library(survival)
diagnostico_weibull <- function(time, status, main = "Diagnóstico Weibull") {
stopifnot(length(time) == length(status))
if (any(time <= 0, na.rm = TRUE)) {
stop("Todos los tiempos deben ser positivos.")
}
ajuste_km <- survfit(Surv(time, status) ~ 1)
# Se excluyen S(t)=0 y S(t)=1 porque la transformación
# log[-log S(t)] no está definida en esos valores.
usar <- ajuste_km$surv > 0 &
ajuste_km$surv < 1 &
ajuste_km$time > 0
x <- log(ajuste_km$time[usar])
y <- log(-log(ajuste_km$surv[usar]))
ajuste_lineal <- lm(y ~ x)
plot(
x, y,
xlab = expression(log(t)),
ylab = expression(log(-log(hat(S)(t)))),
main = main
)
abline(ajuste_lineal, lwd = 2)
pendiente <- unname(coef(ajuste_lineal)[2])
intercepto <- unname(coef(ajuste_lineal)[1])
list(
km = ajuste_km,
regresion = ajuste_lineal,
mu_aprox = -intercepto / pendiente,
sigma_aprox = 1 / pendiente,
alpha_aprox = pendiente
)
}16 Modelos paramétricos de sobrevivencia
16.1 Introducción
Los métodos no paramétricos, como Kaplan-Meier, y semiparamétricos, como el modelo de riesgos proporcionales de Cox, son fundamentales porque permiten representar una gran variedad de formas de la función de riesgo sin imponer una distribución completa para el tiempo de supervivencia.
Los modelos paramétricos también son útiles cuando existe evidencia de que los tiempos de supervivencia siguen aproximadamente una distribución conocida. Sus principales ventajas son:
- dependen de un número pequeño y fijo de parámetros;
- permiten usar directamente la teoría de máxima verosimilitud;
- facilitan la estimación de probabilidades, cuantiles y tiempos medios;
- permiten extrapolar la supervivencia más allá del periodo observado;
- incorporan de manera directa esquemas complejos de censura y truncamiento;
- producen estimaciones suaves de la supervivencia y del riesgo.
Su principal desventaja es que las conclusiones pueden ser incorrectas si la distribución seleccionada no representa adecuadamente los datos.
Las distribuciones más utilizadas incluyen:
- exponencial;
- Weibull;
- lognormal;
- log-logística.
16.2 Distribución exponencial
La distribución exponencial es el modelo paramétrico de supervivencia más simple. Su función de riesgo es constante:
\[ h(t)=\lambda, \qquad \lambda>0. \]
La función de densidad y la función de supervivencia son
\[ f(t;\lambda)=\lambda e^{-\lambda t}, \]
\[ S(t;\lambda)=e^{-\lambda t}. \]
La constancia de \(h(t)\) implica la propiedad de falta de memoria:
\[ P(T>s+t\mid T>s)=P(T>t). \]
En otras palabras, el riesgo instantáneo no depende del tiempo que el individuo ya ha sobrevivido.
La distribución exponencial puede ser útil en cálculos de potencia y tamaño de muestra, pero suele ser demasiado restrictiva para datos reales porque obliga a que el riesgo sea constante.
Para una observación \((t_i,\delta_i)\), donde
\[ \delta_i= \begin{cases} 1, & \text{si se observa el evento},\\ 0, & \text{si la observación está censurada}, \end{cases} \]
la contribución a la verosimilitud es
\[ f(t_i)^{\delta_i}S(t_i)^{1-\delta_i} = h(t_i)^{\delta_i}S(t_i). \]
16.3 Distribución Weibull
Parametrización
Una parametrización conveniente de la distribución Weibull utiliza:
- \(\alpha>0\): parámetro de forma;
- \(\lambda>0\): parámetro de tasa o escala inversa.
La función de riesgo es
\[ h(t)=\alpha\lambda^\alpha t^{\alpha-1}, \]
y la función de supervivencia es
\[ S(t)=\exp\left\{-(\lambda t)^\alpha\right\}. \]
La forma de la función de riesgo depende de \(\alpha\):
- si \(\alpha<1\), el riesgo disminuye con el tiempo;
- si \(\alpha=1\), el riesgo es constante y el modelo se reduce al exponencial;
- si \(\alpha>1\), el riesgo aumenta con el tiempo.
Una parametrización útil para modelos de regresión es
\[ \sigma=\frac{1}{\alpha}, \qquad \mu=-\log(\lambda). \]
Entonces,
\[ h(t) = \frac{1}{\sigma} e^{-\mu/\sigma} t^{1/\sigma-1}, \]
y
\[ S(t) = \exp\left\{ -e^{-\mu/\sigma}t^{1/\sigma} \right\}. \]
En esta parametrización, \(\mu\) es un parámetro de localización para \(\log(T)\); no debe confundirse con \(E(T)\).
Diagnóstico gráfico de la distribución Weibull
Partiendo de
\[ S(t)=\exp\left\{-(\lambda t)^\alpha\right\}, \]
se obtiene
\[ -\log S(t)=(\lambda t)^\alpha. \]
Aplicando logaritmo:
\[ \log[-\log S(t)] = \alpha\log(\lambda)+\alpha\log(t). \]
Usando \(\alpha=1/\sigma\) y \(\mu=-\log\lambda\):
\[ \log[-\log S(t)] = -\frac{\mu}{\sigma} + \frac{1}{\sigma}\log(t). \]
Por tanto, si los datos siguen aproximadamente una distribución Weibull, el gráfico de
\[ \log[-\log \widehat S(t)] \]
contra
\[ \log(t) \]
debería mostrar una relación aproximadamente lineal.
Si se ajusta la recta
\[ y=b+m\log(t), \]
entonces
\[ m=\frac{1}{\sigma}, \qquad b=-\frac{\mu}{\sigma}. \]
Por ello,
\[ \widehat\sigma=\frac{1}{m}, \qquad \widehat\mu=-\frac{b}{m}. \]
Implementación en R:
Ejemplo: datos gastricXelox
El conjunto gastricXelox contiene tiempos de supervivencia de pacientes tratados por cáncer gástrico.
library(asaur)
library(survival)
data("gastricXelox", package = "asaur")
time_months <- gastricXelox$timeWeeks * 7 / 30.25
status <- gastricXelox$delta
diag_gastric <- diagnostico_weibull(
time = time_months,
status = status,
main = "Datos gastricXelox"
)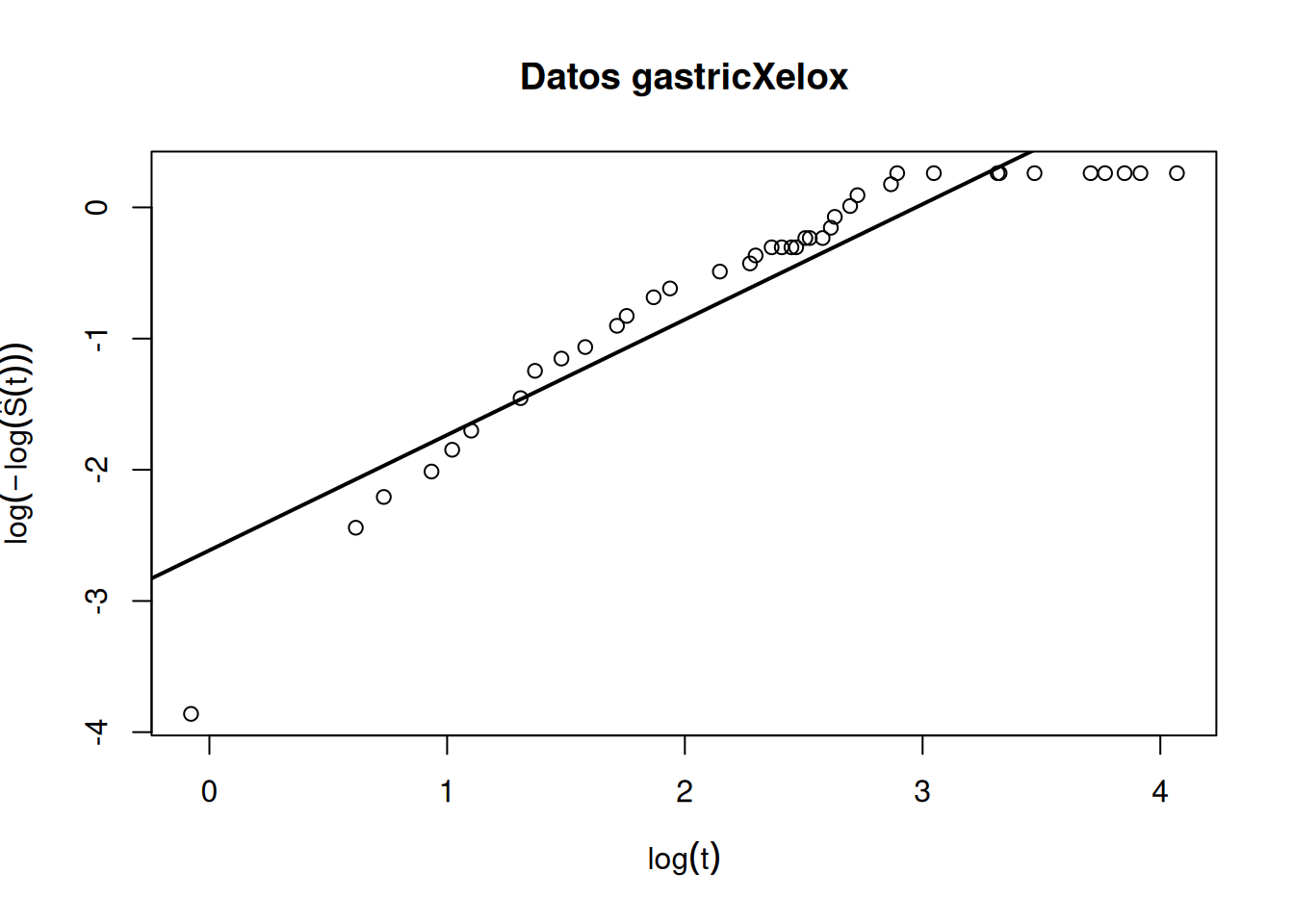
diag_gastric$regresion
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
-2.6141 0.8795 Si los puntos presentan una curvatura sistemática respecto a la recta ajustada, la distribución Weibull puede no ser adecuada.
Ejemplo: datos pharmacoSmoking
El conjunto pharmacoSmoking contiene tiempos hasta recaída en personas sometidas a tratamientos para dejar de fumar.
data("pharmacoSmoking", package = "asaur")
pharmacoSmoking <- transform(
pharmacoSmoking,
ttr = ifelse(ttr == 0, 0.5, ttr)
)
diag_smoking <- diagnostico_weibull(
time = pharmacoSmoking$ttr,
status = pharmacoSmoking$relapse,
main = "Datos pharmacoSmoking"
)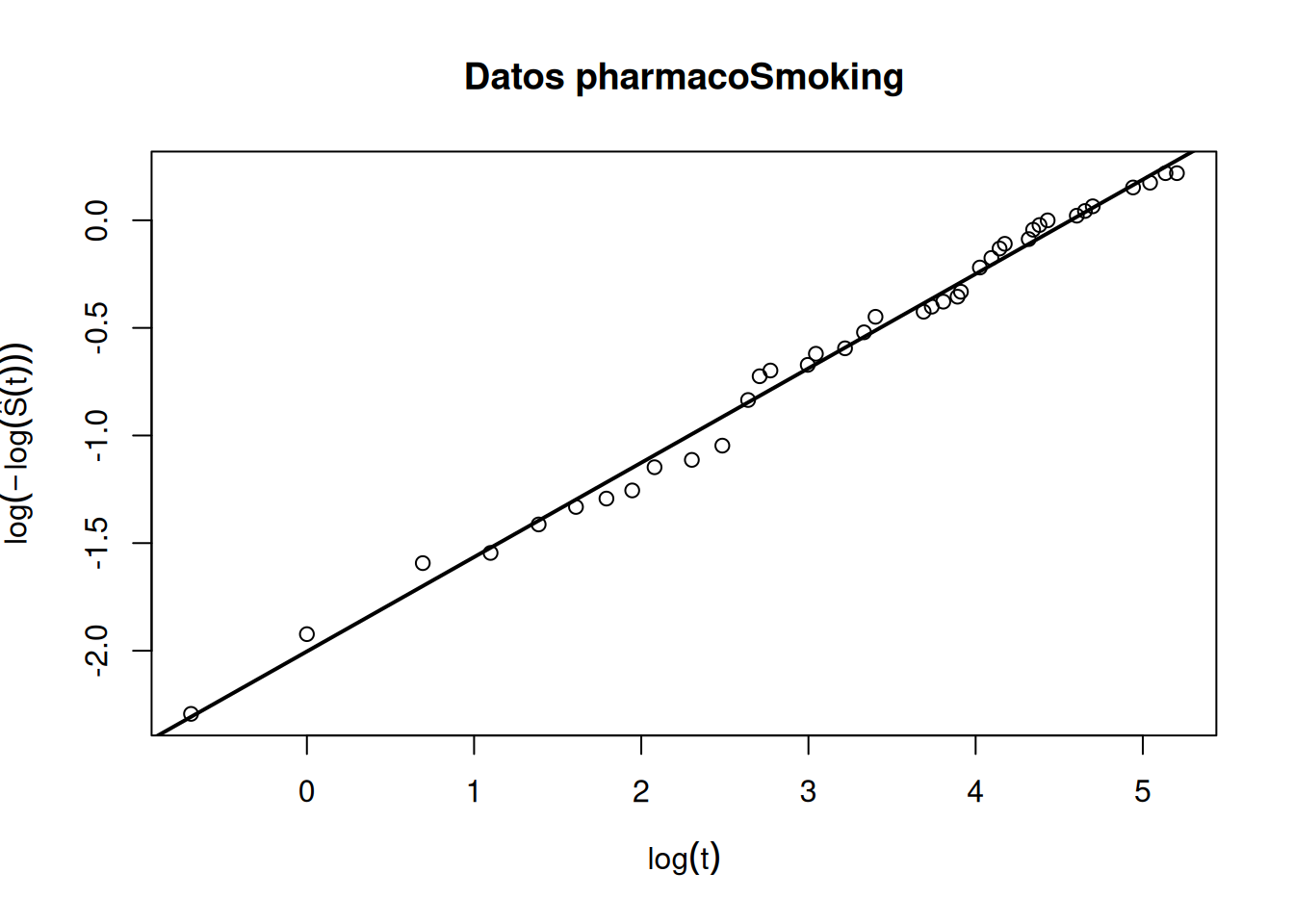
coef(diag_smoking$regresion)(Intercept) x
-2.003177 0.438493 diag_smoking$mu_aprox[1] 4.56832diag_smoking$sigma_aprox[1] 2.280538En el ejemplo original se obtuvo aproximadamente
\[ \widehat b=-2.0032, \qquad \widehat m=0.4385. \]
Entonces,
\[ \widehat\sigma=\frac{1}{0.4385}=2.280, \]
y
\[ \widehat\mu=-\frac{-2.0032}{0.4385}=4.568. \]
La cercanía de los puntos a la recta sugiere que una distribución Weibull puede ser razonable para estos datos.
16.4 Estimación por máxima verosimilitud
Log-verosimilitud Weibull
Para observaciones independientes \((t_i,\delta_i)\), la log-verosimilitud es
\[ \ell(\lambda,\alpha) = \sum_{i=1}^n \left[ \delta_i\log h(t_i)+\log S(t_i) \right]. \]
Sustituyendo las funciones Weibull:
\[ \ell(\lambda,\alpha) = d\log\alpha + d\alpha\log\lambda + (\alpha-1) \sum_{i=1}^n \delta_i\log t_i - \lambda^\alpha \sum_{i=1}^n t_i^\alpha, \]
donde
\[ d=\sum_{i=1}^n\delta_i \]
es el número total de eventos observados.
Maximización numérica en R
Para mejorar la estabilidad numérica se optimiza respecto a
\[ (\mu,\log\sigma), \]
de modo que \(\sigma>0\) automáticamente.
neg_loglik_weibull <- function(par, time, status) {
mu <- par[1]
sigma <- exp(par[2])
alpha <- 1 / sigma
lambda <- exp(-mu)
d <- sum(status)
loglik <- d * log(alpha) +
d * alpha * log(lambda) +
(alpha - 1) * sum(status * log(time)) -
lambda^alpha * sum(time^alpha)
-loglik
}
inicio <- c(
mu = diag_smoking$mu_aprox,
log_sigma = log(diag_smoking$sigma_aprox)
)
ajuste_optim <- optim(
par = inicio,
fn = neg_loglik_weibull,
time = pharmacoSmoking$ttr,
status = pharmacoSmoking$relapse,
method = "BFGS",
hessian = TRUE
)
estimaciones_optim <- c(
mu = ajuste_optim$par[1],
sigma = exp(ajuste_optim$par[2])
)
estimaciones_optim mu.mu sigma.log_sigma
4.656329 2.041061 Los valores obtenidos son aproximadamente
\[ \widehat\mu=4.656, \qquad \widehat\sigma=2.041. \]
Estimación con survreg()
La forma práctica de ajustar el modelo es:
modelo_weibull_0 <- survreg(
Surv(ttr, relapse) ~ 1,
data = pharmacoSmoking,
dist = "weibull"
)
summary(modelo_weibull_0)
Call:
survreg(formula = Surv(ttr, relapse) ~ 1, data = pharmacoSmoking,
dist = "weibull")
Value Std. Error z p
(Intercept) 4.6563 0.2170 21.46 < 2e-16
Log(scale) 0.7135 0.0919 7.76 8.3e-15
Scale= 2.04
Weibull distribution
Loglik(model)= -466.1 Loglik(intercept only)= -466.1
Number of Newton-Raphson Iterations: 5
n= 125 c(
mu = unname(coef(modelo_weibull_0)[1]),
sigma = modelo_weibull_0$scale,
alpha = 1 / modelo_weibull_0$scale
) mu sigma alpha
4.6563293 2.0410612 0.4899412 En la parametrización de survreg():
- el intercepto estima \(\mu\);
Scaleestima \(\sigma\);Log(scale)estima \(\log(\sigma)\);- la forma Weibull es \(\alpha=1/\sigma\).
Verosimilitud perfil
Si \(\alpha\) es fijo, entonces
\[ T^*=T^\alpha \]
sigue una distribución exponencial con tasa \(\lambda^\alpha\).
Para un valor conocido de \(\alpha\), el estimador de máxima verosimilitud de \(\lambda\) es
\[ \widehat\lambda(\alpha) = \left( \frac{d}{\sum_i t_i^\alpha} \right)^{1/\alpha}. \]
La verosimilitud de perfil para \(\alpha\) es
\[ \ell^*(\alpha) = \ell(\widehat\lambda(\alpha),\alpha). \]
Equivalentemente, se puede parametrizar en términos de
\[ \sigma=\frac{1}{\alpha}. \]
loglik_perfil_sigma <- function(sigma, time, status) {
if (sigma <= 0) return(-Inf)
alpha <- 1 / sigma
d <- sum(status)
suma_t_alpha <- sum(time^alpha)
lambda_hat <- (d / suma_t_alpha)^(1 / alpha)
d * log(alpha) +
d * alpha * log(lambda_hat) +
(alpha - 1) * sum(status * log(time)) -
lambda_hat^alpha * suma_t_alpha
}
ajuste_perfil <- optimize(
f = function(sigma) {
-loglik_perfil_sigma(
sigma,
time = pharmacoSmoking$ttr,
status = pharmacoSmoking$relapse
)
},
interval = c(0.05, 10)
)
sigma_hat <- ajuste_perfil$minimum
alpha_hat <- 1 / sigma_hat
d <- sum(pharmacoSmoking$relapse)
suma_t_alpha <- sum(pharmacoSmoking$ttr^alpha_hat)
lambda_hat <- (d / suma_t_alpha)^(1 / alpha_hat)
mu_hat <- -log(lambda_hat)
c(
mu = mu_hat,
sigma = sigma_hat,
alpha = alpha_hat,
lambda = lambda_hat
) mu sigma alpha lambda
4.656327931 2.041045279 0.489945035 0.009501288 Para graficar la log-verosimilitud perfil:
sigma_grid <- seq(1, 5, length.out = 300)
loglik_grid <- vapply(
sigma_grid,
loglik_perfil_sigma,
numeric(1),
time = pharmacoSmoking$ttr,
status = pharmacoSmoking$relapse
)
plot(
sigma_grid, loglik_grid,
type = "l",
xlab = expression(sigma),
ylab = "Log-verosimilitud perfil"
)
abline(v = sigma_hat, lty = 2)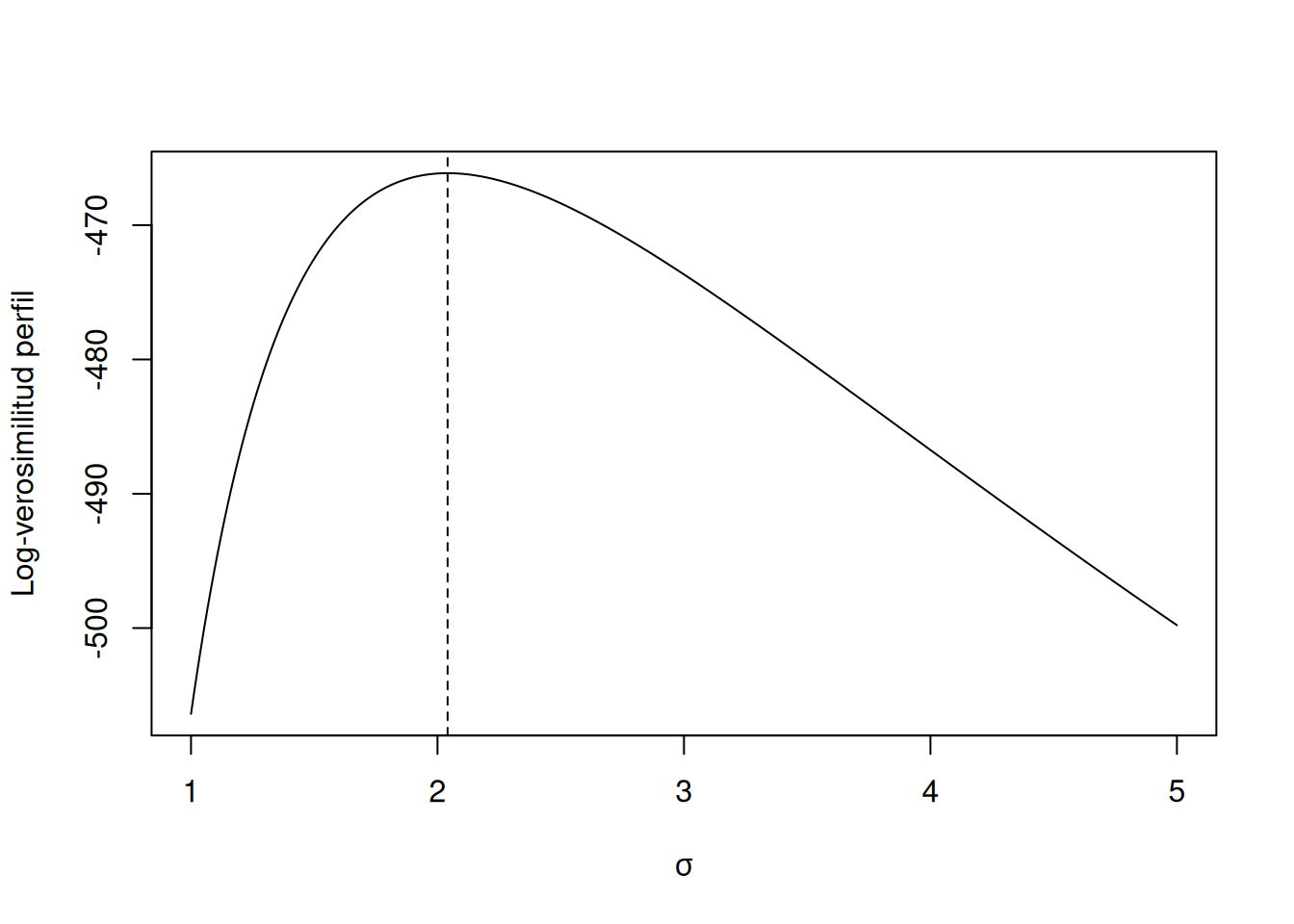
16.5 Ajuste de una Weibull a dos puntos de Kaplan-Meier
En ocasiones se desea seleccionar una distribución Weibull que pase exactamente por dos puntos estimados de una curva de Kaplan-Meier.
Sean
\[ S(t_1)=s_1, \qquad S(t_2)=s_2. \]
Definimos
\[ y_1=\log[-\log(s_1)], \qquad y_2=\log[-\log(s_2)]. \]
Como se asume una distribución Weibull entre los puntos:
\[ y_i = \alpha\log(\lambda)+\alpha\log(t_i), \]
se obtiene
\[ \widetilde\alpha = \frac{y_1-y_2} {\log(t_1)-\log(t_2)}, \]
y
\[ \widetilde\lambda = \exp\left\{ \frac{y_2\log(t_1)-y_1\log(t_2)} {y_1-y_2} \right\}. \]
Implementación en R:
weibull_dos_puntos <- function(time, surv) {
stopifnot(
length(time) == 2,
length(surv) == 2,
all(time > 0),
all(surv > 0 & surv < 1)
)
y <- log(-log(surv))
alpha <- (y[1] - y[2]) /
(log(time[1]) - log(time[2]))
log_lambda <- y[1] / alpha - log(time[1])
lambda <- exp(log_lambda)
S <- function(t) {
exp(-(lambda * t)^alpha)
}
list(
alpha = alpha,
lambda = lambda,
scale_convencional = 1 / lambda,
survival = S
)
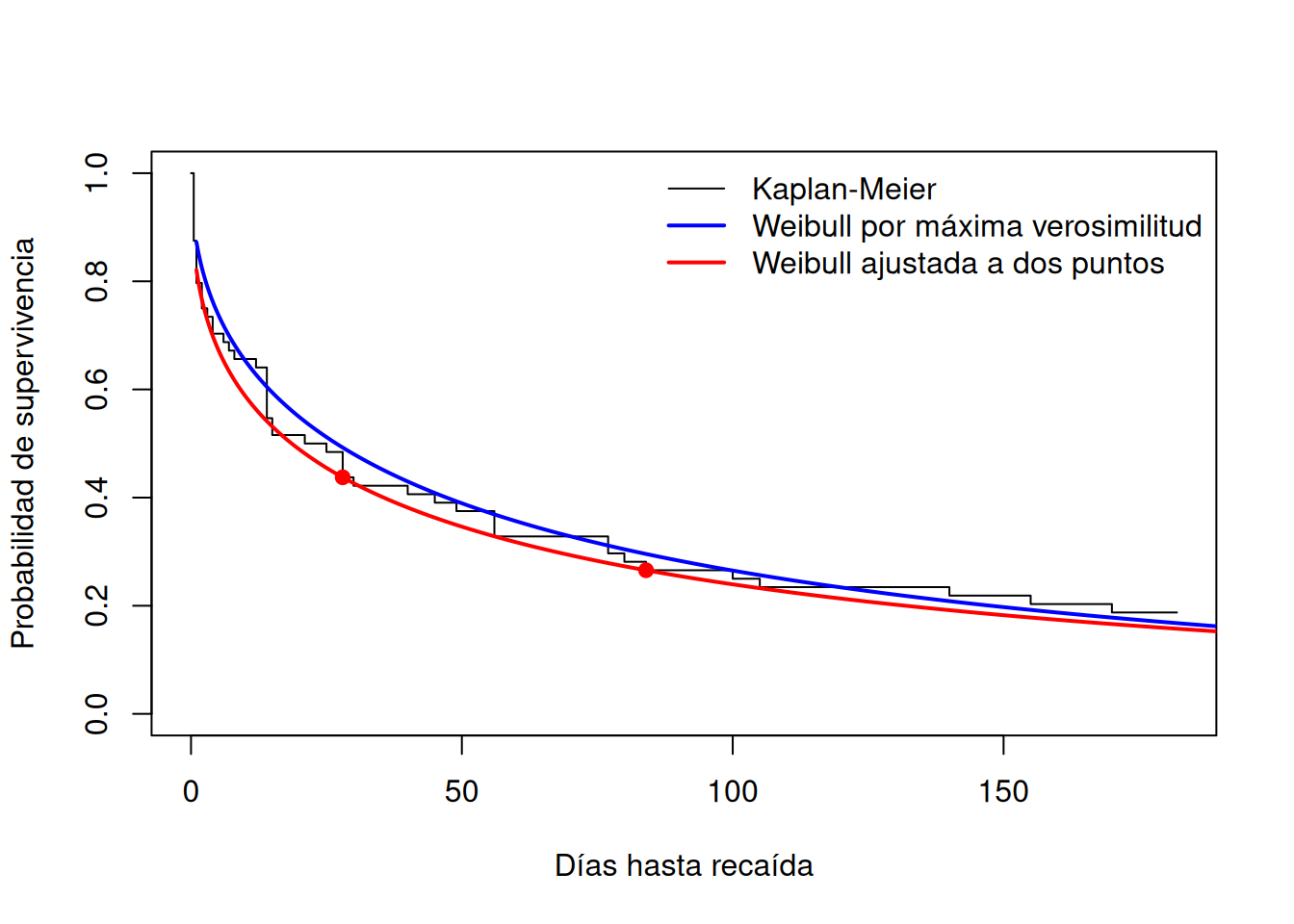
}Ejemplo para el grupo patchOnly
pharmacoSmoking$grp <- factor(pharmacoSmoking$grp)
km_patch <- survfit(
Surv(ttr, relapse) ~ 1,
data = pharmacoSmoking,
subset = grp == "patchOnly"
)
resumen_puntos <- summary(
km_patch,
times = c(28, 84),
extend = TRUE
)
t_vec <- resumen_puntos$time
s_vec <- resumen_puntos$surv
ajuste_2p <- weibull_dos_puntos(t_vec, s_vec)
t_grid <- seq(1, 200, length.out = 500)
S_2p <- ajuste_2p$survival(t_grid)Modelo Weibull por máxima verosimilitud:
weib_patch <- survreg(
Surv(ttr, relapse) ~ 1,
data = pharmacoSmoking,
subset = grp == "patchOnly",
dist = "weibull"
)
mu_mle <- unname(coef(weib_patch)[1])
sigma_mle <- weib_patch$scale
S_mle <- pweibull(
t_grid,
shape = 1 / sigma_mle,
scale = exp(mu_mle),
lower.tail = FALSE
)Comparación gráfica:
plot(
km_patch,
conf.int = FALSE,
xlab = "Días hasta recaída",
ylab = "Probabilidad de supervivencia"
)
lines(t_grid, S_mle, lwd = 2, col = "blue")
lines(t_grid, S_2p, lwd = 2, col = "red")
points(t_vec, s_vec, pch = 19, col = "red")
legend(
"topright",
legend = c(
"Kaplan-Meier",
"Weibull por máxima verosimilitud",
"Weibull ajustada a dos puntos"
),
col = c("black", "blue", "red"),
lty = c(1, 1, 1),
lwd = c(1, 2, 2),
bty = "n"
)
16.6 Modelos de tiempo de falla acelerado
Definición
En un modelo de tiempo de falla acelerado, AFT, se supone que el tiempo de supervivencia del grupo tratado es una multiplicación del tiempo del grupo de referencia:
\[ T_1=e^\gamma T_0. \]
Equivalentemente,
\[ S_1(t)=S_0(e^{-\gamma}t). \]
La función de riesgo satisface
\[ h_1(t) = e^{-\gamma} h_0(e^{-\gamma}t). \]
El factor
\[ e^\gamma \]
se denomina razón de tiempos o factor de aceleración:
- si \(\gamma>0\), entonces \(e^\gamma>1\) y el grupo 1 presenta tiempos más largos;
- si \(\gamma<0\), entonces \(e^\gamma<1\) y el grupo 1 presenta tiempos más cortos.
Equivalencia AFT–PH para la distribución Weibull
Para una distribución Weibull,
\[ h_0(t) = \frac{1}{\sigma} e^{-\mu_0/\sigma} t^{1/\sigma-1}. \]
Entonces,
\[ h_1(t) = e^{-\gamma} h_0(e^{-\gamma}t), \]
y al sustituir:
\[ h_1(t) = e^{-\gamma/\sigma}h_0(t). \]
Por tanto, el modelo Weibull AFT también es un modelo de riesgos proporcionales:
\[ h_1(t)=e^\beta h_0(t), \]
con
\[ \beta=-\frac{\gamma}{\sigma}. \]
Así,
\[ \operatorname{HR} = \exp\left(-\frac{\gamma}{\sigma}\right). \]
La Weibull es la única distribución para la cual los modelos AFT y de riesgos proporcionales son simultáneamente válidos.
Ejemplo: tratamiento para dejar de fumar
Se comparan:
- terapia combinada, grupo de referencia;
- tratamiento únicamente con parche,
patchOnly.
pharmacoSmoking$grp <- relevel(
factor(pharmacoSmoking$grp),
ref = "combination"
)
modelo_aft_grp <- survreg(
Surv(ttr, relapse) ~ grp,
data = pharmacoSmoking,
dist = "weibull"
)
summary(modelo_aft_grp)
Call:
survreg(formula = Surv(ttr, relapse) ~ grp, data = pharmacoSmoking,
dist = "weibull")
Value Std. Error z p
(Intercept) 5.2859 0.3320 15.92 <2e-16
grppatchOnly -1.2514 0.4348 -2.88 0.004
Log(scale) 0.6888 0.0911 7.56 4e-14
Scale= 1.99
Weibull distribution
Loglik(model)= -461.8 Loglik(intercept only)= -466.1
Chisq= 8.63 on 1 degrees of freedom, p= 0.0033
Number of Newton-Raphson Iterations: 5
n= 125 En el ejemplo se obtuvo aproximadamente
\[ \widehat\gamma=-1.251, \qquad \widehat\sigma=1.99. \]
La razón de tiempos es
\[ e^{-1.251}=0.286. \]
Esto indica que el tiempo hasta recaída en el grupo de parche es aproximadamente 28.6% del tiempo correspondiente al grupo de terapia combinada.
La razón de riesgos Weibull equivalente es
\[ \exp\left( -\frac{-1.251}{1.99} \right) = \exp(0.629) \approx 1.88. \]
Por tanto, el riesgo instantáneo de recaída es mayor en el grupo de parche.
gamma_hat <- coef(modelo_aft_grp)["grppatchOnly"]
sigma_hat <- modelo_aft_grp$scale
time_ratio <- exp(gamma_hat)
beta_ph <- -gamma_hat / sigma_hat
HR_weibull <- exp(beta_ph)
c(
gamma_AFT = gamma_hat,
time_ratio = time_ratio,
beta_PH = beta_ph,
HR_Weibull = HR_weibull
) gamma_AFT.grppatchOnly time_ratio.grppatchOnly beta_PH.grppatchOnly
-1.2513664 0.2861136 0.6284384
HR_Weibull.grppatchOnly
1.8746807 Comparación con Cox:
modelo_cox_grp <- coxph(
Surv(ttr, relapse) ~ grp,
data = pharmacoSmoking
)
summary(modelo_cox_grp)Call:
coxph(formula = Surv(ttr, relapse) ~ grp, data = pharmacoSmoking)
n= 125, number of events= 89
coef exp(coef) se(coef) z Pr(>|z|)
grppatchOnly 0.6050 1.8313 0.2161 2.8 0.00511 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
grppatchOnly 1.831 0.5461 1.199 2.797
Concordance= 0.581 (se = 0.027 )
Likelihood ratio test= 7.99 on 1 df, p=0.005
Wald test = 7.84 on 1 df, p=0.005
Score (logrank) test = 8.07 on 1 df, p=0.004c(
HR_Weibull = HR_weibull,
HR_Cox = exp(coef(modelo_cox_grp))
)HR_Weibull.grppatchOnly HR_Cox.grppatchOnly
1.874681 1.831290 En el ejemplo original, el coeficiente de Cox fue aproximadamente
\[ \widehat\beta_{\text{Cox}}=0.605, \]
cercano al coeficiente Weibull equivalente
\[ \widehat\beta_{\text{Weibull}}=0.629. \]
Curvas estimadas por Weibull y Cox
mu0_hat <- unname(coef(modelo_aft_grp)[1])
gamma_hat <- unname(coef(modelo_aft_grp)["grppatchOnly"])
sigma_hat <- modelo_aft_grp$scale
t_grid <- seq(
0.01,
max(pharmacoSmoking$ttr),
length.out = 500
)
S_combination <- pweibull(
t_grid,
shape = 1 / sigma_hat,
scale = exp(mu0_hat),
lower.tail = FALSE
)
S_patch <- pweibull(
t_grid,
shape = 1 / sigma_hat,
scale = exp(mu0_hat + gamma_hat),
lower.tail = FALSE
)
curvas_cox <- survfit(
modelo_cox_grp,
newdata = data.frame(
grp = factor(
c("combination", "patchOnly"),
levels = levels(pharmacoSmoking$grp)
)
)
)
plot(
curvas_cox,
lwd = 1,
xlab = "Tiempo hasta recaída",
ylab = "Probabilidad de supervivencia"
)
lines(t_grid, S_combination, lwd = 2)
lines(t_grid, S_patch, lwd = 2, lty = 2)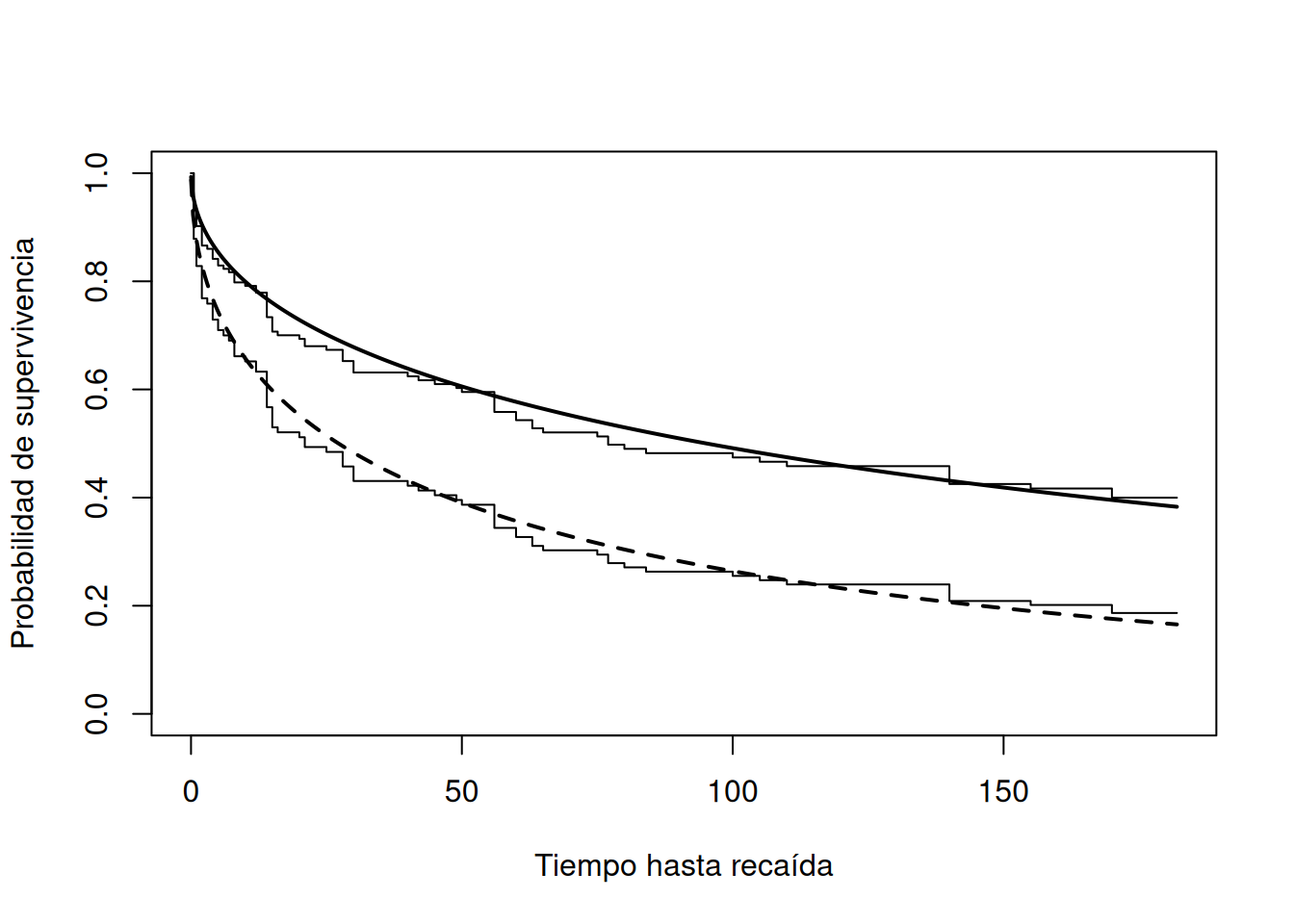
Las curvas de Cox son funciones escalonadas, mientras que las curvas Weibull son suaves.
Formulación de regresión Weibull
El modelo Weibull AFT puede expresarse como un modelo de localización y escala para el logaritmo del tiempo:
\[ \log T = \mu+\mathbf{x}^{\mathsf T}\boldsymbol\gamma + \sigma\varepsilon^*, \]
donde \(\varepsilon^*\) sigue una distribución de valores extremos.
Para una covariable \(x_j\):
\[ e^{\gamma_j} \]
es el factor multiplicativo sobre el tiempo de supervivencia, manteniendo constantes las demás covariables.
En la parametrización equivalente de riesgos proporcionales:
\[ \beta_j=-\frac{\gamma_j}{\sigma}. \]
Weibull con múltiples covariables
Considérese un modelo con:
- grupo de tratamiento;
- edad;
- situación laboral.
Modelo de Cox
modelo_cox_multi <- coxph(
Surv(ttr, relapse) ~ grp + age + employment,
data = pharmacoSmoking
)
summary(modelo_cox_multi)Call:
coxph(formula = Surv(ttr, relapse) ~ grp + age + employment,
data = pharmacoSmoking)
n= 125, number of events= 89
coef exp(coef) se(coef) z Pr(>|z|)
grppatchOnly 0.60788 1.83654 0.21837 2.784 0.00537 **
age -0.03529 0.96533 0.01075 -3.282 0.00103 **
employmentother 0.70348 2.02077 0.26929 2.612 0.00899 **
employmentpt 0.65369 1.92262 0.32732 1.997 0.04581 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
grppatchOnly 1.8365 0.5445 1.1971 2.8176
age 0.9653 1.0359 0.9452 0.9859
employmentother 2.0208 0.4949 1.1920 3.4256
employmentpt 1.9226 0.5201 1.0122 3.6518
Concordance= 0.638 (se = 0.03 )
Likelihood ratio test= 22.03 on 4 df, p=2e-04
Wald test = 21.91 on 4 df, p=2e-04
Score (logrank) test = 22.48 on 4 df, p=2e-04En Cox, un coeficiente positivo representa mayor riesgo y peor supervivencia.
Modelo Weibull AFT
modelo_weib_multi <- survreg(
Surv(ttr, relapse) ~ grp + age + employment,
data = pharmacoSmoking,
dist = "weibull"
)
summary(modelo_weib_multi)
Call:
survreg(formula = Surv(ttr, relapse) ~ grp + age + employment,
data = pharmacoSmoking, dist = "weibull")
Value Std. Error z p
(Intercept) 2.4024 0.9653 2.49 0.0128
grppatchOnly -1.1902 0.4133 -2.88 0.0040
age 0.0697 0.0203 3.43 0.0006
employmentother -1.3890 0.5029 -2.76 0.0057
employmentpt -1.3143 0.6132 -2.14 0.0321
Log(scale) 0.6313 0.0900 7.02 2.3e-12
Scale= 1.88
Weibull distribution
Loglik(model)= -454.1 Loglik(intercept only)= -466.1
Chisq= 23.96 on 4 degrees of freedom, p= 8.2e-05
Number of Newton-Raphson Iterations: 5
n= 125 En un modelo AFT:
- un coeficiente positivo implica tiempos de supervivencia más largos;
- un coeficiente negativo implica tiempos más cortos.
Por ejemplo, si
\[ \widehat\gamma_{\text{patchOnly}}=-1.190, \]
entonces
\[ e^{-1.190}=0.304. \]
El tiempo hasta recaída del grupo de parche se estima como aproximadamente 30.4% del tiempo correspondiente al grupo de terapia combinada.
Conversión a coeficientes de riesgos proporcionales
coef_aft <- coef(modelo_weib_multi)[-1]
sigma_hat <- modelo_weib_multi$scale
coef_ph_weibull <- -coef_aft / sigma_hat
coef_ph_cox <- coef(modelo_cox_multi)
comparacion <- data.frame(
beta_Weibull_PH = coef_ph_weibull,
beta_Cox = coef_ph_cox[names(coef_ph_weibull)]
)
comparacion beta_Weibull_PH beta_Cox
grppatchOnly 0.63301278 0.60788405
age -0.03708786 -0.03528934
employmentother 0.73878031 0.70347664
employmentpt 0.69903157 0.65369019En el ejemplo original, los estimadores fueron similares:
| Covariable | Weibull PH | Cox |
|---|---|---|
grppatchOnly |
0.633 | 0.608 |
age |
-0.037 | -0.035 |
employmentother |
0.739 | 0.703 |
employmentpt |
0.699 | 0.654 |
16.7 Selección y diagnóstico del modelo Weibull
Selección mediante AIC
Puede realizarse selección por pasos usando AIC:
modelo_weib_completo <- survreg(
Surv(ttr, relapse) ~
grp + gender + race + employment +
yearsSmoking + levelSmoking + age +
priorAttempts + longestNoSmoke,
data = pharmacoSmoking,
dist = "weibull"
)
modelo_weib_step <- step(
modelo_weib_completo,
direction = "backward",
trace = FALSE
)
summary(modelo_weib_step)
Call:
survreg(formula = Surv(ttr, relapse) ~ grp + employment + age,
data = pharmacoSmoking, dist = "weibull")
Value Std. Error z p
(Intercept) 2.4024 0.9653 2.49 0.0128
grppatchOnly -1.1902 0.4133 -2.88 0.0040
employmentother -1.3890 0.5029 -2.76 0.0057
employmentpt -1.3143 0.6132 -2.14 0.0321
age 0.0697 0.0203 3.43 0.0006
Log(scale) 0.6313 0.0900 7.02 2.3e-12
Scale= 1.88
Weibull distribution
Loglik(model)= -454.1 Loglik(intercept only)= -466.1
Chisq= 23.96 on 4 degrees of freedom, p= 8.2e-05
Number of Newton-Raphson Iterations: 5
n= 125 Este procedimiento debe considerarse exploratorio. La selección repetida con los mismos datos puede producir modelos inestables e inferencia demasiado optimista.
Residuos de devianza
resid_deviance <- residuals(
modelo_weib_multi,
type = "deviance"
)
op <- par(mfrow = c(2, 2))
scatter.smooth(
x = pharmacoSmoking$age,
y = resid_deviance,
xlab = "Edad",
ylab = "Residuo de devianza",
main = "Residuos versus edad"
)
boxplot(
resid_deviance ~ pharmacoSmoking$grp,
xlab = "Tratamiento",
ylab = "Residuo de devianza",
main = "Residuos versus tratamiento"
)
boxplot(
resid_deviance ~ pharmacoSmoking$employment,
xlab = "Empleo",
ylab = "Residuo de devianza",
main = "Residuos versus empleo"
)
plot(
fitted(modelo_weib_multi),
resid_deviance,
xlab = "Valores ajustados",
ylab = "Residuo de devianza",
main = "Residuos versus ajuste"
)
abline(h = 0, lty = 2)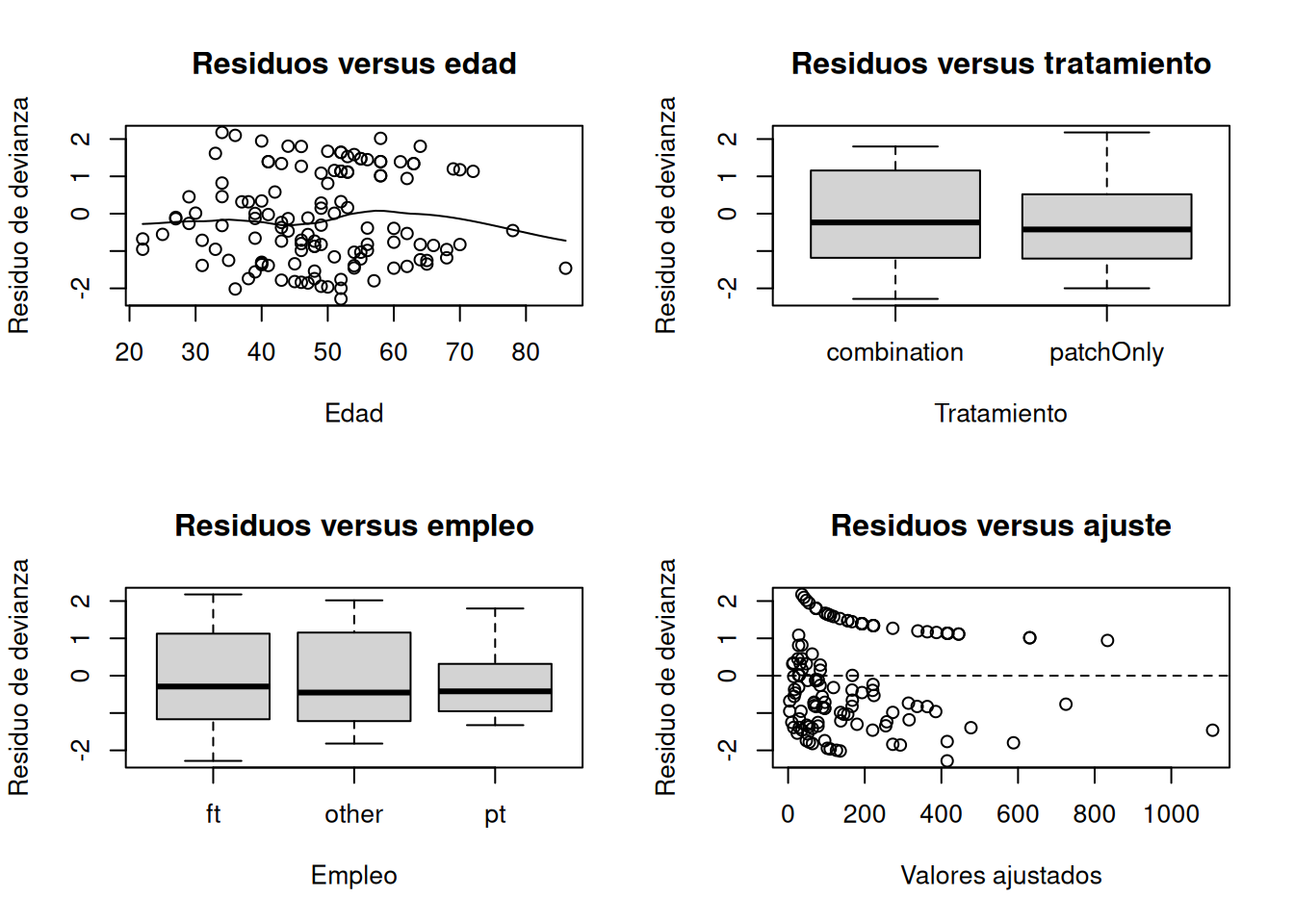
par(op)Se buscan:
- ausencia de tendencias sistemáticas;
- dispersión aproximadamente comparable entre grupos;
- falta de valores excesivamente extremos;
- ausencia de patrones respecto a los valores ajustados.
Residuos dfbeta
Los residuos dfbeta miden cuánto cambia un coeficiente al eliminar una observación.
resid_dfbeta <- residuals(
modelo_weib_multi,
type = "dfbeta"
)
indice_age <- which(
names(coef(modelo_weib_multi)) == "age"
)
dfbeta_age <- resid_dfbeta[, indice_age]
plot(
seq_along(dfbeta_age),
dfbeta_age,
type = "h",
xlab = "Observación",
ylab = "Cambio aproximado en el coeficiente de edad"
)
abline(h = 0, lty = 2)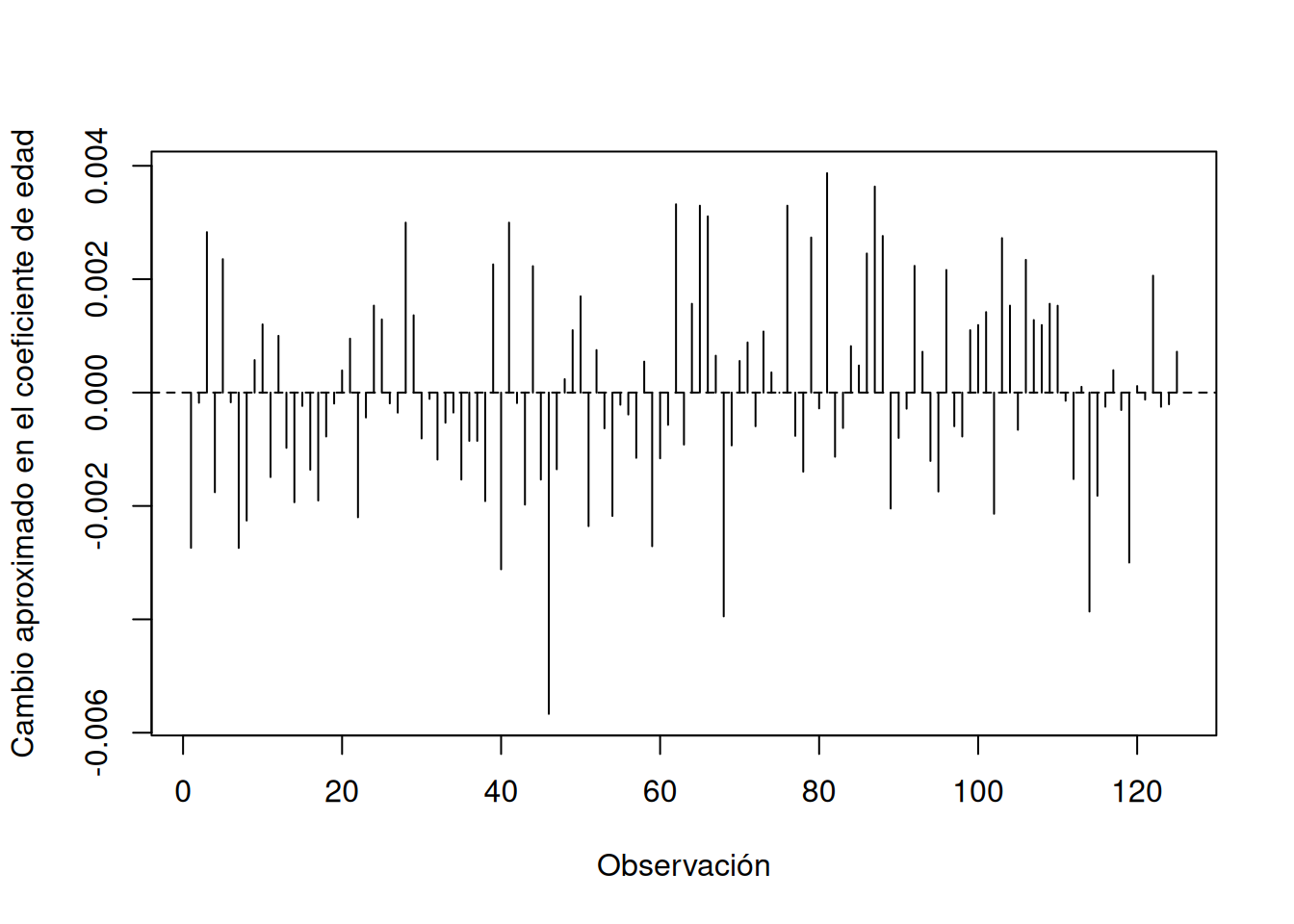
Las observaciones con valores absolutos particularmente grandes pueden ser influyentes.
16.8 Otras distribuciones paramétricas
La formulación general AFT es
\[ \log T = \mu+\mathbf{x}^{\mathsf T}\boldsymbol\gamma + \sigma\varepsilon. \]
La distribución elegida para \(\varepsilon\) determina la distribución de \(T\).
Modelo lognormal
Si
\[ \varepsilon\sim N(0,1), \]
entonces
\[ \log T\sim N(\mu+\mathbf{x}^{\mathsf T}\boldsymbol\gamma,\sigma^2), \]
y \(T\) sigue una distribución lognormal.
modelo_lognormal <- survreg(
Surv(ttr, relapse) ~ grp + age + employment,
data = pharmacoSmoking,
dist = "lognormal"
)
summary(modelo_lognormal)
Call:
survreg(formula = Surv(ttr, relapse) ~ grp + age + employment,
data = pharmacoSmoking, dist = "lognormal")
Value Std. Error z p
(Intercept) 1.6579 1.0084 1.64 0.1002
grppatchOnly -1.2623 0.4523 -2.79 0.0053
age 0.0648 0.0203 3.20 0.0014
employmentother -1.1711 0.5316 -2.20 0.0276
employmentpt -0.9543 0.7198 -1.33 0.1849
Log(scale) 0.8754 0.0796 10.99 <2e-16
Scale= 2.4
Log Normal distribution
Loglik(model)= -451.5 Loglik(intercept only)= -461.7
Chisq= 20.4 on 4 degrees of freedom, p= 0.00042
Number of Newton-Raphson Iterations: 3
n= 125 El modelo lognormal es un modelo AFT, pero no es un modelo de riesgos proporcionales. Su función de riesgo puede aumentar inicialmente y disminuir posteriormente.
Modelo log-logístico
Si \(\varepsilon\) sigue una distribución logística, entonces \(T\) sigue una distribución log-logística.
modelo_loglogistico <- survreg(
Surv(ttr, relapse) ~ grp + age + employment,
data = pharmacoSmoking,
dist = "loglogistic"
)
summary(modelo_loglogistico)
Call:
survreg(formula = Surv(ttr, relapse) ~ grp + age + employment,
data = pharmacoSmoking, dist = "loglogistic")
Value Std. Error z p
(Intercept) 1.9150 0.9708 1.97 0.0485
grppatchOnly -1.3260 0.4588 -2.89 0.0038
age 0.0617 0.0196 3.15 0.0017
employmentother -1.2605 0.5392 -2.34 0.0194
employmentpt -1.0991 0.7050 -1.56 0.1190
Log(scale) 0.3565 0.0884 4.03 5.5e-05
Scale= 1.43
Log logistic distribution
Loglik(model)= -453.4 Loglik(intercept only)= -463.6
Chisq= 20.47 on 4 degrees of freedom, p= 4e-04
Number of Newton-Raphson Iterations: 4
n= 125 El modelo log-logístico es simultáneamente:
- un modelo AFT;
- un modelo de cuotas proporcionales de supervivencia.
Las cuotas de supervivencia satisfacen
\[ \frac{S_1(t)}{1-S_1(t)} = e^{\mathbf{z}^{\mathsf T}\boldsymbol\beta} \frac{S_0(t)}{1-S_0(t)}. \]
Al igual que la lognormal, la log-logística permite funciones de riesgo no monótonas.
Comparación mediante AIC
Si los modelos se ajustan a las mismas observaciones, pueden compararse mediante AIC:
AIC(
Weibull = modelo_weib_multi,
Lognormal = modelo_lognormal,
Loglogistica = modelo_loglogistico
)Un AIC menor indica mejor equilibrio entre ajuste y complejidad, pero la elección final también debe considerar:
- diagnóstico de residuos;
- plausibilidad de la forma del riesgo;
- interpretación científica;
- comportamiento de las extrapolaciones;
- estabilidad de las estimaciones.
16.9 Ejercicios
- veteran, paquete survival.
- rotterdam, paquete survival.