\) es un vector y \(\hat V\) es la matriz de covarianzas del modelo de Cox estándar. Los residuos score son vectores \(1\times q\) y
\[
C
=
\sum_{i=1}^{G}
\sum_{j=1}^{n_i}
\sum_{m=1}^{n_i}
\mathbf{s}_{ij}^{\top}\mathbf{s}_{im}.
\]
La matriz de covarianzas robusta queda
\[
V^*=\hat V C \hat V.
\]
Este estimador se conoce como estimador sándwich, porque la matriz empírica \(C\) queda entre dos copias de \(\hat V\).
Si \(\omega_i>1\), los sujetos del grupo \(i\) tienen mayor riesgo que el promedio, después de ajustar por covariables observadas. Si \(\omega_i<1\), tienen menor riesgo.
En la práctica, las fragilidades \(\omega_i\) son variables latentes: se supone que existen, pero no se observan directamente. Por eso se requieren métodos de estimación más complejos, como el algoritmo EM.
Algoritmo EM
El algoritmo EM alterna dos pasos:
Paso E: calcular valores esperados de las fragilidades usando las estimaciones actuales de \(\beta\) y \(\theta\).
Paso M: actualizar las estimaciones de \(\beta\) y \(\theta\) usando esos valores esperados.
El procedimiento se repite hasta convergencia.
En modelos paramétricos de supervivencia, plantear el EM puede ser relativamente directo. En el modelo de Cox es más complejo, porque además se debe actualizar el riesgo basal \(h_0(t)\) o el riesgo acumulado basal \(H_0(t)\).
Esta formulación ubica los efectos fijos y aleatorios en la misma escala lineal del predictor del modelo de Cox.
Ejemplo con ashkenazi: conglomerados familiares
Primero ajustamos un modelo de Cox estándar para predecir la edad de inicio del cáncer de mama en función del estado mutacional de la probando (sujeto de prueba).
Las familiares de mujeres portadoras de mutación BRCA tienen un riesgo estimado de desarrollar cáncer de mama aproximadamente 3.29 veces el de las familiares de mujeres no portadoras, bajo el modelo de Cox estándar.
La log-verosimilitud parcial del modelo nulo y del modelo con mutant puede extraerse así:
El estimador puntual no cambia, pero el error estándar robusto es ligeramente mayor. Esto sugiere que el agrupamiento familiar tiene un efecto pequeño en este ejemplo. La asociación sigue siendo altamente significativa.
Modelo de fragilidad gamma
También se puede modelar la dependencia familiar mediante fragilidad gamma:
Esto sugiere que el efecto aleatorio familiar mejora el ajuste. Sin embargo, las pruebas para componentes de varianza deben interpretarse con cautela, porque el valor nulo de una varianza está en la frontera del espacio paramétrico.
Ejemplo con diabetes: dos ojos dentro de cada paciente
Ahora se analiza el tiempo hasta la ceguera en pacientes con retinopatía diabética. Cada paciente aporta dos ojos, por lo que las observaciones están agrupadas por paciente.
Esto indica que, en el grupo de referencia para adult, el tratamiento reduce el riesgo de ceguera. Más específicamente, el riesgo instantáneo del ojo tratado es aproximadamente 0.61 veces el riesgo del ojo no tratado, manteniendo lo demás constante.
Esto sugiere que los pacientes con diabetes de inicio adulto tienen mayor riesgo de ceguera temprana que los del grupo de referencia, aunque el valor-p reportado es aproximadamente 0.10.
Este enfoque modela explícitamente la heterogeneidad no observada entre grupos.
Diferencia conceptual
El modelo marginal responde una pregunta de tipo poblacional:
¿Cuál es el efecto promedio de la covariable en la población?
El modelo de fragilidad responde una pregunta condicional al grupo:
¿Cuál es el efecto de la covariable dentro de grupos con fragilidad similar?
Ambos enfoques pueden ser útiles, pero no siempre tienen la misma interpretación.
15.2 Riesgos competitivos y riesgos específicos por causa
En análisis de supervivencia clásico se suele estudiar un único desenlace bien definido, por ejemplo muerte, recaída o falla. En muchas aplicaciones, sin embargo, un individuo puede experimentar distintos tipos de eventos, pero solo se observa el primero que ocurre.
Por ejemplo, en pacientes con cáncer de próstata puede interesar el tiempo desde el diagnóstico hasta:
muerte por cáncer de próstata, causa 1;
muerte por otra causa, causa 2;
censura, si el paciente sigue vivo al final del seguimiento.
A esta situación se le llama riesgos competitivos. Los eventos compiten porque, una vez que ocurre uno de ellos, los demás ya no pueden observarse para ese individuo.
El problema de tratar eventos competitivos como censura
Si interesa estudiar el tiempo hasta muerte por cáncer de próstata, una estrategia simple sería considerar las muertes por otras causas como censuras. Esto permite usar directamente Kaplan-Meier o modelos de Cox estándar.
Sin embargo, esta estrategia requiere que la censura sea independiente del evento de interés. En riesgos competitivos, esta suposición suele ser dudosa. Por ejemplo, edad, comorbilidades o estado general de salud pueden afectar tanto la probabilidad de morir por cáncer de próstata como la probabilidad de morir por otras causas.
Además, con datos de riesgos competitivos no es posible probar directamente si los tiempos potenciales a las distintas causas son independientes. La evaluación de esta suposición requiere información externa o argumentos científicos sobre las causas de muerte.
Por ello, los análisis que tratan eventos competitivos como censura pueden tener una interpretación ambigua o hipotética.
15.2.1 Kaplan-Meier en presencia de riesgos competitivos
Supóngase una variable status con la siguiente codificación:
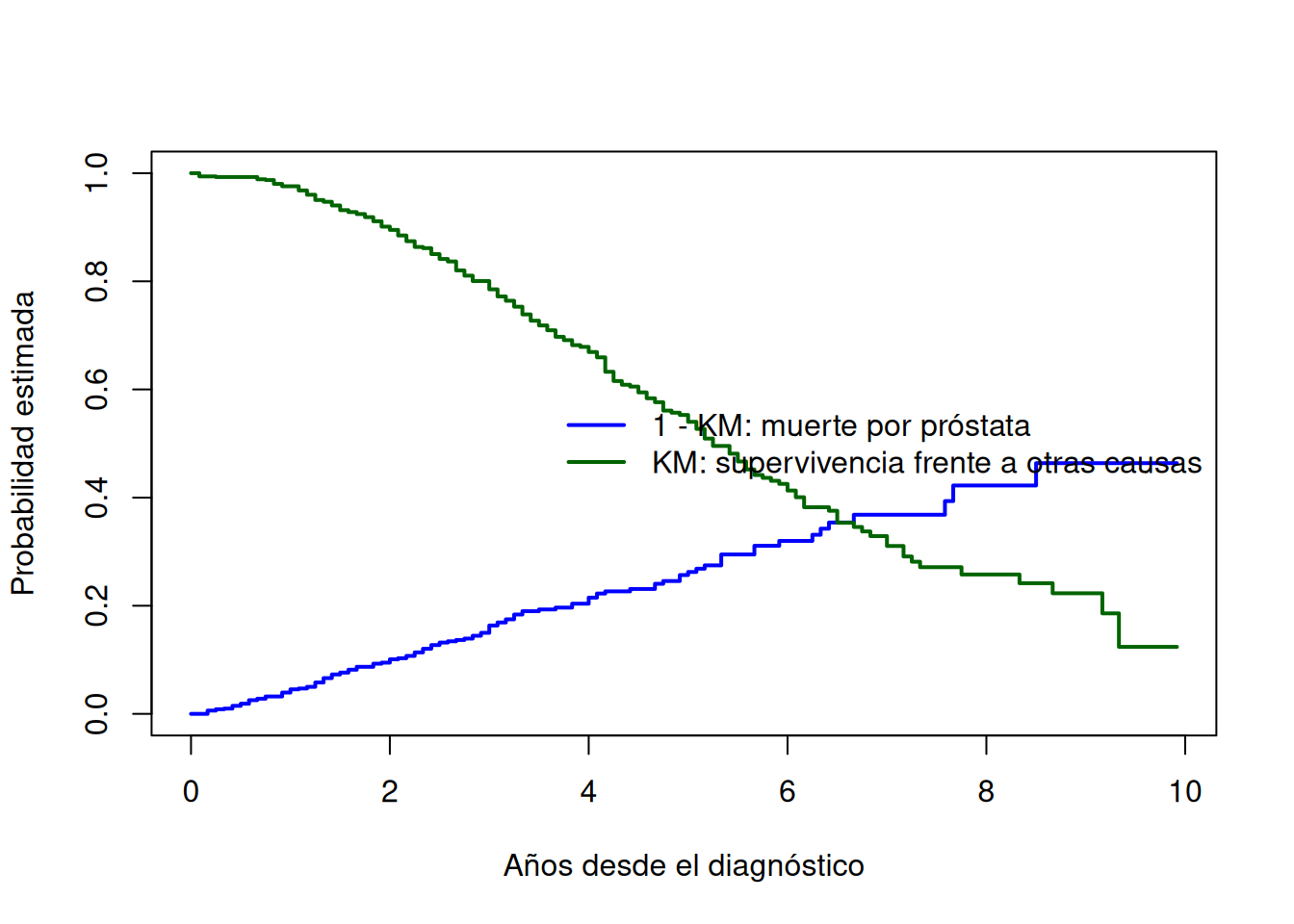
plot( km_prostate$time /12, 1- km_prostate$surv,type ="s", ylim =c(0, 1), lwd =2, col ="blue",xlab ="Años desde el diagnóstico",ylab ="Probabilidad estimada")lines( km_other$time /12, km_other$surv,type ="s", col ="darkgreen", lwd =2)legend("right",legend =c("1 - KM: muerte por próstata","KM: supervivencia frente a otras causas"),col =c("blue", "darkgreen"),lwd =2,bty ="n")
El problema es que estas curvas no representan probabilidades reales simultáneamente observables. En el ejemplo descrito, a 10 años la probabilidad estimada de morir por cáncer de próstata es aproximadamente 0.46 y la probabilidad de morir por otras causas es aproximadamente 0.88. La suma excede 1, lo cual muestra que estas estimaciones no pueden interpretarse como probabilidades reales de muerte por una u otra causa para un mismo paciente.
Estas curvas podrían interpretarse hipotéticamente como probabilidades de morir por una causa si la otra causa fuera eliminada, pero eso requiere asumir independencia entre causas.
15.2.2 Riesgos específicos por causa
Supóngase que existen \(K\) causas mutuamente excluyentes de falla. Cada individuo puede experimentar a lo sumo una causa.
La función de riesgo específica por causa para la causa \(j\) se define como
\[
h_j(t)
=
\lim_{\Delta t \to 0}
\frac{
\Pr(t<T<t+\Delta t,\ C=j \mid T>t)
}{
\Delta t
}.
\]
Esta cantidad mide la tasa instantánea de ocurrencia de la causa \(j\), condicionada a que el individuo sigue libre de cualquier evento justo antes de \(t\).
La función de riesgo total es la suma de los riesgos específicos:
\[
h(t)=\sum_{j=1}^{K} h_j(t).
\]
Es decir, el riesgo instantáneo de morir por cualquier causa es la suma de los riesgos instantáneos de morir por cada causa específica.
Función de incidencia acumulada
Para cada causa \(j\), se define la función de incidencia acumulada, también llamada función de subdistribución, como
\[
F_j(t)=\Pr(T\leq t,\ C=j).
\]
Esta es la probabilidad acumulada de haber experimentado la causa \(j\) antes o en el tiempo \(t\).
Puede escribirse como
\[
F_j(t)
=
\int_0^t h_j(u)S(u)du,
\]
donde \(S(u)\) es la probabilidad de seguir libre de cualquier evento justo antes de \(u\).
A diferencia de una función de distribución ordinaria, \(F_j(t)\) no necesariamente tiende a 1. En cambio,
\[
F_j(\infty)=\Pr(C=j).
\]
Es decir, su límite es la probabilidad final de morir por la causa \(j\).
Estimación no paramétrica de la incidencia acumulada
Supóngase que hay tiempos de falla ordenados
\[
t_1,t_2,\ldots,t_D.
\]
En el tiempo \(t_i\), sean:
\(n_i\): número de individuos en riesgo justo antes de \(t_i\);
\(d_{ik}\): número de eventos de la causa \(k\) en \(t_i\);
\(d_i=\sum_k d_{ik}\): número total de eventos en \(t_i\).
El estimador del riesgo específico por causa \(k\) en \(t_i\) es
\[
\widehat h_k(t_i)=\frac{d_{ik}}{n_i}.
\]
El estimador del riesgo total es
\[
\widehat h(t_i)=\frac{d_i}{n_i}.
\]
La probabilidad estimada de fallar por la causa \(k\) exactamente en \(t_i\) es
\[
\widehat S(t_{i-1})\widehat h_k(t_i),
\]
donde \(\widehat S(t_{i-1})\) es la probabilidad estimada de seguir libre de cualquier evento justo antes de \(t_i\).
Por tanto, la incidencia acumulada para la causa \(k\) se estima mediante
Esta fórmula muestra que, para estimar la probabilidad acumulada de morir por una causa específica, no basta con estimar la supervivencia frente a esa causa. Hay que considerar también la probabilidad de seguir libre de cualquier evento hasta cada tiempo.
Ejemplo hipotético con seis individuos
Se consideran seis observaciones y dos causas de falla:
Surv: estimación de Kaplan-Meier para supervivencia frente a cualquier causa;
CI.1: incidencia acumulada de muerte por cáncer de próstata;
CI.2: incidencia acumulada de muerte por otras causas;
seSurv: error estándar de la supervivencia;
seCI.1: error estándar de CI.1;
seCI.2: error estándar de CI.2.
Para graficar ambas incidencias acumuladas:
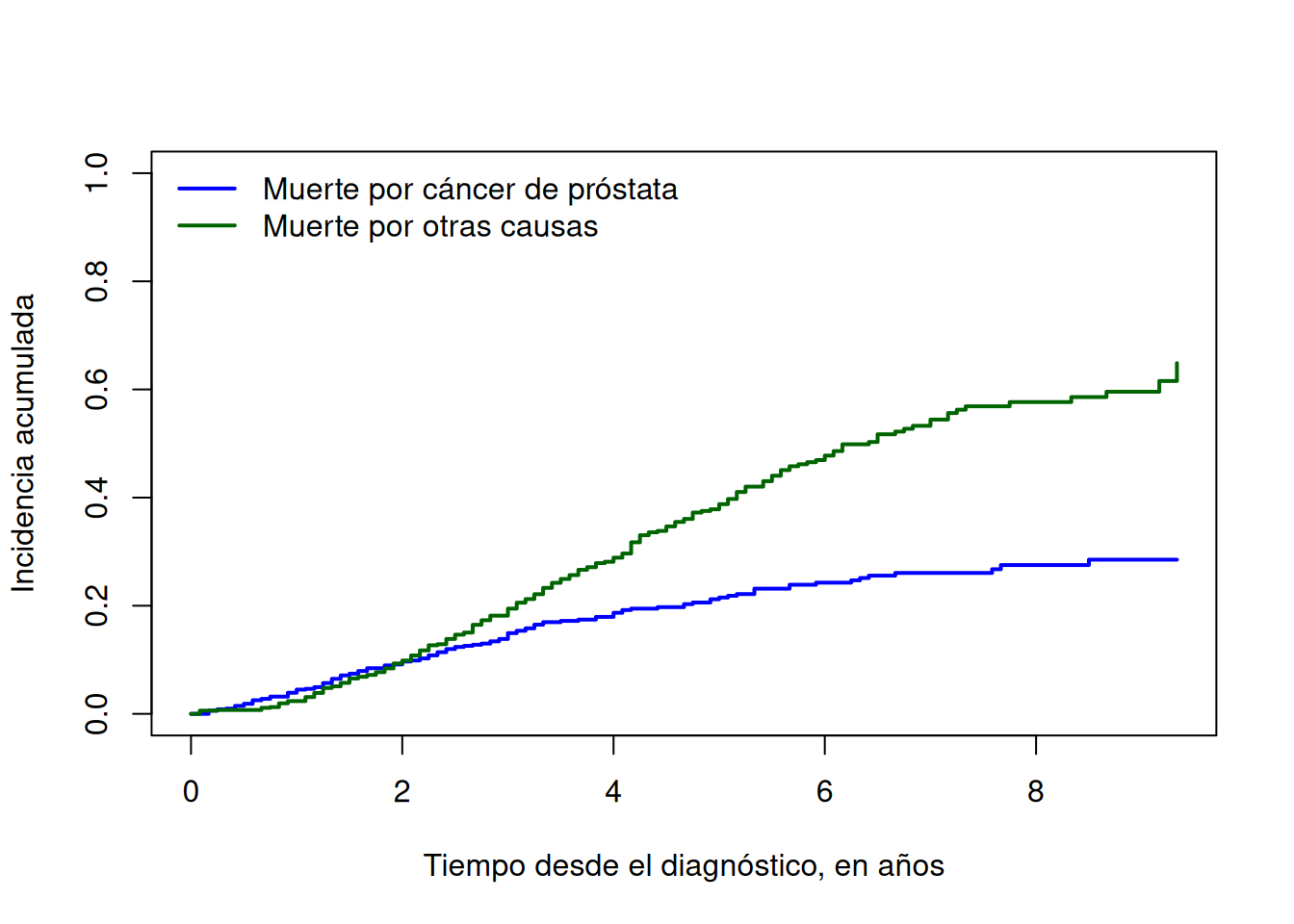
times <- ci_prostate$time /12plot( times, ci_prostate$CI.1,type ="s", lwd =2, col ="blue",ylim =c(0, 1),xlab ="Tiempo desde el diagnóstico, en años",ylab ="Incidencia acumulada")lines( times, ci_prostate$CI.2,type ="s", lwd =2, col ="darkgreen")legend("topleft",legend =c("Muerte por cáncer de próstata", "Muerte por otras causas"),col =c("blue", "darkgreen"),lwd =2,bty ="n")
Estas curvas representan probabilidades reales estimadas:
\[
\widehat F_1(t)=\Pr(T\leq t,\ C=1),
\]
\[
\widehat F_2(t)=\Pr(T\leq t,\ C=2).
\]
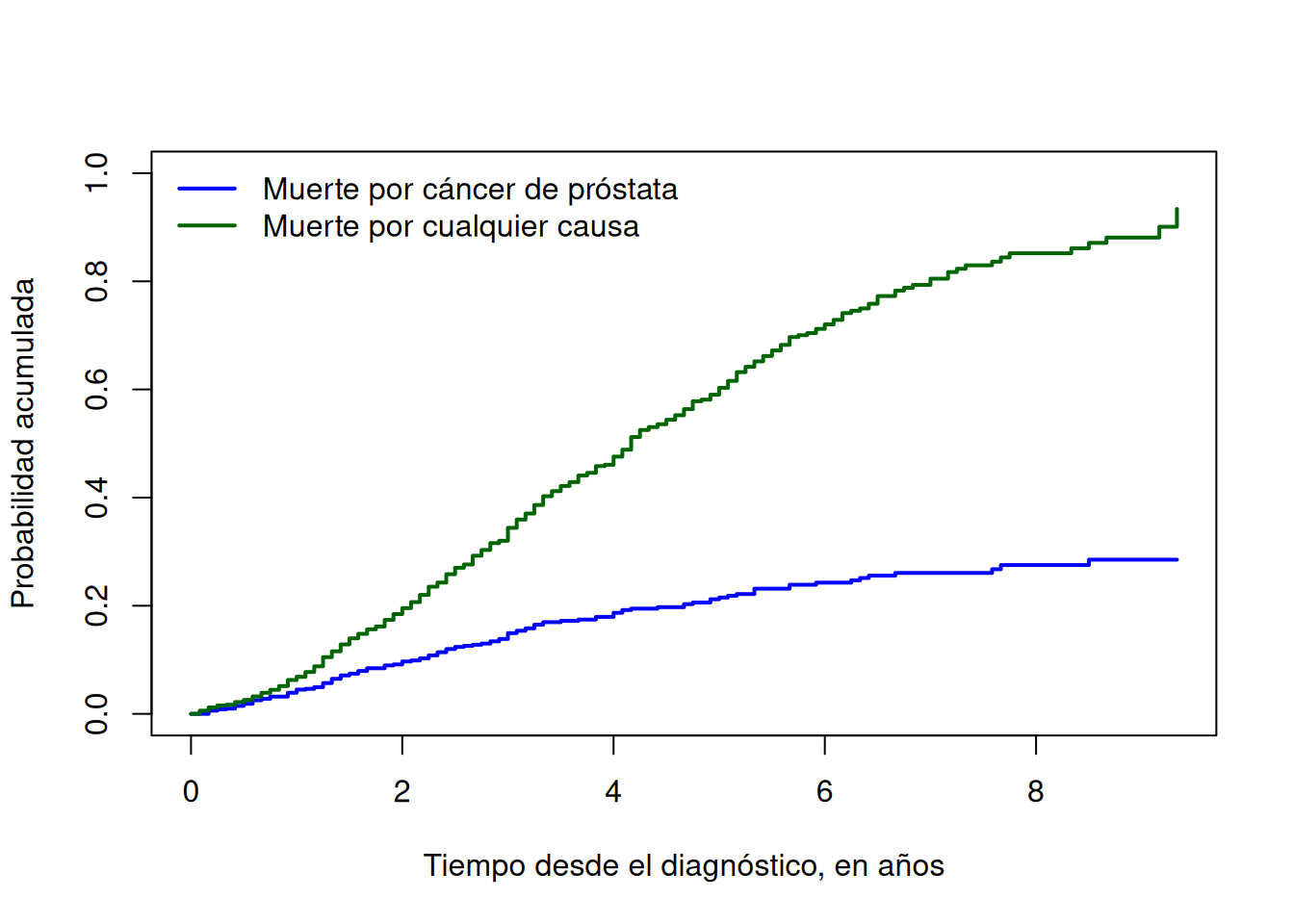
Una representación común es el gráfico apilado:
plot( times, ci_prostate$CI.1,type ="s", lwd =2, col ="blue",ylim =c(0, 1),xlab ="Tiempo desde el diagnóstico, en años",ylab ="Probabilidad acumulada")lines( times, ci_prostate$CI.1+ ci_prostate$CI.2,type ="s", lwd =2, col ="darkgreen")legend("topleft",legend =c("Muerte por cáncer de próstata","Muerte por cualquier causa" ),col =c("blue", "darkgreen"),lwd =2,bty ="n")
En este gráfico:
la curva azul inferior representa la probabilidad acumulada de muerte por cáncer de próstata;
la diferencia entre la curva verde superior y la azul representa la probabilidad acumulada de muerte por otras causas;
la curva verde superior representa la probabilidad acumulada de muerte por cualquier causa:
15.2.3 Regresión para riesgos específicos por causa
Cuando hay un único desenlace, el modelo de Cox permite incorporar covariables mediante
\[
h(t\mid z)=h_0(t)\exp(z^\top\beta).
\]
Con riesgos competitivos, una estrategia directa consiste en ajustar un modelo de Cox separado para cada causa. Para la causa \(k\), se considera como evento la causa \(k\), y las demás causas se tratan como censura.
Esta estrategia modela el riesgo específico por causa:
La interpretación de \(\beta_k\) es sobre la tasa instantánea de ocurrencia de la causa \(k\) entre individuos que siguen libres de cualquier evento justo antes de \(t\).
Cox por causa específica: cáncer de próstata
Se restringe el análisis a pacientes con cáncer de próstata en estadio T2. Se estudia el efecto de:
Para muerte por cáncer de próstata, los resultados reportados son aproximadamente:
Covariable
Coeficiente
Razón de riesgos
gradepoor
1.2199
3.3867
ageGroup70-74
-0.2860
0.7513
ageGroup75-79
0.4027
1.4958
ageGroup80+
0.9728
2.6454
Los pacientes con tumor pobremente diferenciado tienen peor pronóstico que los pacientes con tumor moderadamente diferenciado. La razón de riesgos estimada es
\[
\exp(1.2199)=3.3867.
\]
Es decir, entre pacientes libres de evento justo antes de \(t\), aquellos con tumor pobremente diferenciado tienen una tasa instantánea de muerte por cáncer de próstata aproximadamente 3.39 veces la de los pacientes con tumor moderado, ajustando por edad.
Cox por causa específica: muerte por otras causas
Ahora se toma como evento de interés la muerte por otras causas:
Tomados literalmente, estos resultados indican que los pacientes con tumor pobremente diferenciado también presentan mayor riesgo de morir por causas distintas al cáncer de próstata. Sin embargo, este efecto es mucho menor que el observado para muerte por cáncer de próstata.
Esta interpretación debe hacerse con cuidado. Los modelos de riesgos específicos por causa modelan tasas instantáneas entre personas que siguen libres de cualquier evento. No modelan directamente probabilidades acumuladas de morir por cada causa.
15.2.4 Modelo de Fine y Gray
Fine y Gray propusieron un enfoque alternativo para modelar covariables en presencia de riesgos competitivos. En lugar de modelar el riesgo específico por causa, modelan el riesgo de subdistribución.
Para la causa \(k\), el riesgo de subdistribución se define como
\[
\bar h_k(t)
=
\lim_{\Delta t\to 0}
\frac{
\Pr(t<T_k<t+\Delta t \mid E)
}{
\Delta t
},
\]
La diferencia con el riesgo ordinario es que el conjunto de riesgo incluye no solo a quienes siguen libres de evento, sino también a quienes ya tuvieron antes un evento competitivo distinto de \(k\).
Este modelo se relaciona directamente con la incidencia acumulada \(F_k(t)\). Por tanto, sus coeficientes describen efectos sobre la subdistribución de la causa \(k\), no sobre el riesgo instantáneo específico por causa.
Fine y Gray en R
El modelo de Fine y Gray está implementado en la función crr() del paquete cmprsk.
Primero se crea una matriz de covariables. Se elimina la columna de intercepto porque crr() no la requiere.
Las razones de riesgos de Cox por causa específica y las razones de subriesgos de Fine-Gray no tienen la misma interpretación.
15.2.5 Comparación de efectos sobre distintas causas
Una ventaja del enfoque de riesgos específicos por causa es que permite comparar de forma directa si una covariable tiene efectos distintos sobre causas distintas.
Para ello, se transforma el conjunto de datos a formato largo: cada paciente tendrá una fila por cada causa posible.
En el caso de dos causas, cada paciente tendrá dos filas:
An object of class 'msdata'
Data:
id from to trans Tstart Tstop time status grade ageGroup
1 1 1 2 1 0 27 27 0 mode 70-74
2 1 1 3 2 0 27 27 0 mode 70-74
3 2 1 2 1 0 38 38 0 poor 75-79
4 2 1 3 2 0 38 38 1 poor 75-79
5 3 1 2 1 0 13 13 0 poor 75-79
6 3 1 3 2 0 13 13 0 poor 75-79
El conjunto resultante contiene el doble de filas que el conjunto original. Sus columnas principales son:
id: identificador del paciente original;
trans: causa o transición;
trans = 1: muerte por cáncer de próstata;
trans = 2: muerte por otras causas;
time: tiempo de seguimiento;
status: indicador del evento correspondiente;
grade, ageGroup: covariables copiadas del conjunto original.
Para resumir los eventos:
events(prostate_long)
$Frequencies
to
from event-free prostate other no event total entering
event-free 0 410 1345 4165 5920
prostate 0 0 0 410 410
other 0 0 0 1345 1345
$Proportions
to
from event-free prostate other no event
event-free 0.00000000 0.06925676 0.22719595 0.70354730
prostate 0.00000000 0.00000000 0.00000000 1.00000000
other 0.00000000 0.00000000 0.00000000 1.00000000
En el texto se reporta:
410 muertes por cáncer de próstata;
1345 muertes por otras causas;
4165 censuras;
5920 pacientes en total.
Los modelos separados por causa se pueden reproducir usando subset:
Resultados reportados para las interacciones de edad con causa:
Interacción
Coeficiente
Razón de riesgos
Valor-p
ageGroup70-74:trans2
0.380
1.463
0.186
ageGroup75-79:trans2
-0.089
0.914
0.725
ageGroup80+:trans2
-0.183
0.833
0.451
Ninguna de estas interacciones es estadísticamente significativa. Por tanto, no hay evidencia clara de que el efecto de la edad difiera entre muerte por cáncer de próstata y muerte por otras causas, después de ajustar por grado tumoral.
En cambio, sí hay evidencia fuerte de que el efecto del grado tumoral difiere entre causas.